
变老 - 3 - Automatic Face Aging in Videos via Deep Reinforcement Learning - 1 - 论文学习
Automatic Face Aging in Videos via Deep Reinforcement Learning
Abstract
提出了一种利用深度强化学习方法自动合成视频序列中年龄增长的人脸图像的新方法。该方法在所有视频帧中对给定对象的面部结构和纵向人脸老化过程进行一致性建模。该方法使用一个长期reward,即带有从深度卷积神经网络提取的深度特征的强化学习函数进行优化。与以往的年龄增长法不同,以往的方法只能从单一输入图像中合成一个老化的相似人脸,而本文提出的方法保证视频中合成的具有跨帧一致性的合成面部特征的年龄变化的面部相似度。此外,深度强化学习方法保证了输入人脸在年龄增长后的视觉识别。我们新收集的老化人脸AGFW-v2数据库的视频结果表明,所提出的解决方案在年龄增长人脸的质量、时间平滑性和跨年龄人脸验证方面都具有优势。
1. Introduction
现有的年龄增长法都同样在两个方面存在问题。首先,它们只对单个输入图像有效。假设需要合成出现在视频中的老化人脸,这些方法通常需要将输入视频分割成单独的帧,并独立地合成每一帧中的每一张面孔,这往往会导致合成的面孔之间存在不一致性。由于每一帧的人脸图像都是单独合成的,所以同一目标生成的人脸的老化模式也可能是不连贯的。此外,大多数老化方法都无法生成高分辨率的老化过程图像,这对于在老化过程中较早形成的细纹等特征非常重要。这可能在基于latent的方法中[15,9,7,35,40,45]存在。
该论文的贡献;
提出了一种用于视频年龄增长的深度强化学习(deep Reinforcement Learning, RL)方法,以保证视频中所捕获的合成人脸的衰老模式的一致性。该方法在RL框架下利用卷积神经网络(CNN)的特征将年龄变换嵌入建模为最优选择。该方法不像以往的方法那样将基于图像的年龄序列单独应用于每个视频帧,而是能够利用视频连续两帧之间的时间关系。此属性有助于保持嵌入到每个帧中的老化信息的一致性。在提出的结构中,不仅可以在视频中跨帧生成更平滑的合成,还可以保留老化数据的视觉保真度,即不同或相同年龄的对象的所有图像,都保存下来以便更好地进行年龄转换。据我们所知,我们的框架是用于视频的最早的人脸老化方法之一。最后,这项工作提供了一个新的大规模人脸老化数据库(https://face-aging.github.io/RL-VAP/),以支持未来在图像和视频中的自动人脸年龄增长和年龄估计方向的研究。
3. Data Collection
在人脸数据集中年龄表征的质量是影响老化的学习过程的最重要的一个特性,同时还可以将每个目标的纵向人脸图像样本的数量、目标的数量、总年龄样本的范围和分布,和在数据库中表现的人口表征都考虑进来。以前用于年龄估计或年龄增长系统的公共数据库在图像总数、每个目标的图像数或数据库中目标样本的纵向分离方面都非常有限,即FG-NET[10]、MORPH[31]、AgeDB[27]。最近出现了一些规模可能更大,但年龄标签带有噪音的数据集,即CACD [3], IMDB-WIKI[32]。在这项工作中,我们介绍了在图像和视频收集方面的自然环境下老化人脸的扩展集(AGFW-v2)。表2展示了我们收集到的AGFW-v2的性能与其他数据集的比较:

3.1. Image dataset
AGFW[7]首先引入了18,685张图像,每个图像的采样年龄从10岁到64岁不等。根据AGFW的收集标准,需要一个两倍大小的数据库。与其他与年龄相关的数据库相比,AGFW-v2中的大多数被收集者都不是公众人物,也不太可能有显著的化妆或面部修饰,这有助于在学习过程中嵌入准确的老化效果。特别是,AGFW-v2收集自三个来源。首先,我们采用了不同关键词的搜索引擎,例如20岁的男性等。大部分的图片来自于非名人的日常生活。除了图像,所有与被收集者年龄相关的公开可用元数据也会被收集。第二部分来自公共领域可访问的mugshot图像。这些是由服务机构提供的带有年龄的护照式照片。最后,我们还包括Productive Aging Laboratory(PAL)数据集[26]的数据。总的来说,AGFW-v2由36,299张图像组成,分为11个年龄组,跨度为5年。
3.2. Video dataset
除了静态照片,我们还收集了一个视频数据集,用于对名人的100个视频进行时间老化评估。每个视频clip由200帧组成。特别是,在收集过程中根据个人的名字进行搜索,选择他们的采访、演示或电影会话等视频进行收集,使每帧中只有一张脸以清晰的方式呈现。年龄注释是根据访谈的年份和个人的出生年份来估计的。此外,为了为被收集者在老年时的容貌提供参考,我们还收集了这些个体在当前更老年龄时的面部图像,并将其作为被收集者视频的元数据提供。
4. Video-based Facial Aging
在最简单的方法中,序列的年龄进展可以通过在视频的每一帧中独立使用基于图像的老化技术来实现。然而,单独处理单个帧可能会导致视频中最终的老化图像不一致,即一些合成的特征,如皱纹,在连续的视频帧中表现不同,如图1所示:
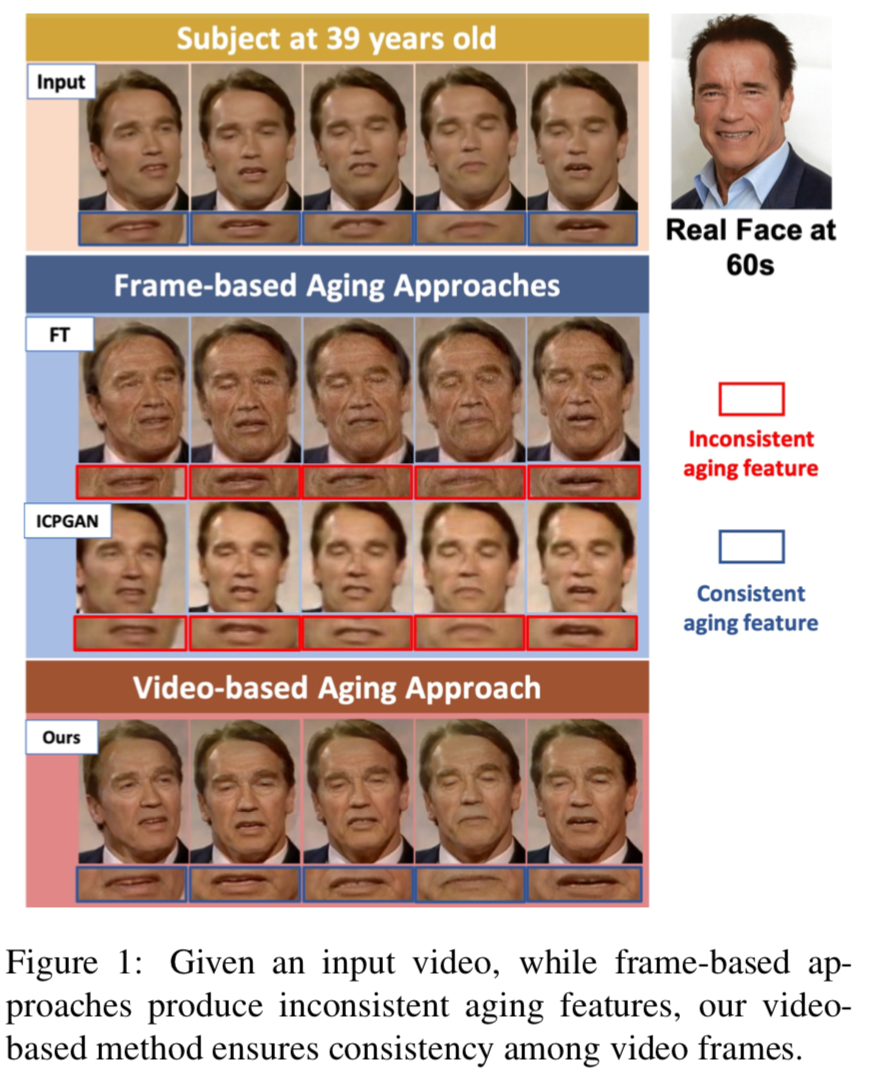
因此,该方法不是将视频视为一组独立的帧,而是利用输入视频帧之间的时间关系来保持每个帧视觉上紧密相关的年龄信息。该老化算法是由一个目标导向的代理在与时间视觉环境交互的过程中所形成的顺序决策过程。在时间采样中,代理整合当前帧和之前帧的相关信息,然后相应修改动作。代理在每个时间步长都获得一个标量奖励,目标是最大化长期奖励的总和,强调在计算当前帧上使用的老化转换时有效地利用了时间观测。
形式上来说,给定一个输入视频,让I ∈ Rd 为一个图片域,为在时间步长t中的图像对Xt = {xyt, xot},包含了在年轻人脸视频中的第t个视频帧xyt ∈ I ,以及老年的合成人脸xot ∈ I 。目标是学习一个合成函数G将xyt映射为xot ,如下所示:
![]()
条件项表示在合成过程中时间约束需要被考虑在内。为了高效地学习G,我们将其分解为如下的子函数:
![]()
其中的F1函数![]() 是用于将年轻人间图像xyt映射到其特征域的表征;M函数:
是用于将年轻人间图像xyt映射到其特征域的表征;M函数:![]() 表示在特征域的遍历函数,即将年轻特征转换为老年特征;F2函数
表示在特征域的遍历函数,即将年轻特征转换为老年特征;F2函数![]() 从特征域映射为图像域,即将特征表征映射为老年图像
从特征域映射为图像域,即将特征表征映射为老年图像
基于此分解,我们提出的框架结构(如图2所示)包括三个主要处理步骤:(1)特征嵌入;(2)多重遍历;(3)从更新的特征中合成最终的图像。在第二步中,我们提出了一个基于深度RL的框架来保证视频帧之间在合成过程中时效变化的一致性。
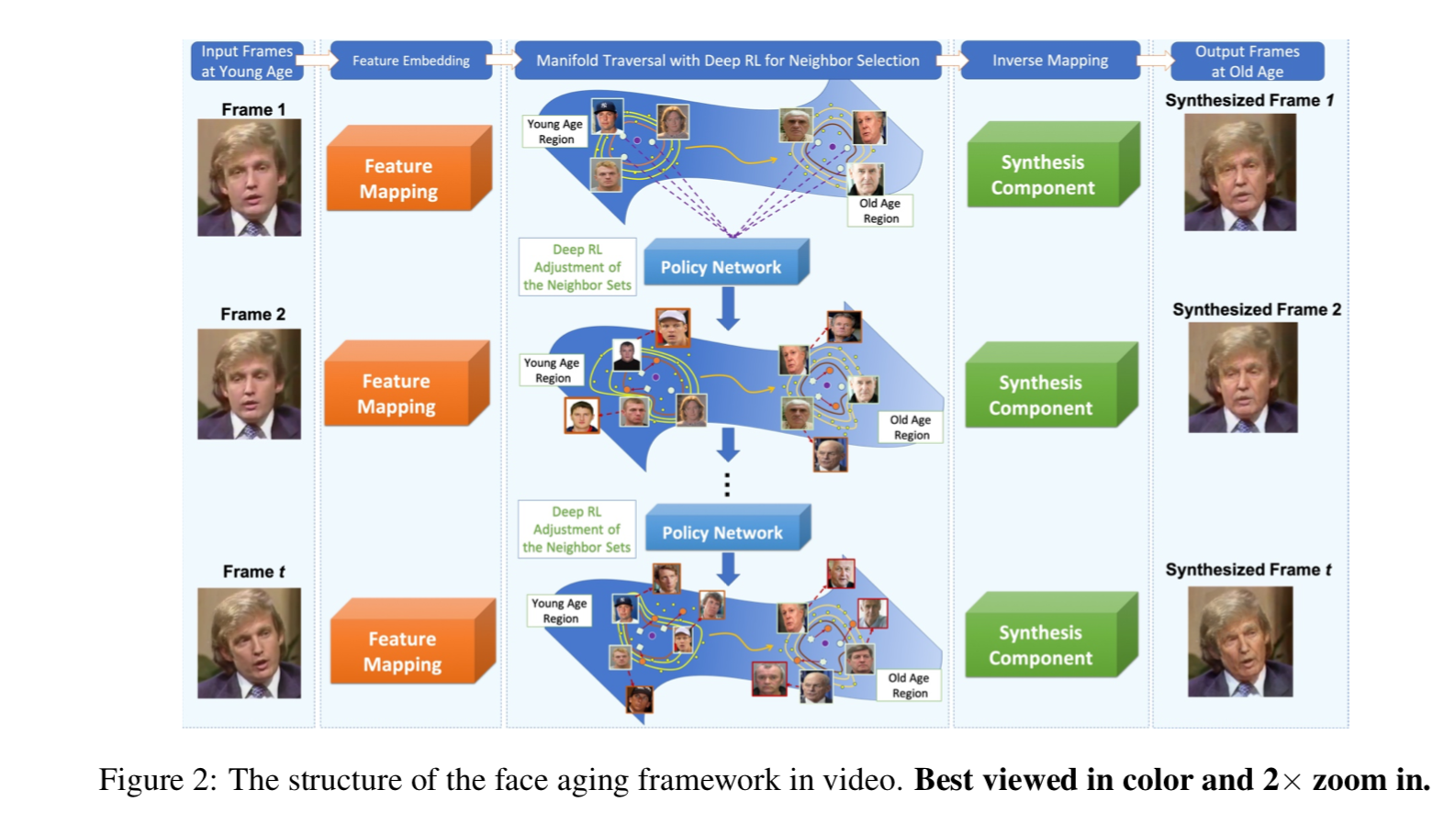
4.1. Feature Embedding
我们的框架的第一步是学习一个嵌入函数F1来将xyt映射到它的潜在表征F1 (xyt)中。虽然F1可以有多种选择,但为了在后续步骤中生成高质量的合成图像,F1选择的结构应该产生一个具有两个主要特性的特征表示:(1)线性可分的(2)细节保留的。一方面,利用前一个性质,将一个年龄组的面部相似性转化为另一个年龄组的面部相似性,可以表示为特征域中沿单个向量方向的线性遍历问题。另一方面,后者的性质保证了一定的细节得以保留,并产生高质量的结果。在我们的框架中,F1使用的是CNN结构。值得注意的是,对于表征所使用的深层的选择仍然存在一些妥协,以便满足这两个属性。在线性化过程中,较深的层更倾向于线性可分性,而较浅的层[25]通常包含人脸的细节。作为多个图像修改任务的有效选择[12,13],我们采用了标准化的VGG-19网络,并使用了其中三层{conv3_1, conv4_1, conv5_1}的拼接作为特征嵌入。
4.2. Manifold Traversing
通过嵌入F1 (xyt),可以将年龄递进过程解释为在深特征域中从较年轻的F1 (xyt)区域到较年长的F1 (xot)区域的线性遍历。则manifold遍历函数M可写成Eqn(3):
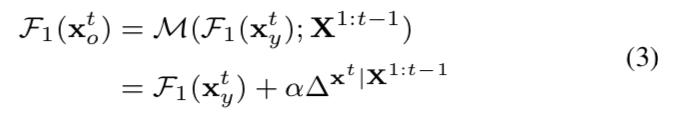
α表示用户定义的关联因子,![]() 编码为了将取决于以前的视频帧的X1:t-1当前视频帧xyt到达更老的年龄域所需要的老化信息数量。
编码为了将取决于以前的视频帧的X1:t-1当前视频帧xyt到达更老的年龄域所需要的老化信息数量。
4.2.1 Learning from Neighbors
为了计算只包含老化效应,而没有其他因素表现,即身份、姿势等的![]() ,我们使用了在两个年龄组中xyt的最近邻之间的老化变化的关系。尤其是,给定xyt,我们构造两个邻居集Nyt和Not,都分别包含在年轻和老年组中xyt的K近邻。这样
,我们使用了在两个年龄组中xyt的最近邻之间的老化变化的关系。尤其是,给定xyt,我们构造两个邻居集Nyt和Not,都分别包含在年轻和老年组中xyt的K近邻。这样![]() 可以估计为:
可以估计为:
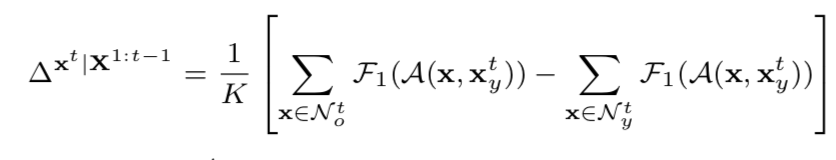
其中![]() 表示一个人脸对齐操作,用于定位在x中的人脸相对于xyt中的人脸位置。当只有xyt的最近邻被考虑到这两个集中时,这两个集除了年龄差异外的其他条件都应该足够相似,且从
表示一个人脸对齐操作,用于定位在x中的人脸相对于xyt中的人脸位置。当只有xyt的最近邻被考虑到这两个集中时,这两个集除了年龄差异外的其他条件都应该足够相似,且从![]() 中抽离出来。而且,均值操作也帮助去忽略身份相关的因素,因此能够强调年龄相关的变换,并将其作为差异的主要来源被编码到
中抽离出来。而且,均值操作也帮助去忽略身份相关的因素,因此能够强调年龄相关的变换,并将其作为差异的主要来源被编码到![]() 中。
中。
剩下的问题就是如何选择恰当的相邻集使得其提供给![]() 和
和![]() 的老化变化是一致的。在下一个部分,一个基于深度强化学习的框架将用于为这两个集合选择恰当的候选人
的老化变化是一致的。在下一个部分,一个基于深度强化学习的框架将用于为这两个集合选择恰当的候选人
4.2.2 Deep RL for Neighbor Selection
一个在年轻和老年中为xyt选择邻近集的直接的方法就是基于邻近标准,如特征域中的距离或匹配属性的数量,去选择靠近xyt的人脸。但是这些标准都不是帧之间相互依存的,他们都不能在视频帧间保存视觉上紧密的年龄信息。因此,我们提出利用图像对{xyt, xyt-1}间表现的关系,和xyt-1的邻近集作为选择过程额外的指导。然后,提出了一个基于RL的框架,并将其表述为一个连续的决策过程,目标是通过xt和xt−1的相邻集之间的一致性来最大化估计的时间奖励
具体来说就是给定两个输入帧{xyt, xyt-1}和两个xyt-1的邻近集{Nyt-1, Not-1},一个策略网络代理将迭代地分析在年轻和老年组中xyt-1的每个邻居的角色,并与F1 (xyt)和F1 (xyt-1)间的关系相结合去决定xyt的新的邻近集{Nyt, Not}。只有当一个新的邻居与xyt足够相似,并保持了两个帧之间老化的一致性时,才被认为是恰当。每次一个新的邻居被选择进来,xyt的邻近集就会被更新,并通过估计两帧之间嵌入的老化信息的相似度来获得奖励。因此,代理可以迭代地探索选择邻居的最优路径,以实现长期奖励的最大化。图3为年龄转换关系的邻居选择过程:
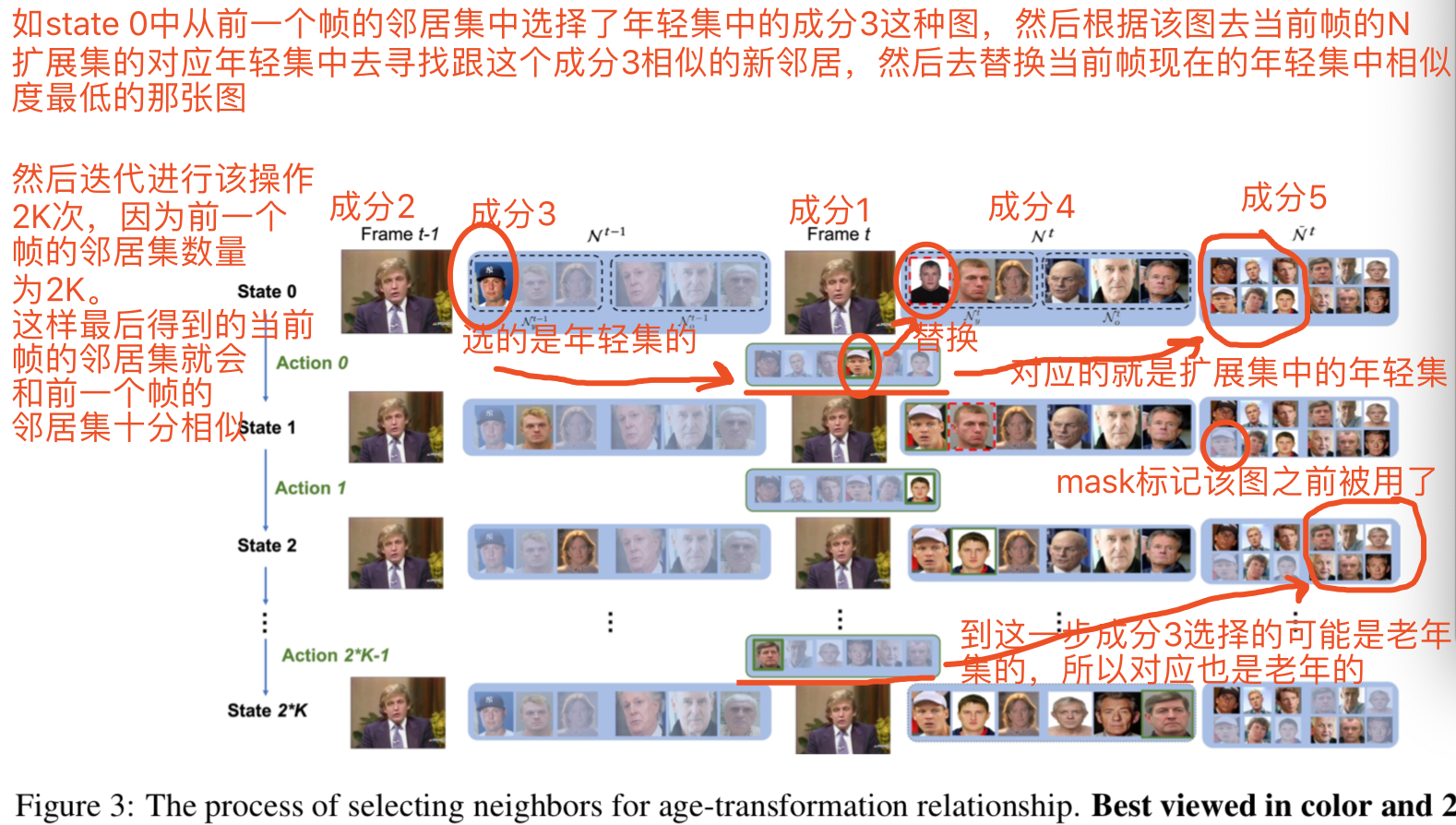
action i就是通过前个帧的第i个邻居去确定当前帧的第i个邻居是否需要替换,如果要替换,应该替换成扩展集中的哪个图片
State:在第i步的状态Sit = ![]() 被定义为6个成分的组合:
被定义为6个成分的组合:
- 成分1: 当前帧xyt
- 成分2: 前一个帧xyt-1
- 成分3: 当前被考虑的xyt-1的一个邻居zit-1,该邻居要么在年轻组,要么在老年组
- 成分4: 当前到第i步前xyt的两个邻近集的构造情况(Nt)i = {(Nyt)i, (Not)i}
- 成分5: 扩展的邻近集
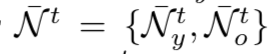 ,其包含了xyt在两个年龄组中各N个邻居,即N>K
,其包含了xyt在两个年龄组中各N个邻居,即N>K - 成分6: 一个二进制mask Mi,表示
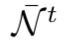 中扩展的邻居样本中那些是在之前的step中已经被选择过的
中扩展的邻居样本中那些是在之前的step中已经被选择过的
在初始的S0t中(即上图中第一行的成分4),两个邻近集{(Nyt)0, (Not)0}分别使用了xyt在两个年龄组中的K近邻。为了找到最近的邻居,我们考虑了两个测量标准:匹配的面部属性的数量,即性别、表情等;以及两个特征嵌入向量之间的余弦距离。mask Mi的所有值在S0t中都设置为1,当被使用之后就会设置为0,表示已经使用过了。
Action:使用来自xyt-1的被选的邻居zit-1的信息,以及{xyt,xyt-1}之间的时间关系,一个行动ait被定义为为当前帧选择新邻居,以便将此新样本添加到当前帧的邻居集,这样xyt和xyt-1之间的老化合成特征就更一致了。
注意,因为数据集中的所有样本不一定和xyt足够相似,我们通过选择xyt的N近邻来限制action空间。在我们的配置中,N=n*K,n和K分别设置为4和100
Policy Network:在每个时间step i中,policy network首先编码在Sit中提供的信息为:
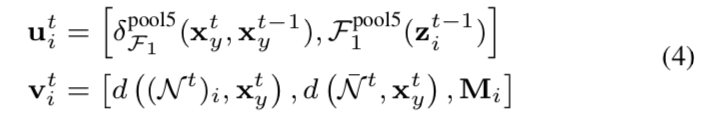
F1pool5是在4.1中表示的嵌入函数,pool5层的输出结果作为表征![]() 嵌入到特征域中xyt和xyt-1之间的关系中。d((Nt)i, xyt)是一个映射(Nt)i中的所有样本到他们的表征,并计算它们到xyt的余弦距离。policy network的最后一层被重定义为
嵌入到特征域中xyt和xyt-1之间的关系中。d((Nt)i, xyt)是一个映射(Nt)i中的所有样本到他们的表征,并计算它们到xyt的余弦距离。policy network的最后一层被重定义为![]()
![]() ,其中{W,b}分别表示隐藏层到输出层的连接的权重weight和偏差bias。
,其中{W,b}分别表示隐藏层到输出层的连接的权重weight和偏差bias。
因此hit包含选择为xyt-1邻居的样本的特征和xyt和xyt-1之间的时间关系,它直接编码人脸如何变化的信息和以前帧中的那些老化信息会被使用。该进程帮助代理评估它的选择去证实xyt的最佳候选人来构造其的邻居集
policy network的输出为N+1维的向量p,用来指示所有可能actions的概率![]() ,每一个entry表示为step i 选择样本xj的概率。注意p的第N+1个值指明在这个step中,该action是否需要更新邻居集。在训练过程中,从这个概率分布中随机抽取一个动作ait。在测试时,选择概率最高的合成过程。
,每一个entry表示为step i 选择样本xj的概率。注意p的第N+1个值指明在这个step中,该action是否需要更新邻居集。在训练过程中,从这个概率分布中随机抽取一个动作ait。在测试时,选择概率最高的合成过程。
State transition:当在state Sit中的action ait的决策被定下来后,下一个state Si+1t 就能够通过状态转移函数![]() 来获得了,其中zit-1被更新为下一个在xyt-1的邻居集中没有被考虑过的样本zi+1t-1。然后根据action ait,那个在zit-1相关集中(即是xyt的Nt中的年轻集还是老年集)与xyt有着最小相似度的邻居将会被替换为xj。当Nyt-1和Not-1中的所有样本都被考虑后,就到达了最后的状态(所以一个{xyt,xyt-1}之间的State的次数是2K次,因为Nyt-1和Not-1中的所有样本数为2K)
来获得了,其中zit-1被更新为下一个在xyt-1的邻居集中没有被考虑过的样本zi+1t-1。然后根据action ait,那个在zit-1相关集中(即是xyt的Nt中的年轻集还是老年集)与xyt有着最小相似度的邻居将会被替换为xj。当Nyt-1和Not-1中的所有样本都被考虑后,就到达了最后的状态(所以一个{xyt,xyt-1}之间的State的次数是2K次,因为Nyt-1和Not-1中的所有样本数为2K)
Reward: 在训练过程中,代理在第i步执行一个动作ait后,会收到来自环境的奖励信号rit。在我们提出的框架中,选择奖励来衡量视频帧之间的老化一致性。
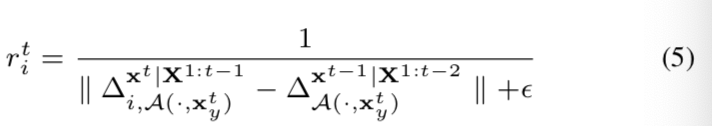
注意在这个公式中,我们将之前和当前帧的所有邻居和xyt对齐。因此在之前和当前帧的所有邻居集中应用相同的对齐函数![]() ,对齐能够将姿势、表情和人脸的位置等因素的影响在rit中降到最小。因此rit仅影响嵌入在xyt,xyt-1中的老化信息的差异
,对齐能够将姿势、表情和人脸的位置等因素的影响在rit中降到最小。因此rit仅影响嵌入在xyt,xyt-1中的老化信息的差异
Model Learning:训练目标函数是用来最大化奖励信号的和:![]() 。我们在每个time step中通过给定的奖励来指导使用REINFORCE算法[42]优化周期policy network。
。我们在每个time step中通过给定的奖励来指导使用REINFORCE算法[42]优化周期policy network。
4.3. Synthesizing from Features
在xyt中的邻居集被选出来后,4.2.1中提到的![]() 就能够被计算出来了,以及xyt在老年区域F1 (xot)的嵌入能够使用等式3估计出来。在最后阶段,F1 (xot)能够通过F2函数被影射回到图像域 I 中,即通过如下的优化实现:
就能够被计算出来了,以及xyt在老年区域F1 (xot)的嵌入能够使用等式3估计出来。在最后阶段,F1 (xot)能够通过F2函数被影射回到图像域 I 中,即通过如下的优化实现:
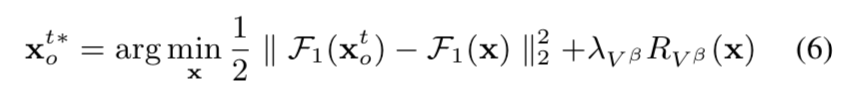
其中Rvβ代表总波动调整器,用于鼓励平滑像素值之间的转换。
5. Experimental Results
省略
6. Conclusions
这项工作提出了一种新的基于深度RL的方法,用于视频中的年龄变化。该模型继承了深度网络的最新进展和强化学习技术的优点,能够在视频帧之间合理、连贯地合成给定对象的老年人脸。我们的方法可以在视频中生成不断老化的面部特征。此外,我们的方法保证了被老化者在综合老化效果后的视觉身份的保存。

