
图像检索(image retrieval)- 2 - Deep Supervised Hashing for Fast Image Retrieval -1-论文学习
Deep Supervised Hashing for Fast Image Retrieval
Abstract
在本文中,我们提出了一种新的哈希方法来学习紧凑的二进制码,以便在大规模数据集上高效地检索图像。而复杂的图像外观变化仍然对可靠的检索构成巨大的挑战,根据在不同的视觉任务上学习鲁棒图像表征的卷积神经网络(CNN)的最新进展 ,本文提出了一种新的深度监督哈希(Deep Supervised Hashing,DSH)方法,为大规模数据集学习紧凑的similarity-preserving二进制编码。具体来说,我们设计了一种CNN架构,它以图像对(相似/不相似)作为训练输入,并鼓励每个图像的输出近似离散值(例如+1/-1)。为此,我们精心设计了一个损失函数,通过对来自输入图像对的监督信息进行编码,同时对实值输出进行正则化,以逼近所需的离散值,从而最大限度地提高输出空间的可辨识性。在图像检索中,新出现的查询图像通过输入网络进行编码,然后将网络输出量化成二进制编码表征,可以很容易地对其进行编码。在两个大规模数据集CIFAR-10和NUS-WIDE上进行的大量实验表明,与目前的研究相比,我们的方法具有良好的性能。
1. Introduction
近年来,互联网上每天都有数十万张图片被上传到网上,根据不同用户的要求寻找相关图片变得极为困难。例如,基于内容的图像检索检索,即得到与给定查询图像相似的图像,其中“相似”可能指视觉上相似或语义上相似。假设数据库中的图像和查询图像都用实值特征表示,寻找相关图像的最简单方法是根据数据库图像在特征空间中与查询图像的距离对数据库图像进行排序,并返回最接近的图像。然而,对于拥有数百万幅图像的数据库,即使是在数据库中进行线性搜索,也会耗费大量的时间和内存。
为了解决实值特征效率低的问题,提出了一种哈希方法,将图像映射到紧凑的二进制编码中,可以近似地保留原始空间中的数据结构[27,9,17]。由于图像采用二进制编码而不是实值特征表示,大大减少了搜索的时间和内存开销。然而,现有的大多数哈希方法的检索性能在很大程度上依赖于所使用的特征,这些特征基本上是无监督提取的,因此更适合于处理视觉相似度搜索,而不是语义相似度搜索。另一方面,近年来在图像分类[12,25,8]、目标检测[26]、人脸识别[24]等许多视觉任务[18,2]的研究进展显示出CNN神经网络令人印象深刻的学习能力。在这些不同的任务中,网络神经网络可以被看作是一个特征提取器,该特征提取器由专门为单个任务设计的目标函数指导。网络神经网络在各种任务中的成功应用表明,尽管图像存在显著的外观变化,但网络神经网络学习到的特征能够很好地捕捉图像的底层语义结构。
受CNN特性的鲁棒性启发,我们提出了一个利用CNN结构的二进制编码学习框架,名为深度监督哈希(Deep Supervised Hashing,DSH)。在我们的方法中,我们首先设计了一个CNN模型,它将图像对以及表示两幅图像是否相似的标签作为训练输入,并生成二进制编码作为输出,如图1所示。在实际操作中,我们在线生成图像对,以便在训练阶段使用更多的图像对。损失函数的设计目的是将相似图像的网络输出拉到一起,将不同图像的输出推开,使学习的hamming空间能够很好地逼近图像的语义结构。为了避免对hamming空间的不可微损失函数进行优化,将网络输出放宽为实值,同时使用正则化器使实值输出逼近期望的离散值。在这个框架下,图像可以很容易地编码,首先通过网络传播,然后量化网络输出的二进制编码表征。
本文的其余部分组织如下:第2节讨论与我们的方法相关的工作。第3节详细描述了DSH。第4节在两个大数据集上广泛地评价了提出的方法。第5节作结束语。

2. Related Works
许多哈希方法[4,28,13,27,6,20,17,22,16,23,15,29,31,14]由于其较低的时间和空间复杂度,已经被提出来提高近似最近邻搜索的性能。在早期,研究人员主要关注于数据无关的哈希方法,如称为局部性敏感哈希(Locality Sensitive Hashing,LSH)[4]的一组方法。LSH方法使用随机投影产生哈希位。理论上证明了随着码长的增加,两个二进制码之间的hamming距离在特征空间中渐近于对应的距离。然而,LSH方法通常需要很长的编码才能达到令人满意的性能,这就需要大量的内存。
为了产生更紧凑的二进制码,提出了依赖数据的哈希方法。这些方法尝试从训练集学习保持相似的哈希函数。这些方法可以进一步分为无监督方法和有监督(半监督)方法。无监督方法只利用无标记的训练数据来学习哈希函数。例如,光谱哈希(Spectral Hashing, SH)[28]使图像对的加权汉明距离最小化,其中权值定义为图像对的相似度度量;迭代量化(Iterative Quantization,ITQ)[6]试图最小化投影图像描述符的量化误差,以缓解实值特征空间与二值汉明空间的差异造成的信息损失。
为了处理更复杂的语义相似度,提出了利用标签信息如类别标签的监督方法。CCA-ITQ[6]是ITQ的扩展,它使用标签信息为图像描述符找到更好的投影;可预测的判别二进制码(Predictable Discriminative Binary Code, DBC)[22]寻找能分割具有大边际的类别的超平面作为哈希函数;最小损失哈希(Minimal Loss Hashing,MLH)[20]优化了hinge-like损失的上界,以学习哈希函数。另一方面,半监督哈希(Semi-Supervised Hashing,SSH)[27]利用大量的未标记数据来规范化哈希函数。上述方法使用线性投影作为哈希函数,很难处理线性不可分的数据。为了克服这一局限性,提出了带核的监督哈希(Supervised Hashing with Kernels,KSH)[17]和二进制重构嵌入(Binary Reconstructive Embedding,BRE)[13]哈希函数,在核空间中学习保持相似的哈希函数 ; 深度哈希(Deep Hashing,DH)[3]利用非线性深度网络产生二进制编码。大多数哈希方法在优化时将二进制码放宽为实数,并将模型输出量化以生成二进制码。但是,不能保证最优实值编码在量化后仍然是最优的。所以提出了离散图哈希(Discrete Graph Hashing,DGH)[16]和监督离散哈希(Supervised Discrete Hashing,SDH)[23]等方法直接对二进制码进行优化,克服了松弛法的缺点,提高了检索性能。
虽然上述的哈希方法在一定程度上取得了成功,但它们都使用了手工制作的特征,无法捕获真实数据中巨大的外观变化下的语义信息,从而限制了学习的二进制编码的检索精度。为了解决这个问题,最近,几种基于CNN的哈希方法[31,14,29,15,30]被提出来,使用前景良好的CNN学习图像表征和二进制编码。[31, 14, 30]强制网络学习保留triplets图像语义关系的类二进制输出;[29]训练一个CNN来拟合由pairwise相似度矩阵计算出的二进制编码;[15]以类二进制隐藏层作为图像分类任务的特征训练模型。这些方法将图像特征提取与二进制编码学习相结合,大大提高了检索精度。然而,这些方法在训练目标上仍然存在一些缺陷,这限制了它们的实际检索性能,我们将在实验中详细说明。此外,他们用来近似量化步骤的非线性激活以可能减慢网络训练[12]为代价进行操作。
3. Approach
我们的目标是学习图像的紧凑二进制编码,这样:(a)相似的图像应该被编码到汉明空间相似的二进制编码,反之亦然;(b)二进制编码可以有效地计算。
尽管已有许多哈希方法被提出来学习保持相似性的二进制编码,但它们都受到手工特征或线性投影的限制。强大的非线性模型被称为CNNs,它促进了最近计算机视觉社区在各种任务上的成功。为此,我们提出使用如图1所示的CNN去同时学习可辨别的图像表征和紧凑的二进制编码,可以突破手工特征和线性模型的局限性。我们的方法首先使用图像对和相应的相似度标签来训练CNN。在这里,损失函数被精心设计来学习保持相似的类二值图像表征。然后对CNN输出进行量化,生成新的图像的二进制编码。
3.1. Loss Function
让![]() 表示RGB空间,我们的目标是学习一个从
表示RGB空间,我们的目标是学习一个从![]() 映射到k-bits二进制编码的:
映射到k-bits二进制编码的:![]() ,使相似的(无论是在视觉上相似的还是在语义上相似的)图像被编码成相似的二进制编码。为了达到这一目的,相似图像的编码应该尽可能的接近,不同图像的编码应该远离。基于这个目标,loss函数自然被设计成将相似图像的编码拉到一起,将不同图像的编码推开。
,使相似的(无论是在视觉上相似的还是在语义上相似的)图像被编码成相似的二进制编码。为了达到这一目的,相似图像的编码应该尽可能的接近,不同图像的编码应该远离。基于这个目标,loss函数自然被设计成将相似图像的编码拉到一起,将不同图像的编码推开。
具体地说,一副图像I1、I2∈Ω,对应的二进制网络输出为 b1, b2∈{+ 1−1}k, 如果他们是相似的,我们定义y = 0,否则和y = 1。对两幅图像的损失定义为:
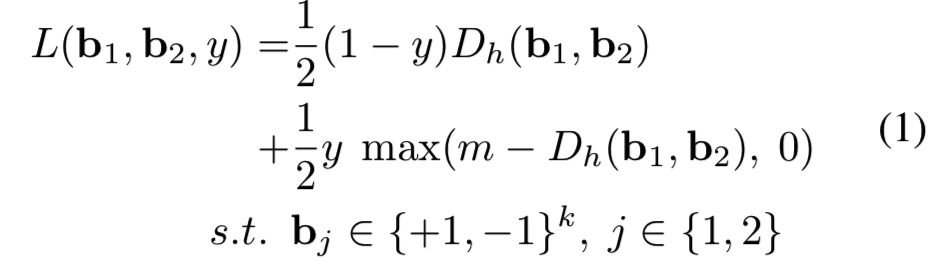
其中Dh(.,.)表示两个二进制向量之间的hamming距离,m > 0是一个边际阈值参数。第一项惩罚映射到不同的二进制编码的相似图像,第二项在映射到相近二进制编码的不相似图像的hamming距离低于边际阈值m时进行惩罚。这里值得注意的是,为了避免崩溃,我们的损失函数采取了类似[7]的contrastive损失,只有那些距离在一个半径内的不相似图像对有资格贡献自己的损失函数(其实就是差距过大的不相似图像对训练网络没什么用)。
假设这里有N对随机从训练图像![]() 中采样的训练图像对,我们的目标是最小化总体的损失函数:
中采样的训练图像对,我们的目标是最小化总体的损失函数:
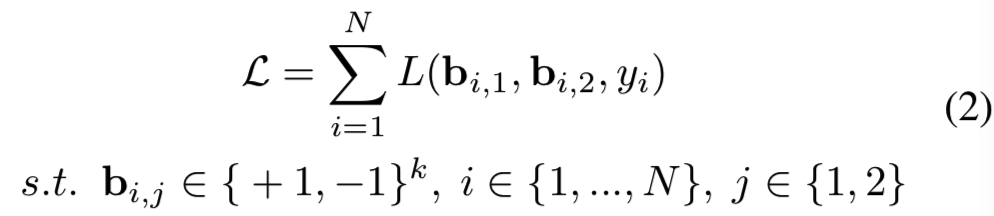
3.2. Relaxation
直接优化等式(2)可能更好,但由于bi,j的二值约束要求对网络输出进行阈值化(如用signum函数),使得用反向传播算法训练网络变得棘手,因此不可行。最近的一些研究[23,16]提出了直接优化二进制编码的方法,但是由于内存的限制,CNN模型只能通过小批量进行训练,当批量大小相对于整个训练集非常小时,生成的二进制编码的最优性存在问题。
另一方面,如果完全忽略二进制约束,则会由于欧几里得空间和汉明空间的差异而导致二进制编码效果次优,而不是最优。一个常用的松弛方案是利用sigmoid或tanh函数来逼近阈值化过程(即+1,-1)。然而,使用这种非线性函数将不可避免地减慢甚至抑制网络[12]的收敛。为了克服这种限制,在本研究中,我们提出在实值网络输出上加一个正则化器,以接近期望的离散值(+1/-1)。其中,我们将Eqn.(1)中的汉明距离替换为欧几里得距离,并附加一个正则化器来替换二进制约束,则等式(1)改写为:

其中下标r为松弛损失函数,1为值全1的向量,||·||1为向量的L1范数,|·|为基于元素的绝对值运算,α为控制正则化器强度的加权参数。
这里我们使用L2范数来度量网络输出之间的距离,因为低阶范数产生的子梯度将不同距离的图像对平等对待,没有利用到不同距离大小所涉及的信息。虽然高阶范数也是可行的,但同时会产生更多的计算量。对于正则化器,我们选择了L1范数而不是高阶范数,因为它的计算量小得多,有利于加快训练过程。
通过将等式(3)代入等式(2),我们将重新定义的总损失函数改写为:
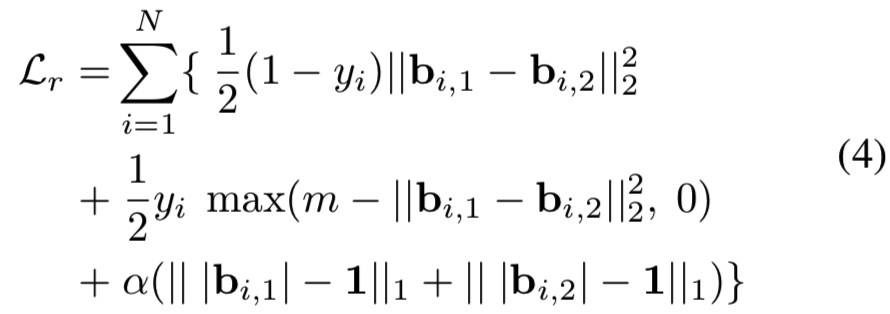
针对此目标函数,采用小批量梯度下降法的反向传播算法对网络进行训练。为此,等式(4)关于bi, j,∀i, j的梯度需要计算。由于目标函数中的max运算和绝对值运算在某些点上不可微,因此我们改用子梯度,并将这些点上的子梯度定义为1。等式(4)前两项的子梯度和第三项(即正则化器)的子梯度分别改写为:

这是基于元素的。通过在mini-batch上计算子梯度,可以以标准方式完成其余的反向传播。
Discussion: 在这样的框架下,用sign(b)很容易得到图像的二进制编码。注意,与现有的基于CNN的哈希方法[29,15,14,31,30]不同,我们的方法没有使用饱和非线性,例如tanh或sigmoid来近似量化步骤,因为这些非线性可能会减慢训练过程[12]。第4.2节中的实验将验证该归一化器相对于饱和非线性的优势。
3.3. Implementation details
Network parameters: 我们的DSH方法是用Caffe[10]实现的。网络结构如图1所示,它由三个卷积池层和两个全连接的层组成。卷积层分别使用32、32和64个步长为1的5×5的filter, pooling使用步长为2的3×3的window。第一个全连接层有500个节点,第二个全连接层有k个节点,其中k为二进制编码的长度。所有卷积层和第一个全连接层后均配置ReLU[19]。
权重层使用“Xavier”初始化[5]进行初始化。在训练期间,batch size被设置为200,momentum为0.9,权重衰减为0.004。初始学习率设置为10-3,每20,000次迭代(共150,000次迭代)后降低40%。等式(4)中的边际m被启发式地设置为m = 2k,以鼓励不同图像的编码差异不小于k/2 bits。
Training methodology: 一种直观的训练网络的方法是使用Siamese结构[7]和离线生成图像对。然而,在这样的方案下,处理n幅图像只能产生n/2个有效图像对,存储这些图像对会占用很大的空间。为了更好地利用计算资源和存储空间,我们建议利用每个小批处理中的所有唯一图像对在线生成图像对。为了跨batches覆盖这些图像对,在每次迭代时从整个训练集中随机选取训练图像。这样,我们的方法减少了存储整个成对相似矩阵的需要,因此可扩展到大规模数据集。
此外,为了学习对应于不同编码长度的模型,如果一个人选择从头开始训练每个模型,这将是种严重的浪费,因为前面的层可以被这些模型共享。此外,随着代码长度的增加,模型在输出层会包含更多的参数,从而容易发生过拟合。为了克服这种限制,我们建议先训练一个输出层节点较少的网络,然后对其进行微调,得到具有所需编码长度的目标模型。
4. Experiments
省略
5. Conclusion
我们将DSH的检索性能归功于三个方面:第一,利用非线性特征学习和哈希编码的耦合来提取特定任务的图像表征;其次,所提出的用于减小实值网络输出空间与期望汉明空间误差的正则化器;第三,在线生成了密集的成对监督来很好地描述期望的汉明空间。在效率方面,实验表明,该方法比传统的散列方法编码新图像的速度更快。由于我们目前的框架是相对通用的,更复杂的网络结构也可以很容易地利用。此外,本研究中对“网络集成”的初步研究证明,这是一种很有前途的方法,值得我们进一步研究,以提高检索性能。

