
人证比对 - 2 - DocFace+: ID Document to Selfie Matching - 1 - 论文学习
代码:https://github.com/seasonSH/DocFace
DocFace+: ID Document to Selfie* Matching
Abstract—在日常生活中,许多活动都要求我们通过出示包含人脸图像的身份证件(如护照和驾照)来验证自己是谁。然而,这个过程是缓慢的,劳动密集型的,不可靠的。因此,需要一套能够实时、高精度地将身份证件照片与实时人脸图像(自拍)进行自动匹配的系统。在本文中,我们提出DocFace+来实现这个目标。首先,我们展示了当许多类有很少的样本时,基于梯度的优化方法收敛缓慢(由于分类器权值不匹配),这是现有ID-selfie数据集的一个特征。为了克服这个缺点,我们提出了一种名为dynamic weight imprinting(DWI)的方法来更新分类器的权值,这种方法可以更快地收敛和得到更一般化的表征。然后,对参数部分共享的兄弟网络进行训练,学习具有特定领域参数的统一人脸表示。对一个ID-selfish数据集做的交叉验证显示,一个公开的通用人脸匹配器(SphereFace)在这个问题上的真实接受率(TAR)只有59.29±1.55%,错误接受率(FAR)只有0.1%,而DocFace+将真实接受率提高到97.51±0.40%。
1 INTRODUCTION
身份验证在我们的日常生活中扮演着重要的角色。例如,访问控制、物理安全和国际边境过境要求我们验证访问(安全)级别和身份。解决这一问题的一种实际和常见的方法是将个人的活生生的面孔与他/她的身份文件中的人脸图像进行比较。例如,移民和海关官员通过查看护照照片来确认旅行者的身份。美国超市的店员在顾客买酒的时候,会通过看顾客的脸和驾照来判断他的年龄。在许多场景中都可以找到ID文档照片匹配的实例。然而,它主要是由人手动执行的,这很耗时、昂贵,而且容易出现操作错误。一项关于澳大利亚悉尼护照官员的研究表明,即使是受过训练的官员,在匹配不熟悉的面孔和护照照片时也表现不佳,错误通过率为14%[1]。因此,需要一个准确、自动化的系统,有效的将身份证件照片与自拍*匹配。此外,自动ID-selfie匹配系统还支持远程认证应用程序,这在其他情况下是不可行的,比如在移动应用程序中为新客户提供身份验证(通过验证创建账户的身份),或者在忘记密码的情况下恢复账户。图1展示了ID-selfie匹配系统(DocFace+)的一个应用程序场景。

在国际边境已经部署了一些ID-selfish自动匹配系统。2007年在澳大利亚部署的SmartGate[2](见图2)是最早的同类产品。

由于前往澳大利亚的旅客越来越多,澳大利亚政府在大多数国际机场推出了SmartGate,为ePassport持有者提供电子护照检查服务。要使用SmartGate,旅客只需让一台机器读取装有他们数码照片的ePassport芯片,然后用安装在SmartGate上的一个摄像头捕捉他们的人脸图像。通过人脸比对验证旅客身份后,大门自动打开,旅客进入澳大利亚。英国(ePassport gates)[3]、美国(u.s. Automated Passport Control)[4]等国家也安装了类似的机器。在中国,这样的验证系统已经被部署在很多地方,包括火车站,用来匹配中国身份证和真人人脸[5]。除了国际边境控制,一些企业[6][7]利用面部识别解决方案来验证在线服务的身份证明文件。
ID-selfie匹配的问题带来了许多不同于一般面部识别的挑战。对于典型的无约束人脸识别任务,主要的挑战来自于姿态、光照和表情(PIE)的变化。相反,在ID-selfie匹配中,我们将扫描的或数字文档照片与真人脸的数字相机照片进行比较。假设用户是合作的,这两个图像都是在约束条件下捕获的,不会出现较大的PIE变化。然而,(1)由于图像压缩导致的文档照片质量不高(大多数电子护照芯片的内存在8KB到30KB之间;人脸图像需要压缩后存储在芯片中。可见https: / /www.readid.com/blog/face-images-in-ePassports)
(2)文档发布日期与验证日期之间的时间间隔过大仍然是主要难点。参见图3:

此外,由于最先进的人脸识别系统是基于深度网络的,我们面临的另一个问题是缺乏大型训练数据集(即成对的ID照片和自拍照片)。
尽管存在大量的应用和相关的挑战,但对ID-selfie匹配的研究却很少。大多数发表的研究都是过时的[9] [10] [11] [12]。值得注意的是,人脸识别技术在过去五年中取得了巨大的进步,这主要是由于大规模人脸数据集的可用性和深度神经网络架构的进展。因此,之前发布的ID-selfie匹配结果现在已经过时了。据我们所知,我们之前的工作[13,Docface]是第一个研究deep CNN在这个问题上的应用,与Zhu等人[14]的工作同步(即人证比对 - 1 - Large-scale Bisample Learning on ID Versus Spot Face Recognition - 1 - 论文学习)。
在本文中,我们首先简要回顾了ID-selfie匹配问题的现有研究以及与我们工作相关的其他研究。然后,我们将之前的DocFace[13]工作扩展到更高级的方法DocFace+,用于构建ID-selfie匹配系统。我们使用带有相应自拍照的中国身份证的大数据集来开发系统(这个数据集包含在不同地点和不同时间捕获的53591对ID-selfie。由于隐私原因,我们不能在公共领域发布这些数据。据我们所知,在公共领域没有这样的数据集),并评估(i)两种商用现成(COTS)人脸匹配器、(ii)开源深度网络人脸匹配器和(iii)所提方法 的性能。我们还在Zhu等[14]建立的开放基准上比较了提出的系统。本文的贡献总结如下:
一种基于分类的浅层数据集嵌入学习优化方法(人脸识别数据集通常用广度和深度[15]来描述,其中广度是类的个数,深度是每个类的平均样本数)。
一种新的识别系统,包含一对部分共享的网络,用于从ID-selfish学习统一表示。
对显示ID-selfie匹配的COTS和公共域人脸匹配器的评估是一个与一般人脸匹配不同的非简单问题。
一个用于ID-selfie匹配的开源人脸匹配器,即DocFace+,它显著提高了最先进的普通人脸匹配器的性能。我们的实验结果表明,公开可用的CNN matcher (SphereFace)在错误接受率为0.1%的情况下,其正确接受率(TAR)仅为59.29±1.55%,而DocFace+将TAR提高到97.51±0.40%。
2 RELATED WORKS
2.1 ID Document Photo Matching
据我们所知,第一个关于ID-selfie匹配的研究来自Starovoitov等人[9][12]。假设所有的人脸图像都是没有较大表情变化的正面脸,首先利用Hough Transform对眼睛进行定位。基于人眼位置对人脸区域进行裁剪,并计算出梯度映射作为特征映射。该算法与一般的约束脸匹配器相似,只是它是为文档照片数据集开发的。Bourlai等人[10][11]认为ID-selfie匹配是对退化的人脸图像,即扫描的文档照片和高质量的活人脸图像进行比较。为了消除扫描造成的退化,Bourlai等人在使用通用人脸匹配器比较照片之前插入了一个图像恢复阶段。特别是,他们训练一个分类器对给定的图像进行退化类型的分类,然后应用退化特定的过滤器来恢复退化的图像。
与其他对扫描文件的研究相比,我们数据集中的文件照片是从中国身份证内嵌的芯片读取的。此外,我们的方法不是为任何特定的退化类型而设计的,可以应用于任何类型的ID文档照片。与我们之前的工作[13]同时,Zhu等人也在深入研究基于cnn的ID-selfie匹配系统。利用同样来自中国不公开的身份证数据集的2.5M个ID-selfie对,他们将其定义为bisample学习问题,并提出将网络训练分为三个阶段:(1)对一般人脸数据集进行预学习(分类),(2)迁移学习(验证)和(3)细粒度学习(分类)。另一方面,针对ID-selfie数据集上基于分类的嵌入学习方法收敛速度慢的问题,我们提出了一种特殊的优化方法,不需要进行多阶段训练。与我们之前的工作[13,Docface]相比,此版本的差异如下:(1)一个更大的ID-selfie数据集(over 50000 papers),这是[13]中的两个小型私有数据集和另一个更大的ID-selfie数据集组合而成的,(2)不同的损失函数,即DIAM-Softmax,用来学习人脸表征,(3)更全面的实验分析每个模块的作用和(4)在Zhu等人[14]发布的新的ID-selfie基准Public IvS上评估提出的体系以及其他的人脸匹配器 。
2.2 Deep Face Recognition
自从深度神经网络在ImageNet竞赛[16]中取得成功后,几乎所有正在进行的人脸识别研究现在都利用深度神经网络来学习人脸表示。Taigman等人[17]首先提出将深度神经网络应用于学习人脸表示。他们设计了一个8层的卷积神经网络,并用Softmax损失函数(用于分类问题的标准损失函数)对其进行训练。他们使用bottleneck的输出作为人脸表示,并在2014年取得了当时最先进的性能。考虑到Softmax损失只会鼓励大的类间的变化,而不会限制类内的变化,Sun等人[18]后来提出用分类信号(Softmax损失)和度量学习信号(contrastive损失)来训练网络。大约在同一时间,Schroff等人[19]提出了一个名为triplet loss的度量学习损失函数,提高了标准LFW协议[8]的最新性能。Liu等人使用Angular-Softmax (A-Softmax)损失函数,[20]首先弥补了分类损失函数和度量学习方法之间的差距,这是一种基于角度距离对样本进行分类的改进的Softmax损失函数。Wang等人[22]最近提出了Additive Margin Softmax(AM-Softmax),该方法通过附加的边际来增加角度识别力,结果表明该方法比Softmax更健壮。
2.3 Heterogeneous Face Recognition
异构人脸识别(HFR)是近年来兴起的热门话题。通常是指两种不同模式之间的人脸识别,包括可见光图像(VIS)、近红外图像(NIR)[24]、热红外图像[25]、复合速写[26]等。ID-selfie匹配可以认为是HFR的一种特殊情况,因为需要匹配的图像来自两个不同的来源,因此可能需要不同的建模方法。因此,在HFR中使用的技术可能有助于解决ID-selfie问题。目前研究HFR的方法主要有两种:基于合成的方法和基于判别特征的方法。基于合成的方法旨在将图像从一种模态转换为另一种模态,从而使一般的类内模态(intra-modality)人脸识别系统能够应用。相反,基于判别特征的方法要么手工设计一个模态不变的视觉descriptor,要么从训练数据中学习一组特征,从而使来自不同模式的图像可以映射到一个共享的特征空间[30][31][32]。最近关于HFR的研究集中于利用深度神经网络来学习这种模态不变特征。在[33]中,Liu等人首先提出通过迁移学习将深度VIS人脸特征应用于VIS-NIR匹配,在VIS- NIR数据集上对网络进行微调,采用修正的triplet损失。He等人提出了[34],使用共享的卷积神经网络将VIS和NIR图像映射成三个特征向量:一组共享特征和两组特定于模态的特征集,然后用三个Softmax loss函数将其拼接和训练。Wu等[35]提出用两个相关的模态特有的Softmax损失函数学习统一的特征空间。两个Softmax损失的权重通过trace norm和block-diagonal进行规则化,以鼓励不同模式表示之间的相关性,并避免过拟合。
2.4 Low-shot Learning
与我们工作相关的另一个领域是low-shot学习问题。在low-shot学习[36][37][38]中,对模型进行训练,使其能够泛化到看不见的类,这些类可能样本很少。low-shot学习有两个训练阶段:首先在一个更大的分类数据集上训练模型,然后在测试中,给出一些新类的标记样本,需要模型学习给定这些类的新分类器。形容词“low-shot”指的是每个类的少量图片。机器学习社区对这个问题越来越感兴趣,因为人类非常善于适应对象(类)的新类型,而传统的深度学习方法需要大量的样本来区分特定的类。这与ID-selfie问题有关,因为大多数身份只有少量样本,导致数据集较浅。针对low-shot学习问题,已经提出了许多方法。Koch等人[36]提出了一种简单而有效的方法,即通过siamese网络[39]学习指标进行low-shot识别。Vinyals等人[37]提出了Matching Net,在训练阶段通过小批量学习low-shot识别来模拟测试场景。这个想法被概括为meta-learning,一个额外的meta-learner可以学习如何优化或生成新的分类器[40][41]。Snell et al.[38]的Prototypical Network与我们的工作更相关。他们提出学习一个prototypes网络,即不可见类的平均特征向量,可以用于分类。Qi等人[42]基于prototypes或proxies[43]的思想,提出将提取的特征印入新分类器的权值。我们注意到,他们的工作与我们的不同,因为他们使用的imprinting权重只是作为初始化,而我们使用权重imprinting作为优化方法,在整个训练中动态imprinting权重。
3 DATASETS
在这一节中,我们简要介绍本文中使用的数据集。数据集的一些示例图像如图4所示。如前所述,由于隐私问题,我们不能发布不公开的ID-selfie数据集。但是通过与公开人脸匹配器的比较,我们认为这足以说明问题的难度和所提方法的优势。

3.1 MS-Celeb-1M
MS-Celeb-1M数据集[44]是一个公开的人脸数据集,有助于人脸识别的深度网络训练。它包含了从网上下载的99,892名受试者(大部分是名人)的8,456,240张面部图像。在我们的迁移学习框架中,它被用来训练一个基础网络。由于已知数据集有许多错误的标签,我们使用了一个MS-Celeb-1M的清理后的版本(https://github.com/AlfredXiangWu/face verification experiment),包含98687个对象的5041 527张图片。这个数据集的一些示例图像如图4(a)所示。
3.2 Private ID-selfie
在实验中,我们使用一个私有数据集来开发和评估我们的ID-selfie匹配系统。它是一个较大的ID-selfie数据集和我们之前工作[13]中使用的两个较小数据集的组合。数据集包含53,591个身份的116,914张图像。每个身份证件只有一张身份证照片。53054个身份中只有一张自拍,而其他537个身份中有多张自拍。身份证照片是从中国居民身份证上的芯片读取的。在实验中,我们将对该数据集进行5次交叉验证,以评估我们方法各部分的有效性。图4(b)显示了来自这个数据集的一些示例对。
3.3 Public IvS
Public IvS是Zhu等人[14]发布的ID-selfie匹配系统评价数据集。该数据集是通过从互联网上收集中国人物的身份证照片和真人面部照片来构建的。数据集总共包含1,262个身份和5,503张图像。每个身份都有一张身份证照片和1到10张自拍照。它不是严格意义上的ID-selfie数据集,因为它的ID照片不是来自真实的ID卡,而是用高度受限的正面照片模拟的。该数据集的结果与真实世界ID-selfie数据集[14]一致。这个数据集的一些示例对如图4(c)所示。
4 METHODOLOGY
4.1 Overview
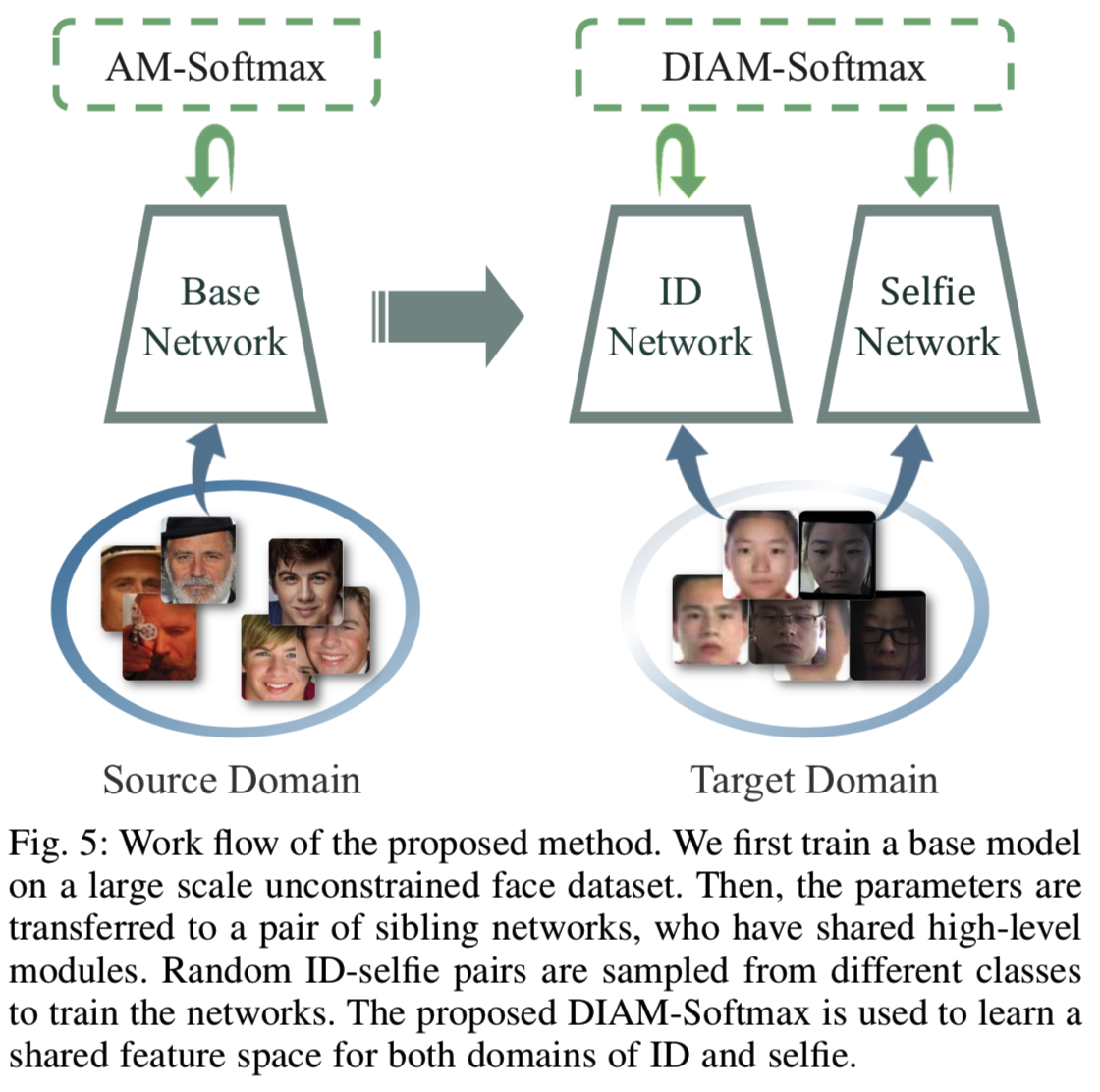
在我们的工作中,我们首先在一个大规模的无约束的人脸数据集,即MS-Celeb 1M上训练一个网络作为基础模型,然后将其特征转移到我们的目标领域ID-selfie对。为了保证转移学习的性能,我们利用流行的Face-ResNet架构[21]来构建卷积神经网络。为了训练基础模型,我们采用了最先进的Additive Margin Softmax (AM-Softmax)损失函数[22][45]。然后,我们提出了一种新的优化方法,即dynamic weight imprinting(DWI)方法,用于在ID-selfie数据集训练时更新AM-softmax中的权值矩阵。提出了一对兄弟网络,分别用于学习IDs和自拍照领域特有的特征,并具有共享的高级参数。工作流程的概述如图5所示。
4.2 Original AM-Softmax
我们使用原始的Additive Margin Softmax(AM-Softmax)损失函数[22][45]来训练基础模型。在介绍下一节的修改之前,我们先做一个简短的回顾,以更好地理解这个损失函数。与Angular Softmax[20]和L2-Softmax[46]类似,AM-Softmax是一个基于分类的嵌入学习损失函数,目的是最大化类间的分离和最小化类内的变化。让![]() 作为我们的训练数据集,同时
作为我们的训练数据集,同时![]() 为特征抽取网络。其中
为特征抽取网络。其中![]() 表示人脸图像,yi表示对应的标签,h、w、c分别表示输入图像的高、宽、和channels的数量。N是训练图像的数量,d是特征维度的数量。对于一个mini-batch的训练样本xi,其损失函数为:
表示人脸图像,yi表示对应的标签,h、w、c分别表示输入图像的高、宽、和channels的数量。N是训练图像的数量,d是特征维度的数量。对于一个mini-batch的训练样本xi,其损失函数为:

其中![]() 是第j个类的权重向量,m是用来控制边际的超参数,s是尺度参数。注意该公式与原始的AM-Softmax[22]有点不同,即边际m没有被s相乘,这就允许我们去自动学习参数s[47]了。在训练中,等式(1)中的损失被mini-batch中的所有图像平均。AM-Softmax和原始Softmax的最主要的不同是特征fi和权重向量wi都被归一化,并坐落在球形嵌入空间中。因此,AM-Softmax不是根据内积对样本进行分类,而是根据测试阶段使用的相同度量标准——cosine相似度对样本进行分类。这就缩小了训练和测试之间的差距,以及分类学习和度量学习之间的差距。归一化后的权值向量wj被认为是第j个类的“agent”或“proxy”,表示该类在嵌入空间[47]中的分布情况。在优化过程中,采用随机梯度下降法(SGD)对分类器权值进行优化。对于ground-truth类的权重wyi,梯度为:
是第j个类的权重向量,m是用来控制边际的超参数,s是尺度参数。注意该公式与原始的AM-Softmax[22]有点不同,即边际m没有被s相乘,这就允许我们去自动学习参数s[47]了。在训练中,等式(1)中的损失被mini-batch中的所有图像平均。AM-Softmax和原始Softmax的最主要的不同是特征fi和权重向量wi都被归一化,并坐落在球形嵌入空间中。因此,AM-Softmax不是根据内积对样本进行分类,而是根据测试阶段使用的相同度量标准——cosine相似度对样本进行分类。这就缩小了训练和测试之间的差距,以及分类学习和度量学习之间的差距。归一化后的权值向量wj被认为是第j个类的“agent”或“proxy”,表示该类在嵌入空间[47]中的分布情况。在优化过程中,采用随机梯度下降法(SGD)对分类器权值进行优化。对于ground-truth类的权重wyi,梯度为:
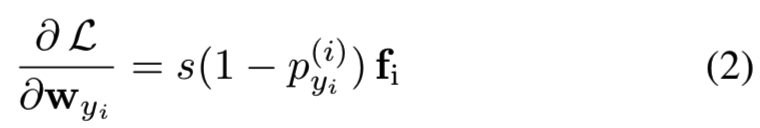
作为一个吸引信号来使wyi更接近fi。对于其他类![]() ,梯度为:
,梯度为:
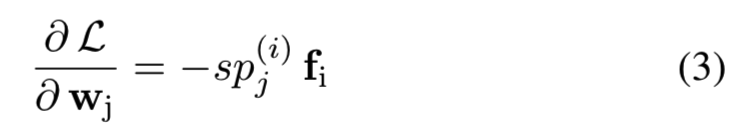
提供排斥信号使wj远离fi。与[39][19]度量学习方法相比,归一化权值使AM-Softmax能够捕获不同类在嵌入空间中的全局分布,收敛速度更快,性能更好。
4.3 Dynamic Weight Imprinting
尽管AM-Softmax等基于分类的嵌入学习损失函数在通用人脸识别[46][47][20]上取得了成功,但我们发现它们在ID-selfie数据集[13]上的迁移学习竞争力较低。事实上,通常情况下,它们收敛得非常慢,陷入了一个糟糕的局部最小值。如图6所示:
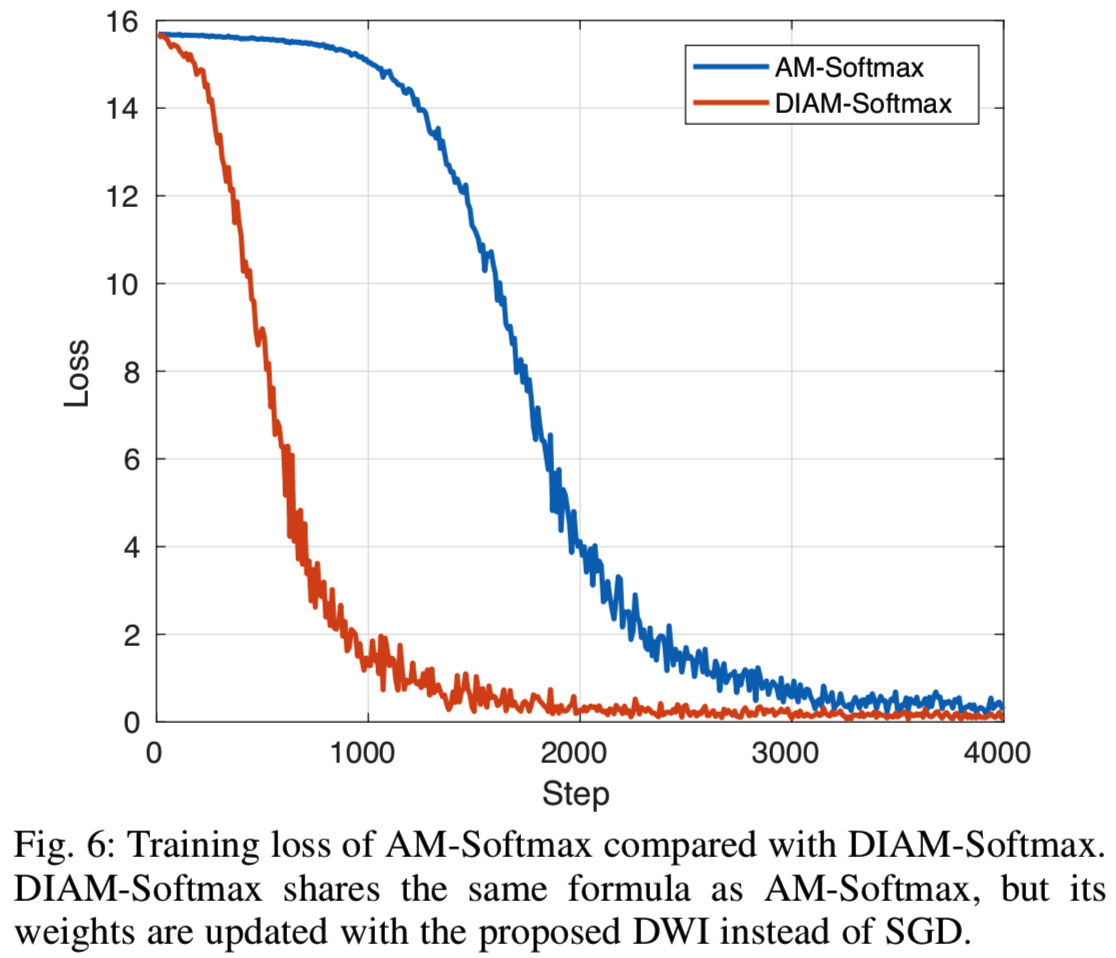
原始的AM-Softmax在几个epoch之后并没有开始收敛(在该实验中,每个epoch大约有300 steps)。为了更深入地了解这个问题,我们通过降维来可视化嵌入。我们提取样本的特征以及训练数据集中8个类别的归一化权向量,并使用t-SNE[48]将其维数从512降至2(随机选择七个类,其中一个类有更多的数据。与大多数类类似,随机选择的7个类只有两张图片(一个ID和一个自拍)。)。如图7(a)所示:

值得注意的是,即使在收敛之后,许多权值也会从相应类的分布中移开。尽管因为排斥信号[47],在最初的损失函数中,权重的移动是有被预料到的,但其不影响在传统的人脸数据集上的收敛;但是该移动对于大多数类只有几个样本的shallow数据集中将扩大并对其收敛有害。这种更大的移动主要是由优化方法引起的,而不是因为排斥其他类。由于SGD用小批量更新网络,在two-shot情况下,每个权值向量在每个epoch中只会收到两次吸引信号。这些稀疏吸引信号乘上学习率后,对分类器权值的影响不大。SGD信号的稀疏性导致最后一层全连接层的分类器权值不够拟合,偏离了特征分布,导致收敛缓慢,而不是过拟合。
基于上述观察,我们对基于分类的嵌入学习损失函数的权值提出了不同的优化方法。其主要思想是根据样本特征更新分类器权值,避免分类器权值不拟合,加快收敛速度。这个权重imprinting的想法已经在文献[42][14]中被研究过,但是他们只是在微调的开始imprint权重。受center loss[49]的启发,我们提出了一个dynamic weight imprinting(DWI)策略来更新权值:
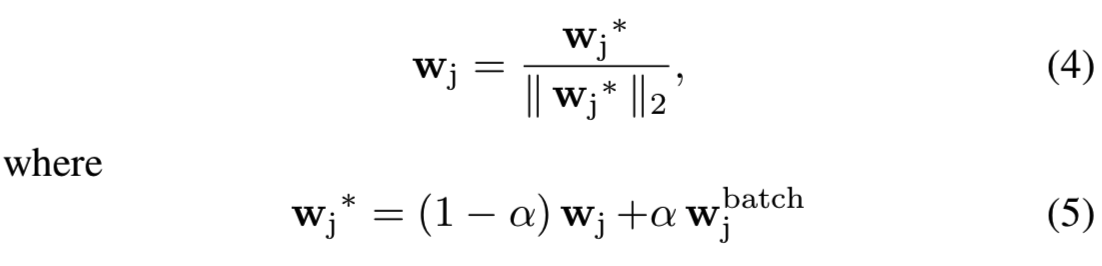
其中![]() 是是基于当前mini-batch计算的目标权重向量。注意,我们只更新类的权重,这些类的样本出现在当前的mini-batch中,我们将wj而不是wj∗作为变量存储。我们在ID-selfie问题中考虑了三个候选的
是是基于当前mini-batch计算的目标权重向量。注意,我们只更新类的权重,这些类的样本出现在当前的mini-batch中,我们将wj而不是wj∗作为变量存储。我们在ID-selfie问题中考虑了三个候选的![]() :(1) ID图像的特征,(2)自拍照图像的特征,(3)ID和自拍照图像的平均特征。超参数α是更新速率。我们在这里使用这个α来考虑一个更广泛的情况,即权重被softly更新。事实上,如5.2节中所示,当α=1时性能是最好的,此时更新公式可以简单写为:
:(1) ID图像的特征,(2)自拍照图像的特征,(3)ID和自拍照图像的平均特征。超参数α是更新速率。我们在这里使用这个α来考虑一个更广泛的情况,即权重被softly更新。事实上,如5.2节中所示,当α=1时性能是最好的,此时更新公式可以简单写为:

直观地说,DWI利用样本特征加速了权值向量的更新,并且不受优化器参数设置的影响。与基于梯度的优化方法相比,该方法只基于真实样本更新权值,不考虑其他类的排斥。这可能引起怀疑它是否可以优化等式(1)中的损失函数。然而,如图6和图7,经验上我们发现DWI不仅能够优化损失函数,而且还可以通过减少权重的移动来帮助损失更快收敛。此外,我们在私有的ID-selfie数据集上的交叉验证结果显示,即使我们训练SGD的时间是它的两倍,在完全收敛之前,DWI在准确性上仍优于SGD。见表1所示。
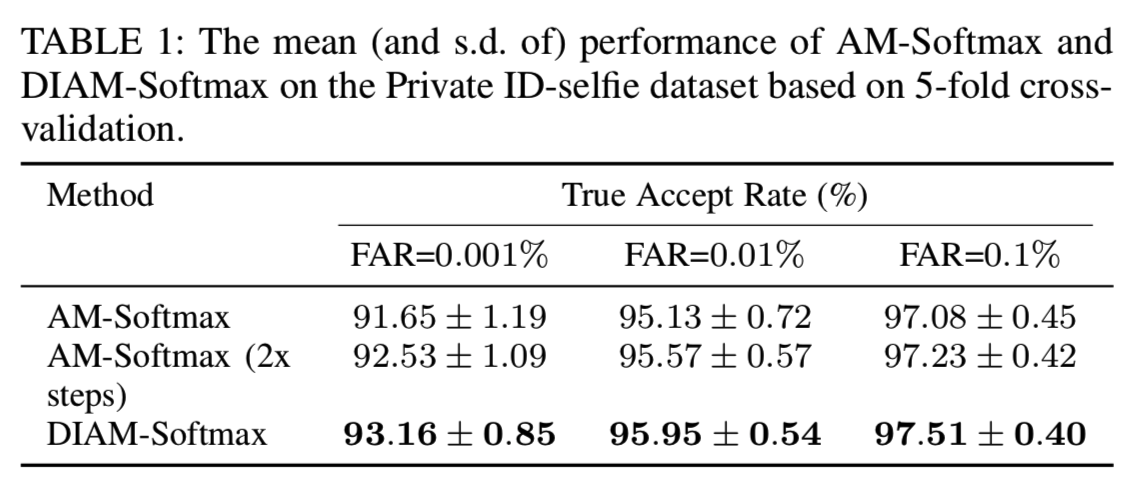
需要注意的是,DWI并不是为AM-Softmax专门设计的,也可以应用于其他基于分类的嵌入学习损失函数,如L2-Softmax[46]。虽然它主要是一种优化方法,并且没有改变损失函数的公式,但是从另一个角度来看,DWI也产生了一种新的损失函数,因为不同的分类器权值的选择本质上带来了不同的学习目标。因此,我们将本文结合DWI和AM-Softmax的方法命名为一个新的损失函数,称为dynamic imprinting AM-Softmax (DIAM-Softmax)。
这里需要注意的是,DWI没有引入任何显著的计算负担,训练速度几乎与以前相同。此外,由于DWI仅更新mini-batch中出现的类的权重,它是自然兼容那些所有类的权重矩阵太大以至于不能加载,所以训练时仅有一部分权重能够被采样的极宽的数据集,如[14]。但是,由于数据的限制,我们在本文中没有进一步探讨这个想法。
4.4 Domain Specific Modeling
ID-selfie匹配问题可以看作是一个异构人脸识别(HFR)[32]的实例,因为人脸图像来自两个不同的来源。因此,期望HFR方法能够帮助解决我们的问题是合理的。HFR中常见的一种方法是利用两个独立的领域特定模型将来自不同来源的图像映射到统一的特征空间。因此,我们分别对ID图像和自拍图像使用一对兄弟网络,它们共享相同的架构,但可以有不同的参数。它们的两个特征都是从基础模型转移过来的,也就是说,它们有相同的初始化。虽然这增加了模型的大小,但推理速度将保持不变,因为每张图像只被输入到一个兄弟网络中。使用兄弟网络允许特定领域的建模,但是更多的参数也可能导致过拟合的风险。因此,与我们之前的工作[13]不同,我们提出限制共享的兄弟网络的高层参数,以避免过拟合。特别的是,我们使用一对Face-ResNet模型,只有bottleneck层共享。
4.5 Data Sampling
将基于分类的损失函数应用于一般的人脸识别中,通常是通过均匀随机的对图像进行采样来构造用于训练的mini-batch图像。但是,由于我们的数据是从两个不同的区域获取的,这样的图像级均匀采样可能不是最佳选择。一个类通常只有一个ID图像,而自拍照可能会更多,所以均匀地采样图像会导致对自拍照的偏向,导致对ID照片域建模不足。因此,我们建议使用不同的采样策略来解决域不平衡问题。在每次迭代中,均匀随机选择B/2类,其中B为批大小,从每个类中随机采样一个ID-selfie对构建mini-batch。第5.3节的实证结果表明,与图像级均匀采样相比,这种均衡采样具有更好的性能。
5 EXPERIMENTS
5.1 Experimental Settings
我们使用Tensorflow库进行所有的实验。在MS-Celeb-1M上使用原始的AM-Softmax对基础模型进行训练时,我们使用的batch size为256,持续训练280K步。学习率从0.1开始,在16万步和24万步后分别降低到0.01、0.001。在对私有ID-selfie数据集进行微调时,我们使用batch size为248,并对兄弟网络进行4000步训练。我们以较低的0.01学习率开始学习,在3200步后将学习率降低到0.001。在两个训练阶段,特征网络都由动量为0.9、权值衰减为0.0005的随机梯度下降(SGD)优化器进行优化。所有图像基于通过MTCNN[50]检测到的landmarks的相似性变换进行对齐,并将大小调整为96×112。我们在两个阶段都将边际参数m设为5.0。所有的训练和测试都运行在一个Nvidia Geforce GTX 1080Ti GPU上,该GPU内存为11GB。我们的模型在这个GPU上的推理速度是每幅图像3ms。
利用MS-Celeb-1M数据集和等式(1)中的AM-Softmax 损失函数,我们的基础模型在LFW标准验证协议上达到99.67%的准确率;在BLUFR[51]协议上错误接受率(FAR)为0.1%时,验证率(VR)为达到99.60%的。
在下面的小节中,我们将对所有私有ID-selfie数据集的实验进行五次交叉验证,以评估方法的性能和鲁棒性。数据集被平均分割成5个分区,在每一次fold中,一个分割用于测试,而其余4个的用于训练。特别是,在每个折叠中,分别有42,873和10,718个身份用于训练和测试。我们使用整个公共IvS数据集进行跨数据集评估。所有实验的比较评分采用余弦相似度。
5.2 Dynamic Weight Imprinting
在本节中,我们想比较不同的权重imprinting策略如何影响DIAM-Softmax的性能,并为接下来的实验找到最佳设置。我们首先比较了使用不同更新率α的准确度,然后评估了更新向量![]() 的不同选择。
的不同选择。
图8显示了平均泛化性能如何随α而变化:
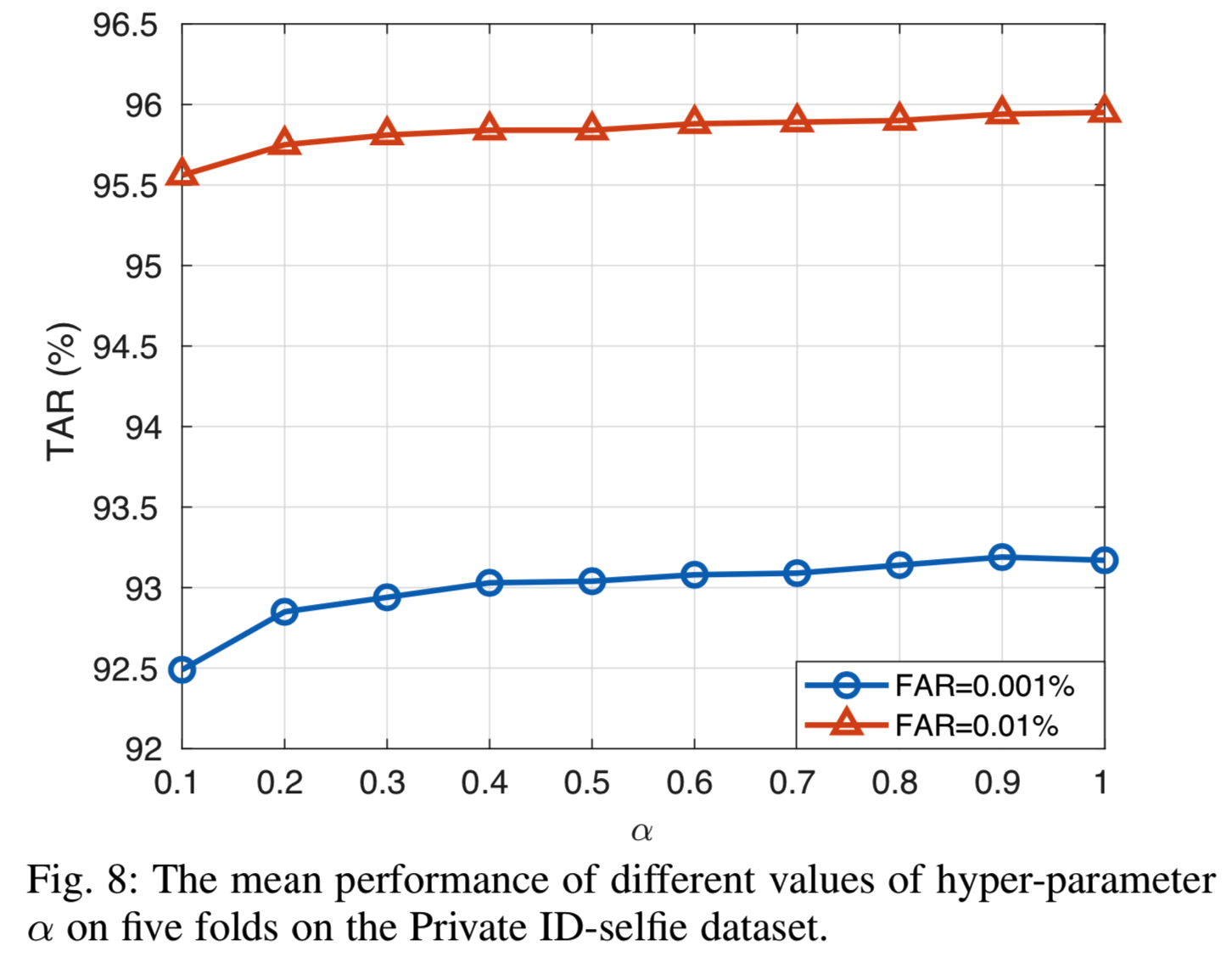
在这里,我们使用来自不同类的随机ID-selfie对构建mini-batches。然后选择![]() 作为ID和自拍样本的平均特征。从图中,很明显,一个更大的α时总是会导致更好的性能,当α= 1时准确性达到顶点, 此时如方程(6)那样我们直接使用
作为ID和自拍样本的平均特征。从图中,很明显,一个更大的α时总是会导致更好的性能,当α= 1时准确性达到顶点, 此时如方程(6)那样我们直接使用![]() 取代权重。这并不奇怪,因为大多数类只有两个样本,因此实际上是没有需要softly更新权重,因为α= 1总是导致类的分布有最准确的估计。在数据集较深的情况下,可能会更倾向于较小的α。
取代权重。这并不奇怪,因为大多数类只有两个样本,因此实际上是没有需要softly更新权重,因为α= 1总是导致类的分布有最准确的估计。在数据集较深的情况下,可能会更倾向于较小的α。
三种不同的![]() 选择的结果如表2所示。单独使用ID特征或自拍特征都会导致性能低于平均特征:
选择的结果如表2所示。单独使用ID特征或自拍特征都会导致性能低于平均特征:
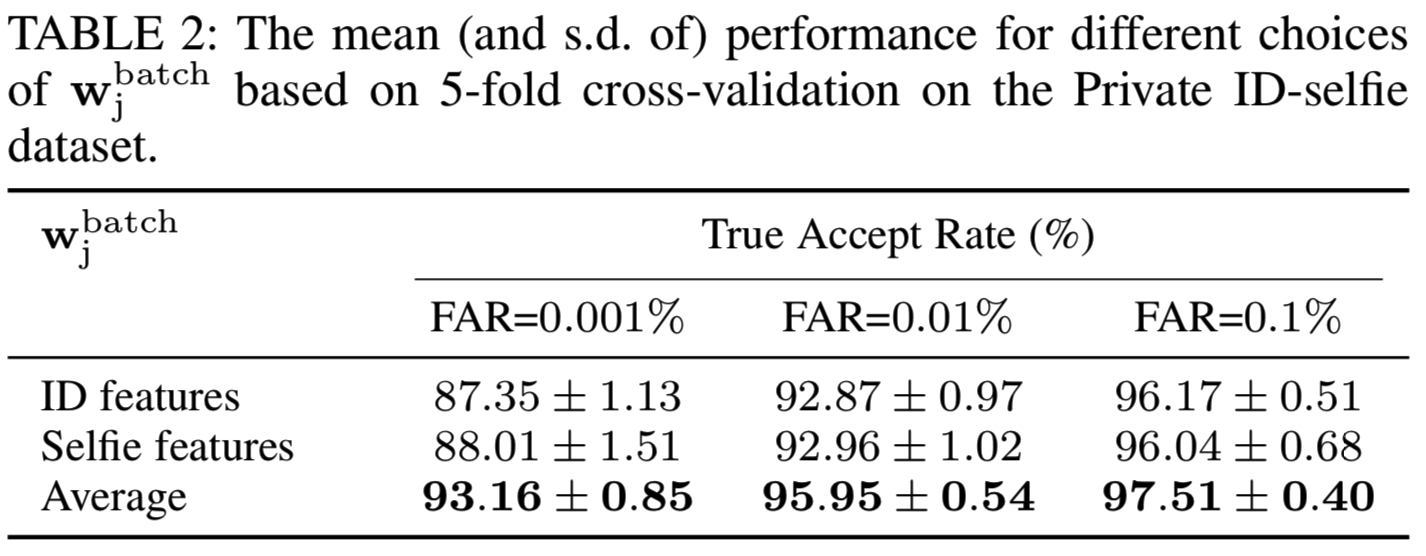
这与Zhu等人[14]的结果不同,Zhu等人发现将分类器权重初始化为ID特征会得到最好的性能。这种差异可能来自于更新分类器权值的策略不同,因为我们是动态更新它们,而不是从训练开始就固定它们。由于大多数类只有两个图像,每个域一个(即ID域一个,自拍域一个),只使用其中一个更新权值会对这些图像造成偏差损失,从而阻碍网络学习一个域的更好表示。
5.3 Data Sampling
由于我们的数据可以以两种方式分类:身份(不同人)和来源(ID或自拍),这就提出了我们应该如何在训练期间对图像进行mini-batch采样的问题。在这里,我们比较了三种不同的抽样方法:(1)图像上的随机抽样,(2)不同类别的随机对,(3)不同类别的随机ID-selfie(提出)对。方法(1)是训练分类损失函数的常用方法,而方法(2)是度量学习方法的常用方法,因为它们需要在小批量内进行真对训练。对于(1)和(2),分类器权重根据每个类样本的平均特征更新。结果如表3所示:
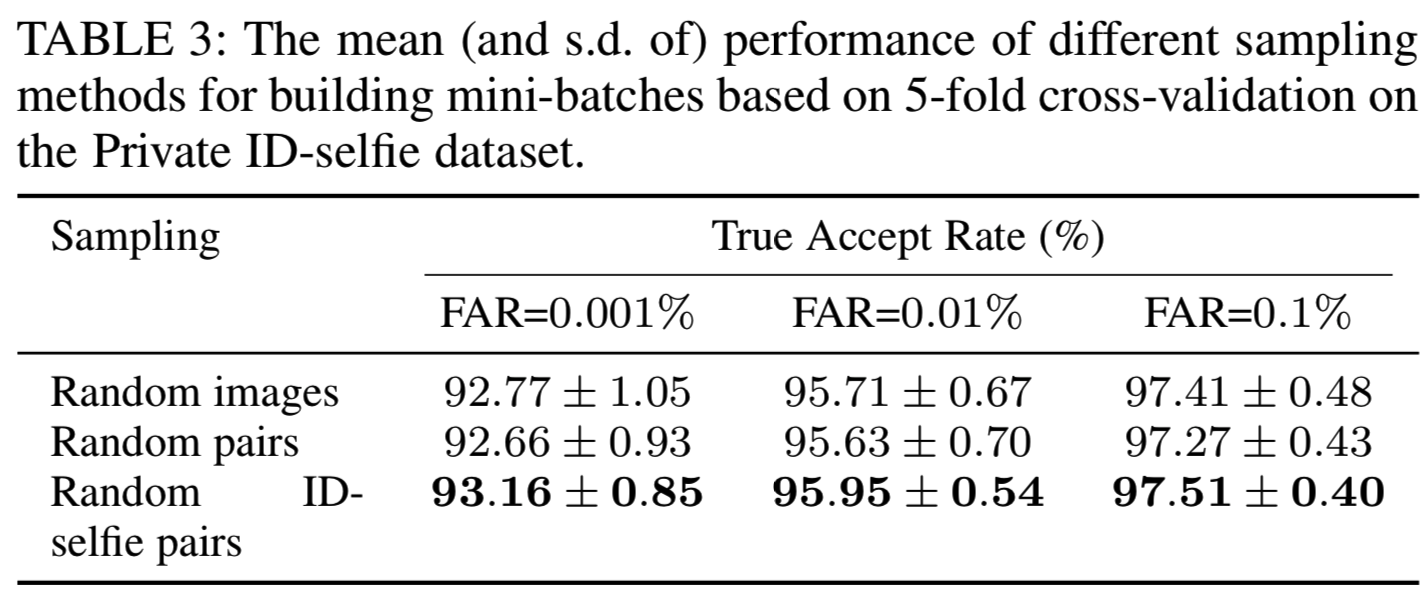
可以看出,随机图像采样的效果略优于随机对采样,这与一般人脸识别的结果是一致的。这是因为随机对导致不同类的图像采样机会不同,模型会偏向小类的样本,因为小类的样本采样频率更高。然而,尽管存在这个问题,随机ID-selfie对仍然比随机图像工作得稍微好一些,这表明在我们的问题中平衡两个领域的参数学习是很重要的。这些结果意味着应该研究如何通过同时解决类不平衡问题(或长尾问题)和域不平衡问题来进一步提高性能。
5.4 Parameter Sharing
为了评估共享参数和领域特定参数的影响,我们限制了ID和selfie域之间共享的兄弟网络中的一个参数子集,并比较性能。这里,我们考虑共享低层参数的情况和共享高层参数的情况。特别地,我们比较了共享网络中的模块“Conv1”、“Conv1-3”和“Conv1-5”来学习低层参数的情况。然后,通过共享“FC”、“Conv5 + FC”模块和“Conv4-5 + FC”模块来重复实验实现高层参数的情况。这里“Conv i-j”表示第i ~ j个卷积模块,“FC”表示特征提取的全连接层。结果如表4所示:

从表4中可以看出,参数共享对性能影响不大。这部分是因为我们的基础模型学习了高度可转移的特性,这些特性的参数已经为所有这些模块提供了良好的初始化。特别是,共享低层参数对性能没有明显的影响,但是限制共享bottleneck确实会在所有错误接受率的准确性和标准偏差方面有轻微的改善。然后,当我们限制更多要共享的高层参数时,性能会下降。此外,与其他参数相比,共享所有参数会导致性能更差。我们确实可以得出结论,ID照片和自拍照片之间存在很小的领域差异,学习领域特定参数有助于跨两个领域的照片识别。
5.5 Comparison with Static Weight Imprinting
在[14]中,Zhu等人将ID特征作为固定的分类器权重进行细粒度训练,性能较原始表示有所提高。我们把这种方法称为静态权重imprinting法。静态权重imprinting的优点是可以同时从所有类中提取特征来更新分类器权值。但是,在训练过程中,它们不仅会造成额外的计算代价,而且无法捕捉全局分布。我们比较了动态权重imprinting法和静态权重imprinting法。特别地,我们考虑了静态imprinting的两种情况:(1)只在微调开始时更新权值,并在训练期间保持不变;(2)每两个周期更新一次权值。对于静态方法,我们从每个类中提取随机ID-selfie对的特征,并使用它们的平均向量更新权重。结果如表5所示:
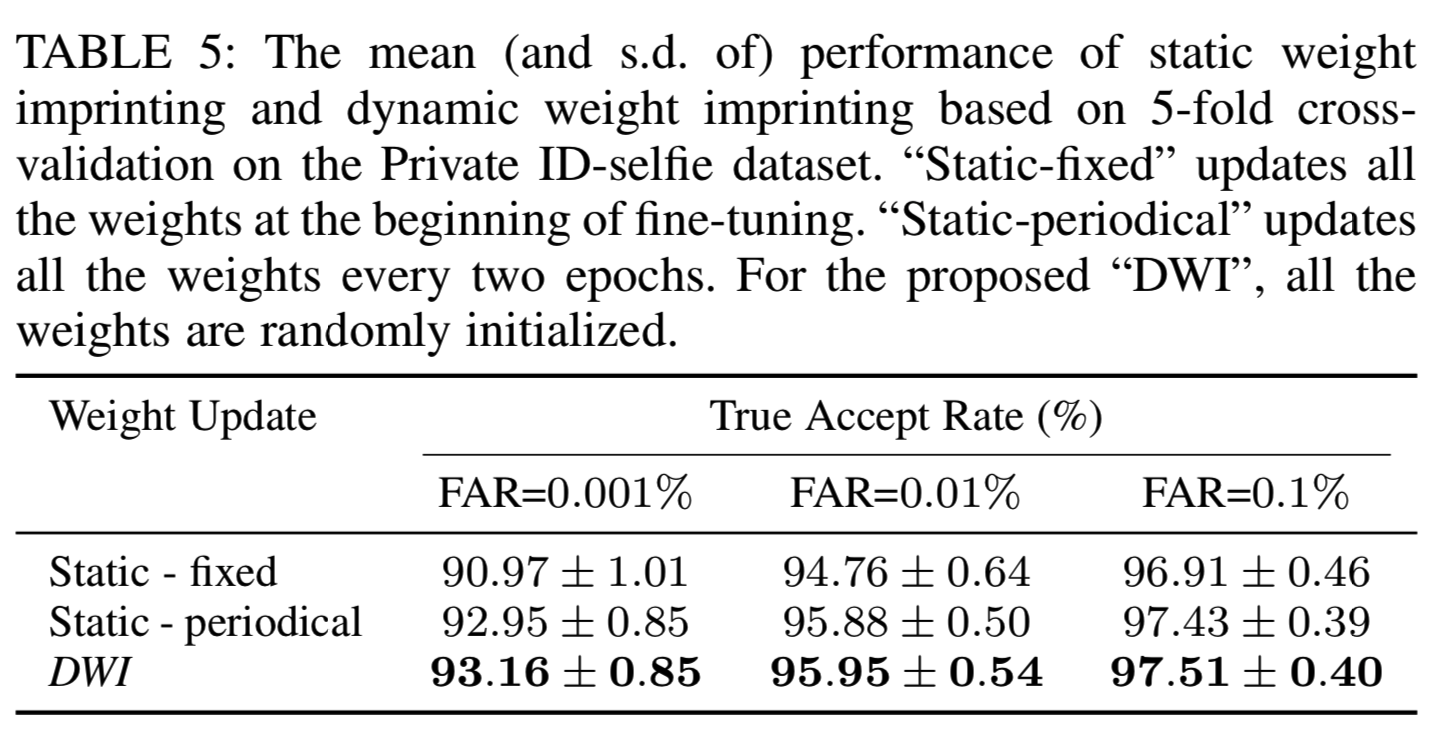
可以看出周期性更新优于固定权值,因为固定权值跟不上特征分布。如果我们更频繁地更新静态权值,应该会有更好的性能。然而,需要注意的是,周期性更新也引入了更多的计算成本,因为我们每次更新权重时都需要提取数以万计的特征。相比之下,DWI的额外计算量几乎为零,但其性能甚至优于周期性更新,说明DWI下的权值能够保持最新,准确捕捉全局分布。
5.6 Comparison with Different Loss Functions
在本节中,我们将评估用于微调私有ID-selfie数据集的不同损失函数的效果。我们没有深入研究训练基本模型的损失函数的选择,因为这与本文的主题无关。我们将提出的DIAM-Softmax与三个基于分类的嵌入学习损失函数:Softmax、A-Softmax[20]和AM-Softmax[22],以及其他三个度量学习损失函数:contrastive损失[39]、triplet损失[19]和我们之前工作[13]中提出的MPS损失进行了比较。基于分类的损失函数能够捕获全局信息,因此在一般性的人脸识别问题[22]上取得了最先进的性能,而度量学习损失函数在非常大的数据集[19]上显示出了有效性。为了保证比较的公平性,我们在Tensorflow中实现了所有的损失函数,并保持实验设置不变,只是AM-Softmax的训练时间延长了一倍。结果如表6所示:
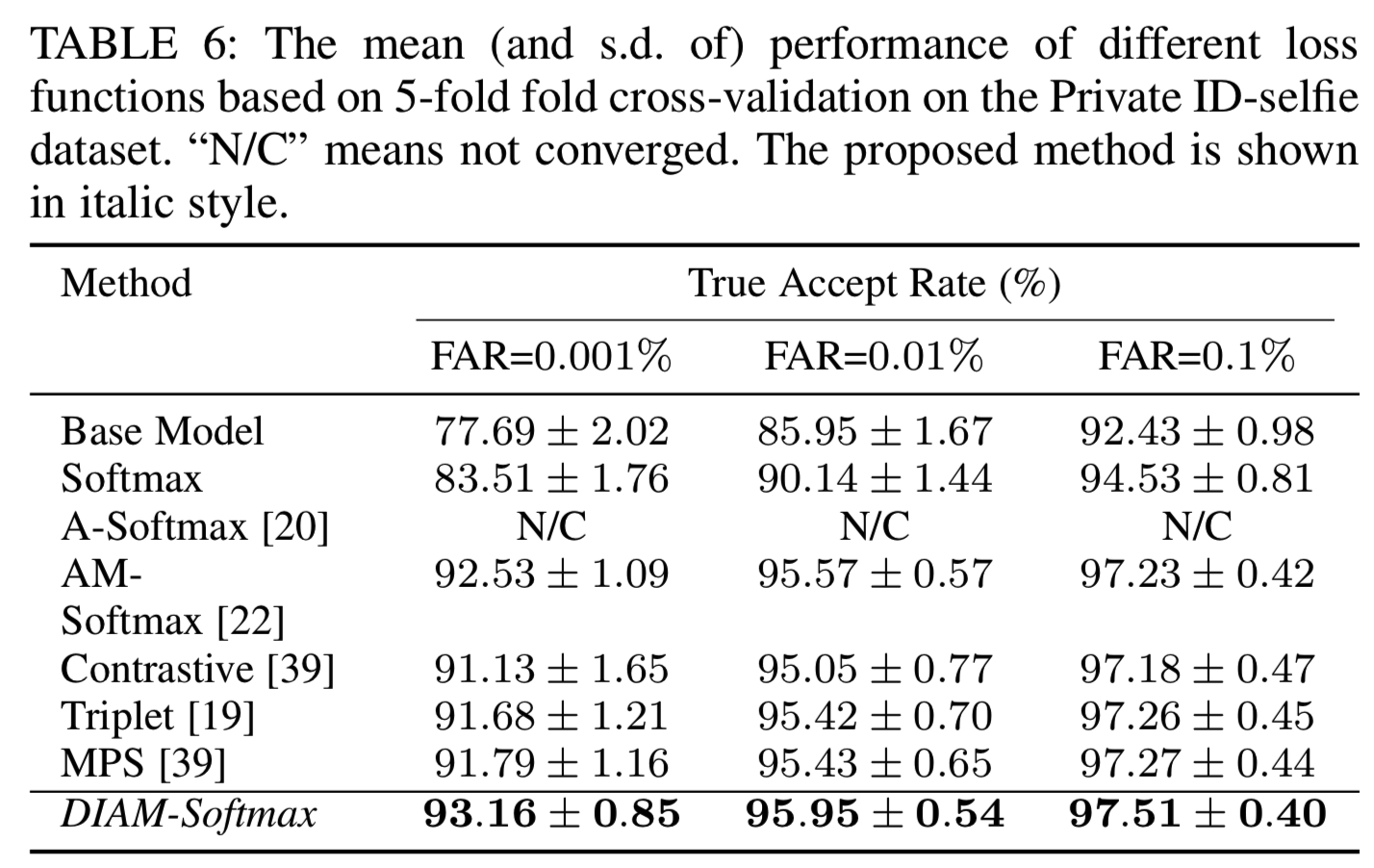
从表6中,我们可以看到一个基本模型在目标数据集上没有任何调整时就已经达到相当高的性能(当FAR为0.1%时,TAR为92.43%±0.98的),表明学习一般人脸数据集的特性是高度可转让的,但是在如LFW的一般的人脸数据集时,由于这两个任务的人脸数据特征的差异,其性能明显低于LFW的性能。对大部分损失函数进行微调后,可以观察到明显的改善。为了进一步了解,我们在图9中绘制了TAR-step曲线(x轴是训练步骤的数量,y轴是该步骤中5次fold的平均TAR@FAR=0.001%):
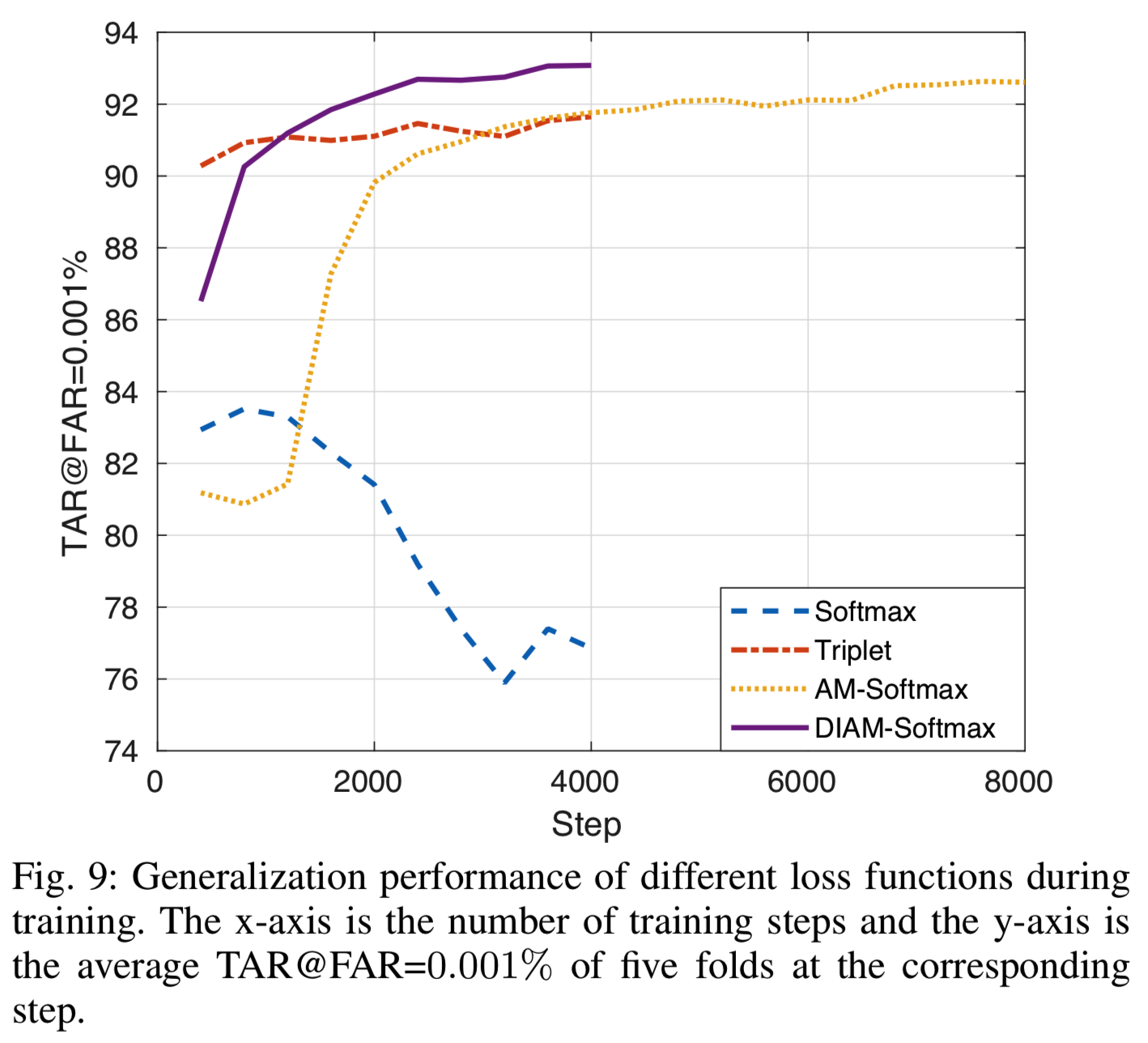
为了使剧情清晰,我们只选取了具有代表性的损失函数。从图9中,我们可以看到,Softmax在两个epoch后过拟合,而度量学习损失更稳定,收敛速度更快。尽管AM-Softmax的性能比度量学习方法好,但它的收敛速度太慢,以至于我们不得不训练它两倍多的步骤。请注意,这个结果与我们之前的工作[13]并不矛盾,在[13]中,我们发现AM-Softmax在微调方面表现很差,因为我们在[13]中只允许同样有限的训练步骤。与收敛速度较慢的AM-Softmax算法相比,采用该权值更新方法的DIAM-Softmax算法不仅收敛速度更快,而且对过拟合具有较强的鲁棒性,推广效果也优于其他算法。
5.7 Comparison with existing methods
在本节中,我们将评估其他人脸匹配器在私有ID-selfie数据集上的性能,并与我们的方法进行比较。据我们所知,目前在ID-selfie匹配领域还没有公共人脸匹配器。虽然Zhu等人在2.5M ID-selfie训练对上开发了一个系统,但他们的系统和训练数据都不公开,因此我们无法在我们的数据集上将他们的系统与提出的方法进行比较。因此,我们将我们的方法与最先进的一般人脸匹配器进行比较,以评估我们的系统在ID-selfie匹配问题上的有效性。为了确保我们的实验足够全面,我们不仅将我们的方法与两个商用(COTS)人脸匹配器进行比较,还将我们的方法与两个最先进的开源CNN人脸匹配器进行比较,即CenterFace[49](https://github.com/ydwen/caffe-face)和SphereFace[20](https://github.com/wy1iu/sphereface)。在5-fold交叉验证期间,由于这些一般的脸匹配器不能再训练,只使用分割的那份测试数据。结果如表7所示:
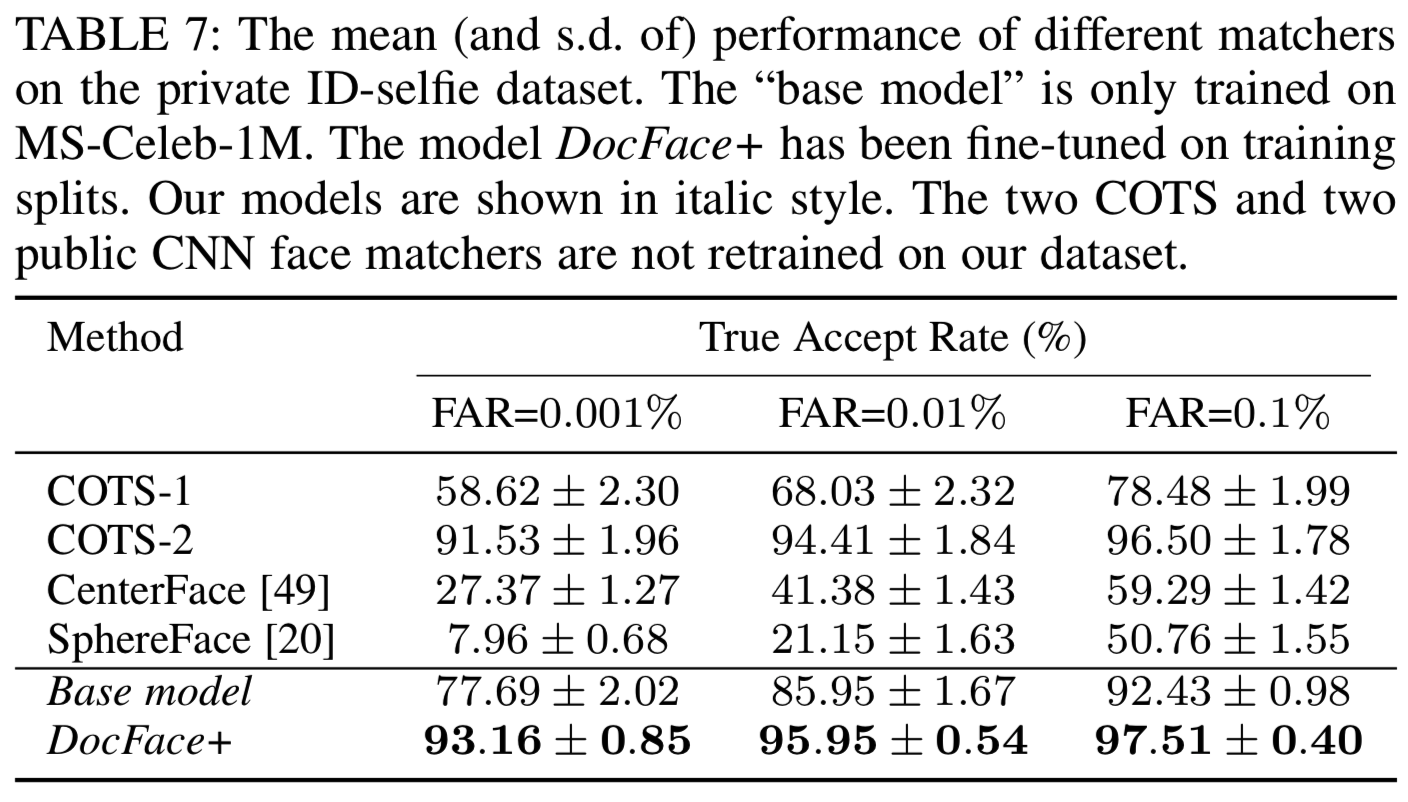
CNN的两个开源匹配器CenterFace和SphereFace在这个数据集上的表现低于平均水平,比他们在[49][20]一般的人脸数据集上的结果差得多。虽然我们的基础模型性能更好,但与它在一般人脸数据集上的性能相比,它的性能仍然有很大的下降。可以得出结论,一般的CNN人脸匹配器不能直接应用于ID-selfie问题,因为ID-selfie图像的特征与一般的人脸数据集不同,必须进行特定领域的建模。一个商业的最先进的人脸识别系统,COTS-2,执行更接近我们的微调模型。然而,由于用于训练COTS-2的人脸数据集是专有的,因此很难断定一个通用的商用人脸匹配器是否能很好地解决这个问题。实际上,从表7可以看出,另一个商业人脸匹配器COTS-1在这个数据集上的性能要差得多。
5.8 Evaluation on Public-IvS
在[14]中,Zhu等人发布了一个模拟ID-selfie数据集,用于公开评估。这个数据集的细节和示例图像在3.3节中给出。这里,我们在这个数据集上测试我们的系统以及以前的公共匹配器,以便进行比较。在所有的照片中,我们成功地用MTCNN对齐了5500张图片。假设受试者是合作的,并且在真实的应用程序中不会出现注册失败的情况,我们只对对齐的图像进行测试。DocFace+模型是在整个私人ID-selfie数据集上训练的。因此,这里不需要交叉验证。结果如表8所示:
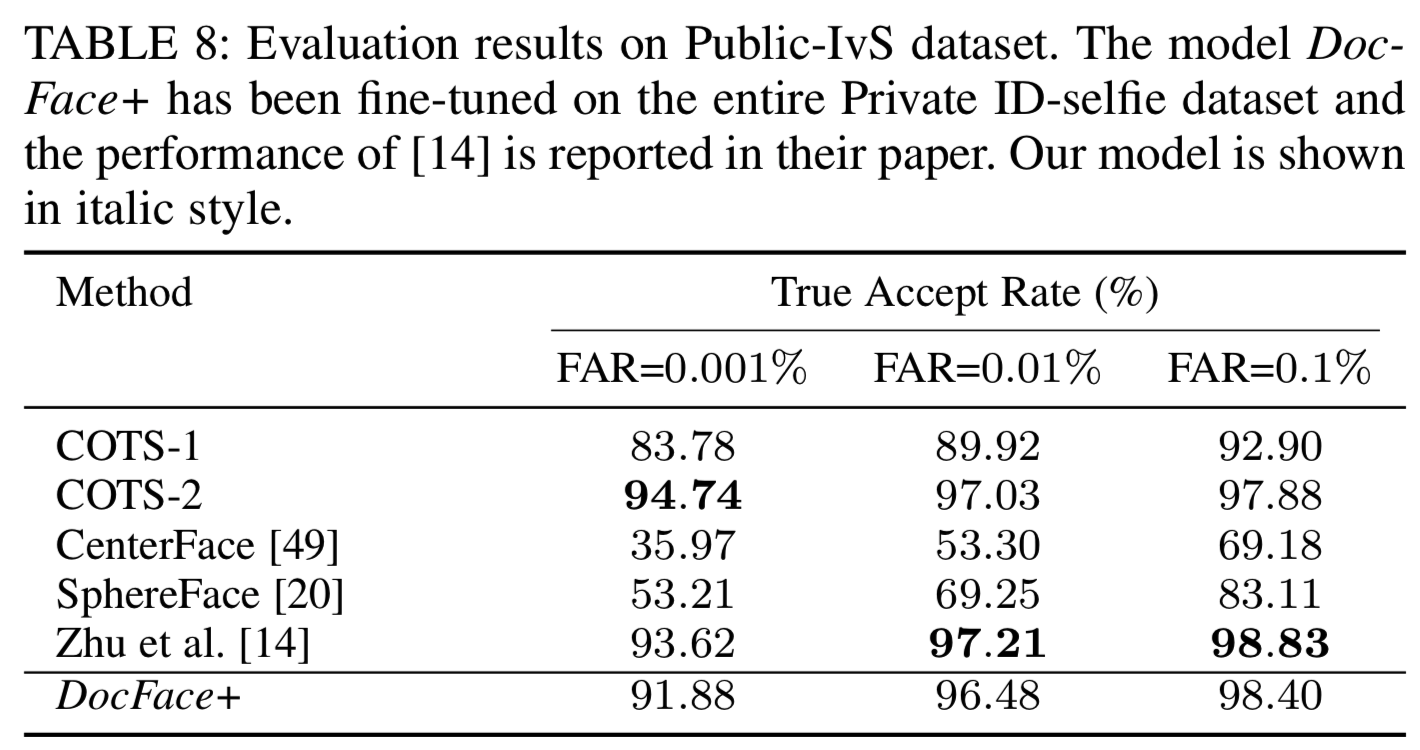
从表中可以看出,所有的竞争对手在这个数据集上的表现都比在我们的私有数据集上的好,这表明这是一个更容易的任务。由于该数据集是一个模拟ID-selfie数据集,并带有web照片(见3.3节),因此对这些结果的合理解释是,该数据集和我们的数据集之间存在轻微的协方差变化。因此,在私有ID-selfie数据集上进行了微调的DocFace+模型在该数据集上的性能较低。请注意,尽管Zhu等人[14]的性能比我们的模型要高,但他们使用的训练数据集是250万对ID-selfie,而我们的训练数据集(Private ID-selfie)仅包含约120K幅图像。总的来说,我们仍然可以得出结论,我们的模型在这个数据集上很好地推广,并且显著优于大多数竞争对手。

6 CONCLUSIONS
在本文中,我们提出了一个新的系统,名为DocFace+,用于ID文档照片与自拍照的匹配。迁移学习技术用于在私有ID-selfie数据集上进行微调的无约束人脸识别的基础模型上。一对具有共享高层模块的兄弟网络用于建模特定领域的参数。基于我们对浅数据集上基于分类的嵌入学习损失函数的权值偏移问题的观察,我们提出了一种替代的优化方法,称为动态权重imprinting(DWI)和AM-Softmax的一个变形,DIAM-Softmax。实验结果表明,该方法不仅提高了损失收敛速度,而且提高了泛化性能。与静态权重imprinting方法的比较表明,DWI能够准确地捕捉嵌入的全局分布。研究了mini-batch结构的不同采样方法,发现两个区域间的平衡采样对可推广特征的学习最有帮助。我们在我们私有数据集上将提出的系统与现有的通用人脸识别系统进行了比较,发现我们的系统有了显著改进,表明了对ID-selfie数据进行领域特定建模的必要性。最后,我们在Public-IvS数据集上比较了不同匹配器的性能,发现尽管存在协方差变化,但我们的系统仍能很好地应用。

