
变老 - 5 - Exploring Unlabeled Faces for Novel Attribute Discovery - 1 - 论文学习(人脸生成)
Exploring Unlabeled Faces for Novel Attribute Discovery
Abstract
尽管在非成对图像到图像的转换方面取得了显著的成功,现有的系统仍然需要大量的标记图像。这是他们实际应用的瓶颈;在实践中,在带标记的CelebA数据集上训练的模型对于来自不同分布的测试图像效果不佳——这极大地限制了它们应用于更大数量的未标记图像。在本文中,我们试图减轻在人脸图像翻译领域中使用标记数据的必要性。我们的目标是探索您能在多大程度上从未标记的人脸中发现新的属性并执行高质量的翻译。为此,我们以视觉世界的先验知识为指导,发现新的属性,并通过一种新的归一化方法进行转移。实验表明,我们在未标记数据上训练的方法能够产生高质量的翻译,保持身份,并且在感知真实性上与在标记数据上训练的最先进的方法一样好,甚至更好
1. Introduction
近年来,无监督图像到图像的翻译得到了极大的改进[44,23,17]。现有的翻译方法使用术语“无监督”来翻译非成对的训练数据(即来自域X和Y的图像,但是没有x匹配哪个y的信息)。但是,现有的系统在本质上仍然是经过监督训练的,因为需要大量的标记过的图像来进行翻译。这成为了它们在现实世界中应用的瓶颈;在实际应用中,基于标记的CelebA数据集[26]训练的模型由于数据集偏向的原因[35,38],不能很好地用于不同测试分布的图像。例如,一个根据CeleA照片训练的模型会偏向于西方名人的人脸,这就需要收集、标记和用新数据进行训练,以匹配不同的测试分布。因此,对标签的需求极大地限制了它们在大量无标签图像上的应用。
在本文中,我们尝试从未标记的图像中自动发现新的属性,实现非成对和未标记的多域图像到图像的转换,以减轻标记数据的必要性。我们特别关注人脸图像的图像翻译,因为它们需要对多个属性进行注释(例如,CelebA中202,599张图像的40个属性),这使得标记工作和时间都很紧张。当现有的基准数据集试图标记尽可能多的属性时,我们注意到有很多属性仍然是未命名的,例如,CelebA在所有可能的皮肤颜色中只包含“pale skin”属性。这让我们思考:难道我们不能从数据中“浮现”属性吗?
本文旨在探讨能多大程度地从未标记的人脸X中发现新属性,从而提出了我们的模型XploreGAN。为此,我们利用预先训练好的CNN特征——充分利用我们已经了解的视觉世界。注意,用于CNN预训练的类(ImageNet类)不同于未标记的数据(人脸属性)。我们的目标不是传递它的特定类,而是在一般情况下[13]传递关于哪些属性的一般知识可以构成一个好的类。我们使用它作为指导来分组新的未标记人脸集,其中每个组包含一个公共属性,并通过我们新提出的attribute summary instance normalization(ASIN)将该属性转移到一个输入图像。与以前的样式归一化方法(style normalization)不同,以前的样式归一化方法是从单个图像中生成仿射参数[7,16],实现存在于在样式图像(style image)中的纠缠属性的翻译(即。例如,头发颜色、肤色和性别),ASIN总结了在一组图像(集群)中的共同特征(如金色头发),并只将其公共属性(样式)传递给输入(内容)。实验表明,在未标记数据上训练XploreGAN可以产生高质量的翻译结果,与使用标记数据训练的最先进的方法一样好,甚至更好。就我们所知,这是第一种同时进行非成对和无标记图像到图像转换的方法。
2. Proposed Method
而现有的方法使用用多个标签标注了得单一图像(即一对多映射)来获得多域间的翻译,我们稍微修改了这个假设,以便在不使用任何属性标签的情况下获得高质量的性能。首先利用预先训练好的特征空间作为引导,根据未标记图像的共同属性对其进行聚类。通过将聚类分配作为伪标签,我们利用新提出的attribute summary instance normalization(ASIN)来总结每个聚类之间的共同属性(如金发),并进行高质量的翻译。
2.1. Clustering for attribute discovery
在ImageNet[5]上预先训练好的CNN特征被用来评估图像之间的感知相似度[19,42]。换句话说,具有相似预训练特征的图像被认为是相似的。利用这一特性,我们提出将未标记数据的特征向量聚类,并使用这些聚类分配作为属性的伪标签,从而发现未标记数据中的新属性。也就是说,我们利用预先训练好的特征空间作为引导,根据图像的主导属性对图像进行分组。
我们采用标准聚类算法 —— K-means算法,和将来自预训练网络的特征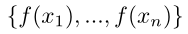 通过解决下面的问题来分成k组:
通过解决下面的问题来分成k组:
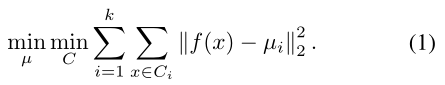
解决这个问题的结果是得到一组集群C,集群中心是μ,和他们的标准差是σ。我们使用C作为伪标签来训练鉴别器的辅助分类器,并使用μ和σ来调节生成器的归一化层。
2.2. Attribute summary instance normalization
Normalizatio层在建模style中扮演着重要的角色。正如[16]所说,单一网络可以“通过在instance normalization (IN)层中使用相同的卷积参数但不同的仿射参数,生成风格完全不同的图像”。换句话说,要向内容图像注入样式,只需在对内容图像进行归一化之后调整特定于每种样式的缩放和移动参数就足够了。
以往的风格归一化方法从单个图像实例中生成仿射参数[7,16],导致了给定风格图像中存在的纠缠属性(如头发颜色/形状、肤色和性别)的转换。相比之下,我们的方法通过从每个聚类的特征统计中生成仿射参数来总结和转移一组图像中的共同属性(如金发)。我们将此属性称为 attribute summary instance normalization (ASIN)。我们使用多层感知器(MLP) f 映射集群统计到归一化层的仿射参数,定义为:

由于生成器经过训练来泛化图像子集(聚类)中的共同特征,ASIN允许我们发现未标记数据中的多个属性。ASIN还可以用于有监督设置,以总结具有相同标签的图像之间的共同属性(例如,黑头发)。您可以从每个聚类的质心μ和方差σ2中生成仿射参数,或仅从质心信息μ或域伪标签(即集群分配C)中生成。我们将在本文后面的方程中使用第一种方法(即使用每个聚类的质心μ和方差σ2),以免读者混淆。
2.3. Objective function
Cluster classification loss. 为了将输入图像x翻译到目标域k,我们采用域分类损失[4]来生成适好分类为目标域的图像。然而,我们使用集群分配C作为每个属性的伪标签,不像以前的多域翻译方法使用预先给定的标签进行分类[4,32]。我们对鉴别器D进行优化,通过定义的损失函数将真实图像x分类到其原始域k‘:
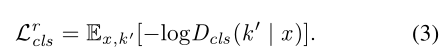
同样地,我们优化生成器G去通过定义如下的损失函数分类假的图像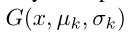 到目标域k中:
到目标域k中:

集群统计信息(即质心μ和方差σ2)作为条件信息来将将图像翻译到其对应的伪域中
Reconstruction and latent loss.我们的生成器应该对内容的变化很敏感,但对其他变化很健壮。为了使翻译后的图像保留其输入图像的内容,而只改变与域相关的细节,我们对生成器采用cycle consistency los[22,44],定义为:

其中生成器被输入假图像和原始集群统计信息 ,旨在重构原始的真实图像x。使用L1 norm作为重构损失
,旨在重构原始的真实图像x。使用L1 norm作为重构损失
然而,在单个生成器必须同时学习大量域(例如,超过40个域)的情况下,仅使用像素级重建损失并不能保证翻译后的图像保留原始图像的高级内容。受到[40]的启发,我们采用了latent损失,将真图和假图在特征空间之间的距离最小化:
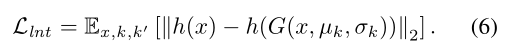
我们用h表示G的编码器encoder,用L2 norm表示latent损失。这种latent损失保证了真图像和伪图像具有相似的高级特征表示,即尽管它们在像素级别上可能有很大的不同,但它们在感知上是相似的。
Adversarial loss. 采用使用在GAN中的对抗损失让生成的图像能和真实图像区分开来。生成器G尝试在给定输入图像x和目标集群统计信息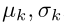 时生成真实的图像,同时判别器D尝试区分生成的图和真实的图。为了稳定GAN训练,我们采用带有梯度惩罚[1,11]的Wasserstein GAN目标函数:
时生成真实的图像,同时判别器D尝试区分生成的图和真实的图。为了稳定GAN训练,我们采用带有梯度惩罚[1,11]的Wasserstein GAN目标函数:
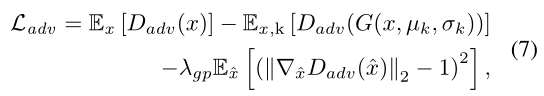
其中 是从真图和假图对间的直线上均匀采样得到的
是从真图和假图对间的直线上均匀采样得到的
Full objective function. 最后,我们用于D和G的目标函数分别为:
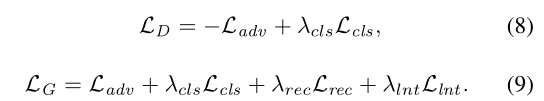
超参数控制每个损失函数的相应的重要程度。在实验中,使用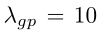
 在测试中,我们使用伪标签去生成翻译结果。我们惊喜地发现伪标签对应于有意义的面部属性;结果可见Section 3
在测试中,我们使用伪标签去生成翻译结果。我们惊喜地发现伪标签对应于有意义的面部属性;结果可见Section 3
2.4. Implementation details
Clustering stage. 我们使用最后的卷积激活层(即BagNet-17和ResNet-50的conv层)来根据高级属性对图像进行聚类。我们使用ImageNet (IN)[5]上预训练的BagNet-17[3]作为FFHQ[21]和CelebA[26]数据集的特征提取器,使用Stylized ImageNet (SIN)[9]上预训练的ResNet-50[14]作为EmotioNet[8]数据集的特征提取器。前者能有效地检测出局部纹理线索,而后者忽略纹理线索却能有效地检测出全局形状。对提取的特征进行l2归一化,PCA降至256维。我们利用Johnson等[20]的k-means实现,对于256×256分辨率的图像使用k = 50;对于128×128分辨率的图像使用k = 100
Translation stage. 我们的编码器是由StarGAN[4]改编而来的,它有两个卷积层用于下采样,然后跟着是六个带有spectral normalization[28] 的 residual blocks[14]。我们的解码器有6个带有attribute summary instance normalization (ASIN)的residual blocks,每个卷积层之后都添加了像素噪声[21]。它后面是两个转置卷积层,用于上采样。我们也采用随机变量[21]来提高图像的精细、随机细节的生成性能。对于鉴别器,我们使用PatchGANs[24, 18, 43]来区分图像patch的真假。作为预测ASIN仿射参数的模块,我们的多层感知器包括用于FFHQ和EmotioNet数据集的七层和CelebA数据集的三层。为了进行训练,我们使用Adam优化器,一个mini-batch大小为32,学习率为0.0001,而decay rates为β1 = 0.5, β2 = 0.999。
3. Experiments
3.1. Datasets
Flickr-Faces-HQ (FFHQ)[21]是一个高质量的人脸图像数据集,拥有70,000张图像,提供了年龄、种族和背景方面的各种图像。数据集没有提供任何属性标签。
CelebFaces Attributes (CelebA)[26]是一个大规模的人脸数据集,包含202,599张名人图片,每张图片都标注了40个二进制属性标签。在我们的实验中,我们没有使用属性标签来训练我们的模型。
EmotioNet[8]包含了95万张不同表情的人脸图像。面部表情注释了动作单位,但我们没有利用它们来训练我们的模型。
3.2. Baseline models
我们将其与使用非成对的标记数据集的基线模型进行比较。基线的所有实验都是使用原始代码和超参数进行的。由于XploreGAN在训练期间不使用任何标签,所以在测试时,我们选择最能估计其他基线模型使用的标签的伪标签(例如,最符合“blond”的伪标签)。我们的模型的每个结果都是从单个集群统计数据生成的。
StarGAN是一种先进的多领域图像转换模型,在训练过程中使用属性标签。
DRIT和MUNIT是最先进的在两个域之间执行多模态图像转换的模型。
3.3. Comparison on style normalization
我们对基于group的ASIN和基于instance的AdaIN进行了定性比较。为了公平比较,我们用在[17]中实现的AdaIN替换ASIN层,同时保持所有其他网络架构和训练设置。如图2所示:

AdaIN依靠单个图像实例来传递样式。AdaIN导致了在参考图像中存在纠缠属性的转换(例如,头发颜色/形状、性别、背景颜色;图2的最后三行)。相反,ASIN能够总结一组图像中的共同属性(例如,头发颜色)并转移其特定属性。这使得用户可以很容易地传输他们想要的特定属性,同时保持内容图像的所有其他属性(标识)不变。
3.4. Qualitative evaluation
如图4所示,我们对CelebA数据集上的人脸属性转换结果进行定性比较。

所有的基线模型都使用属性标签进行训练,而XploreGAN使用未标记数据进行训练。当我们增加k的数量时,我们可以发现一个属性的多个子集(例如,“women”的不同风格;在第3.6节中进一步讨论)。这可以被认为是发现了数据中的k种模式。因此,我们不仅可以比较多领域的转换,而且可以比较两个领域之间的多模态转换。从图4可以看出,我们的方法和其他使用标签训练的模型一样,能够产生高质量的翻译结果。此外,图3显示XploreGAN可以对各种数据集(FFHQ[21]、CelebA[26]和Emotionet[8])进行高质量的翻译。

我们在附录中提供了额外的定性结果。
3.5. Quantitative evaluation
高质量的图像翻译应该是:1)很好地传递目标属性,2)保持输入图像的身份,3)看起来真实。我们通过属性分类、人脸验证和用户研究定量地测量了三个质量指标。
Attribute classification. 为了衡量模型转移属性的程度,我们比较了合成图像在人脸属性上的分类精度。我们为CelebA数据集(训练和测试集的分割比为70%/30%)中选择的每个属性(金发、棕色、年老、男性和女性)训练一个二值分类器,结果在真实测试图像上的平均准确率为95.8%。我们用相同的训练集训练所有的模型,并在相同的测试集上进行图像变换。最后,我们使用上面训练好的分类器来测量变换后图像的分类精度。
令人惊讶的是,XploreGAN在几乎所有属性转换中都优于所有基线模型,如表1所示。
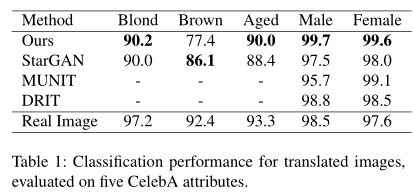
这表明,我们在未标记数据上训练的方法可以执行高质量的转换,与那些在标记数据上训练的模型一样好,有时甚至更好。
Identity preservation. 我们使用最先进的人脸验证模型来衡量翻译图像的身份保存性能。我们使用预先在Celeb-1M数据集[12]上训练过的ArcFace[6],其在CelebA测试集上的平均准确率为89.76%。然后,我们对5个面部属性(金发、棕发、年龄、男性和女性)在同一个看不见的测试集上进行图像转换。为了衡量一幅翻译后的图像对输入图像的身份保留程度,我们使用上述预先训练好的验证模型,对真图像和伪图像进行人脸验证精度的测量。如表2所示:
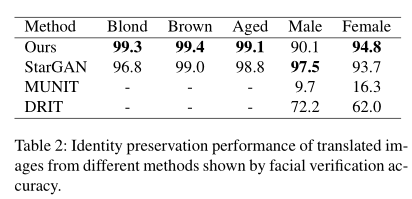
我们的方法生成的翻译结果可以与大多数基于属性标签的基线模型一样,甚至更好地保留输入图像的标识。尽管多模态图像转换模型(MUNIT和DRIT)显示了较高的分类性能(即我们观察到,它们倾向于修改输入,以至于极大地阻碍了身份保存。
User study. 为了评估翻译出来的结果对人眼来说是否真实,我们进行了一项有32名参与者的用户研究。用户被要求选择最成功的、产生了高质量的图像得输出,同时保持内容和传递目标属性。对于这6个属性中的每一个属性都给出了20个问题,总共有120个问题。请注意,MUNIT和DRIT生产多模态输出,因此随机选择一个单一的图像用于用户研究。表3显示了我们的模型在不同属性上的表现与监督模型一样好:

虽然StarGAN取得了很好的结果,但是它在H+G上的结果经常有绿色的伪影,这降低了用户的偏好。
3.6. Analysis on the clustering stage
Comparison on pre-trained feature spaces. 预先训练好的特征空间为未标记图像的分组提供了指导。我们发现,模型架构和预训练的数据集的差异会导致特征空间的显著差异,即表征偏差。我们试图利用这种“skewness”来识别某些类型的特征(例如,纹理或形状)——以不同的方向将新图像分组。
我们将主要比较两个特征空间:偏重纹理的BagNets和偏重形状的ResNets。已经发现ImageNet预训练的cnn更倾向于识别纹理而不是形状[9]。根据这一特性,与vanilla ResNets[14]相比,BagNets[3]被设计为通过限制接受野的大小来更敏感地识别局部纹理。它们被设计成专注于小的局部图像特征,而没有考虑到它们更大的空间关系。另一方面,在Stylized ImageNet[9]上训练的ResNet(表示ResNet (SIN))完全忽略纹理线索,而关注图像的全局形状。
图5给出了这两个特征空间的特征。

经过ImageNet训练的BagNets可以有效地检测详细的纹理线索(如肤色和纹理、年龄、头发颜色/形状、光线)。然而,BagNets或vanilla ResNets在检测面部情绪方面是无效的,因为他们倾向于产生偏向于局部纹理线索的聚类结果。为此,我们发现ResNet (SIN)在忽略纹理线索和关注全局形状信息(如面部表情、手势、观点)方面非常有效。考虑到这些特性,我们采用BagNet-17 (IN)作为CelebA[26]和FFHQ[21]数据集的特征提取器,采用ResNet-50 (SIN)作为EmotioNet[8]数据集的特征提取器。
Choosing the number of clusters. 如图6所示:

随着k的增加,单个金发簇被细分为特定类型的金发。因此,k值越小,聚类越紧凑,特征越明显,而k值越大,聚类特征越相似,特征越详细。在现实中,没有最优数量的k。换句话说,一个人如何定义在一个给定的数据集上的一个属性是高度主观的(例如,“浅妆”本身可以是一个单一的属性,或者它可能是进一步细分为“白皮肤”,“有眼影”,和“擦口红”)。在我们的模型中,用户可以通过调整k的个数来间接控制这种division的程度。
4. Related Work
Generative adversarial networks (GANs). GANs[10]在图像生成方面取得了显著的成功。它成功的关键是对抗性的损失,判别器试图区分真实和虚假的图像,而生成器试图通过产生真实的虚假图像来欺骗判别器。一些研究利用条件GANs来生成以类[27,29,30],文本描述[33,41,34],域信息[4,32],输入图像[18],或颜色特征[2]为条件的样本。在本文中,我们采用基于聚类统计的对抗损失来生成相应的翻译图像,使其与真实图像无法区分。
Unpaired image-to-image translation. 图像到图像的转换[18,45]最近取得了显著的成功。CycleGAN[44]将图像到图像的转换扩展到非成对图像的设置,这将深度学习模型的应用扩展到更多的数据集。多域图像到图像的转换模型[4,32]提出了在给定域标签时生成不同输出的方法。DRIT[23]和MUNIT[17]进一步开发图像转换模型,使用非成对数据产生随机多模态输出。现有的图像到图像的转换模型大多依赖标记数据。不像以前的方法,定义术语“非成对”与无监督同义,我们定义无监督包括未成对和未标记。根据我们的定义,以前在图像到图像的转换方面还没有解决过这种设置。
Clustering for discovering the unknown. 聚类是一种功能强大的无监督学习方法,它根据数据的相似性对数据进行分组。聚类用于发现图像[25]和视频[31,36,15,39]中新的对象类。我们的工作目标不是发现新的对象类,而是通过聚类发现未标记数据中的属性。查找属性是一项复杂的任务,因为单个图像可能有多个不同的属性。就我们所知,我们的工作是第一次使用未标记数据中新发现的属性来执行图像到图像的转换。
Instance normalization for style transfer. 为了简化神经网络的训练,最初引入了batch normalization (BN)。BN根据小批图像的均值和标准差对各特征通道进行归一化。 Instance normalization[37]对每个样本的均值和标准差进行采样。在扩展IN后,conditional instance normalizatio[7]为每种样式学习不同的参数集。Adaptive instance normalization(AdaIN)[16]执行归一化不需要额外的可训练参数,MUNIT增加了可训练参数以增强翻译能力。与在图像实例上执行样式转换的现有normalization方法不同,我们的attribute summary instance normalization(ASIN)使用集群统计数据来总结每个集群中的公共属性(即即质心μ和方差σ2),并允许精细、详细的属性转换。
5. Conclusion
在本文中,我们试图减轻标记数据在人脸图像翻译领域的必要性。针对未标记的原始数据,提出了一种非成对、未标记的多域图像-图像转换方法。我们利用预先训练好的特征空间中的先验知识来对未知的、未标记的图像进行分组。attribute summary instance normalization(ASIN)可以有效地总结集群中的公共属性,实现对特定属性的高质量翻译。我们证明,我们的模型可以产生与最先进的方法一样好的结果,有时甚至更好。

