

人脸检测和识别以及检测中loss学习 - 15 - ShrinkTeaNet - 1 - 论文学习
ShrinkTeaNet: Million-scale Lightweight Face Recognition via Shrinking Teacher-Student Networks
Abstract
大规模的自然环境下的人脸识别技术近年来在许多实际工作中得到了成熟的应用。然而,这些系统是建立在GPU平台上的,并且大多部署很大的深度网络架构。给定一个高性能的大网络作为教师网络,该论文提出了一个简单和优雅的老师-学生学习范式,即ShrinkTeaNet,以训练一个便携式的学生网络,其显然具有较少的参数和能与教师网络相竞争的准确性。我们提出的老师-学生网络与以往的主要关注于封闭集问题的精度和压缩比的老师-学生网络相对比,在面对开放集问题,即大规模人脸识别问题中,我们的方法表现出了更强的鲁棒性。此外,本文还引入了一种新的角度蒸馏损失,用于提取教师超球面的特征方向和样本分布到它的学生网络中。然后ShrinkTeaNet框架利用特征嵌入的中间阶段和最后阶段呈现的教师模型的知识来有效地指导学生的学习过程。对LFW、CFP-FP、AgeDB、IJB-B和IJB-C Janus以及拥有100万个干扰物的MegaFace的评估表明,该方法能够有效地学习具有良好精度和紧凑大小的鲁棒的学生网络。我们的ShrinkTeaNet能够支持轻量级架构,在LFW上得到了99.77%的效果,在大型Megaface协议上得到了95.64%的效果。
1 Introduction
近年来,知识蒸馏以其将大网络的解释能力转移到其他轻量体系结构并使之更强大的能力而成为一个突出的课题。对于一个沉重但强大的网络(即教师网络),传统的精馏方法[6,7]鼓励输入轻量网络(即学生)的输出与输入教师网络的输出之间的相似性,以提高学生的表现。通过这种方式,学生可以有效地继承老师的能力和优势。已经提出了不同的度量方法用于相似度的度量,如L2损失或交叉熵损失。其他一些方法将这些度量注入中间层,并利用教师网络的各个方面,如特征量[8]、特征流[9]、激活图[10,11]、梯度图[12]和其他因素[13-15]。
虽然这些方法取得了显著的效果,但它们大多是针对封闭集问题提出的,封闭集中对象类是预定义的,并且在训练和测试阶段保持不变。根据这一假设,教师的预测分数可以被传递给学生,并作为监督信号。然而,当训练与测试的类别不同时(即开放集人脸识别),训练类别的预测分数会因为在测试阶段的变化而变得不那么有价值。因此,学生在处理新类时可能会有很多困难。此外,L2损失通常用于最后的输出层或中间层。这对于学生网络来说实际上是一个hard约束,因为它导致了两个网络特征之间的“精确匹配”。因此,当它被应用到多个层时,学生网络的训练过程可能会出现过于规范化的问题,变得不稳定。
Contributions. 提出了一种用于开放集大规模人脸识别的老师-学生学习算法——ShrinkTeaNet。这项工作的贡献有三个:
- 首先,我们没有强调特征之间的精确匹配,而是提出了一种新的角度蒸馏损失来提取从教师的超球面到学生的特征方向和样本分布。与L2损失相比,角度约束更“soft”,并为学生在嵌入过程中解释信息提供了更大的灵活性。此外,从其老师那里继承样本分布可以帮助学生在对象类改变时有效地重用所学习的知识。
- 其次,我们提出了一种新的ShrinkTeaNet框架,该框架在特征嵌入过程的每个阶段都能有效地提取教师的知识。
- 第三,评价结果显示了在小规模和大规模基准上的改进。
据我们所知,这是解决开放集大规模识别问题的最早的蒸馏方法之一。
2 Related work
轻量深层神经网络的设计越来越受到关注,主要是通过调整深层神经网络的结构来达到精度和速度之间的最佳平衡。除了直接设计新的深度网络架构外,根据所提出框架的动机和技术,还可以将其分为两类:网络修剪(network pruning)和知识蒸馏(knowledge distillation)。
Network Pruning. 网络裁剪是对重网络中的冗余进行分析和去除,得到精度相当的轻量形式。通常,这类方法的训练框架包括三个阶段,即(1)训练一个大型(超参数化模型),(2)根据一些标准对训练后的大型模型进行修剪,(3)对修剪后的模型进行微调以获得良好的性能。网络修剪分为两类。第一类是非结构化的剪枝方法,它从大型、超参数化和高性能的模型开始。Optimal Brain Damage[16]、Optimal brain surgeon[17]是基于损失函数Hessian的第一个网络修剪方法。[18]提出了通过设置阈值以下的权值为零,且精度不下降的剪枝网络,然后将权值量化到8位或更少来改善它,最后进行Huffman编码[19]。[21]也采用变分Dropout[20]方法来裁剪冗余权值。最近,[22]采用了基于随机门的L0-norm正则化的稀疏网络。在第二类,即结构化剪枝方法中,通道剪枝是一种常用的方法。[23]通过将过滤器剪枝看作为一个优化问题来基于其下一层剪枝过滤器。一个滤波器的重要性是计算出来的,在[24,25]中采用了它的绝对权重来决定保留哪些通道。[26]采用泰勒展开式,近似计算各通道对最终损失的重要性,并进行相应的修剪。
Knowledge Distillation. 知识蒸馏方法不像前一组那样试图“简化”计算昂贵的深层网络,而是旨在学习一个轻量级网络(即学生),使其能够模仿大网络(即教师)的行为。有了来自老师的有用信息,学生可以学习得更有效率,更“聪明”。在这种动机的启发下,[6]引入了第一个知识蒸馏作品,建议最小化从这两个网络的最后一层提取的特征之间的L2距离。Hilton等人后来指出,教师预测的类概率之间的隐藏关系对学生来说也是非常重要和有用的。在训练阶段,除了常规的带标签的训练数据外,还采用教师模型生成的软标签作为监督信号。除了[7]中的软标签外,Romero等人的[8]桥接了学生和教师网络的中间层,采用L2损失进一步监督学生的输出。文献中还利用了教师网络的其他几个方面和知识,包括特征激活图[11]、特征分布[14]、块特征流[9]、基于激活和梯度的注意图[10]、Jacobians矩阵[13]、无监督特征因子[15]等的转移。最近,Guo等人提出提取预测分数和梯度图,以增强学生对数据扰动的鲁棒性。对于各种学习任务,也提出了其他的知识蒸馏方法[9,27 - 31]。
3 Proposed method
本节首先描述了知识蒸馏问题的一般形式。然后考虑了人脸识别的两个重要设计方面:(1)蒸馏知识的表示;(2)如何在师生之间进行有效的转移。最后,介绍了带有角度精馏损失的ShrinkTeaNet结构。
让T : I → Z和S : I → Z 定义从图像域I到一个高级别的嵌入信息域Z的映射函数。函数T和S都是n个子函数Ti和Si的组合:
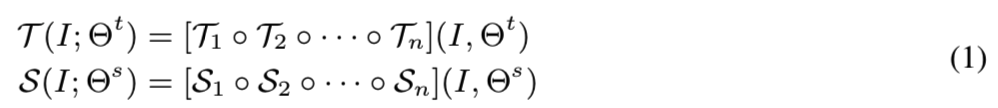
其中I表示输入图像,Θt和Θs分别是T和S的参数。然后给定一个高容量的函数T(即教师网络),模型蒸馏的目标就是蒸馏来自T的知识到一个有限容量的函数S中(即学生网络),这样S就能够嵌入与T相似的潜在域。为了获取该目标,S的学习过程通常通过一步步计算他们的输出来在T的监督下发生。
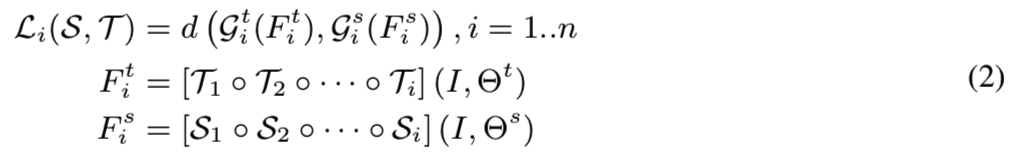
其中Git(·)和Gis(·)是T和S的转换函数,用于让它们对应的嵌入特性具有可比性。d(·,·)表示这些变换后的特征之间的差异。然后通过最小化这些差异![]() ,来自教师T的知识就能够转移到学生网络S,以至于它们可以嵌入相似的潜在域。值得注意的是,Li(S, T)的形式提供了两个重要的性质。首先,由于d(·,·)度量的是Fit与Fis之间的距离,因此它隐含地定义了要从T转移到s的知识。其次,转换函数Git(·)和Gis(·)控制转移信息的部分。接下来的部分将重点介绍这两个组件的设计,以选择最有用的信息并将它们传递给学生,同时又不遗漏老师提供的重要信息。
,来自教师T的知识就能够转移到学生网络S,以至于它们可以嵌入相似的潜在域。值得注意的是,Li(S, T)的形式提供了两个重要的性质。首先,由于d(·,·)度量的是Fit与Fis之间的距离,因此它隐含地定义了要从T转移到s的知识。其次,转换函数Git(·)和Gis(·)控制转移信息的部分。接下来的部分将重点介绍这两个组件的设计,以选择最有用的信息并将它们传递给学生,同时又不遗漏老师提供的重要信息。
3.1 Distilled Knowledge from Teacher Hypersphere
如表1所示,以前的大部分蒸馏框架都是针对封闭集分类问题而引入的,即使用预定义的类进行对象分类或语义分割。在假定类的数量固定(且数量很少)的情况下,可以有效地采用传统的度量方法进行蒸馏过程。例如,L2距离可以用来测量S和T之间的相似度![]() 。然而,由于S的容量是有限的,将这个约束作为每个Fis的正则化(即强制Fis和Fit精确匹配)可能会导致过度正则化的问题。因此,这个约束变得过于困难,使得S的学习过程更加困难。另一种度量方法是采用教师T预测的类概率作为学生S[7]的软目标分布。但是,只有在训练和测试阶段都固定了对象类时,这个度量才有效。否则,将嵌入的特征转换为类概率的知识在测试阶段就不能被重用,因此,提取的知识也会被部分忽略。
。然而,由于S的容量是有限的,将这个约束作为每个Fis的正则化(即强制Fis和Fit精确匹配)可能会导致过度正则化的问题。因此,这个约束变得过于困难,使得S的学习过程更加困难。另一种度量方法是采用教师T预测的类概率作为学生S[7]的软目标分布。但是,只有在训练和测试阶段都固定了对象类时,这个度量才有效。否则,将嵌入的特征转换为类概率的知识在测试阶段就不能被重用,因此,提取的知识也会被部分忽略。
在开放集问题中,由于类不是预先定义的,所以每个类的样本分布和类之间的边界成为更有价值的知识。换句话说,对于开放集问题,样本间的角度差异和样本在教师超球面上的分布方式对学生更有利。因此,我们建议使用角度信息作为主要的知识进行提取。通过这种方式,我们可以放松约束,使学生提取的嵌入特征只需要与教师提取的方向相似,而不是强制学生遵循教师的精确输出(如L2距离)。一般来说,有了“更柔和”的蒸馏约束,学生能够自适应地解释老师的信息,并更有效地学习求解过程。
Softmax Loss Revisit. Softmax损失是分类问题中应用最广泛的损失之一,每个输入图像的softmax损失可表示为:
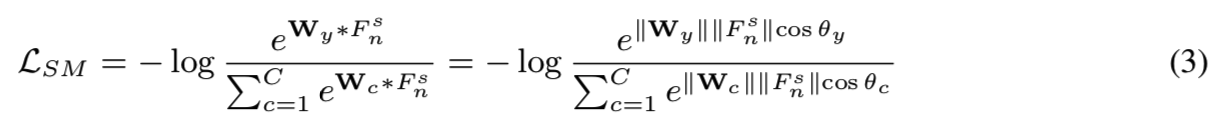
其中y为输入图像的正确类的索引,C为类的数量。注意,为了简单起见,bias项固定为0。通过对特征Fns和权重Wc采用L2归一化,它们之间的角度成为唯一的分类标准。若将每个权向量Wc视为c类的代表,则将损失最小化意味着需要每个类的样本以最小的角度差分布在该类表征的周围。在测试过程中也是如此,从输入图像中提取特征的方向夹角以及每个类的表征(即带有预定义的类的分类问题)或其他样品的提取特征(即验证问题)用于决定是否属于同一类。在这方面,特征Fns的大小比方向更重要。因此,在蒸馏过程中,不需要同时考虑Fnt的大小和方向,只要知道方向就足够了,这样学生就可以得到类似于教师超球面的分布。此外,还可以有效地重用这些知识来比较目标类,而不是训练中的目标类的样本。
Feature Direction as Distilled Knowledge. 我们建议使用教师特征Fnt的方向作为提取的知识,定义一个角度蒸馏损失如下:
![]()
通过这种形式的蒸馏,需要在T和S之间传递的唯一知识就是嵌入特征的方向。也就是说,只要Fns和Fnt方向相似,这些特征就可以自由分布潜在空间中有着不同半径的超球体上。这就为S在学习过程中解释老师的知识提供了一定程度的自由。将这个蒸馏损失合并到等式3,目标函数为:
![]()
第一项对应传统的分类损失,而第二项则引导学生向教师的超球体学习。请注意,这个目标函数并不局限于特定的分类损失。这种蒸馏损失可以作为对任何其他损失函数的支持。
The Transformation Functions.为了防止在蒸馏过程中丢失信息,我们为T选择恒等变换函数为:![]() ,其中
,其中![]() 作为一个映射函数,实现:
作为一个映射函数,实现:![]() ,即将Fns的维度增长到匹配Fnt的维度。比如,如果
,即将Fns的维度增长到匹配Fnt的维度。比如,如果![]() 是从一个深度神经网络中提取的特征映射,那么
是从一个深度神经网络中提取的特征映射,那么![]() 可以定义为一个1*1的卷积层用来将转换Fns为
可以定义为一个1*1的卷积层用来将转换Fns为![]() ,其中
,其中![]() 是Fnt的维度。通过这种方式,在特征转换中就不会有信息丢失了,因此S能够利用来自T的所有知识
是Fnt的维度。通过这种方式,在特征转换中就不会有信息丢失了,因此S能够利用来自T的所有知识
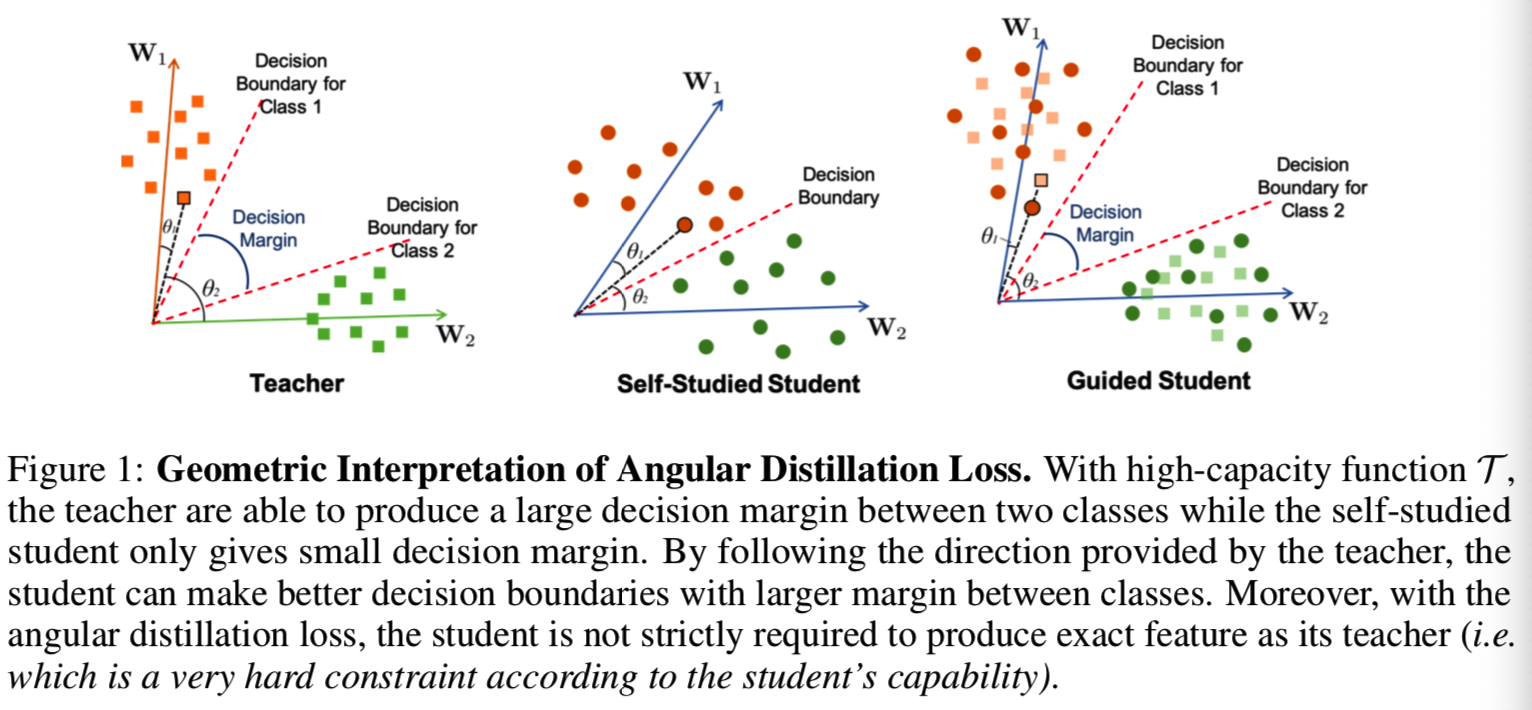
Geometric Interpretation. 考虑二分类,其中只有两个类,代表W1和W2。如前一节所示,当嵌入特性和表征都是标准化的时,分类的结果完全取决于它们之间的角度,即θ1和θ2。在训练阶段,softmax损失LSM需要得到θ1 <θ2的结果去将输入分类为类1,反之亦然。如图1所示,能力越大,教师在两个类之间提供更好的决策边界,而自学的学生(即仅使用softmax损失函数)只能提供较小的决策边界。当Ln(S, T)损失被纳入时(即被引导学生),类1和类2之间的分类边界通过跟随其教师的特征方向进一步增强,并产生更好的决策边界。此外,我们可以很容易地看到,即使学生不能像老师一样生成精确的特征,也可以很容易地模仿老师的特征方向,并从老师的超球面中获益。
3.2 Intermediate Distilled Knowledge
在这一节中,我们进一步将教师的知识提炼为学生的中间成分。一般来说,如果S的输入被解释为问题,其嵌入特征的分布就是答案,那么在中间阶段,即Fis,生成的特征可以被看作是学生网络对解决过程的中间理解或解释。然后,为了帮助学生有效地“理解”解决方案的发展过程,教师应该向学生说明“好的特性是什么样的”以及“学生当前的特性是否足够好,以便在以后的步骤中得到解决方案”。然后,老师可以监督和有效地纠正学生从一开始,从而领导学生网络生成更有效的学习过程。
类似于前一节,而不是采用L2范数作为每一对{Fis,Fit}的成本函数,我们提出使用来自Fis和Fit,且在最后阶段使用同一个老师网络的解释生成的嵌入的角度差来验证Fis的质量。特别的是,每个中间特征Fis的蒸馏损失可表示为:
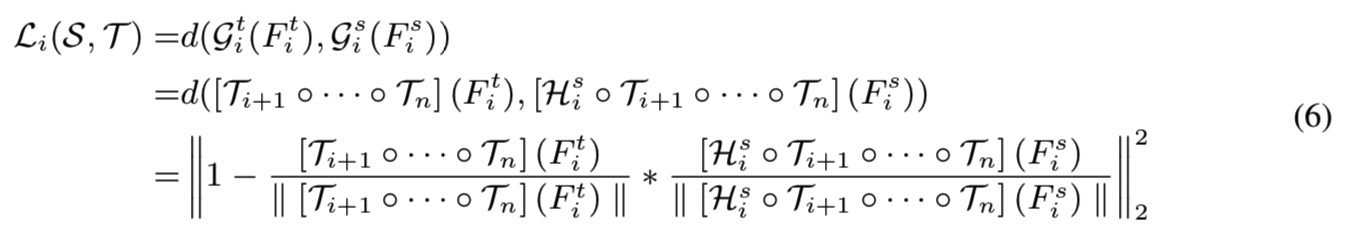
对每个中间特征Fis的这种蒸馏损失背后的直觉是验证Fis是否包含足够有用的信息,以便在后面的步骤中像它的老师一样做出类似的决策。为了验证这一点,我们建议利用教师的能力来解决给定学生在第i阶段的输入,即Fis,的解决方案。如果教师仍然可以使用该输入得到类似的解决方案,那么学生的理解直到该阶段是可以接受的。否则,学生将被要求立即重新更正。因此,在给定中间特征Fis的情况下,His首先对其进行变换以匹配教师特征拟合的维数。
Fis和Fit都会被教师T分析,即![]() ,用于最后的嵌入特征。最后,它们在超球体中的相似度则用来验证Fis所嵌入的知识是否足够
,用于最后的嵌入特征。最后,它们在超球体中的相似度则用来验证Fis所嵌入的知识是否足够
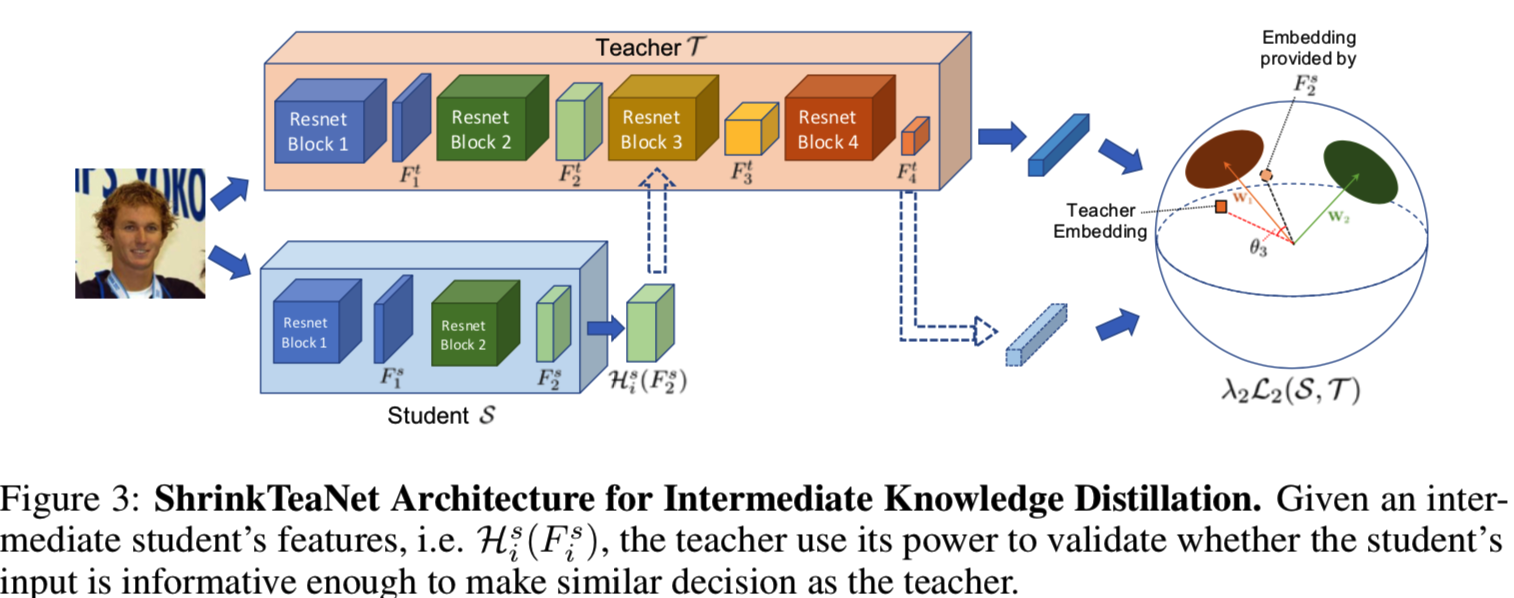
如该图可见,其实这个过程就是将相同的输入分别输到教室网络T和学生网络S中,T直接得到最后的嵌入特征;而学生网络S先得到自己的Fis结果,然后通过函数His进行维度转换,使其与Fit的维度相同,这样His(Fis)他就能作为教师网络后半部分的输入,然后再得到一个嵌入特征,如果这个特征和教师网络T直接得到的嵌入特征相似,就说明学生学得不错。
3.3 Shrinking Teacher-Student Network for Face Recognition
图2和图3说明了我们提出的ShrinkTeaNet框架,该框架用于提取最终和中间特性的知识:
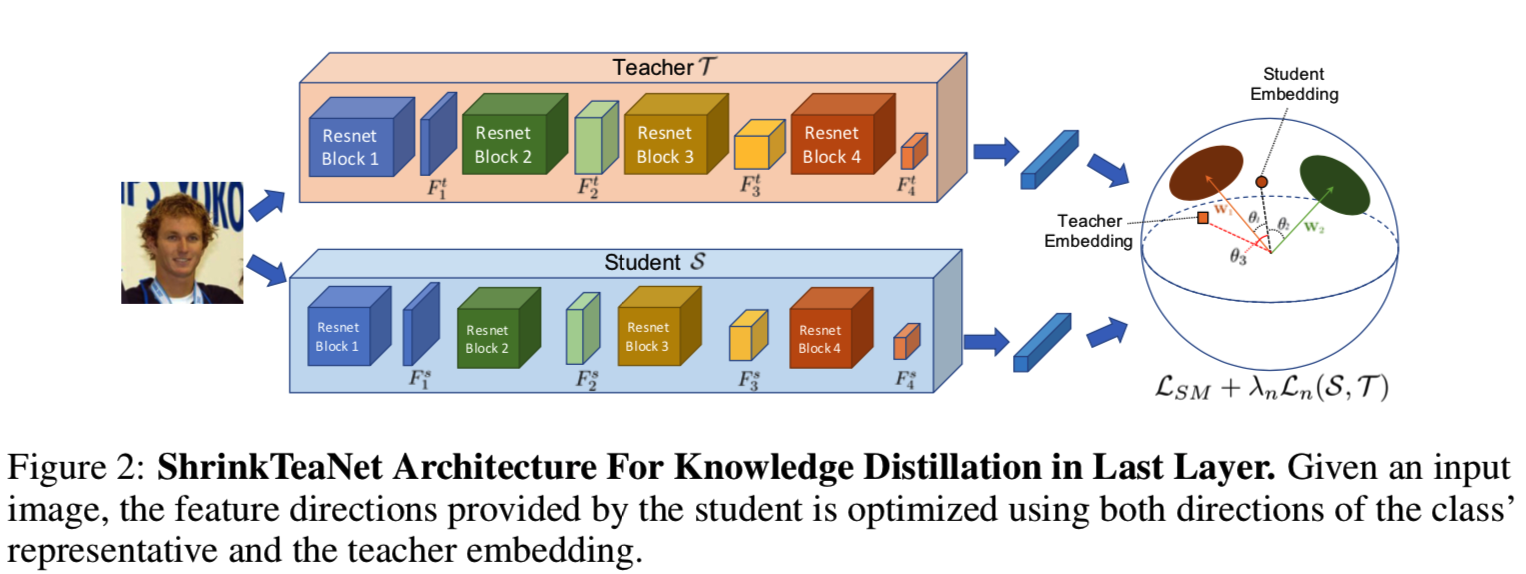
教师和学生都使用了带有四个resnet块的resnet样式的卷积神经网络(CNN)。整个网络可以看作是映射函数,即T和S,而每个resnet块对应于每个子函数,即Ti和Si。然后我们通过提取所有四个模块的知识来学习强大而有效的学生网络。给定数据集为![]() 包含了N个人脸图像Ij以及他们对影的标签信息yi。因此包含了等式5和等式6的最终学习目标函数为:
包含了N个人脸图像Ij以及他们对影的标签信息yi。因此包含了等式5和等式6的最终学习目标函数为:
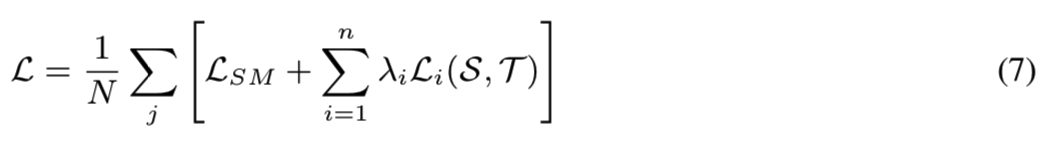
其中λi表示用来控制在不同resnet块中被转移的蒸馏知识的平衡的超参数。此外,如前一节所述,所有函数Git均采用恒等变换函数,Gis采用带有batch归一化层的1×1卷积来匹配相应教师特征的维数。
4 Experimental results
4.1 Databases
MS-Celeb-1M[43]包含10万名受试者的1000万张照片。然而,该数据集的很大一部分包括有噪声的图像或不正确的ID标签。这个数据集[42]的清理版本提供了来自85K个人的5.8M张照片。
Labeled Faces in the Wild (LFW) [44] 有5749名受试者的13233张自然环境下的人脸图像。他们被分成有着3000对正配对的6000对配对。
MegaFace[45]提供了一个非常具有挑战性的测试协议,它具有百万级的干扰。图片库包含了690K名受试者超过100万张的照片,而测试图片库包含了530个身份的100K张照片。
Celebrities Frontal-Profile [46]发布用于验证模型的正面头像模式和侧面头像模式。它由500名受试者的7000对配对组成
AgeDB[47]提供了一个包含4个测试年龄组的协议,每个年龄组由440名受试者的600对配对的10组分割组成。除了年龄因素外,其他面部变化(如姿势、光照、表情)也包括在内。
IJB-B[48]和IJB-C[49]作为两种大规模的人脸验证协议。IJC-B提供了有着10270个正匹配和8M个负匹配的12115个模板,其扩展IJB-C又提供了有着19557个正匹配和15639K个负匹配对的23124个模板。
4.2 Implementation Details
Data Preprocessing. 首先使用MTCNN[50]检测所有的人脸,并使用相似变换对齐到一个预定义的模板。然后裁剪成112×112的大小。
Network Architectures. 在所有的实验中,我们使用Resnet-90结构的[4]作为教师网络,而使用不同的轻量级网络,如MobileNetV1[32]、MobileNetV2[33]、MobileFaceNet[34]。学生网络亦采用经修订的MobileFacenet,即MobileFacenet-R。这个修改版本与MobileFacenet相似,不同之处在于每个resnet块的特征大小等于其在教师网络中对应特征的大小。
Model Configurations. 在训练阶段,batchsize设置为512。学习率从0.1开始,momentum是0.9。所有模型均在MXNET环境下进行训练,机器为有着4个P6000 GPUs的Core i7-6850K @3.6GHz CPU, 64.00 GB RAM,。根据经验,在使用角蒸馏损失的情况下将λn设置为1;在使用L2损失的情况下,因为大的特征映射有着大的损失值,将该值设置为0.001。对于中间层,λi = λi+1/2。
4.3 Evaluation Results
Small-scale Protocols. 我们验证了我们的ShrinkTeaNet框架的效率,它有4个轻量级的骨架,适用于小规模的协议。训练在MS-Celeb-1M的Resnet-90网络充当教师网络。然后,对每个轻量backbone,考虑三种情况:(1)在没有老师帮助的情况下进行训练的自学的学生网络;(2)使用等式7的目标函数进行训练的Student-1,其中蒸馏损失采用的是L2函数;(3)以及使用角度蒸馏损失的ShrinkTeaNet。表2说明了教师网络及其学生的表现:
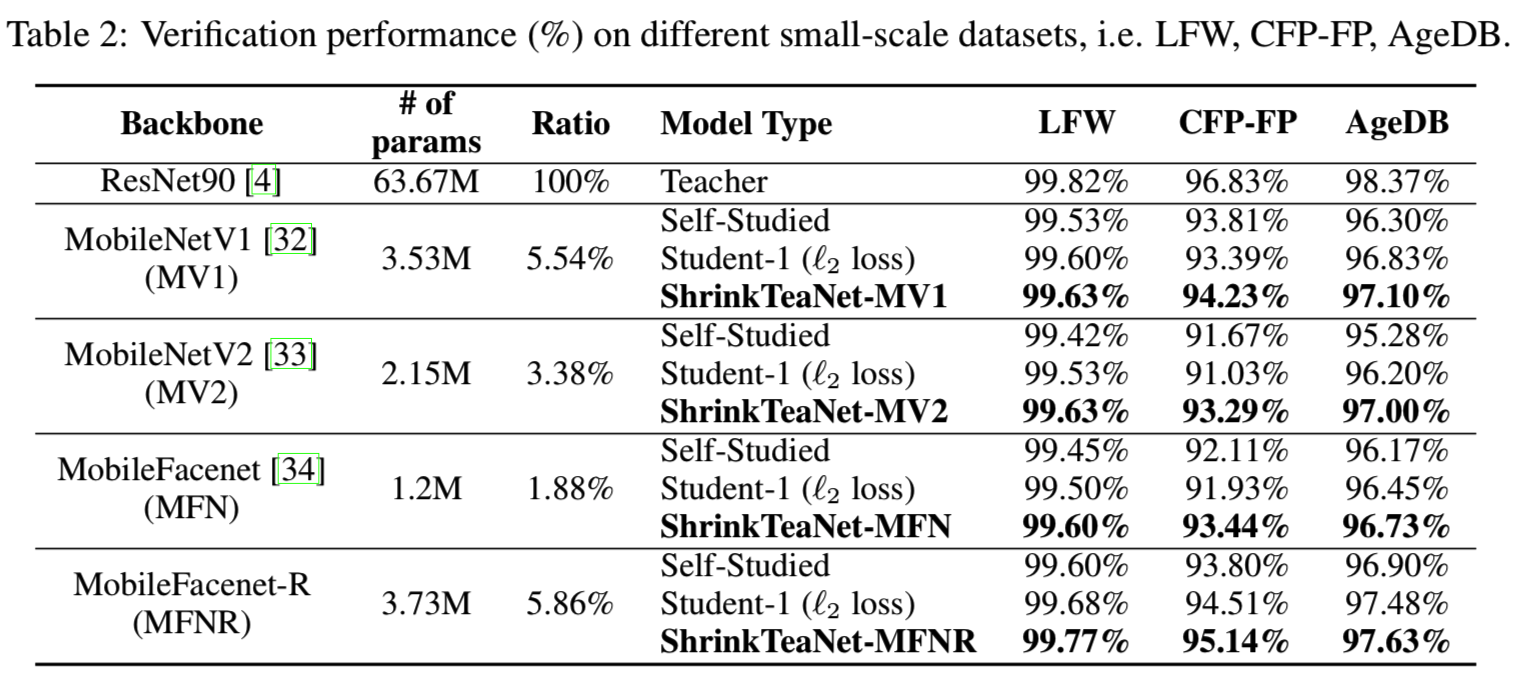
由于轻量backbone的能力有限,在所有四种情况下,自学网络与他们的老师网络在LFW、CFP-FP和AgeDB上的性能差异分别为0.2%-0.4%、3.02%-5.16%和1.47%-3.09%。虽然使用L2 loss的被导学生可以略微提高准确性,但在CFP-FP基准中,MobileNetV1、MobileNetV2、MobileFacenet的准确性都有所降低。此外,我们也注意到L2损失的训练过程是不稳定的。同时,我们提出的ShrinkTeaNet能有效地将教师网络的知识提取给学生,在LFW、CFP-FP和AgeDB三个基准上,最大的性能差距分别降低到0.05%、1.83%和0.74%。与其他人脸识别方法的LFW比较如表3所示:
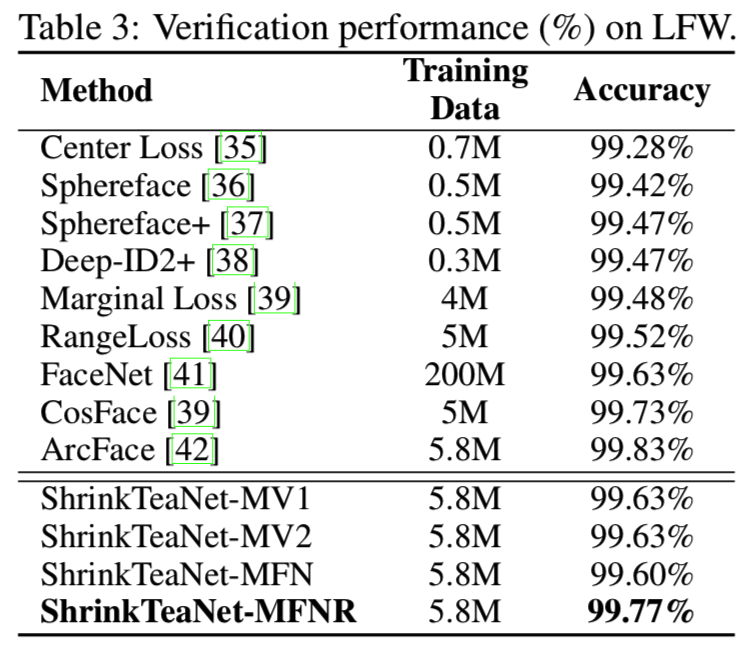
从这些结果来看,即使使用轻量级骨干,ShrinkTeaNet也可以获得与其他大规模网络竞争的性能。
Megaface Protocol. 我们采用类似于小规模协议的训练过程,并在具有挑战性的Megaface基准上评估我们的ShrinkTeaNet,以应对数百万干扰物。表4给出了我们的ShrinkTeaNet与其他模型的Rank-1识别率的比较:
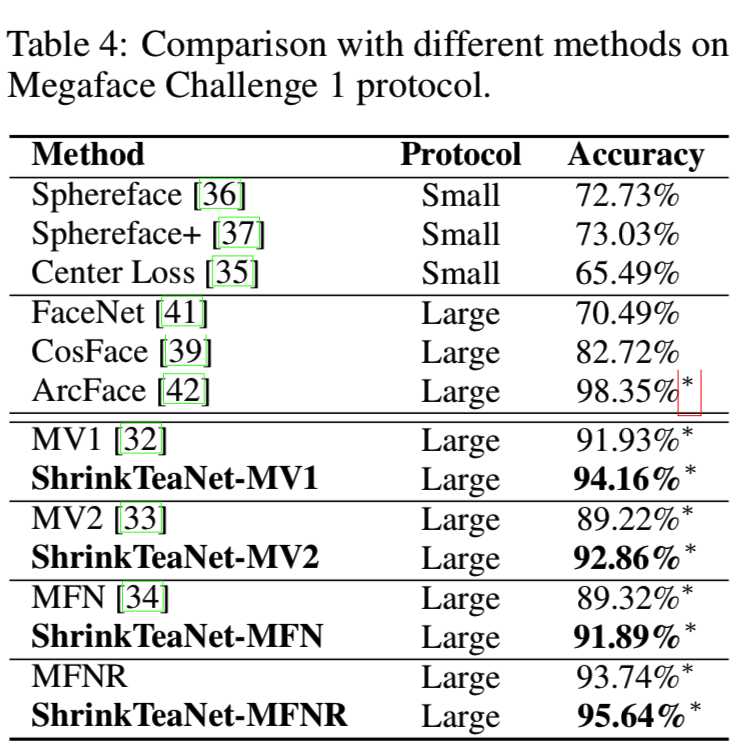
这些结果再次显示了我们的ShrinkTeaNet的优势,为四个轻量级学生网络提供了一致的改进。MV1、MV2、MFN和MFNR的性能分别提高了2.23%、3.64%、2.57%和1.9%。此外,ShrinkTeaNet-MFNR与其他大规模网络的竞争精度达到95.64%,与ArcFace[42]的差距缩小到只有1.71%。
IJB-B and IJB-C Protocols. 表5还说明了与最近在IJB-B和IJB-C基准上的其他方法的比较:
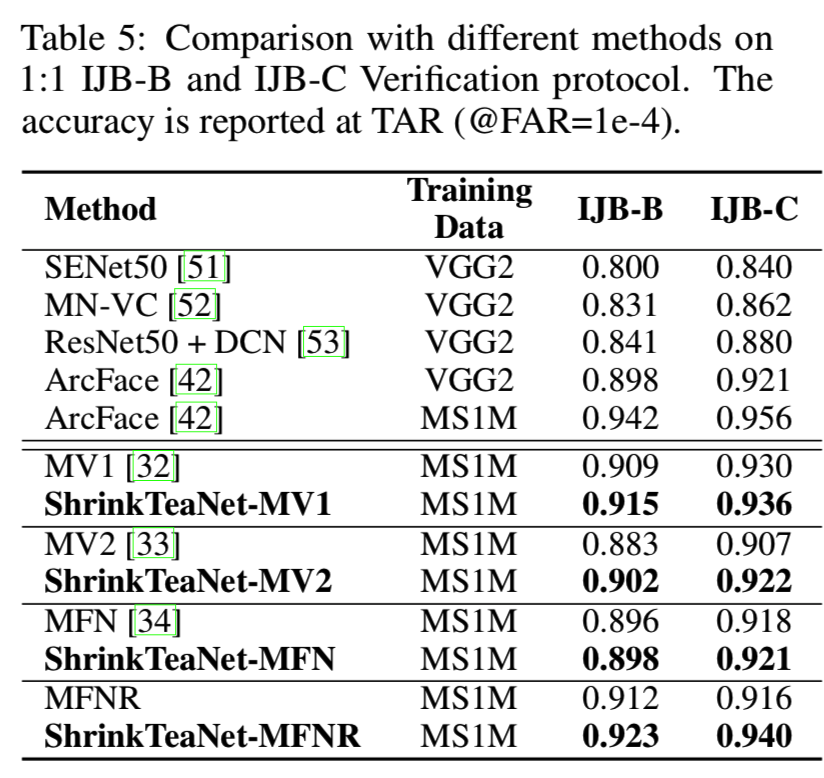
与Megaface协议类似,ShrinkTeaNet能够显著提高轻量级backbones的性能,并将其与大型backbones的性能差距缩小到IJB-B上的0.019和IJB-C上的0.016。这些结果进一步强调了提出的用于模型蒸馏的ShrinkTeaNet框架的优点。
Conclusions. 该论文提出了一种新的面向开放集人脸识别的老师-学生学习范式——ShrinkTeaNet。通过将提出的角蒸馏损失与特征嵌入过程各阶段的蒸馏相结合,学生网络可以轻松有效地吸收教师的超球面知识。这些学习到的知识可以灵活运用,即使是在测试类与训练类不同的情况下。小规模和大规模协议的评估都显示了所提出的ShrinkTeaNet框架的优点。
