GAN Compression - 1 - 论文学习
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Abstract
条件生成对抗网络(cGANs)为许多计算机视觉和图形应用提供了可控的图像合成。然而,最近的cGANs比现代识别CNNs的计算强度高了1-2个数量级。例如,GauGAN每个图像消耗281G MACs,而MobileNet-v3只消耗0.44G MACs,这使得交互式部署变得非常困难。在这项工作中,我们提出了一个通用的压缩框架来减少cGANs中生成器的推理时间和模型大小。直接应用现有的CNNs压缩方法会产生较差的性能,这是由于GAN训练的难度和生成器架构的差异造成的。我们以两种方式应对这些挑战。首先,为了稳定GAN训练,我们将原模型的多个中间表示的知识转移到其压缩模型中,将非成对和成对学习统一起来。其次,我们的方法不是重用现有的CNN设计,而是通过神经架构搜索(NAS)自动找到有效的架构。为了加速搜索过程,我们通过权值共享来解耦模型训练和架构搜索。实验证明了我们的方法在不同的监督设置(配对和不配对)、模型架构和学习方法(如pix2pix、GauGAN、CycleGAN)下的有效性。在不损失图像质量的前提下,我们将CycleGAN的计算量减少了20×以上,GauGAN的计算量减少了9×,为交互式图像合成铺平了道路。code和demo是公开的。
1. Introduction
生成式对抗网络(GANs)[14]擅长合成逼真的照片。其条件扩展,条件GANs[76,47,27],允许可控的图像合成,并使许多计算机视觉和图形应用程序的应用,如交互式地从用户画像[49]创建一个图像、或将舞蹈的运动视频转移到一个不同的人[62,8,1]、或为远程社会互动[64]创建虚拟现实面部动画 变成可能。所有这些应用程序都需要模型与人交互,因此需要低延迟的设备性能以获得更好的用户体验。然而,边缘设备(移动电话、平板电脑、VR耳机)受到内存和电池等硬件资源的严格限制。这种计算瓶颈阻碍了条件GANs在边缘设备上的部署。
与图像识别CNNs[32, 57, 19, 25]不同的是,基于图像条件的GANs的计算量非常大。例如,被广泛使用的CycleGAN模型[76]需要超过50G MACs,比MobileNet[25]多100倍。更近期的模型GauGAN[49],虽然能生成逼真的高分辨率图像,但需要250G MACs,比MobileNet多500倍[25,53,24]。
在这项工作中,我们提出了GAN压缩,这是一种通用的压缩方法,用于减少条件GANs的推理时间和计算成本。我们观察到压缩生成模型面临两个基本的困难:GANs神经网络是不稳定的,特别是在不配对的情况下;生成器也不同于识别CNN,因此很难重用现有的CNN设计。为了解决这些问题,我们首先将知识从原始teacher生成器的中间表示层转移到其相应的压缩student生成器层。我们还发现,使用教师模型的输出为非配对训练创建伪配对是有益的。这将把非配对学习转化为配对学习。其次,我们使用神经架构搜索(NAS)来自动找到一个计算成本和参数显著减少的高效网络。为了降低训练成本,我们通过训练一个包含所有可能的channel数量配置的“once-for-all网络”,将模型训练从架构搜索中解耦出来。once-for-all网络可以通过权值共享产生多个子网络,不需要再训练就可以评估每个子网络的性能。我们的方法可以应用于各种条件GAN模型,无论模型架构、学习算法和监督设置(配对或不配对)是什么样。
通过大量的实验,我们证明我们的方法可以减少三种广泛使用的条件GAN模型的计算量,包括pix2pix [27], CycleGAN [76], GauGAN[49],在MACs上减少9×到21×的计算量,同时不丢失生成图像的视觉保真度(几个例子见图1):
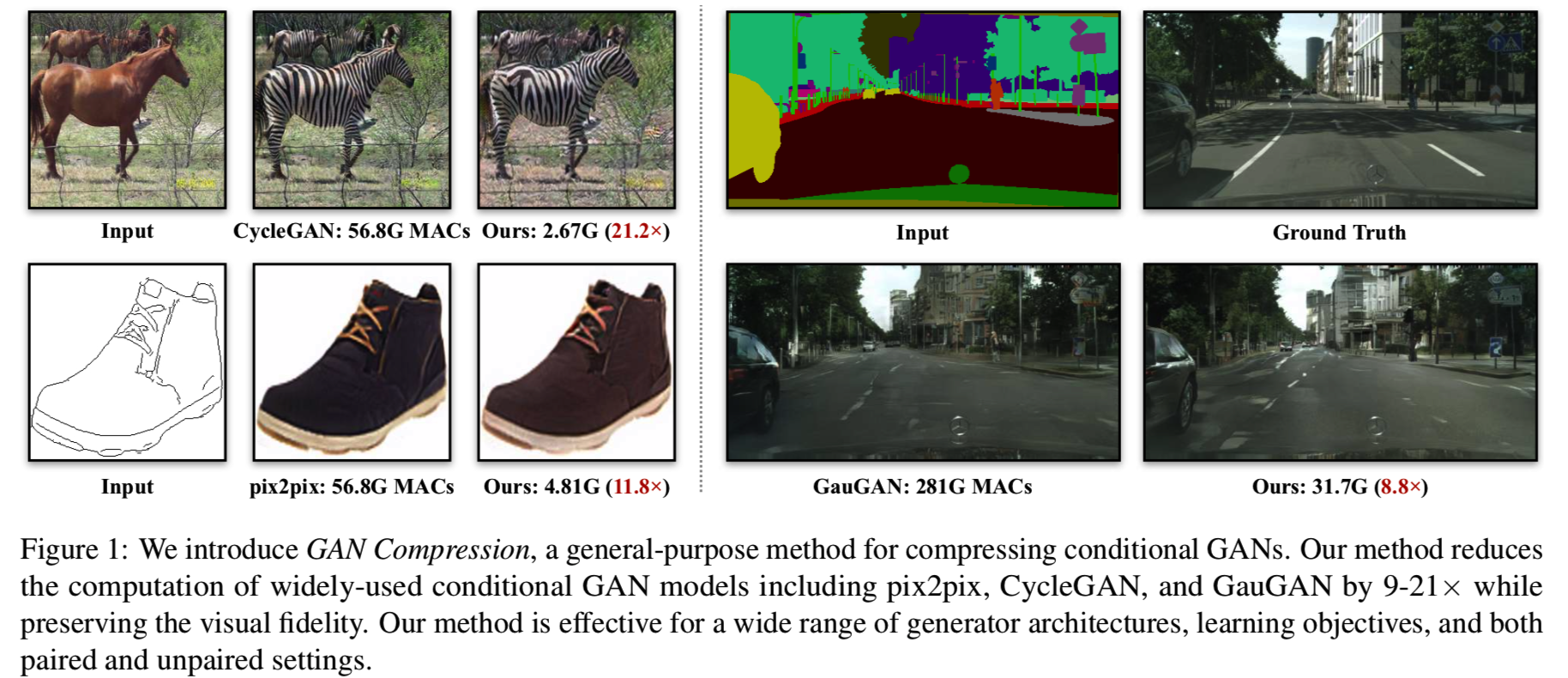
最后,我们在移动设备(Jetson Nano)上部署了压缩的pix2pix模型,并演示了一个交互式的edges2shoes应用程序demo
2. Related Work
Conditional GANs. 生成式对抗网络(GANs)[14]擅长合成逼真的照片结果[29,5]。它的条件形式,条件GANs[47,27]进一步支持可控的图像合成,允许用户合成给定各种条件的输入的输出图像,如用户草图[27,54]、类标签[47,5]或文本描述[51,73]。后续的工作进一步提高了结果的分辨率和真实感[63,49]。后来,提出了几种学习无配对数据条件GANs的算法[59、55、76、30、67、40、11、26、33]。
高分辨率、真实感的合成结果需要大量的计算。如图2所示:
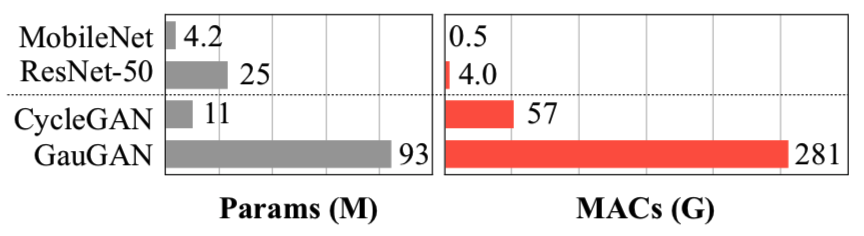
虽然模型大小与图像识别CNNs[19]的大小相同,但是条件GANs需要比其大两个数量级的计算量。这使得在有限的计算资源下将这些模型部署到边缘设备非常具有挑战性。在这项工作中,我们关注用于交互式应用的有效的图像条件GANs架构。
Model acceleration. 在各种实际应用中,硬件高效的深度学习受到了广泛的关注[18,17,75,61,16]。为了减少网络权重的冗余,研究人员提出了修剪各层之间的连接[18,17,65]。然而,经过修剪的网络需要专门的硬件来实现它的完全加速。随后的几项工作提出了修剪整个卷积滤波器(convolution filter)[21,36,41],以提高计算的规律性。AutoML for Model Compression (AMC)[20]利用强化学习来自动确定每一层的修剪比例。Liu等人后来用进化搜索算法代替了强化学习。最近,Shu等人[56]通过对原有的CycleGAN算法进行了修改,提出了CycleGAN的协同进化剪枝方法。这种方法是为特定的算法量身定做的。在适当的压缩比(4.2×)下,压缩模型显著提高了FID。相比之下,我们的模型无关方法可以应用于具有不同学习算法、体系结构以及成对和非成对设置的条件GANs。我们假设不知道原始的cGAN学习算法。实验表明,我们的通用方法在保留原模型FID的同时,达到了21.1×压缩比(比特定于CycleGAN的方法[56]好5倍)。
Knowledge distillation. Hinton等人在[23]中引入了知识蒸馏,将更大的教师网络中的知识转移到更小的学生网络中。学生网络被训练成模仿教师网络的行为。有几种方法利用知识蒸馏来压缩识别模型[45,9,34]。最近,Aguinaldo等人[2]采用了这种方法来加速无条件的GANs。与它们不同的是,我们关注的是条件GANs。我们在条件GANs上实验了几种蒸馏方法[2,68],但只观察到有限的改进,不足以用于交互式应用。详情请参阅附录6.2。
Neural architecture search. 神经结构搜索(Neural Architecture Search, NAS)成功地设计出了在大规模图像分类任务[78,37,38]中表现优于手工制作的神经网络结构。为了有效降低搜索成本,研究人员最近提出了一种once-for-all神经结构搜索[39,7,66,15,24,4,6],其中不同的候选子网络可以共享同一组权值。虽然所有这些方法都侧重于图像分类模型,但我们使用NAS研究了有效的条件GANs体系结构。
3. Method
压缩交互式应用程序的条件生成模型具有挑战性,原因有二。首先,GANs的训练动态本质上是高度不稳定的。其次,识别和生成模型在架构上的巨大差异使得现有的CNN压缩算法难以直接应用。针对上述问题,我们提出了一种适合高效生成模型的训练协议(第3.1节),并通过神经结构搜索(NAS)进一步提高压缩比(第3.2节)。整个框架如图3所示:

这里,我们以ResNet生成器[28,76]为例。但是,相同的框架可以应用于不同的生成器架构和学习目标。
3.1. Training Objective
Unifying unpaired and paired learning. 条件GANs的目标是学习源域X和目标域Y之间的映射函数G。它们可以使用配对数据({xi, yi}i=1N,其中xi∈X和yi∈Y)或未配对数据(源数据集{xi}i=1N到目标数据集{yj}j=1M)进行训练。这里,N和M表示训练图像的数量。为了简单起见,我们省略了下标i和j。已经提出了几个学习目标来处理成对和非成对的设置(例如,[27,49,63,76,40,26])。广泛的训练目标使得构建通用的压缩框架非常困难。为了解决这个问题,我们在模型压缩设置中统一了非成对和成对的学习,而不管教师模型最初是如何训练的。给定原始的教师发生器G',我们可以将不配对的训练集转化为成对的训练集。特别地,对于非成对的设置,我们可以将原始生成器的输出视为我们的ground-truth,并使用成对的学习目标来训练我们的压缩生成器G。我们的学习目标可以总结如下:

通过这些修改,我们可以将相同的压缩框架应用于不同类型的cGANs。此外,如4.4节所示,使用上述伪对进行学习,与原始的非成对训练设置相比,训练更加稳定,效果也更好。
由于未配对训练已经转化为配对训练,除非另有说明,我们将在配对训练设置中讨论下面的章节。
Inheriting the teacher discriminator. 虽然我们的目标是压缩发生器,但判别器D在识别当前发生器[3]的弱点时,会存储已学习GAN的有用知识。因此,我们采用相同的判别器结构,使用teacher预先训练的权重,并与我们的压缩发生器一起对判别器进行微调。在我们的实验中,我们观察到一个预先训练的判别器可以指导我们的student发生器的训练。使用一个随机初始化的鉴别器往往会导致严重的训练不稳定性和图像质量的下降。GAN的目标函数正式表述为:
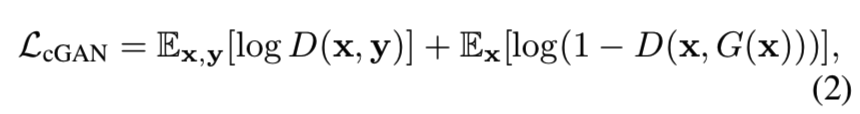
在这里,我们使用来自teacher判别器D'的权重来初始化student判别器D。G和D使用标准的极小极大优化[14]进行训练。
Intermediate feature distillation. 知识蒸馏是一种广泛使用的CNN模型压缩方法[23,45,9,68,34,50,10]。通过匹配输出层的对数分布,可以将知识从教师模型转移到学生模型,提高学生的性能。然而,条件GANs[27,76]通常输出的是确定性的图像,而不是概率分布。因此,很难从教师的输出像素中提取出black知识。特别是在成对训练的情况下,教师模型生成的输出图像与真实目标图像相比,基本不包含额外的信息。附录6.2中的实验表明,在配对训练中,单纯地模仿教师模型的输出并没有带来改进。
为了解决上述问题,我们匹配教师生成器的中间表示,像之前的工作所探索的那样[34,71,9]。中间层包含更多的channels,提供更丰富的信息,并允许学生模型获得除输出之外的更多信息。蒸馏目标函数可以形式化为:

其中,Gt(x)和G't(x)是学生和教师模型中第T个选择层的中间特征激活,T表示层数。1×1可学习卷积层ft将学生模型的特征映射到教师模型特征中相同数量的channels。我们共同优化Gt和ft,使蒸馏损失最小化。附录6.1详细说明了我们在实践中选择的层。
Full objective. 我们的最终目标如下:
![]()
其中超参数λrecon和λdistill控制每个项的重要性。详情请参阅附录6.1。
3.2. Efficient Generator Design Space
选择一个设计良好的学生架构对于知识蒸馏的最终表现是至关重要的。我们发现,单纯地缩小教师模型的通道数并不能产生一个紧凑的学生模型:当计算减少超过4倍时, 性能开始显著下降。其中一个可能的原因是现有的生成器架构通常采用图像识别模型[43,19,52,43],可能不是图像合成任务的最佳选择。下面,我们将展示如何从现有的cGAN生成器派生出更好的架构设计空间,并在该空间内执行神经架构搜索(NAS)。
Convolution decomposition and layer sensitivity. 现有的生成器通常采用vanilla卷积来遵循分类和分割CNNs的设计。最近高效的CNN设计广泛采用了卷积的分解版本(depthwise+pointwise)[25],这证明了有更好的性能计算权衡。我们发现使用分解的卷积也有利于cGANs中生成器的设计。
不幸的是,我们早期的实验已经表明,直接对所有卷积层进行分解(如在分类器中)将显著降低图像质量。分解一些层会立即影响性能,而其他层则更健壮。此外,这个层敏感性模式也不同于识别模型。例如,在ResNet生成器[19,28]中,resBlock层消耗了大部分的模型参数和计算成本,而几乎不受分解的影响。相反,上采样层有更少的参数,但是对模型压缩相当敏感:适度的压缩会导致很大的FID退化。因此,我们只分解resBlock层。我们在第4.4节中对层的敏感性进行了全面的研究。
Automated channel reduction with NAS. 现有的生成器在所有层上使用手工制作的(而且基本上是统一的)通道数,其包含冗余信息,远远不是最优的选择。为了进一步提高压缩比,我们使用通道剪枝方法[21,20,41,77,44]来自动选择生成器中的通道宽度来去除冗余,这样可以二次减少计算量。我们支持关于通道数量的细粒度选择。对于每个卷积层,通道的数量可以从8的倍数中选择,这平衡了MACs和硬件并行性[20]。
给定可能的通道配置{c1,c2,…,cK},其中K是要修剪的层数,我们的目标是使用神经结构搜索找到最佳的通道配置![]() ,其中Ft为计算约束。一种直接的方法是遍历所有可能的通道配置,训练它至收敛,然后评估并选择性能最好的生成器。然而,随着K的增加,可能的配置的数量呈指数级增长,每个配置可能需要不同的超参数,这些超参数与每个项的学习率和权重有关。这种尝试和错误的过程太耗时了。
,其中Ft为计算约束。一种直接的方法是遍历所有可能的通道配置,训练它至收敛,然后评估并选择性能最好的生成器。然而,随着K的增加,可能的配置的数量呈指数级增长,每个配置可能需要不同的超参数,这些超参数与每个项的学习率和权重有关。这种尝试和错误的过程太耗时了。
3.3. Decouple Training and Search
为了解决这个问题,我们将模型训练从架构搜索中解耦出来,就像最近once-for-all神经架构搜索方法的工作一样[7,6,15]。我们首先训练一个支持不同channels数量的once-for-all网络[6]。每个通道数目不同的子网络都经过同等的训练,可以独立运行。子网络与“once-for-all”网络共享权重。图3说明了整个框架。我们假设原始的教师生成器有{ck0}k=1K个通道。对于一个给定的通道数量配置{ck}k=1K ,ck≤ck0,我们按照Guo等人的[15]方法,从“once-for-all”网络的相应权张量中提取第一个{ck}k=1K的通道,得到子网络的权值。在每个训练步骤,我们随机采样带有某通道数量配置的子网络,计算出输出和梯度,使用我们的学习目标函数(等式4)提取和更新权重。由于权重在最初的几个通道更新更加频繁,他们在所有的权重中发挥更重要的作用。(once-for-all可见ONCE-FOR-ALL - 1 - 论文学习)
在对“once-for-all”网络进行训练后,我们通过直接评估验证集上每个候选子网络的性能来找到最佳的子网络。由于“once-for-all”网络经过了充分的训练,并进行了权值共享,因此不需要进行微调。当从零开始训练时,这近似于模型的性能。通过这种方式,我们可以解耦生成器架构的训练和搜索:我们只需要训练一次,但是我们可以评估所有可能的通道配置,而不需要进一步的训练,并选择最好的一个作为搜索结果。我们还可以选择微调所选的体系结构,以进一步提高性能。我们在4.4节中报告了这两种变体。
4. Experiments
4.1. Setups
Models. 在三个条件GAN模型上进行了实验,验证了该方法的通用性。
- CycleGAN[76]是一种非成对的图像到图像的翻译模型,它使用一个基于resnet的生成器[19,28]将图像从源域转换为目标域,而不使用成对。
- Pix2pix[27]是一个基于条件GAN的成对图像到图像的翻译模型。在这个模型中,我们将原始的U-Net生成器[52]替换为基于resnet的生成器[28],因为我们观察到,在相同的学习目标下,基于resnet的生成器以更少的计算成本获得更好的结果。有关详细的U-Net与ResNet基准测试,请参见附录6.2。
- GauGAN[49]是一个最先进的成对图像到图像的翻译模型。它可以生成一个给定一个语义标签map的高保真图像。
Datasets. 使用了如下的四个数据:
- Edges→shoes. 我们使用来自UT Zappos50K数据集[69]的50,025张图像。我们随机分离数据集,使验证集有2048张图像,用于Fréchet初始距离(FID)(见4.2节)的稳定评估。我们在这个数据集上评估了pix2pix模型。
- Cityscapes. 该数据集[12]包含德国街景的图像。训练集和验证集分别由2975和500幅图像组成。我们在这个数据集上评估了pix2pix和GauGAN模型。
- Horse↔zebra. 该数据集由1187张马图像和1474张斑马图像组成,这些图像最初来自于ImageNet[13],并在CycleGAN中使用[76]。验证集包含120幅马的图像和140幅斑马的图像。我们在这个数据集上评估CycleGAN模型。
- Map↔aerial photo. 该数据集包含从谷歌地图中提取的2194张图像,并用于pix2pix[27]。训练集和验证集分别包含1096和1098张图像。我们在这个数据集上评估了pix2pix模型。
Implementation details. 对于CycleGAN和pix2pix模型,我们在所有实验中对生成器和判别器的训练都使用了0.0002的学习率。
数据集Horse↔zebra、Edges→shoes、Map↔aerial photo、Cityscapes的batch size分别设置为1、4、1、1。对于GauGAN模型,我们遵循原始论文[49]的设置,除了batch size设置为16而不是32。我们发现,我们可以使用更小的batch size实现一个更好的结果。有关更多实现细节,请参见附录6.1。
4.2. Evaluation Metrics
我们介绍了评价合成图像等价性的指标。
Fréchet Inception Distance(FID)[22]. FID分数用于计算从真实图像中提取的特征向量分布与使用InceptionV3[58]网络生成的图像之间的距离。该分数衡量的是真实图像和生成图像分布的相似性。得分越低,表示生成的图像质量越好。我们使用开源的FID评估代码(https://github.com/mseitzer/pytorch- fid)
Semantic Segmentation Metrics. 根据之前的工作[27,76,49],我们采用语义分割度量来评估Cityscapes数据集上生成的图像。我们对生成的图像运行语义分割模型,并比较分割模型的性能。我们选择均值平均精度(Mean Average Precision, mAP)作为分割指标,并使用DRN-D-105[70]作为分割模型。更高的mAPs意味着生成的图像看起来更真实,更好地反映输入标签映射。
4.3. Results
我们报告了压缩CycleGAN、pix2pix和GuaGAN在表1中的四个数据集上的定量结果:

通过使用“once-for-all”网络中性能最好的子网,我们的GAN压缩方法实现了较大的压缩比。它可以将最先进的条件GANs压缩9-21倍,将模型尺寸缩小5-33倍,模型性能的下降几乎可以忽略不计。具体来说,我们提出的方法与之前的协同进化方法[56]相比,具有明显的CycleGAN压缩优势。我们可以将CycleGAN generator的计算量减少21.2×,与之前特定于CycleGAN的方法[56]相比,减少了5×,同时实现了更好的FID,超过30。
Performance vs. Computation Trade-off. 除了可以获得较大的压缩比外,我们还验证了我们的方法可以在不同的模型尺寸下持续地提高性能。以pix2pix模型为例,我们绘制了Cityscapes和Edges→shoes数据集的性能vs计算权衡结果,如图6所示:
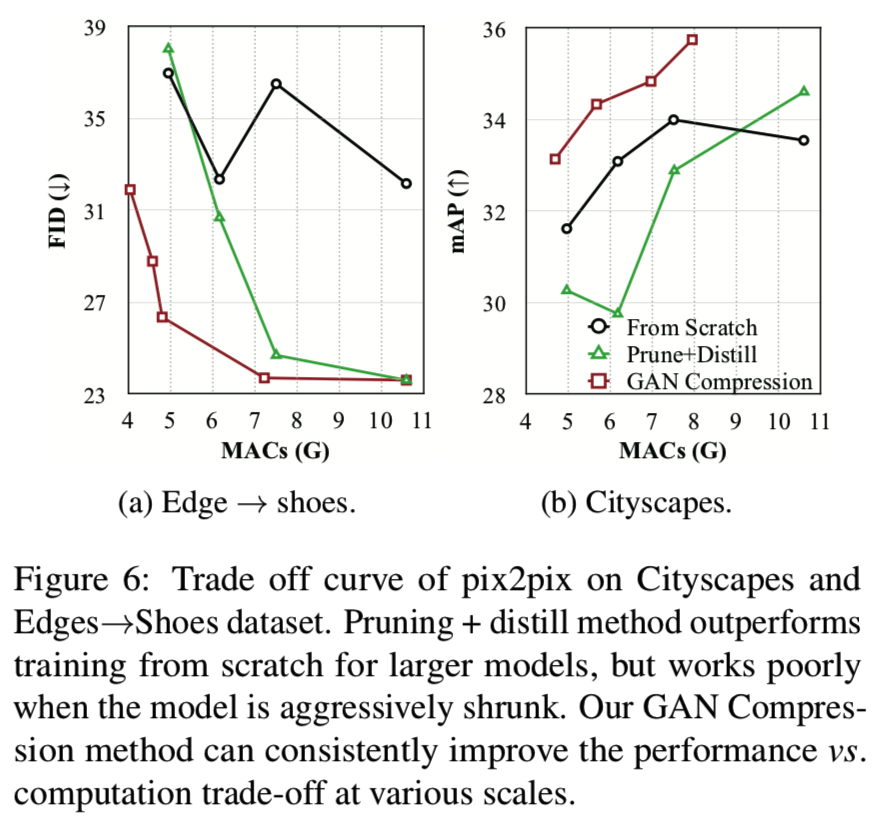
首先,在大模型尺寸情况下,prune +distill(不含NAS)的效果优于从零开始的训练,显示了中间层蒸馏的有效性。不幸的是,随着通道的不断缩小,学生和老师之间的能力差距变得太大了。结果,来自老师的知识对学生来说可能太深奥了,在这种情况下,蒸馏甚至可能对学生的模型产生负面影响。
相反,我们的训练策略可以让我们自动找到一个学生和老师之间差距更小的子网络,这使得学习更容易。我们的方法始终比基线有很大的优势。
图4显示了几个示例结果:

我们提供了输入图像、它的ground-truth(非成对设置除外)、原始模型的输出和我们的压缩模型的输出。即使在较大的压缩比下,我们的压缩方法也能很好地保持输出图像的视觉保真度。对于CycleGAN,我们也提供了基线模型的输出(0.25 CycleGAN: 14.9×)。0.25倍的基线模型CycleGAN包含1/4通道,已经从零开始训练。我们的优势是明显的:基线模型很难在输出图像上创建斑马图案,且它的压缩比要小得多。在某些情况下,压缩模型可能会出现轻微的退化(例如,图4中第二条斑马的腿),但在其他情况下,压缩模型有时会超过原来的例子(例如,第一个和最后一个鞋的图像有更好的皮革纹理)。一般来说,我们的方法压缩的GAN模型能与原始模型的性能比较,上面的定量结果可表明。
Accelerate Inference on Hardware. 对于真实的交互应用程序,硬件上的推理速度的减少比计算量减少更重要。为了验证该方法的实际有效性,我们在不同计算能力的设备上测量了我们的压缩模型的推理速度。为了模拟交互式应用程序,我们使用batch size为1。我们首先执行100次热身的运行,并测量接下来100次运行的平均时间。结果如表2所示:

在Jetson Xavier的edge GPU上,压缩CycleGAN生成器的推理速度可以达到40 FPS左右,满足了交互应用的需求。我们注意到,与CPU相比,GPU上的加速没那么显著,这主要是由于并行度很大。然而,我们的重点是使生成模型在边缘设上更容易访问,强大的gpu可能是不可用的,因此该结果说明更多的人可以使用交互式的cGAN应用程序。
4.4. Ablation Study
下面,我们针对我们的个别系统组件和设计选择进行一些消融研究。
Advantage of unpaired-to-paired trainsform. 首先利用教师模型的输出,分析了将非成对条件GANs变换为伪成对训练集的优点。

图7a显示了原始的非配对训练和我们的伪配对训练的性能比较:

随着我们的计算预算的减少,由非配对训练方法产生的图像质量急剧下降,而我们的伪配对训练方法相对稳定。非配对训练要求模型足够强大,能够捕获源域和目标域之间复杂而模糊的映射。一旦学习了映射,我们的学生模型就可以直接从教师模型中学习。此外,学生模型仍然可以从遗传的判别器中学习关于真实目标图像的额外信息。
The effectiveness of intermediate distillation and inheriting the teacher discriminator. 表3展示了中间蒸馏和在pix2pix模型上的继承教师判别器的效果:

单独的修剪和提取中间特征并不能得到比基线化训练更好的结果。我们也探讨了判别器在修剪中的作用。训练前的判别器存储了原始生成器的有用信息,可以指导修剪后的生成器更快更好地学习。如果重新设置学生判别器,那么被修剪的学生生成器的知识将被随机初始化的判别器破坏,这将产生比从零开始的训练基线更糟糕的结果。
Effectiveness of convolution decomposition. 系统地分析了条件GANs对卷积分解变换的灵敏度。我们以CycleGAN的基于resnet的生成器为例,对其有效性进行了测试。根据ResNet生成器的网络结构,我们将其结构分为三部分:Downsample(3个卷积)、ResBlocks(9个residual block)和Upsample(最后两个反卷积)。为了验证每个阶段的灵敏度,我们将每个阶段的所有常规卷积替换为可分卷积[25]。性能下降情况见表4:
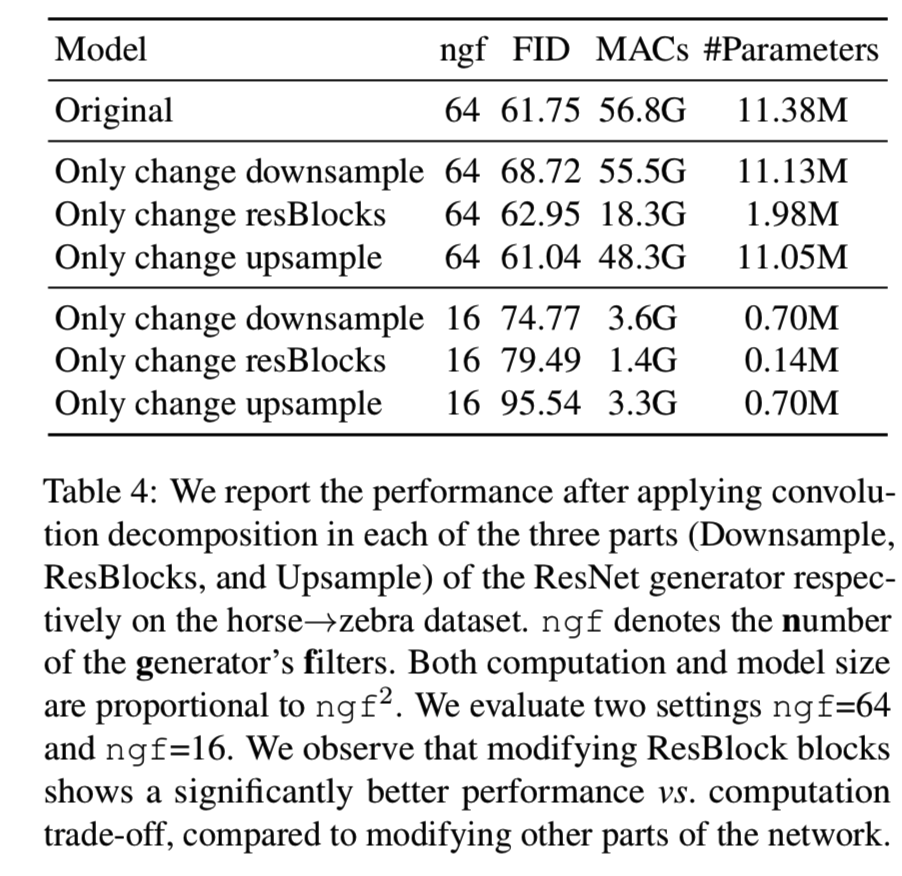
ResBlock部分需要相当大的计算量,因此在ResBlock中对卷积进行分解可以显著降低计算量。通过对ngf=64和ngf=16架构的测试,ResBlock-modified架构显示出更好的计算成本和性能权衡。我们进一步探讨了在Cityscapes数据集上使用ResBlock-modified架构的计算成本与性能权衡。图7b说明了这种mobilenet风格的架构始终比原来的架构更有效,原来的架构已经减少了大约一半的计算成本。
5. Conclusion
在这项工作中,我们提出了一个通用的压缩框架来减少条件GANs中生成器的计算成本和模型大小。我们利用知识蒸馏和神经结构搜索来缓解训练的不稳定性,提高模型的效率。大量的实验表明,该方法在保证视觉质量的同时,可以压缩多个条件GAN模型。未来的工作包括减少模型的延迟和用于生成视频模型[62,60]的有效架构。
6. Appendix
6.1. Additional Implementation Details
Complete Pipeline. 对于每个模型和数据集,我们首先从零开始训练一个MobileNet[25]风格的网络,然后使用这个网络作为一个教师模型来提取一个更小的学生网络。由经过蒸馏的学生网络初始化,我们训练一个“once-for-all”网络。然后,我们在一定的计算预算下评估所有的子网络。经过评估,我们在“once-for-all”网络中选择性能最好的子网络,并对其进行微调,以获得最终的压缩模型。对于每个任务,从零开始的MobileNet风格的老师和经过筛选的学生的大小列在表5中。

Training Epochs. 在所有的实验中,我们采用Adam优化器[31]和在开始保持相同的学习率,在训练的后期阶段线性衰减比率到零。我们对来自“once-for-all”[6]网络训练的从零开始的训练、蒸馏和微调使用不同的epochs。每个任务的具体时间列在表5中。
Distillation Layers. 在我们的实验中,我们选择了4种中间激活来进行蒸馏。我们将9个residual块分成3个大小的组,每三层使用特征蒸馏。我们的经验发现,这样的配置可以传递足够的知识,同时对于学生网络来说也很容易学习,如附录6.2所示。
Loss function. 对于pix2pix模型[27],我们用一个更稳定的Hinge GAN损失代替了普通的GAN损失[14][35,48,72]。对于CycleGAN模型[76]和GauGAN模型[49],我们采用与原始文献相同的设置,分别使用LSGAN损失[46]和Hinge GAN损失项。我们对教师和学生模型以及我们的基线使用相同的GAN损失函数。我们的论文中提到的超参数λrecon和λdistill如表5所示。
Discriminator. 判别器在GAN训练中起着至关重要的作用。对于每个模型,我们采用与原始工作相同的判别器架构。在我们的实验中,我们没有压缩判别器,因为它在推理时没有使用。我们也尝试过调整判别器的容量,但发现效果不佳。我们发现,与使用压缩判别器相比,使用带有压缩发生器的大容量判别器可以获得更好的性能。表5详细列出了每个判别器的容量。
6.2. Additional Ablation Study
Distillation. 最近,Aguinaldo等人[2]采用知识蒸馏来加速无条件GANs推理。它们强制学生生成器的输出近似于教师生成器的输出。然而,在配对条件GAN训练环境中,学生发生器已经能够从其ground-truth目标图像中获得足够的信息。因此,相比真实的输出,教师的输出不包含额外的信息。图8从经验上证明了这一点:

我们在cityscapes数据集[12]上运行pix2pix模型的实验。蒸馏基准[2]的结果甚至比从零开始训练的模型更差。我们的GAN压缩方法始终优于这两个基线。我们还将我们的方法与Yim等人[68]进行了比较,Yim等人是一种用于识别网络的最先进的蒸馏方法。表7是pix2pix模型的cityscapes数据集的基准测试:
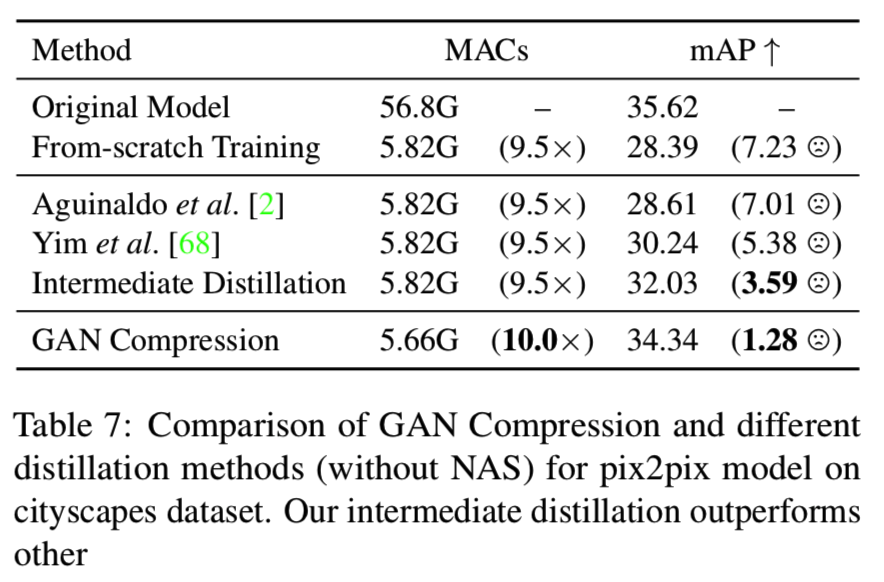
我们的GAN压缩方法比其他的蒸馏方法有很大的优势,为交互式图像合成铺平了道路。
Network architecture for pix2pix. 在pix2pix实验中,我们用基于resnet的生成器[28]代替了原来的U-net[52]。表6验证了我们的设计选择:
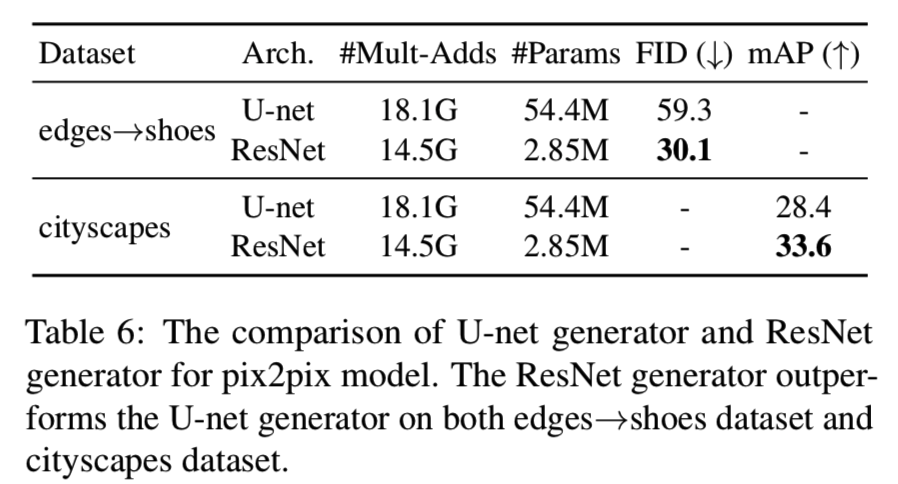
在edges→shoes和cityscapes数据集中,ResNet生成器实现了更好的性能。
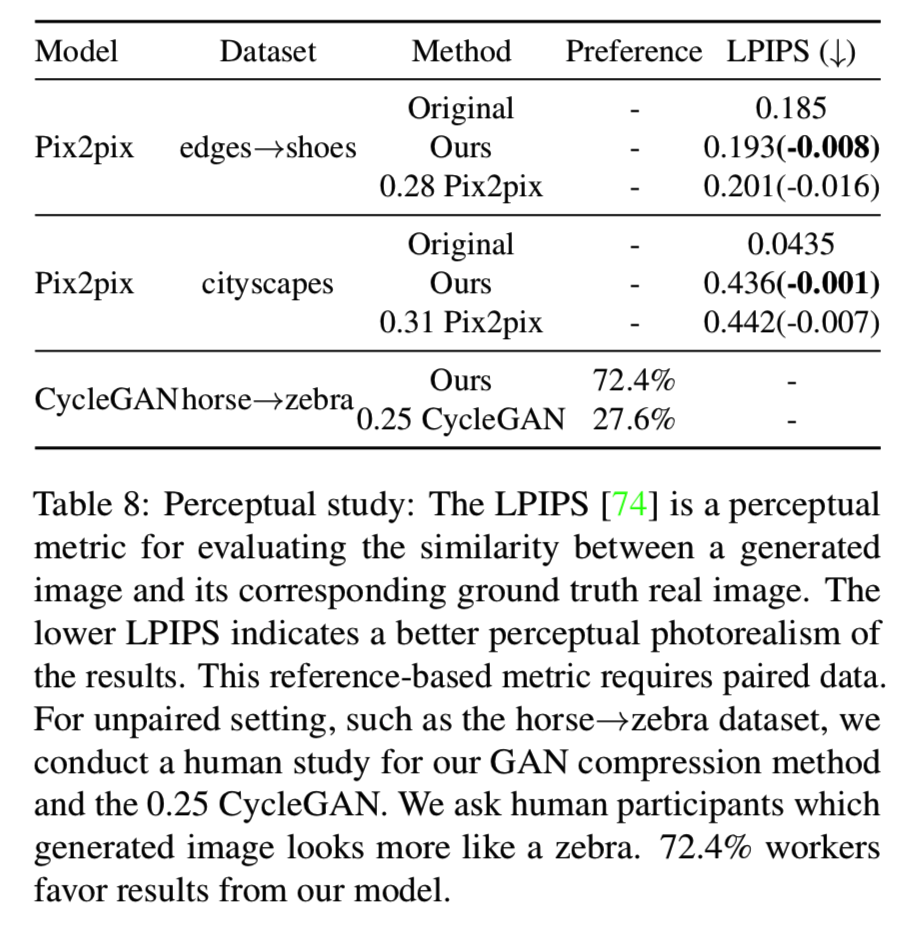
Perceptual similarity and user study. 对于成对的数据集,我们评估我们结果的感知真实性。我们使用LPIPS[74]度量来度量生成的图像和相应的真实图像的感知相似性。较低的LPIPS表示生成的图像质量更好。对于CycleGAN模型,由于没有成对的图像,我们对Amazon Mechanical Turk (AMT)上的horse→zebra数据集进行了人类偏好测试。我们基本上遵循[27]协议,只是我们要求工作人员在GAN压缩模型和0.25倍的CycleGAN之间决定哪个图像更像真实的斑马图像。表8显示了我们对pix2pix模型和CycleGAN模型的感知研究结果:
我们的GAN压缩方法明显优于简单的从头开始的训练基线。
6.3. Additional Results
在图9中,我们展示了我们提出的用于horse→zebra数据集的CycleGAN模型的GAN压缩方法的附加可视化结果:

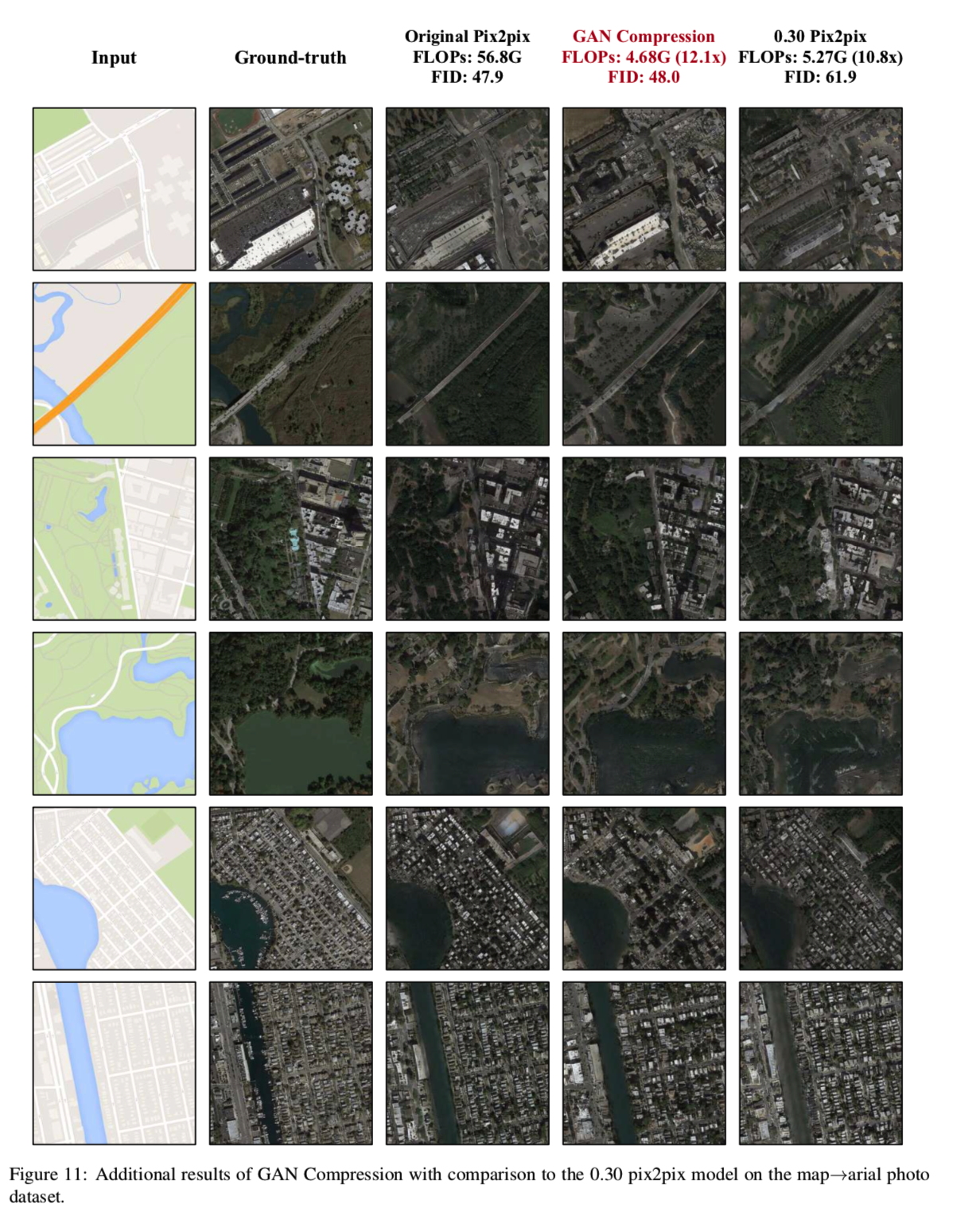
在图10、11和12中,我们展示了我们为pix2pix模型的edges→shoes、map→arial photo和cityscapes数据集所提出的方法的额外视觉结果。
在图13中,我们在cityscapes上显示了我们为GauGAN模型提出的方法的附加可视结果。