
图像检索(image retrieval)- 5 - Visual Search at Alibaba - 1 -论文学习
Visual Search at Alibaba
ABSTRACT
介绍了阿里巴巴的大规模可视化搜索算法和系统架构。如下面临的挑战将在阿里巴巴电子商务环境下讨论:(a)如何处理异构的图像数据,并减小用户查询的实拍图像与在线图像之间的差距。(b)如何处理海量更新数据的大规模索引。(c)如何训练深度模型,在没有大量人工标注的情况下得到有效地特征表征。(d)如何通过考虑内容的质量来提高用户的参与度。我们利用阿里巴巴收集的大量图像和最先进的深度学习技术进行大规模的视觉搜索。我们提供解决方案和实现细节来克服这些问题,并分享我们从构建如此大规模的商业视觉搜索引擎的经验教训。引入基于模型和搜索的融合方法,有效地预测类别。同时,我们提出了一个深度CNN模型,通过挖掘用户点击行为来进行联合检测和特征学习。二进制索引引擎的设计目的是在不影响召回率和精度的情况下扩大索引。最后,我们将所有的阶段应用到一个端到端的系统架构中,可以同时实现高效率和可扩展的性能,适应于真实拍摄的图像。大量的实验证明了系统各模块的先进性。我们希望阿里巴巴的视觉搜索能更广泛地融入到今天的商业应用中。
1 INTRODUCTION
随着网络图片在搜索引擎和社交媒体上的日益普及,视觉搜索或基于内容的图像检索(CBIR)成为近年来的热门研究课题。因此,因为其明显的优势,开发电子商务系统中的视觉搜索势在必行:1)更方便的交互,2)搜索条目优于文本的细粒度描述,3)在线和离线场景之间的良好连接。考虑到现实世界中视觉搜索系统的算法和工程复杂性,很少有出版物详细描述在商业应用上部署的端到端系统。一般来说,一些可视化搜索系统,如Ebay [22], Pinterest[7]发布他们的部署产品来描述架构,算法和部署。
在阿里巴巴,我们在视觉搜索技术的实际应用中也遇到了很多挑战。通过与阿里巴巴的算法和搜索团队的合作,我们成功开发了智能电商应用“Pailitao”。“Pailitao”,就是用相机购物。它是以深度学习和大规模机器学习技术为核心的创新图像智能产品,利用视觉搜索服务实现“图像搜索”功能,如图1所示。自2014年推出以来,在业界引起了高度的关注和广泛的认可,并经历了快速的增长,2017年日均活跃用户(Daily Active User,DAU)超过1700万。2017年中国双十一购物节,Pailitao成功突破3000万DAU。在这篇文章中,我们想分享一些视觉搜索技术的关键进展,这些进展明确地解决了阿里巴巴目前面临的挑战。这款产品极具挑战性,与其他产品的区别主要体现在以下四个方面:
Heterogeneous images matching: 不像标准的搜索引擎,Pailitao的用户搜索通常是实景图片,这意味着我们允许用户从真实生活中拍摄图片,也可以上传任何来源的查询图片。我们很容易注意到,实拍图像的质量并不像库存图像那样完美,总是存在语义和视觉上的差距。
Billions of data with fine-grained categories: 大多数视觉搜索解决方案都无法达到阿里巴巴的规模。阿里巴巴拥有庞大且持续增长的图片收藏,其中的标签有noise,也可能是错误的。此外,该集合涵盖了许多容易相互混淆的细粒度类别。我们的系统需要具有可扩展性和成本效益,采用分布式架构来处理大量数据。
Huge expense for maintaining training data: 在阿里巴巴这样的动态市场中,由于图像的多样性,数据总是会有噪声。对于深度模型的训练,这些图像往往包含复杂的背景,来自多个数据源,这使得特征学习难以实现高搜索相关性和低延迟。维护训练数据非常辛苦,从数据的收集和清理到标注注释,通常需要巨大的成本。
Improving the user engagement: 一个商业应用程序的成功是通过它给用户带来的好处来衡量的。如何吸引更多的用户尝试视觉搜索服务是关键问题。现在迫切需要鼓励用户购买这些产品并进行可能的转化。

尽管有挑战,但我们也有机会,1)库存中的每一件商品都有自己的图片,2)图片是由卖家或客户提供的带有自然标签的数据,3)自然的购物场景为视觉搜索提供了很大的空间。
抓住现有的机会,我们描述如何缓解上述问题和应对挑战。总体来说,我们详细介绍了阿里巴巴视觉搜索系统的构建和运营方法。我们举例说明了我们的系统架构,并进一步挖掘有效数据供深度学习模型使用。具体来说,我们描述了如何依据精度和速度来利用深度学习方法进行分类预测、联合检测和特征学习,并讨论了大规模索引和图像重新排序。我们在自己构建的测试集上进行实验,以评估每个模块的有效性。我们还展示了我们的索引引擎在无损召回和重新排序策略方面的效率。
2 RELATED WORK
在语义特征表示和图像分类方面,深度学习已经被证明是极其强大和广泛发展的。随着深度卷积神经网络呈指数级增长,视觉搜索引起了人们的极大兴趣[4,7,22]。在实际的视觉搜索场景中,针对含有细粒度分类的大尺度图像,包含复杂背景和带噪声标签的问题,如何根据查询图像找到相同或相似的项仍然是一个非常具有挑战性的问题。考虑到所应用的技术,之前的视觉搜索深度学习大致有三个方面。
例如用于实例检索的CNN:最近,CNN[8,12]在视觉问题方面表现出了良好的性能。已有多篇文章尝试将CNN应用于图像和实例检索(image and instance retrival)[1,19,23]。通过将CNN作为NeuralCode进行图像检索,如Babenko等[2]将全连接层的输出作为图像特征进行检索。Ng等人[10]对CNN特征进行编码,卷积特征全局映射到VLAD中。在[18]中,Tolias等人通过简单地在卷积特征图的所有位置上应用空间max-pooling来生成有效的可视化描述符。在我们的场景中,实例检索(instance retrieval)与图像检索(image retrieval)略有不同,因为它关注的是包含目标对象(不包括背景)的图像区域,而不是整个图像。
Deep metric embedding: 深度度量学习在测量图像之间的相似性方面有很好的效果。Siamese网络或triplet loss在实践中更难训练。为了学习更有效和高效的表示方法,设计了一些针对难样本挖掘的工作,这些工作针对的是一批被认为难的样本。利用FaceNet[15],提出了一种在线策略,将小批处理中的每一对正对与一个semi-hard反例关联。Sohn[16]通过在每次迭代中共同排除多个负例子,进一步将triplet损失扩展为N-pair损失,从而提高triplet损失。像阿里巴巴的大量库存,新产品更新频繁的问题使其计算效率低下和在所有类别中收集triplet数据的不可行性,我们在检索过程和用户点击行为中设计了在线难样本挖掘,效果令人印象深刻,尤其是当图像的细粒度高和且样式多样时。
Weakly supervised object localization: 最近的许多工作都在探索使用CNNs的弱监督对象定位[3,5,11]。为了定位对象,Bergamo等[3]提出了一种自学习的目标定位技术,该技术涉及屏蔽图像区域,以识别导致最大激活的区域。Cinbis等[5]和Pinheiro等[11]将多实例学习与CNN特性相结合,对对象进行定位。然而,这些方法仍处于未经过端到端训练的多阶段,取得了良好的效果。有些工作需要多次网络转发来进行定位,这使得实际数据难以扩展。我们的方法是端到端的训练,以学习没有强注解图像的目标位置和特征。
尽管上述工作取得了成功,但如何将真实的产品落地,找到与用户意图最相关的产品,仍然存在着挑战和问题。考虑到阿里巴巴规模庞大的数据集,要处理数十亿的数据并实现令人满意的性能和延迟是一项挑战和艰巨的任务。
考虑到这些现实的挑战,我们提出了一个可扩展和资源高效的混合视觉搜索系统。我们的贡献如下:
1)引入了一种有效的类别预测方法,利用基于模型和基于搜索方法的融合来减少搜索空间。与传统的仅基于模型的方法相比,该方法具有更好的可扩展性,在混淆类别和领域限制方面取得了更好的性能。
2)我们提出了一个带分支的深度CNN模型,用于联合检测和特征学习。与完全监督这种训练在需要巨大花费的人力标注数据上的检测方法不同,我们提出在不受背景干扰的情况下,同时发现检测mask和精确识别特征。我们直接以一种弱监督的方式应用用户点击行为来训练模型,而不需要额外的注释。
3)作为已部署的移动应用,我们使用二进制索引引擎完成检索过程,并重新排序以提高参与度。我们允许用户自由拍照,在毫秒级响应和无损召回的情况下,以一个高可用性和可扩展的解决方案来寻找相同的项目。大量的实验证明了Pailitao的端到端架构能够有效地为数百万用户提供视觉搜索。
3 VISUAL SEARCH ARCHITECTURE
视觉搜索的目的是通过视觉特征搜索图像,为用户提供相关的图像列表。作为专业图像搜索引擎中的检索服务,Pailitao于2014年首次上线,通过对产品技术的不断打磨,已成为数百万用户的应用。随着业务的增长,我们也建立了稳定的、可扩展的视觉搜索架构。
图2给出了Pailitao的整体视觉搜索流程,分为离线和在线流程。离线过程:主要是指每天构建文档索引的整个过程,包括条目选择、离线特征提取、索引构建(即将图像和其对应特征一一对应起来)。执行完成后,在线库存将每天在指定的时间内更新。在线过程:主要是指用户上传查询图像时返回过程最终结果的关键步骤。这与离线的过程相似,包括在线类别预测、在线检测和特征提取。最后,我们通过索引和重新排序来检索结果列表。
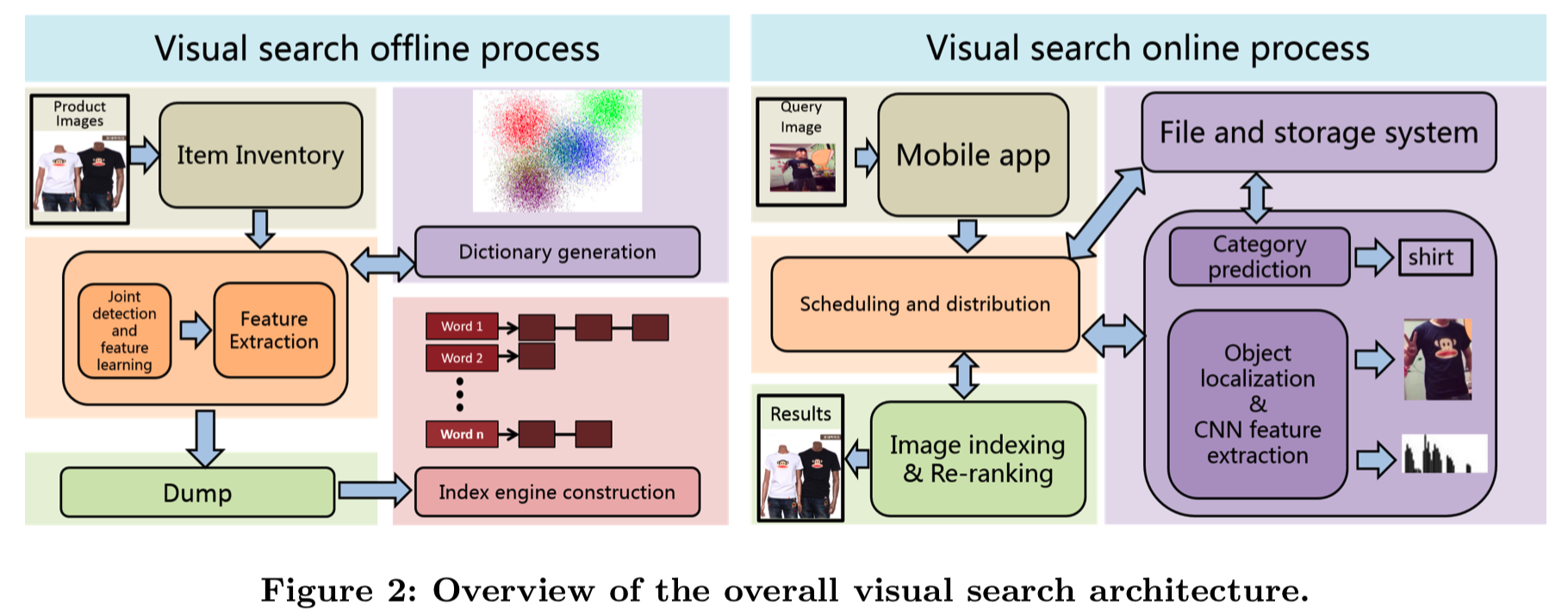
3.1 Category Prediction
3.1.1 Item inventory selection. 有大量的产品类别和图片,包括PC主图片,SKU图片,unboxing图片和LOG图片,涵盖了电子商务的各个方面。我们需要从这些海量的图片中选择用户相对感兴趣的图片作为条目库存进行索引。我们首先根据购物偏好和图像质量过滤整个gallery。由于淘宝上相同或高度相似的商品太多,最终的搜索结果会出现大量相同的商品,不经过过滤,导致用户体验差。在此之后,我们添加了重复图像删除模块,其目的是删除相同或高度相似的项,并优化索引文档。
3.1.2 Model and search-based fusion. 淘宝类别是一个叶子类别的层次系统,同时考虑了一定的视觉和语义相似性。类别系统不仅是一个技术问题,也是一个有利于消费者意识的业务问题。目前,为了适应用户偏好,缩小搜索空间,我们在Pailitao中预测了14个集合类别,涵盖了所有的叶子类别,如鞋、衣服、包等。对于基于模型的部分,我们在高精度和低延迟之间进行权衡,部署了最先进的GoogLeNet V1[17]网络。利用带有类别标签的商品库存子集对网络进行训练,其中包含多种产品类别。作为输入,按照标准设置[17],将每个图像的大小调整为256×256,随机裁剪为227×227。为了训练网络,我们使用标准的softmax-loss来完成分类任务(基于模型的方法得到查询图像的类别其实就是直接将查询图像x输入到分类模型中,然后直接得到类别结果)。在基于搜索的部分,我们利用了深度网络输出特征的识别能力。具体地说,我们收集2亿张图片作为带有ground-truth类别的参考组作为一对(𝑥𝑖,𝑦𝑖)。我们在参考集的检索结果前30名中使用二进制搜索引擎。我们为30个neighbours中的每个xi加权yi的贡献来预测查询x图像的标签y。这是基于检索结果xi到查询图像x的距离得到的,使用了加权函数![]()
![]() ,其中λ在加权函数中通过极大似然估计
,其中λ在加权函数中通过极大似然估计![]() 得到。(所以基于搜索的方法得到查询图像x的类别其实就是通过特征比对从参考集中得到top 30相似结果,然后再根据这些相似图像xi与查询图像x的距离确定他们在最终类别结果中占的权重,这样,最后查询图像的最后类别预测结果,就是使用每个相似图像xi * w(x,xi)的结果求和得到的类别结果)
得到。(所以基于搜索的方法得到查询图像x的类别其实就是通过特征比对从参考集中得到top 30相似结果,然后再根据这些相似图像xi与查询图像x的距离确定他们在最终类别结果中占的权重,这样,最后查询图像的最后类别预测结果,就是使用每个相似图像xi * w(x,xi)的结果求和得到的类别结果)
为了提高类别预测的准确性,我们对基于模型和基于搜索的结果进行加权融合。验证集也从库存数据中收集,并涵盖所有类别。利用特征的识别能力,基于搜索的方法纠正了分类混乱的情况,提高了最终的搜索结果。总体而言,融合使类别预测的最高精度提高了2%以上。
3.2 Joint Detection and Feature Learning
在本节中,我们将介绍基于用户点击行为的联合检测和特征学习。在产品图片搜索场景下的主要挑战是来自消费者和销售者的图片之间的巨大差异。卖家的照片通常都是高质量的,是用高端相机在受控环境下拍摄的。然而,消费者的查询图像通常是使用低端手机相机拍摄的,可能存在光照不均匀、模糊较大、背景复杂等问题。为了减小复杂的背景影响,需要从图像中对目标进行定位。图3反映了用户的查询,展示了目标检测在搜索结果中的重要性。为了在无背景杂波的情况下实现买卖双方图像特征的匹配,我们提出了一种基于深度度量学习的带分支的深度CNN模型来同时学习检测和特征表征。

在最大程度上,我们利用PV(Page View)-LOG图像和用户单击的数据进行难样本挖掘。因此,我们通过用户点击的图像构造有效的triplets,能够用来共同学习对象的位置和特征,而无需进一步的边框注释。
3.2.1 PVLOG triplet mining. 特别,给定一个输入图像𝑞,第一个问题是可靠地匹配来自客户和卖家的异构图像的CNN embeddings 𝑓(𝑞)。这意味着我们需要把查询图像𝑞与相同的产品图像𝑞+之间的距离拉近,并拉远查询图像𝑞和不同的产品图像𝑞−之间的距离。因此,triplet排序损失表示为loss(𝑞, 𝑞+,𝑞−):
![]()
其中L2表示归一化两个特征之间的距离,𝛿表示边际(𝛿= 0.1)。𝑓由CNN网络参数化,可以通过端到端的训练得到。
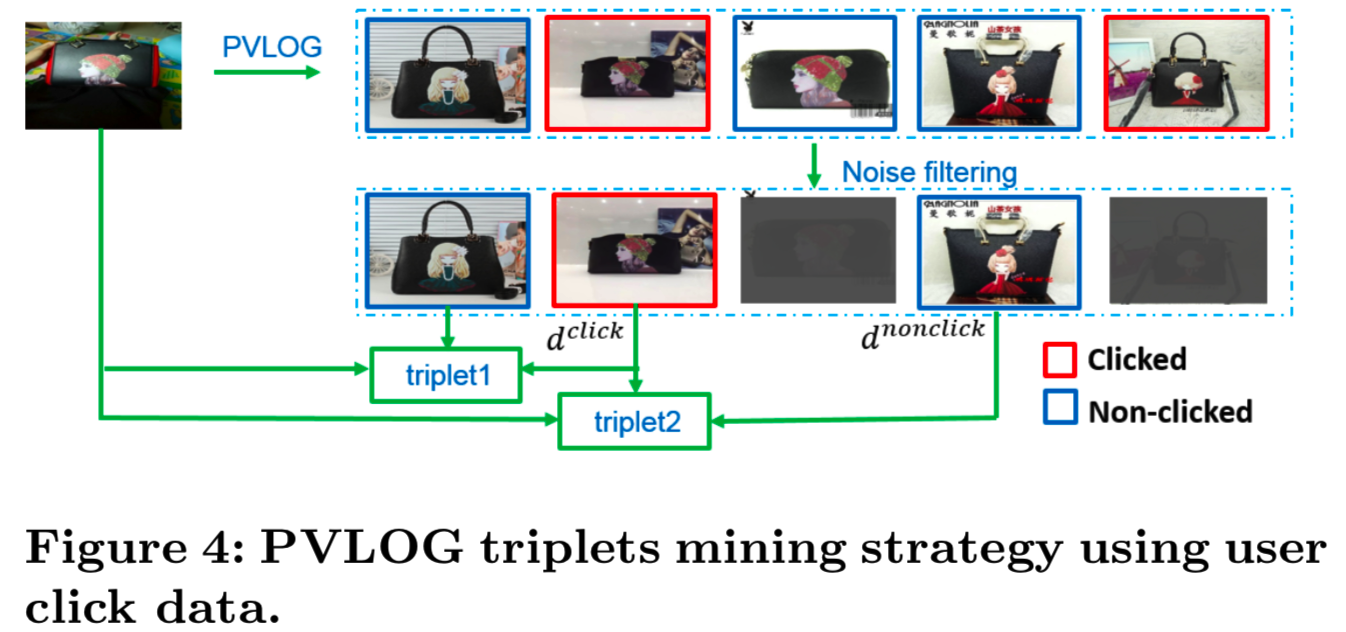
主要难点是如何获取训练样本[21]的难样本。作为一种直接的方法,我们从与查询图像相同的类别中选择正样本,从另一个类别中选择负样本。但是,这样得到的正图像和负图像与查询图像相比会产生较大的视觉差异,导致在训练过程中,triplet排序损失很容易得到零,没有贡献。在如图4中的产品图像检索情况下,我们预计,很大一部分的用户会点击返回列表的相同的产品图片,这表明点击图像𝑑click可以看作是查询的正样本。𝑑nonclick 这种non-clicked图像的优点是,他们通常是难样本,这意味着他们是类似于查询图像的不同产品。但是,non-clicked图像仍然包含与查询相同的项,因为当许多相同的产品图像返回时,用户可能只单击一个或两个结果。所以为了过滤掉non-clicked中与查询图像相同的图片,负样本𝑞−的选取计算如下:

即non-clicked的图像𝑞−中选取的是距离查询图像q和正样本图像𝑞+的距离都大于γ的图像
为了计算特征的dist(),我们采用了一种结合局部特征、之前版本特征和预训练的ImageNet[14]特征的多特征融合方法,可以更准确地找到负样本。同样的步骤应用于点击图像,获得更准确的正样本。
![]()
即正样本找的是点击图像中距离小于ε的图像
为了在一个小批处理中进一步扩展所有可用数据,在一个小批处理中在生成的triplets中共享所有负样本。通过共享负样本,我们可以在进入损失层前生成𝑚2个triplets,如果不共享,则只能生成𝑚个triplets。为了进一步减少训练图像中的噪音,原来的triplet排名损失loss(𝑞, 𝑞+, 𝑞−)改为:
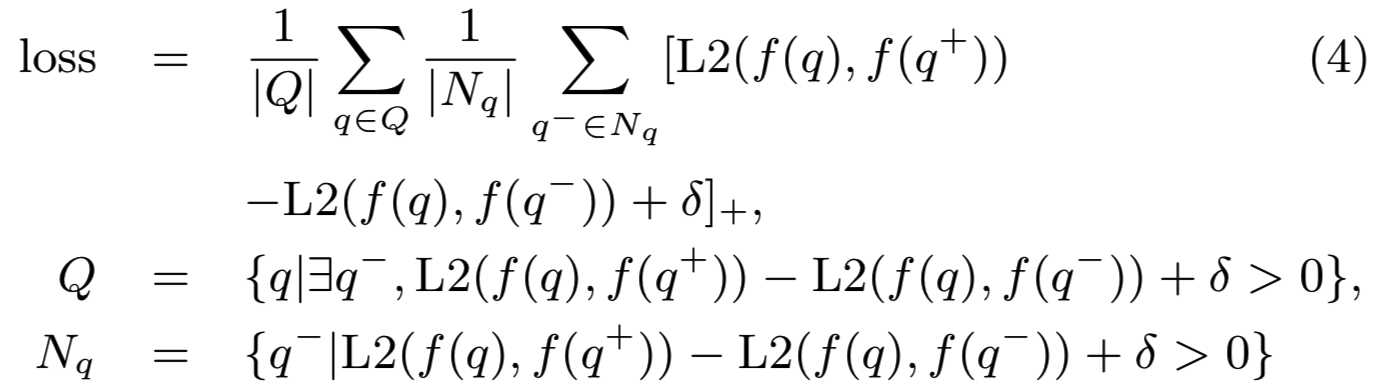
其中损失是在查询层而不是在triplet层计算的平均值,这样我们可以减少noisy查询的影响并平衡样本。利用triplet排名损失,我们可以通过CNN的embeddings将买家的真实拍摄图像和卖家的高质量图像映射到同一个空间,从而实现异构源图像的可靠匹配。
3.2.2 Unified deep ranking framework. 第二个问题是处理图像中的背景杂乱问题。一个直接的方法是部署现成的目标检测算法,如Faster-RCNN[13]或SSD[9]。但是,这种方法用大量的时间和边界框注释成本来分解该过程,且可能得到不是最佳的结果。我们寻求通过两个分支联合优化检测和特征学习,深度联合模型如图5所示。

所以这里没有使用Faster-RCNN[13]或SSD[9]的目标检测算法,而是使用triplet数据来训练得到一个能够同时检测到目标且得到特征的网络
我们部署深度学习排名框架,通过同时输入(𝑞, 𝑞+, 𝑞−)作为triplets去学习深度特征和检测mask,最大化triplets中正负样本的特性,并在没有边界框注释的情况下检测信息对象mask。整体的深度排序框架如图6所示。在每个深度联合模型中,检测mask 𝑀(𝑥,𝑦)可以表示为一个在检测分支中用于边界框估计的step函数,如图5所示,我们使用矩形坐标(𝑥𝑙,𝑥𝑟,𝑦𝑡,𝑦𝑏),element-wise地将输入图像和mask M图像相乘。
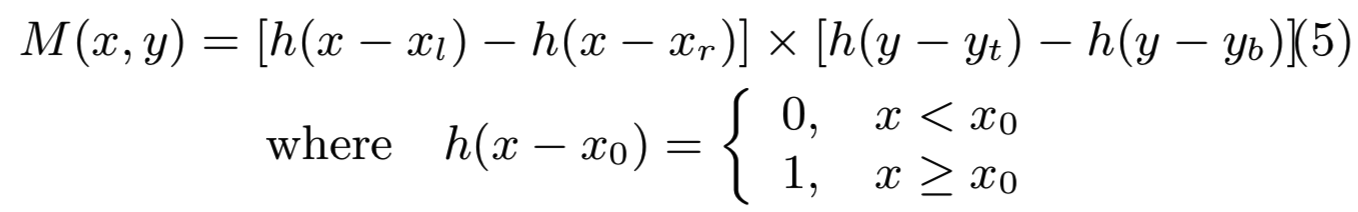
(x,y)表示的是图中某个像素的坐标点,通过上面的计算,将框以外的像素点设置为0,框以内的像素点设置为1,这样和原图一相乘,就能够得到检测到的目标了
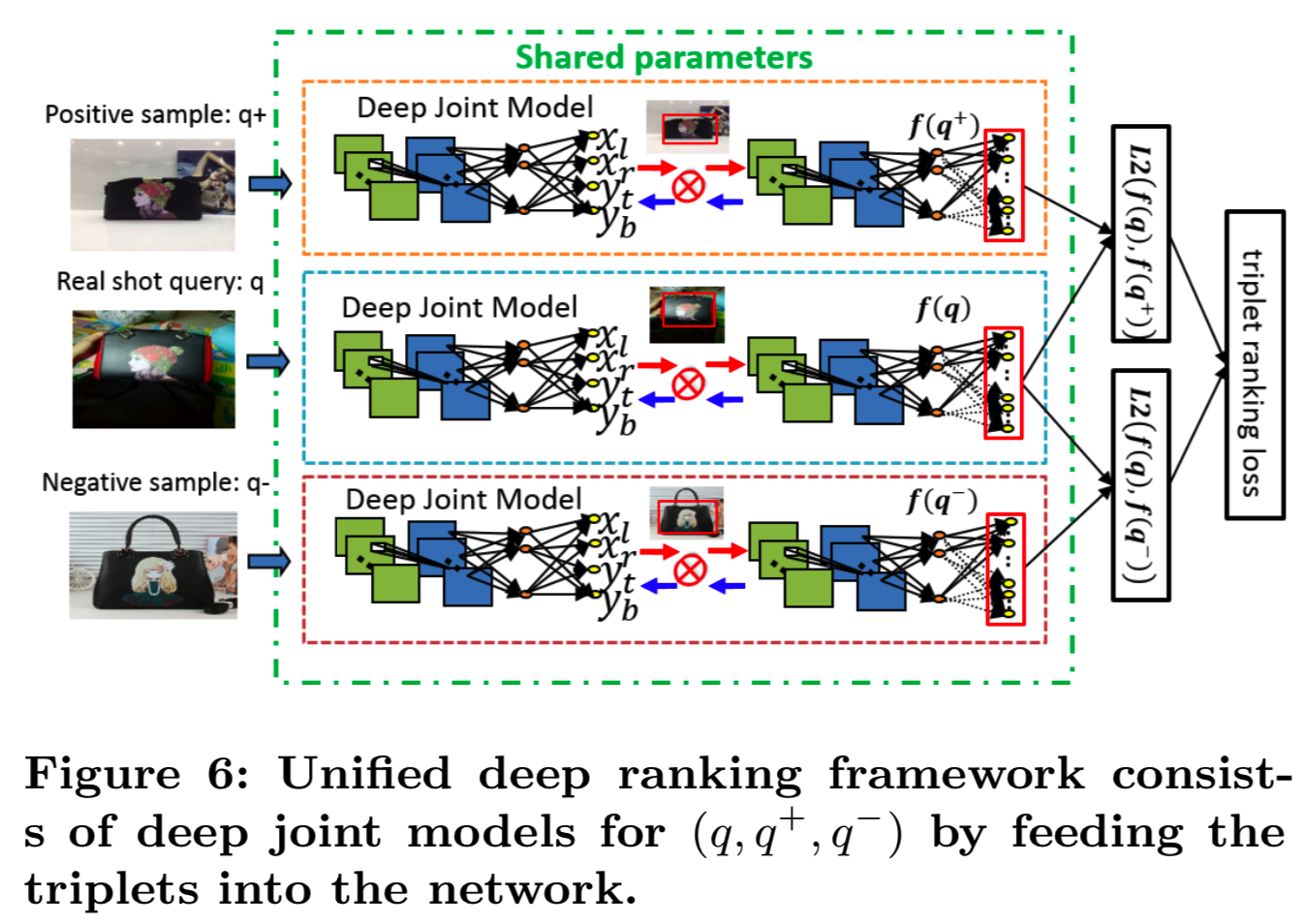
然而,step函数𝑀(𝑥𝑦)不是可微的。为了执行端到端训练,我们可以使用sigmoid函数![]() 近似替代step函数,其中𝑘足够大以使它可微。为了实现深度排序框架,triplet排序损失解决了目标区域受背景影响的问题,同时增强了embedding的区分性。需要注意的是,我们只需要弱监督的用户点击数据,不依赖任何边界框的注释进行训练,这大大降低了人力资源成本,提高了训练效率。
近似替代step函数,其中𝑘足够大以使它可微。为了实现深度排序框架,triplet排序损失解决了目标区域受背景影响的问题,同时增强了embedding的区分性。需要注意的是,我们只需要弱监督的用户点击数据,不依赖任何边界框的注释进行训练,这大大降低了人力资源成本,提高了训练效率。
3.3 Image Indexing and Retrieval
3.3.1 Large-scale search of billion-scale images. 一个实时、稳定的搜索引擎非常重要,因为每天都有上千万的用户在使用Pailitao的视觉搜索服务。因此,我们采用了图7所示的多复制(Multi-replications)和多分片(Multi-shards)引擎架构,它不仅具有容错能力,而且具有非常好的可扩展性。
Multi-shards: 就内存和可扩展性而言,索引实例通常很难存储在一台机器上。我们通常使用多台机器来存储整个数据集,每个分片只存储总向量的一个子集。对于查询,每个分片节点将在自己的子集搜索并返回其𝐾个最近邻。之后,将每个分片的结果合并,然后再排序multi-list候选人得到最终的𝐾个最近邻。multi-shards通过动态添加分片(shards)来满足数据容量的可伸缩性,并且每台机器只处理一小部分向量,有助于提高性能和召回率。
Multi-replications: 每秒的查询量(qps)是在线实时系统的一个重要指标。对于Pailtao搜索来说,qps非常高,这意味着搜索引擎对每个查询的响应时间非常短,给系统带来了巨大的挑战。此外,阿里巴巴每年都有很多大的促销活动,这会让qps波动多达10倍。考虑到上述问题,我们在引擎上安装了multi-replications机制。假设同时有Q个查询访问我们的系统,我们将这些查询分成R个部分,每个部分都有Q/R查询。每个查询部分分别请求一个索引集群。这样,索引集群一次需要处理的查询数量从Q减少到Q/R。通过适当的复制,可以保证qps不超过理论峰值。
对于每个节点,使用两种类型的索引:粗糙过滤和精细排序。粗糙过滤器是基于二值化特征(CNN特征的二值化)构造的改进的二值inverted索引,以图像ID为key,二值化特征为value。通过汉明距离计算,可以快速过滤掉大量不匹配的数据。然后我们将根据返回的数据完整的二进制代码得到𝐾个最近邻。精细重排序是用来做一个更准确的排序细化。它根据额外的元数据,如视觉属性和局部特征,对来自粗过滤器的候选信息进行重新排序。这个过程相对较慢,部分原因是由于元数据以非二进制形式存储,另一个不可忽略的原因是元数据通常太大而无法在内存中存储,这意味着缓存命中率是影响性能的关键因素。
3.3.2 Quality-aware image re-ranking. 我们进一步利用质量感知元数据来提高点击率(Click Through Rate,CTR)和转化率(Click Value Rate,CVR),以吸引更多的用户。考虑到初始结果仅通过外观相似度获得,我们进一步利用语义信息对前60个结果进行重新排序,包括销量、percent conversion,、applause rate、用户画像等。我们利用Gradient Boost Decision Tree集成不同维数的相关描述特征,并利用Logistic回归将最终得分标到[0,1],既保证了外观相似度,又保证了语义相似度,保证了每个维数的重要性能被学到。在保留整体相似度的前提下,根据质量信息重新排序可以细化具有边属性的低质量图像列表。(这个就是使用一些语义信息再将上面得到的结果排序一遍)
4 EXPERIMENT
在本节中,我们将进行广泛的实验来评估系统中每个模块的性能。我们以GoogLeNet V1模型[17]作为分类预测和特征学习的基础模型,遵循3.1节和3.2节的协议。为了对视觉搜索中的每个成分进行评价,我们收集了与检索结果有着相同项标签的15万张最高召回图像。我们的高召回集涵盖了14类real-shot图像,如表1所示。我们在表1中用各种评估指标演示了统一体系结构中所有组件的端到端评估结果。

4.1 Evaluation of Category Prediction
我们进行了实验来评估我们的融合方法与基于模型的方法和基于搜索的方法的性能。在表1(A)中,我们表明我们的融合方法在分类准确率方面取得了更好的分类Accuracy@1。我们基于搜索的模型的平均Top-1 Accuracy为85.51%,略低于基于模型的88.86%。然而,基于搜索的方法比基于模型的方法在某些类别,如衬衫,裤子,包,获得更高的结果。总的来说,我们报告了用于类别预测的融合方法的Accuracy@1结果为91.01%,使基于模型的方法增加了2.15%。结果表明,基于模型的方法和基于搜索的方法具有互补性,融合方法纠正了基于模型的方法的一些错误分类。
4.2 Evaluation of Search Relevance
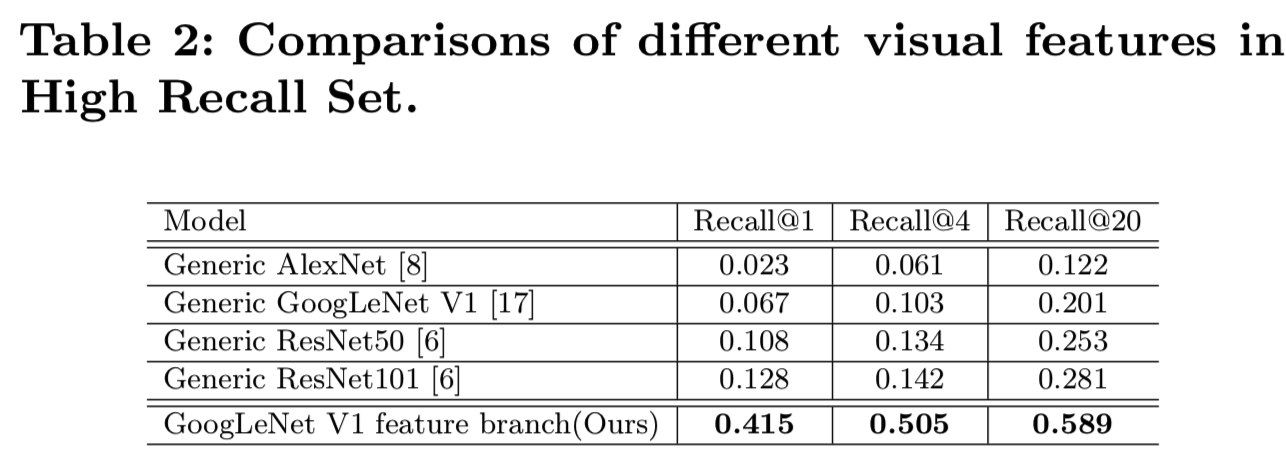
Effect of feature branch: 为了评价特征学习的性能,我们使用上面的高召回集作为查询集,在物品库存中搜索相似的图像。我们通过测量搜索相关性来评估学习到的特征。通过改变返回的K个top结果的数量,同一项的Recall@K将作为 Identical Recall metric。这意味着在前𝐾个检索结果,如果至少有一个返回图像与查询图像属于相同的项目,则查询被认为是正确分类。度量测量相关结果的数量,因为相同的项将产生最多可能的转换。作为基线,我们在图像上执行最新的基于模型的结果。我们最初的实验利用了来自原始通用模型(ImageNet的预训练模型)的特征[6,8,17]。我们根据模型的最后FC层的激活计算了Identical Recall@K(K=1,4,20)。表2显示了这些模型的Identical Recall性能。我们没有选择深度联合模型,而是只选择了使用我们的数据对整个图像进行微调的特征分支,与其他相比有了明显的改进。
此外,我们在表1(B)中报告了深层联合模型对所有类别的总体特征结果。对于所有的实验,我们对带有预测类别的20个相似图像计算得到 Recall@K(K=1,4,20)。我们的方法的Identical Recall随着𝐾增加而改善,这清楚地表明,我们的方法没有引入许多无关的图片到搜索的top结果中。与单一特征分支相比,采用联合检测和特征学习模型进行检索能够取得更好的性能。联合模型抑制了背景干扰,在所有类别中优于所有基线变体。
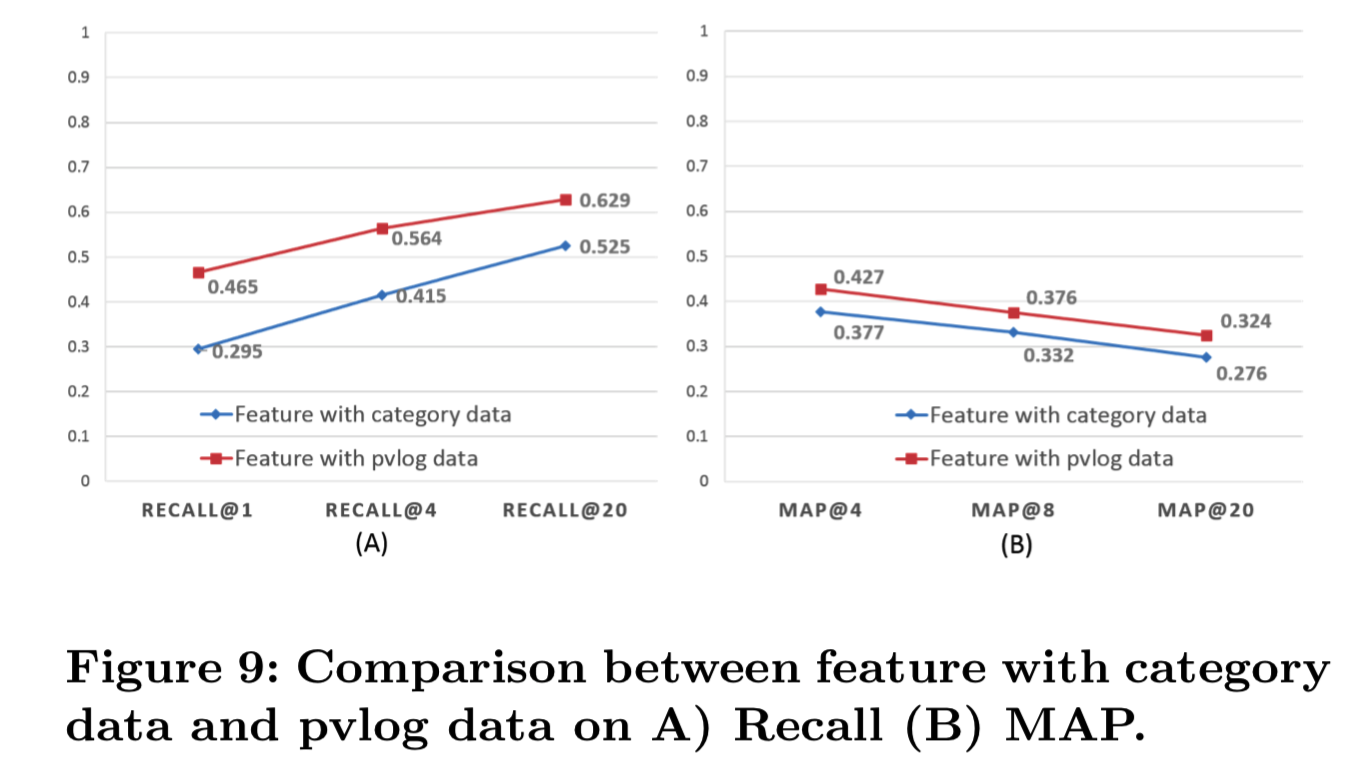
Effect of PVLOG triplets: 如3.2节所示,我们发现大多数点击的图像很可能是与查询图像相同的项,因此我们通过挖掘PVLOG图像来训练深层特征,形成有效的triplet,无需进一步的注释。为了评价PVLOG triplet的优越性,我们将其与使用类别数据进行类别预测训练的到的模型的FC层特征进行了比较。如图9(A)所示,我们将Identical Recall@1增加了17个百分点。在Mean Average Precision(MAP)度量上,我们观察到我们比类别数据的特征的MAP@1多了5%,说明我们得到了更好更相关的列表。
我们将进一步定性地确认我们的特征的细粒度识别能力。图8演示了对来自产品库存中的5个叶子家具类别的基于FC层的512维的语义特征使用tSNE[20]得到的embeddings。
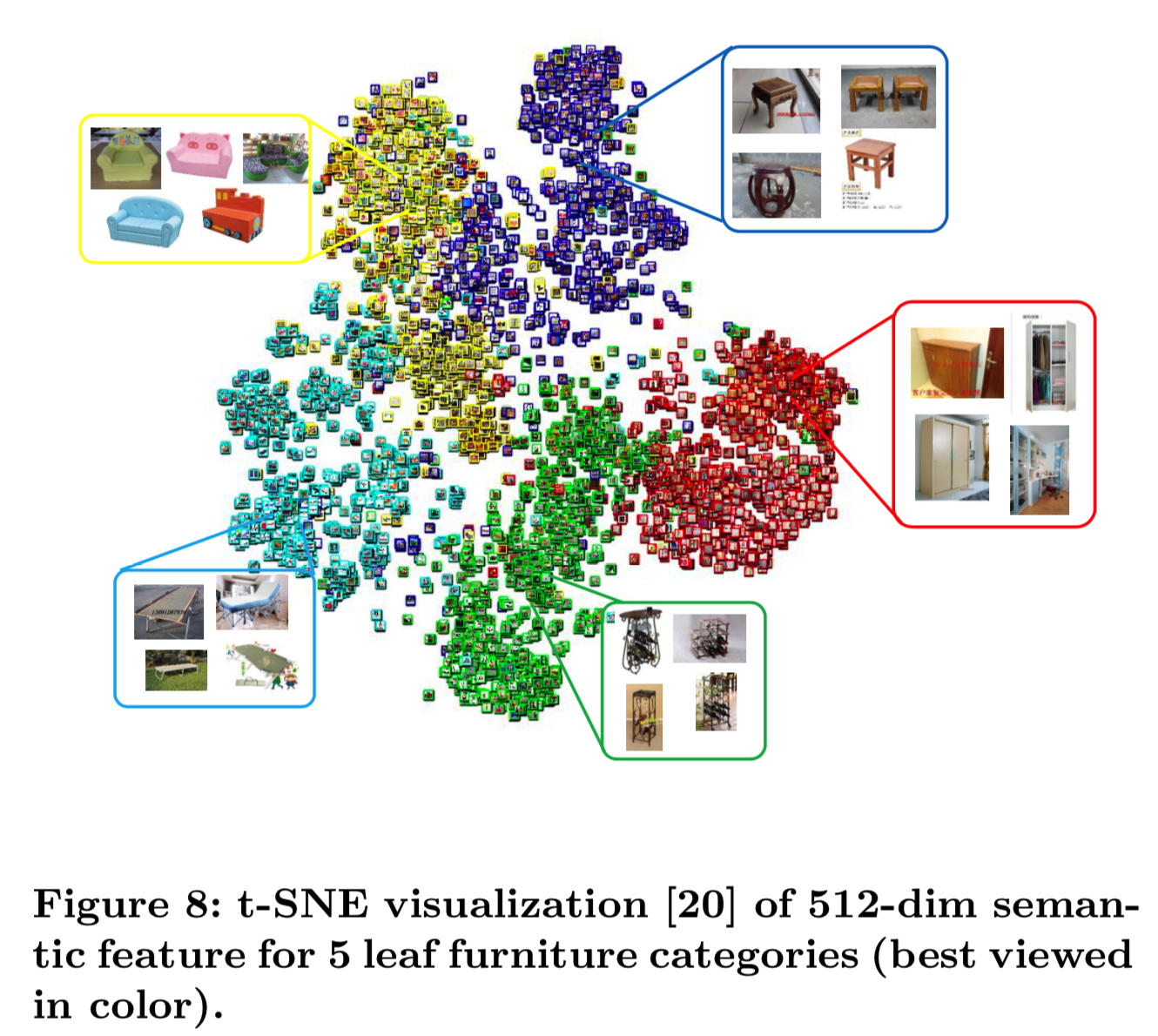
这从定性上加强了我们的主张,即我们的特征保留了语义信息和local neighborhood。对语义信息进行编码以减轻冲突的不良影响是很重要的,因为冲突中的项在语义上是相似的。
在图10中,我们可视化了real-shot查询图像的检索结果,它显示了相同项上令人满意的返回列表。

4.3 Evaluation of Object Localization
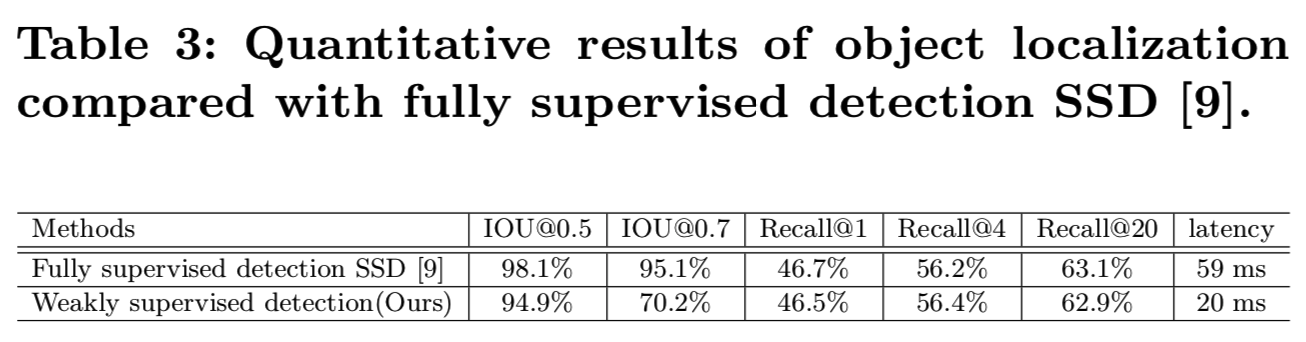
如表3所示,与groundtruth边界框相比,我们的深度联合模型定位结果得到IOU@0.5为98.1%、 IOU@0.7为70.2%的效果,仅略低于全监督检测SSD方法[9]。图11展示了对公共可用图像的检测结果,显示了学习的检测分支的识别能力和对象内容的捕获能力。同时,与全监督法相比,我们在不影响Identical Recall的情况下,以更快的速度获得了有竞争力的结果,实现了20ms的前向传播。

为了进一步解决性能问题,我们还可视化了所选对象的位置,这将在图10中定位fashion对象。从这些例子中,我们提取视觉和语义特征,以得到更好的检索图像列表。用户可以很容易地点击相同的物品进行查询并支付。
4.4 Evaluation of Indexing and Reranking
我们在表1(C)中展示了用于索引评估的Linear Recall算法,使用在30亿幅图像上,并对20万数据进行了粗糙过滤。我们用线性搜索的方式来比较索引结果的性能,其中我们将线性搜索的结果视为ground truth,并评估结果与groundtruth的近似程度。我们使用Linear Recall@K来衡量排名列表的质量和相关性。结果表明,与线性搜索相比,我们可以在Linear Recall@60范围内实现无损召回。我们还给出了几个主要组件的延迟。通过广泛的优化和利用云计算能力,给定一个用户查询,预测类别平均需要30ms(model+search),生成购物场景的图像特征embedding需要40ms。排序列表需要10ms到20ms来返回1200个项,因为粗糙过滤不依赖于类别的大小。质量相关的重新排序只需要5ms就能重新排名前60名的结果。因此,总延迟为数百毫秒,这为用户提供了一个可接受和愉快的购物体验。此外,我们通过部署表1(C)中的质量相关重新排序,对前60名进行了重新排序,实现了平均CVR参与度相对7.85%的提高。
5 CONCLUSIONS
本文介绍了阿里巴巴的端到端可视化搜索系统。采用有效的基于模型和基于搜索的融合方法进行分类预测。带分支的深度CNN模型是通过挖掘用户点击行为来进行联合检测和特征学习,不需要进一步的注释。作为移动端应用,我们也提出了二进制索引引擎,并讨论了如何降低开发和部署成本,提高用户参与度。在高召回集上的大量实验证明了我们的模块具有良好的性能。此外,我们的可视化搜索解决方案已经成功部署到Pailitao,并集成到阿里巴巴的其他内部应用中。在未来的工作中,我们将利用图像中的目标共分割和上下文约束来增强视觉搜索的相关性。

