
人脸检测和识别以及检测中loss学习 - 17 - Mis-classified Vector Guided Softmax Loss for Face Recognition - 1 - 论文学习
Abstract
深度卷积神经网络(CNNs)的发展使人脸识别得到了长远的发展,其核心任务是提高特征识别的能力。为此,提出了几个基于边缘的softmax损失函数(如角边缘、附加性边缘和附加性角边缘)来增加不同类别之间的特征边缘。然而,尽管取得了很大的成就,但主要存在三个问题:1)明显忽视了信息特征挖掘对区分学习的重要性;2)只从ground truth类鼓励特征边缘,没有实现与其他非ground truth类的区别;3)将不同类别之间的特征边界设置为相同且固定的值,可能不能很好地适应情况。针对这些问题,本文提出了一种新的loss函数,该函数自适应地强调错误分类的特征向量来指导鉴别特征学习。因此,我们可以解决上述所有问题,实现更有区别性的人脸特征。据我们所知,这是首次尝试将特征边缘和特征挖掘的优势继承为统一的loss function。在几个基准上的实验结果证明了对比最先的其他方法,我们的方法更具有效性。我们的代码可以在http://www.cbsr.ia.ac.cn/users/xiaobowang/找到。
Introduction
前三段介绍了下之前的工作,省略
虽然上述方法取得了良好的效果,但它们主要存在三个缺点:1)明显忽略了信息特征挖掘对于区分学习的重要性。要解决这个问题,可以求助于基于挖掘的softmax loss函数。Shrivastava等人(Shrivastava, Gupta, and Girshick. 2016)设计了hard挖掘策略(HM-Softmax),通过使用高loss样本构建mini-batch来提高特征识别。但是hard样本的百分比是由经验决定的,简单例子完全被抛弃。相比之下,Lin等人(Lin, Goyal, and Girshick. 2017)设计了一种相对soft的挖掘策略,即Focal loss (F-Softmax),将训练重点放在hard样本的稀疏集上。然而,hard样本的指示是不清楚的。因此,这两种基于挖掘的候选方法往往不能提高性能。如何从语义上选择hard样本仍然是一个有待解决的问题。2)仅从ground truth类的角度扩大了特征边缘,这是局部的,没有实现与其他非ground truth类的可区分性。3)最后但并非最不重要的是,他们通过对所有类使用相同且固定的边界来扩大特征边界,这在实践中可能并不合适,也可能效果不太好。
为了克服上述缺点,本文尝试设计一种新的损失函数,将难分类的例子明确表示为误分类的向量,并自适应地强调其重要性,以指导鉴别特征学习。综上所述,本文的主要贡献可以总结如下:
- 我们提出了一种新的MV-Softmax loss算法,它明确指出了hard例子,并着重于它们来指导鉴别特征学习。因此,我们新的损失也吸收了其他非ground-truth类的可识别性,同时也为不同的类提供了自适应的边界。
- 据我们所知,这是第一次尝试有效地将特征边界和特征挖掘技术的优点继承到一个统一的loss函数中。并深入分析了新损失与当前基于边界和基于挖掘的损失之间的关系和区别。
- 我们在LFW、CALFW、CPLFW、AgeDB、CFP、RFW、MegaFace、Trillion-Pair等常用基准上进行了大量实验,验证了新方法相对于基线softmax损失、基于挖掘的softmax损失、基于边界的softmax损失及其天然融合损失的优越性。
Preliminary Knowledge(省略)
Softmax
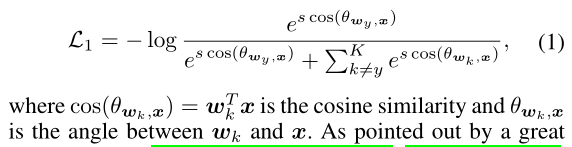
Mining-based Softmax.

Margin-based Softmax

Problem Formulation
首先,让我们回顾一下基于边界的softmax损失的公式,即公式3:
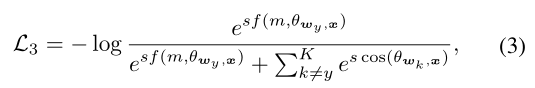
(1)忽略了信息特征挖掘对于鉴别学习的重要性。2)它只利用了ground truth类y 的可判别性,即f(m,Θwy, x),不考虑与其他非ground truth类k的潜在区别性,其中k不等于 y, k∈{1,2,…,K}\{y}。3)简单地使用相同且固定的边界m1, m2或m3来扩大不同类别之间的特征边界。
Naive Mining-Margin Softmax Loss
为了解决第一个缺点,人们可能会求助于hard例子挖掘策略(Shrivastava, Gupta, and Girshick. 2016;(2017)。基于挖掘的损失函数主要用于困难样本的训练,而基于边界的损失函数主要用于扩大不同类别之间的特征边界。因此,这两个分支是正交的,可以无缝地结合到彼此,导致生成一个简单的动机,即直接集成它们:
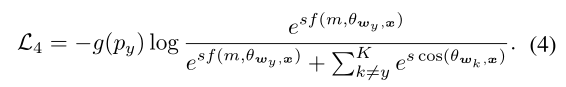
公式Eq.(4)的确通过指标函数g(py)涉及了信息特征,但在实践中对其改进有限。这背后的原因可能是,对HM-Softmax (Shrivastava, Gupta, and Girshick. 2016)来说,它明确地指出了困难的例子,但却抛弃了容易的例子。对于F-Softmax (Lin, Goyal, and Girshick. 2017),它使用了所有的例子,并通过一个调节因子对它们重置权重,但是难的例子对于训练来说并不清楚,也没有直观的解释。这促使我们设计更有效的方法来提高性能。
Mis-classified Vector Guided Softmax Loss
直觉上说,考虑良好分离的特征向量对学习问题的影响很小。这意味着错误分类的特征向量对于提高特征的可分辨性更为关键。为此,我们或者引入一种更优雅的方法,将训练重点放在真正具有信息性的特性上(即错误分类向量)。具体来说,基于基于边界的softmax损失函数,我们定义了一个二值指标Ik,自适应地表示当前阶段某个样本(特征)是否被特定分类器wk(其中k不等于其真正的类y)误分类:
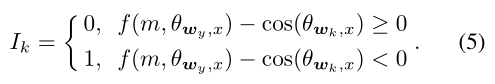
从Eq.(5)的定义可以看出,如果一个样本(特征)分类错误,即, f(m, Θwy, x) - cos(Θwk, x) < 0(例如:,在图1的左子图中,特征x2属于类1,但分类器w2对其进行了错误分类,即f(m,Θw1, x2) - cos(Θw2, x2) < 0),该样本x2将会被暂时强调,即标Ik = 1。这样,困难的例子就被明确的指出来,我们主要针对这些困难的例子进行区分训练。因此,我们将 Mis-classifie Vector guided Softmax (MV-Softmax)损失表示为:
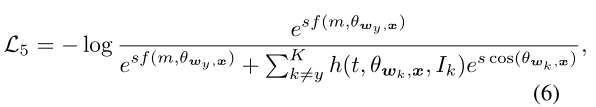
其中h(t,Θwk,x, Ik)≥1是一个重置权重函数,以强调指明的错误分类向量。这里我们给出了两个候选,一个是所有错误分类的类的固定权重:
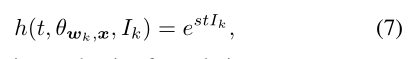
另一个是可适应的公式:
![]()
其中t >= 0是一个预先设置的超参数。显然,当t=0时,设计的MV-Softmax损失等式(6)变得和原来基于边界的softmax损失等式(3)完全一样了
Comparision to Mining-based Softmax Losses. 为了说明我们的MV-softmax loss相对于传统基于挖掘的loss函数(例如HM-Softmax (Shrivastava, Gupta, and Girshick. 2016)和F-Softmax (Lin, Goyal, and Girshick. 2017)的优势,图1给出了一个toy示例:
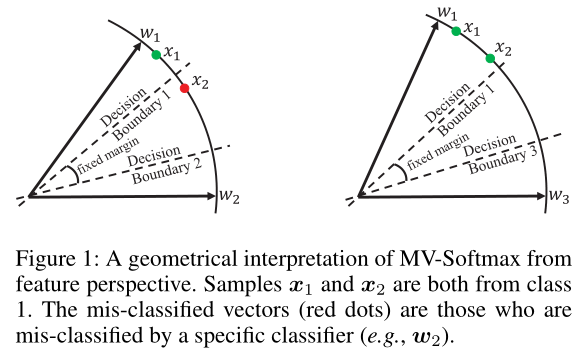
假设我们有两个样本(特征)x1和x2,它们都来自类1,其中x1是分类良好的,而x2不是。HM-Softmax经验地表示了困难样本,抛弃了简单样本x1,使用困难样本x2进行训练。F-Softmax没有明确表示困难样本,但它重新加权所有的样本,使较困难的一个x2有相对较大的损失值。这两种策略都是直接从损失的角度出发的,难例的选择没有语义指导。我们的MV-Softmax损失Eq.(6)是从一个不同的方式。首先,根据决策边界对难例(误分类向量)进行语义标注。以往方法的困难定义为特征(样本)和特征(样本)之间的全局关系。而我们的困难是特征和分类器之间的局部关系,这更符合区分性特征学习。然后,我们从概率的角度来强调这些困难的例子。具体来说,由于交叉熵损失 -log(p)是一个单调递减函数,降低错误分类向量x2的概率p(原因是h(t,Θwk,x,I k)≥1,见方程式(7)和(8)),即增加整个等式6的交叉熵损失值L5,这将增加其训练的重要性。综上所述,我们可以断言,我们的错误分类向量引导挖掘策略,在区分特征学习方面比以往的策略更优越。
Comparision to Margin-based Softmax Losses. 相同地,假设我们有来自类1的样本x2,且其没有正确分类(如图1左图的红点)。原始的softmax loss旨在让![]()
![]()
![]() 。为了让该目标函数更严格,基于边界的损失函数介绍了一个来自ground truth类(即Θ1)角度的边界函数
。为了让该目标函数更严格,基于边界的损失函数介绍了一个来自ground truth类(即Θ1)角度的边界函数![]()
![]()
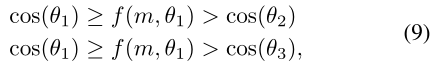
其中,f(m, Θ1)对于不同的类具有相同且固定的边界,忽略了与其他非ground truth类(如:Θ2和Θ3)的潜在区别性。为了解决这些问题,我们的MV-Softmax loss试图从其他非ground truth类的角度进一步扩大特征。具体来说,我们为错误分类的特征x2引入了一个边界函数h∗(t,Θ2):
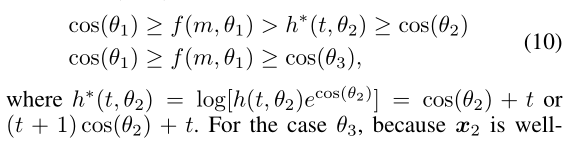
对于Θ3,因为x2被其正确分类(即判定x2不是类3),所以我们不需要对其添加额外的增强去进一步增大其的边界。而且,我们的MV-Softmax loss也为不同的类设置了不同的可适应边界。以 MV-AM-Softmax(即![]() )为例,对于错误分类的类,其边界为
)为例,对于错误分类的类,其边界为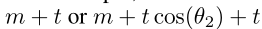 。然而对于正确分类的类,其边界为m。基于这些特性,我们的MV-Softmax loss解决了第二和第三个缺点
。然而对于正确分类的类,其边界为m。基于这些特性,我们的MV-Softmax loss解决了第二和第三个缺点
根据上面的讨论,我们总结出我们的新损失继承了特征边界和特征挖掘的优点到统一的损失函数中,因此可以期待其在人脸识别中获得更具区分性的特征
Optimization
在这部分,我们展示了我们的MV-Softmax loss(等式6)是可训练的,并能被经典的随机梯度下降法(SGD)优化。以前基于边界的softmax损失和这个提出的MV-Softmax损失之间的差别主要取决于最后的全连接层:
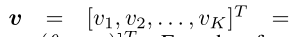
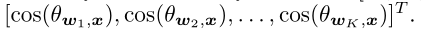
对于前向传播,当k=y时,其与原始的基于边界的softmax 损失相同(即![]()
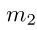 )。当k不等于y时,有两种情况,如果特征向量被特定分类器正确分类,则它也是与原始softmax相同(即
)。当k不等于y时,有两种情况,如果特征向量被特定分类器正确分类,则它也是与原始softmax相同(即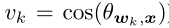 )。否则,它将会重新使用一个固定权重
)。否则,它将会重新使用一个固定权重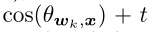 或一个自适应权重
或一个自适应权重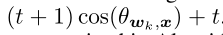 重新计算。我们方法的整个方案如下面的算法1:
重新计算。我们方法的整个方案如下面的算法1:

Experiments
省略
Conclusion
本文提出了一个简单但非常有效的损失函数,即误分类矢量引导的softmax损失(即MV-Softmax),用于人脸识别任务。具体来说,MV-Softmax loss明确地专注于对错误分类的特征向量进行优化。从而将特征边界和特征挖掘的动机在语义上继承为一个统一的损失函数。因此,它比基线Softmax损失、当前基于挖掘的损失、基于边界的损失和它们的简单融合的损失表现出更高的性能。在几个人脸识别基准上的广泛实验已经验证了我们的新方法在最先进的替代方案的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号