
styleGAN相关论文 - Closed-Form Factorization of Latent Semantics in GANs - 1 - 论文学习
Closed-Form Factorization of Latent Semantics in GANs
Abstract
在经过训练的用于合成图像的生成对抗网络(GANs)的潜在空间中,出现了丰富的语义属性。为了识别这些用于图像操纵的潜在语义,以往的方法首先对一组合成样本进行注释,然后在潜在空间中训练监督分类器。但是,它们需要明确的目标属性定义以及相应的手工注释,这严重限制了它们在实践中的应用。在这项工作中,我们检查了GANs学习的内部表征,以无监督的方式揭示潜在的变量因素。通过研究将潜在编码作为GANs生成器输入的全连接层的本质作用,我们提出了一种用于潜在语义发现的Closed-Form Factorization方法。进一步从理论和实证两方面分析了所识别的语义的性质。通过快速高效的实现,我们的方法不仅能够像最先进的监督方法那样精确地发现潜在语义,而且还能够在多个训练在广泛的数据集的GAN模型上产生更加通用的语义类。
1 Introduction
生成对抗网络(GANs)[8]在图像合成方面取得了巨大的成功。最近的研究[7,14,23,21,25]发现,在学习合成图像时,GANs会自发地在潜在空间中表示多个可解释属性,如人脸合成[23]的性别,场景合成[25]的光照条件。通过正确地识别这些语义,我们可以重用GANs学习到的知识来合理地控制图像生成过程,从而实现广泛的编辑应用,如人脸处理[23,9]和场景编辑[25,27]。
解释GANs的潜在空间的关键是找到与人类可理解属性[7,14,23,21,25]对应的有意义子空间。通过这种方法,将潜在编码向某个子空间的方向移动,可以相应地改变合成图像中出现的语义。然而,由于潜在空间的高维性和图像语义的多样性,在潜在空间中寻找有效的方向是极具挑战性的。现有的基于监督学习的方法通常首先随机抽取大量的潜在代码,然后合成一组图像,并在这些图像上标注一些预定义的标签,最后利用这些标记的样本在潜在空间中学习一个分离边界。为了得到用于训练边界的标签,他们要么引入预先训练好的语义预测器[7,23],要么利用图像的一些简单统计信息(如物体位置和色调)[14,21]。
以前的语义发现方法在很大程度上依赖于预定义的语义和注释样例的准备,从而产生了一些关键性的限制。一方面,依赖于预定义的语义会阻碍算法应用于语义预测器缺失的情况。另一方面,采样是不稳定的,因此不同的综合集合可能导致不同的边界搜索。此外,为了识别一些罕见的属性,需要生成相当大数量的样本,以确保获得足够多的正例进行边界训练,这可能非常耗时,而且会有偏差。因此,我们没有利用合成的样本作为中间步骤,而是直接研究GANs的生成机制来解释其内部表示。更具体地说,对于所有基于神经网络的GAN架构,总是采用全连接层作为第一步,将输入的潜在代码带入生成器。它提供了将潜在空间投射到转换空间的驱动力。这种变换实际上滤掉了潜在空间中一些可以忽略的方向,突出了对图像合成至关重要的方向。如果我们能够识别出这些重要的潜在方向,我们就能够控制图像生成过程,即编辑合成图像的语义。
为此,我们提供了一种新的、简单的closed-form方法,称为SeFa,用于GANs中的潜在语义分解。与现有方法中常用的三步流水线(即采样、标记和边界搜索)不同,我们的算法仅使用GAN模型的学习权重进行语义发现。广泛的实验表明,我们的方法能够以极其快速和有效的实现(即不到1秒)来识别通用的潜在语义。图1展示了一些操作示例,我们可以在不知道其底层3D模型或姿态标签的情况下旋转图像中的对象。与现有的监督方法和一些最近的无监督基线相比,我们的方法能够在更大范围内更准确地识别可解释的维度。此外,我们的方法是通用的和灵活的,因此它可以很好地支持在多个GAN模型(例如,PGGAN [15], StyleGAN [16], BigGAN[4],和StyleGAN2[17])中发现可理解的语义,这些模型在广泛的数据集上训练,如图1所示。

1.1 Related Work
Generative Adversarial Networks. 近年来,GAN[8]在图像合成方面取得了显著进展[22,2,15,4,16,17]。GANs中的生成器能够以随机采样的潜码作为输入输出高保真图像。现有的GAN模型通常建立在深度卷积神经网络[22]上。为了将潜码带入生成器,我们使用全连接层从卷积层开始的地方将潜码映射为初始特征映射[22,2,15]。最近,基于风格的生成器对这一思想进行了改进[16,17],其中潜码被映射成分层风格代码,然后通过自适应实例归一化(AdaIN)[13]馈入每个卷积层。在本例中,将完全连接层转换为样式映射仍然是生成器处理潜在代码的第一步。
Latent Semantic Interpretation. 生成模型显示了从数据中以无监督的方式学习变化因素的巨大潜力。Chen et al. [5] 和 Higgins et al. [12] 提出添加正则化器到训练过程中显式地学习表示一个可解释的因素表征,但因素的数量应该是在训练前预定义的,且如果他们适用于最近的高保真图像合成模型,像StyleGAN[16],该因素数量是未知的,。最近的研究发现无条件GANs在中间特征映射[3]和初始潜在空间中自动编码各种语义[7,14,23,25]。通过正确地识别这些语义,我们能够忠实地控制图像生成过程。然而,现有的方法需要准备一组合成图像,对这些图像进行语义评分,然后使用图像-评分对进行监督语义搜索,这受到现有语义预测器的严重限制。一些并行工作研究了GANs中的无监督语义发现。Voynov和Babenko[24]将InfoGAN[5]提出的正则化器引入到语义搜索过程中,但需要预定义的语义数量。Harkonen等人[10]提出跳过标记过程,对采样数据进行主成分分析,寻找潜在空间中的主要方向。但是,这两种方法都是基于大量的数据抽样。不同的是,我们提出了一种潜在语义解释的Closed-Form Factorization方法,它独立于抽样,也不需要任何预先监督的信息,如语义标签或分类器。
2 Methodology
2.1 Problem Statement
在GAN中的生成器G(.)学习将d维的潜在编码![]() 映射到一个高维的图像空间
映射到一个高维的图像空间![]() 。这里
。这里![]() 分别表示输入潜在编码和输出图像。这里有两种常见的方法去输入一个向量z到生成器中,如图2所示。
分别表示输入潜在编码和输出图像。这里有两种常见的方法去输入一个向量z到生成器中,如图2所示。
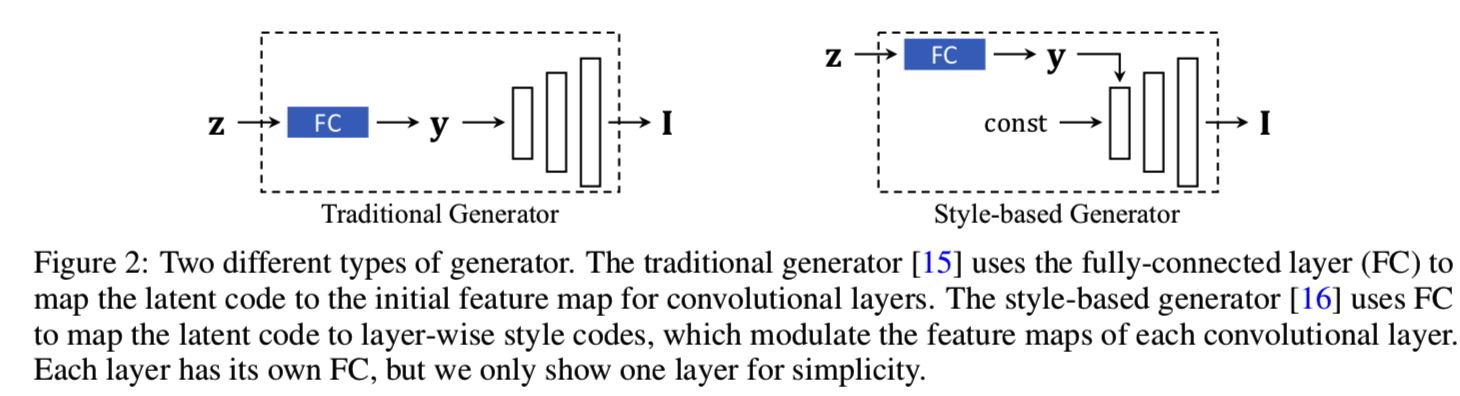
一种是将z映射为一个卷积层开始的特征映射[22,15],另一种是将z映射为基于layer的风格编码,通过AdaIN[16,17]控制每个卷积层的输出特征映射。这两种方法都需要由全连接层(FC)实现的线性投影来实现映射。因此,我们将生成过程重新表示为:
![]()
其中G'(.)表示生成器除了一开始的可学习FC层的剩下部分。
GANs的潜在空间已经被证明可以用向量算术性质[22]来编码丰富的语义知识[7,14,23,25]。这种矢量运算特性通常是通过将潜码向一定方向移动来实现的
![]()
其中![]() 表示对应于某个属性的方向,α即移动步长。之后,出现在输出图像
表示对应于某个属性的方向,α即移动步长。之后,出现在输出图像![]() 中的寓意将会相应地有所不同。在这项工作中,我们的目标是在无监督的方式下找到语义上有意义的方向n。
中的寓意将会相应地有所不同。在这项工作中,我们的目标是在无监督的方式下找到语义上有意义的方向n。
2.2 Unsupervised Semantic Factorization
从等式(2)中我们观察到语义实际上是由潜在方向n决定的,它独立于采样编码z,换句话说,我们希望找到能最大程度引起 I 移位的n,而不是z。根据等式(1),G'(·)是固定的,所以 I 的变化取决于y。在这里,我们做一个假设,一个大y的变化将导致 I 大量内容的变化。从这个角度来看,我们的目标变成寻找会导致y的重大变化的方向n。
为了更好地模拟n和y之间的关系,我们重新讨论了由连接潜在编码和生成器的完全连接层实现的线性投影。![]() 分别表示权重和偏差,其中m是投射空间的维度。然后,我们有
分别表示权重和偏差,其中m是投射空间的维度。然后,我们有![]() 。在使用等式(2)调试潜在编码后,我们可以计算潜在编码的变化:
。在使用等式(2)调试潜在编码后,我们可以计算潜在编码的变化:
![]()
从等式(3)中可以看出,要使y发生较大的变化,需要找到一个方向,使这个方向在A的“投影”后产生较大的范数。直观上,全连接层(A)中的这种转换起到了本质的“语义选择器”作用。对于在潜在空间中编码的任何语义(n),它都必须经过这个选择器才能在最终的合成(I)中反映出来。因此,我们通过解决下面的优化问题,将这个投影分解作为探索潜在语义的指导:
![]()
其中|| · ||2表示L2范数。这里设置α=1,对所有方向使用单位向量来保证他们是可比较的
上面是只寻找一个语义方向,如果变成寻找k个最重要的语义方向{n1, n2, ... , nk},等式(4)变为:
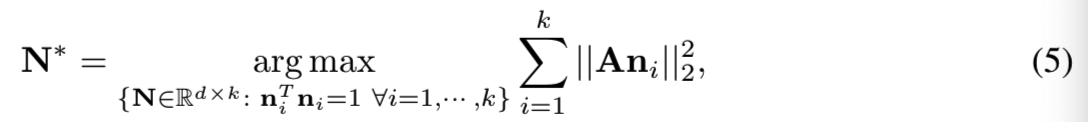
其中N= {n1, n2, ... , nk}表示top-k的语义
为了解决该问题,这里介绍Lagrange Multiplier(拉格朗日乘数法):
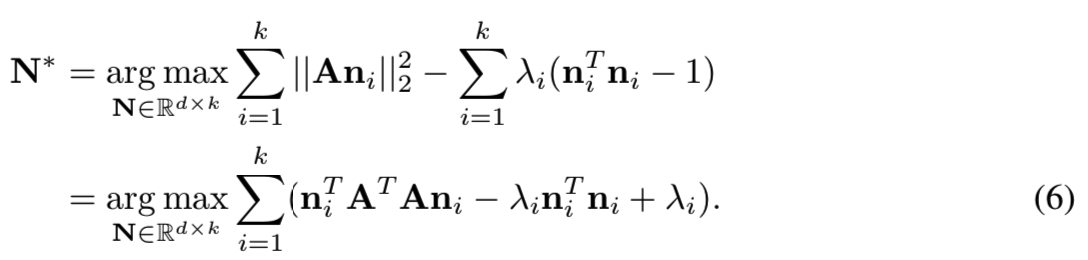
通过对每个ni求偏导,我们得到:
![]()
从等式(7)可见所有可能的解决方案应该是矩阵ATA的特征向量。因此,为了得到最大的目标函数值,并让![]() 互相之间是可区分的,我们选择N的列作为与k个最高特征值有关的ATA的特征向量
互相之间是可区分的,我们选择N的列作为与k个最高特征值有关的ATA的特征向量
2.3 Property of the Discovered Semantics
在这一部分中,我们将讨论已发现语义的一些重要性质。如2.2节所述,所有语义方向都是矩阵ATA的特征向量,A为正半定。因此,我们总是有特征分解:
![]()
其中Λ是对角矩阵,表示特征值,Q为正交矩阵,包含所有的特征向量。
很明显,每个ni都是Q的列。因此有NTN = Ik,其中 Ik表示k维恒等矩阵。其意味着我们的算法找到的所有语义方向在编码空间中互相都是正交的。所以有:
![]()
这意味着FC的输出在不同方向上的变化也是相互正交的。基于这两个观察,我们希望与![]() 相关的语义互相之间是解耦合的
相关的语义互相之间是解耦合的
3 Experiments
在本节中,我们对所提出的方法的有效性进行了实证评估。在进入细节之前,我们首先介绍在这项工作中使用的模型和数据集以及实现细节。
Models and Datasets. 我们对最先进的GAN模型进行了广泛的实验,包括PGGAN[15]、StyleGAN[16]、BigGAN[4]和StyleGAN2[17]。他们在不同的数据集上接受训练,包括人脸(CelebA-HQ[15]和FF-HQ[16])、动画人脸[1]、场景和物体(LSUN[26])、街景[19]和ImageNet[6]。为了对人脸进行定量分析,我们使用ResNet-50[11]在CelebA数据集[18]上训练一个属性预测器,遵循之前的工作[23]。
Implementation Details. 对于PGGAN,我们将算法应用到FC的第一层。对于使用基于样式生成器的StyleGAN和StyleGAN2,我们选择每个卷积块的样式映射层。我们的算法可以灵活地解释所有或任何特定的层。具体地说,我们将所有目标层的权重矩阵沿第一个轴连接起来,从而得到一个更大的矩阵。注意,除了潜在空间Z,styleGAN引入了一个更解耦合的空间W[16]。我们在StyleGAN和StyleGAN2的W空间上做实验,因为w∈W是输入生成器的代码,而不是z∈Z。BigGAN将潜在代码映射到初始特征映射和分层样式,我们选择将所有这些全连接层的权重组合在一起。由于BigGAN使用了一个扩展到潜码的嵌入向量,用于条件合成,我们只使用与潜码部分(即前半列)相关的权重参数。在进行特征分解之前,我们对权矩阵A的每一行进行归一化,因为我们更关注方向而不是距离。
3.1 Comparison with Unsupervised Baselines
Post-Annotation of the Discovered Semantics. 在获得潜在的语义方向之后,我们需要通过赋予它们可解释的含义来使它们与人类的感知相一致。这里,我们使用现有的监督方法,即InterFaceGAN[23]找到的语义方向作为“ground truth”。对于一个特定的属性,我们将算法中的所有特征方向与“ground-truth”方向进行比较,并选择余弦距离最小的方向。表1显示了结果,我们可以看到,使用我们的方法,在传统生成器(PGGAN[15])和基于风格的生成器(StyleGAN[16])上,姿势、年龄和性别都作为主要方向出现。微笑语义不会引起图像的明显变化(即只有嘴部变化),因此不具有高特征值。但是我们的方法仍然可以发现这种变化。
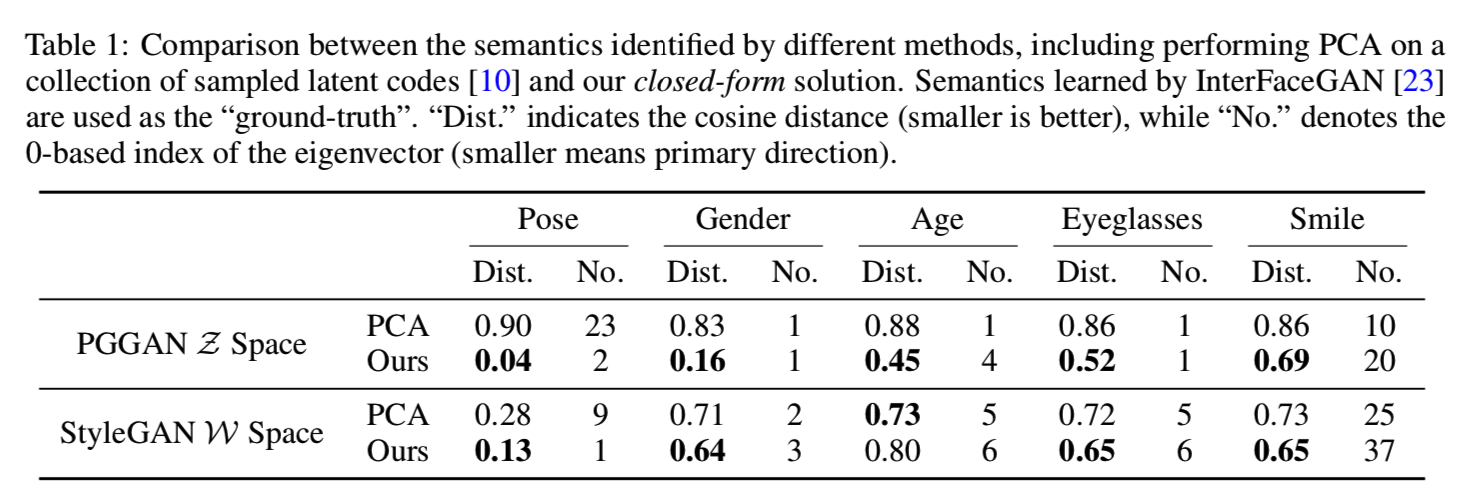
Comparison with Sampling-based Unsupervised Baseline. 然后,我们将我们的方法与基于采样的无监督基线进行比较,后者是首先对一组潜在代码进行采样,然后对这些样本进行PCA(主成分分析),以找到主要方向[10]。这里,我们使用500K样本进行PCA。从表1可以看出,基于采样的方法在传统的生成器上是失败的,因为潜码只是服从正态分布。对正态分布的数据进行PCA不能给出有意义的方向。同时,我们的方法在StyleGAN的W空间上也取得了较好的结果。例如,姿态pose在PCA中被识别为第9个方向,而在我们的算法中被识别为第1个方向。此外,我们的方法显示了一个与“ground truth”较小的距离。值得一提的是,我们的方法不依赖于采样数据,因此更加稳定。我们还在图3中显示了一些定性结果。我们可以看到,我们的结果(行(b))更接近那些由监督方法InterFaceGAN(行(c))取得的结果。例如,当使用StyleGAN上的PCA编辑pose时,身份和发型会发生变化(row (a))。

Comparison with Learning-based Unsupervised Baseline. InfoGAN[5]提出了以无监督的方式显式地学习因数分解表示。我们将我们的方法与通过添加正则化器使互信息[20]最大化的PGGAN模型进行比较,如图4所示。我们有两个主要优势。首先,InfoGAN要求在训练过程之前知道factor的数量。如果我们想要添加更多的语义,模型应该从头开始重新训练。其次,我们的算法识别由GANs自动学习的语义,它比附加的正则化器学习的语义更准确。以图4中的姿态操作为例,使用Info-PGGAN进行编辑时,头发颜色会发生变化。

3.2 Comparison with Supervised Approach & Semantic Property Analysis
我们将我们的算法与用于发现潜在语义的最先进的监督方法(InterFaceGAN[23])进行比较,从(a)的视角查看不同的语义如何互相解耦合,以及(b)的视角看如何识别语义的多样性。
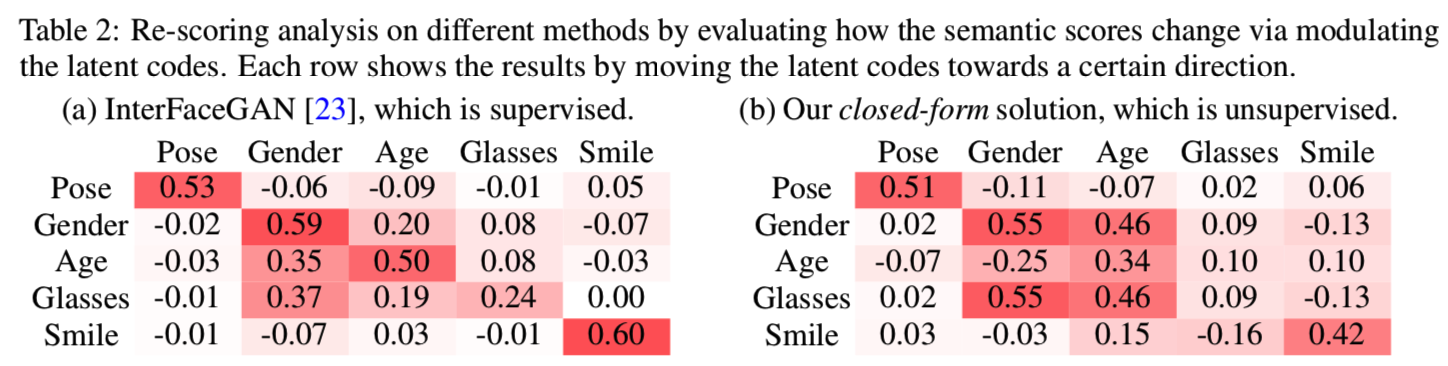
Disentanglement Comparison. 我们执行重评分分析,以定量地评估不同语义之间的解耦性。具体来说,我们首先随机抽取2000幅图像,然后按照一定的语义方向对它们进行操作,最后使用预先训练好的属性预测器来检查在操作过程中不同属性对应的分数有何变化。表2为比较结果。我们可以看到,我们的非监督发现的语义显示了类似于监督方法的解耦属性。例如,姿势和微笑几乎独立于其他三个属性,而性别,年龄,眼镜是高度相互纠缠的。一个有趣的观察是,当使用InterFaceGAN操作年龄和性别时(表2(a)),性别得分总是增加。然而,使用我们的方法(表2(b)),性别得分在操纵性别时增加,而在操纵年龄时减少。这是因为即使我们的算法也不能完美地将年龄和性别分离(这可能是由于数据偏差[23]造成的),边界本身就被分离了,正如2.3节所证明的那样。例如,“男性化+老龄化”和“女性化+老龄化”在潜在空间中也是两个正交的方向。此外,我们的方法识别的方向的标签是使用InterFaceGAN分配的(见第3.1节),它不是100%准确的。比如,性别和眼镜被分配到同一个方向。如果我们手工标记这些方向,可能会导致更好的解耦性。
Diversity Comparison. 监督方法高度依赖于可用的属性预测器。相比之下,我们的方法更通用,能够找到更多样化的语义。如图5(a)所示,我们成功地识别出了发色、发型、肤色对应的方向。由于这些属性的预测器在实践中是不容易获得的,这就超越了TnterFaceGAN方法。此外,监督方法通常受到训练目标的限制。例如,InterFaceGAN被提出来处理二进制属性。相比之下,我们的方法可以识别更复杂的属性(例如多个特征方向控制同一个属性),如图5(b)中的不同发型。

Real Image Manipulation. 在InterFaceGAN[23]之后,我们将GAN反演[9,27]方法引入到这项工作中,以实现真实的图像处理。更具体地说,给定一个要编辑的目标图像,我们首先将其投影回潜在代码,然后使用发现的潜在语义来调整反向代码。图6给出了一些例子。我们可以看出,通过我们的closed-form方法找到的语义足够精确,可以操纵真实的图像。例如,我们设法在输入图像(图6第四列)中添加眼镜或删除眼镜。

3.3 Generalization to Other GAN Models
在这一部分中,我们通过将我们的算法应用于在不同数据集上训练的各种最先进的GAN模型来验证我们算法的泛化能力。
Layer-wise Interpretation on StyleGAN and StyleGAN2. 我们的算法是通用的和灵活的,这样它可以用来解释新型基于风格生成器[16,17]的部分层。从动画人脸、猫、汽车、教堂和街景中识别出的层次语义如图7所示。回想一下,我们没有与这些语义对应的属性预测器。我们还进行了一项用户研究,通过在每个层次上操作前50个特征方向的图像,询问人们有多少方向会导致明显的内容变化,以及有多少方向是有语义意义的。表3表明,我们的closed-form解决方案确实可以找到解释因素,甚至可以从GAN模型的某些特定层中找到解释因素。


Results on Conditional BigGAN. 我们还解释了大型BigGAN[4]模型,该模型在ImageNet[6]的1000个类上有条件地进行了训练。注意BigGAN将一个类别衍生的嵌入向量与潜在代码连接起来,以实现条件合成。在这里,我们只关注语义发现的潜在代码部分。从图8可以看出,我们的闭型算法发现的语义可以忠实地应用于不同类别的图像处理。这验证了该方法的泛化能力。

4 Conclusion
在这项工作中,我们提出了一个closed-form的解决方案SeFa,分解GANs所学习的潜在语义。大量的实验证明了我们的算法的有效性,它显示了强大的识别功能,从不同类型的GAN模型在无监督的方式。

