
变老 - 2 - Attribute-aware Face Aging with Wavelet-based Generative Adversarial Networks - 1 - 论文学习
Attribute-aware Face Aging with Wavelet-based Generative Adversarial Networks
Abstract
由于很难在大范围的年龄跨度内收集同一对象的面部图像,所以现有的大多数面部老化方法都采用非配对数据集来学习年龄映射。然而,未配对训练数据所固有的年轻与老年人脸图像的匹配模糊性,可能会导致人脸属性在老化过程中发生非自然的变化,而这并不能像现有的大多数研究一样,仅仅通过加强身份一致性来解决。针对上述问题,本文提出了一种基于小波生成对抗网络的属性感知人脸老化模型。具体来说,我们将人脸属性向量嵌入到模型的生成器和判别器中,以鼓励每个合成的老年人脸图像忠实于其相应输入的属性。在此基础上,结合小波包变换(WPT)模块,通过在频率空间的多个尺度上捕获与年龄相关的纹理细节,提高生成图像的视觉保真度。定性结果证明了我们的模型在合成视觉上可信的人脸图像方面的能力,广泛的定量评估结果表明,该方法在现有的数据集上达到了最先进的性能。
1. Introduction
以前使用带有不匹配属性的人脸图像对的方法将误导模型学习除了老化以外的转换,导致严重的ghosting artifacts,甚至是合成结果中出现不正确的人脸属性,如图1所示:

可见有些女性变老后变成了男性,并长出了胡子。这是因为模型学习过程中,发现长胡子是一个典型的老化的迹象,但没有办法知道这不会发生在一个女人身上,因为如果没有条件信息被考虑进来的话,年轻女性和老年男性的人脸图像对就可以被视为正的训练样本。
为了解决上述问题,本文提出了一个基于生成式对抗网络(GANs)的框架。与文献中已有的方法不同,我们通过在生成器和判别器中嵌入人脸属性向量的方法来加入输入的语义条件信息,从而引导模型输出 属性忠实于每个对应输入 的老年人脸图像。此外,为了增强老化细节,在观察到老化迹象主要表现为皱纹、笑纹、眼袋等局部纹理的基础上,我们利用小波包变换有效地提取了频率空间中的多尺度特征。
该论文的主要贡献有:
- 人脸属性作为条件信息被合并到人脸老化的生成器和判别器中,因为仅仅使用身份的保存不足以产生合理的结果。
- 采用小波包变换在频域内提取多尺度纹理细节特征,生成老化效果的细粒度细节。
- 大量的实验表明,该方法能够准确地描述老化效应,并保留身份和面部特征信息。定量结果表明,我们的方法达到了最先进的性能。
3. Approach
所以该论文的主要两点在于:
- 嵌入人脸属性到生成器和判别器中
- 使用小波转换模块获取纹理信息作为判别器的输入
网络如下图所示:
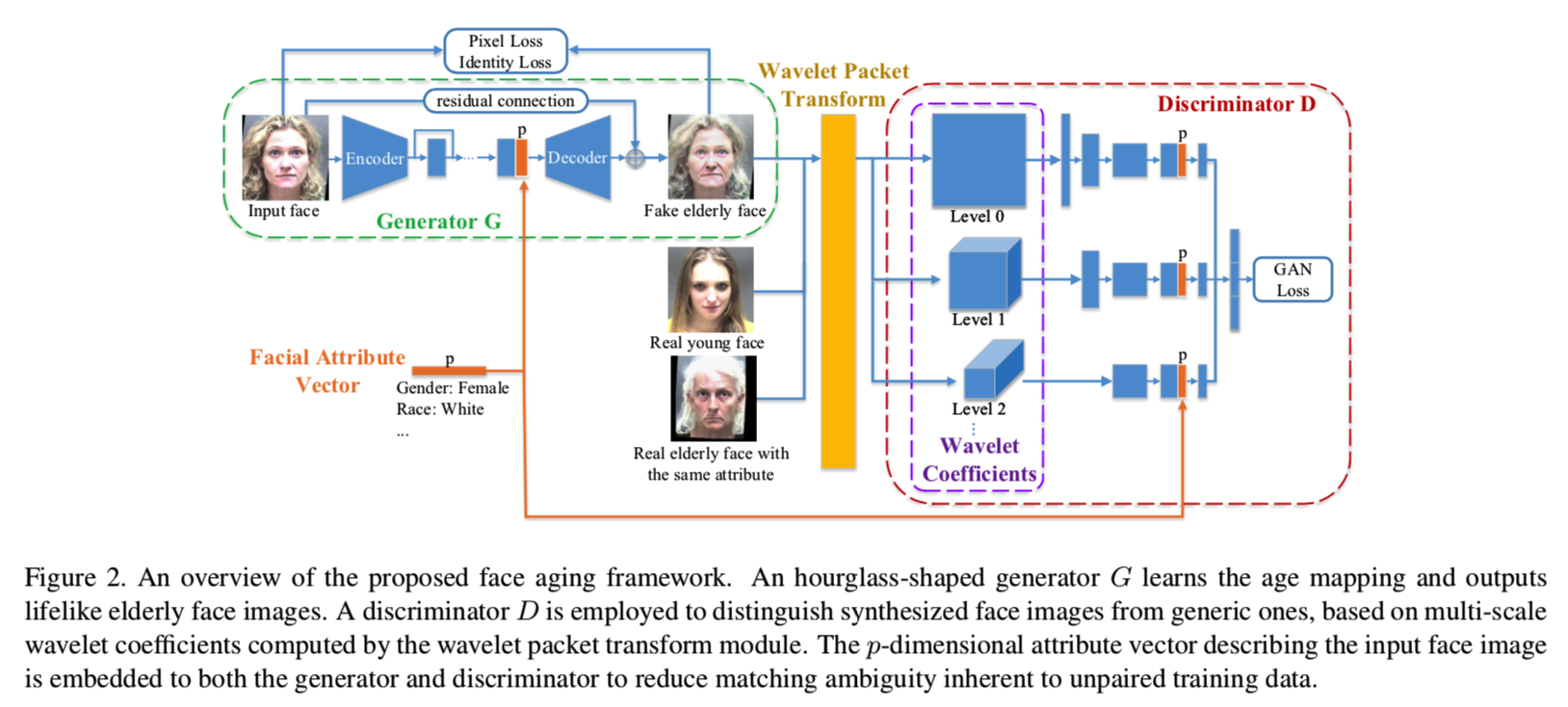
与以往的工作不同,输入不再只是低层次的图像信息(即图片input face)我们提出将低层次的图像信息(像素值,input face)和高层次的语义信息(面部属性,facial attribute vector)结合到人脸老化模型中,以规范图像的转换模式,减少未配对的年轻和年老人脸之间的映射模糊性。该模型以年轻人脸图像及其对应的属性向量作为输入,生成与输入属性一致的老年人脸图像。
我们没有简单地采用一个附加的损失项来监督生成结果的属性,而是将属性向量嵌入生成器中,以便在生成过程中充分考虑语义面部信息,并鼓励模型更有效地生成具有一致属性的面部图像。
生成器结构为:
具体来说,我们使用沙漏形的全卷积网络作为生成器,这在之前的图像翻译研究中已经取得了成功[6,29]。它由一个编码器网络、一个解码器网络和中间的四个剩余块作为瓶颈组成。将输入的面部属性向量复制并连接到最后剩余块的输出blob,因为它们都包含高级语义特征。组合之后,解码器网络将连接的特征块转换回图像空间。
由于人脸老化可以看作是在输入年轻人脸图像的条件下产生的老化效果,我们将输入图像加入解码器的输出中,形成一个residual连接。与合成整个人脸图像相比,这种结构自动使得生成器更专注于建模输入和输出人脸图像之间的差异,即老化的代表性标志,更不容易被背景等与衰老无关的视觉内容分散注意力。最后,利用双曲正切映射(tanh)对生成的张量的数值尺度进行归一化处理,得到了生成的老年人脸图像。
3.2. Wavelet-based Discriminator
该判别器有两个主要部分:
- 区分合成的人脸图像(合成老人)和一般的人脸图像(一般的有年轻的,也有老的)
- 检查每个合成的结果的属性(合成老人脸的老化属性)是否与对应输入的属性(真实老人脸的老化属性)一致。
具体来说,考虑到皱纹、笑纹、眼袋等典型的衰老信号可以被视为局部图像纹理,我们采用小波包变换(WPT)来捕捉与年龄相关的纹理特征。如图3所示:
在该论文中对应的是: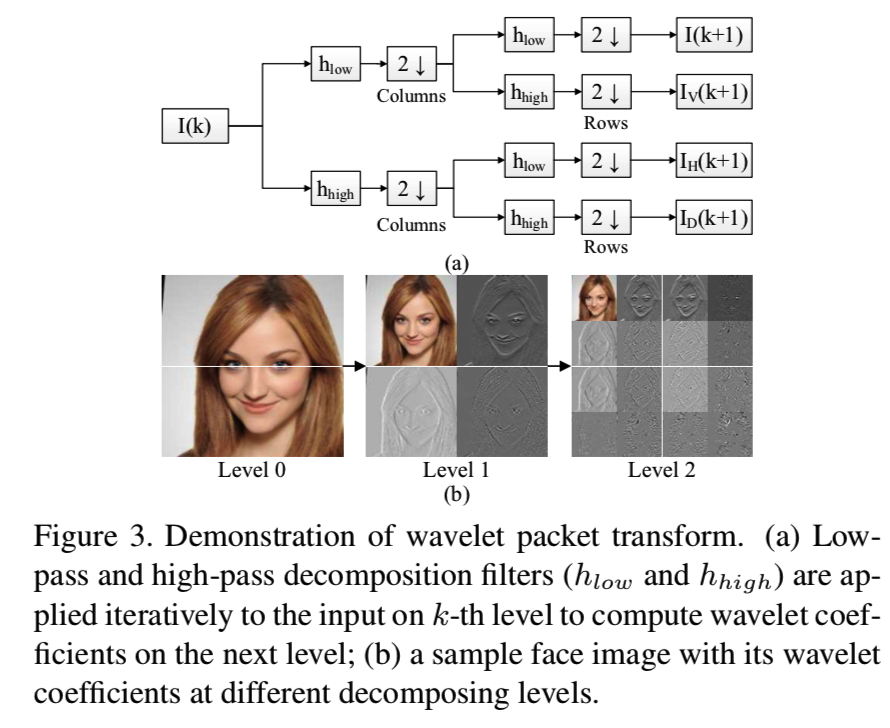
具体来说,多层WPT是为了对给定图像中的纹理进行更全面的分析,在每个分解级别的小波系数被输入到判别器的卷积路径中。注意,这与[9]不同,因为在我们的工作中,小波系数仅用于判别,不涉及预测或重构。
为了使判别器获得能在在生成的图像中判别是否保留了属性的能力,还将输入的属性向量复制并连接到每个路径的中间卷积块的输出。在判别器的末端,所有路径的相同大小的输出被融合成一个单独的张量,然后根据标签张量估计对抗损失。
与[25]中通过卷积层序列提取多尺度特征相比,使用WPT的优点是计算小波系数可以看作是通过单个卷积层进行前向传播,大大降低了计算成本。因此,WPT大大减少了每个转发过程中执行的卷积的数量。虽然对模型的这一部分进行了简化,但仍然利用了多尺度图像纹理分析的优势,有助于提高生成图像的视觉保真度。
从图上可知,其WPT进行的操作就是对输入的图像level 0进行一层小波变换,假设输入level 0是一张224*224*3的原始图像,得到的level1的大小就是112*112*(3*4),然后再将这4张图作为输入再进行一层小波变化,得到大小为56*56*(3*16)的level 2。这里假设使用的是haar小波变换
详情可见:
pytorch_wavelets包实现的小波变换和MWCNN中的小波变换的异同点
3.3. Overall Objective Functions
GAN模型模拟训练的过程优化生成器G和判别器D之间的minimax-max双方博弈游戏。不像常规的GANs[5],我们采用最小平方损失而不是负对数似然损失,用于最小化生成样本和特征空间的决策边界之间的边际,这也进一步提高了合成图片[12]的质量。实际操作中,我们将年轻人脸图像xi和它们对应的p维的属性向量αi配对起来,表示为(xi,αi)~Pyoung(x,α),并将他们作为模型的输入。只有带有属性向量αi的原有的老人人脸图片的输入,即(xi,αi)~Pyoung(x,αi)才会在判别器D中被判定为正样本,真实的年轻人脸,即(xi,αi)~Pyoung(x,α)会被判定为负样本来帮助D在老化方面获得判别能力
从公式上来说,G和D的目标函数为:
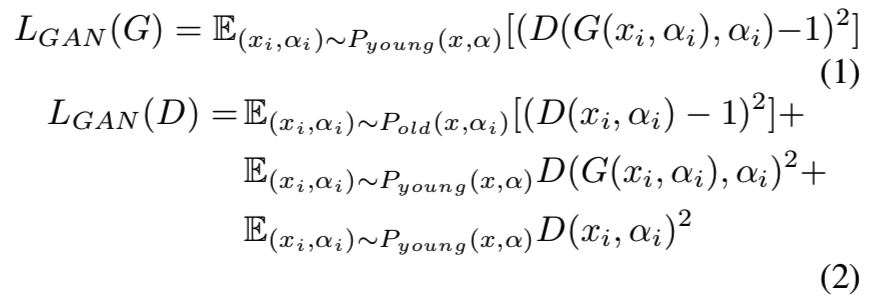
Pyoung和Pold分别表示收集的年轻人和老年人的人脸图像分布
LGAN(G)的意思是训练G时,通过生成器G合成的老年人脸输入判别器D中优化使结果趋紧于1,即判定为正样本
LGAN(D)的意思是在训练D时,判别真正的老年人脸图像为正样本,即结果趋紧于1;而生成器生成的合成老年人脸则判别为负样本,结果趋近于0;真正的年轻人样本也被判定为负样本,结果趋近于0。这样就能让判别器的判别能力越来越好
此外,还采用了像素损失和身份损失来保持图像级和个性化特征级的一致性。具体而言,我们利用VGG-Face描述器[14],表示为φ,提取一个人脸图像身份相关的语义表征。这两个损失项可以表述为:
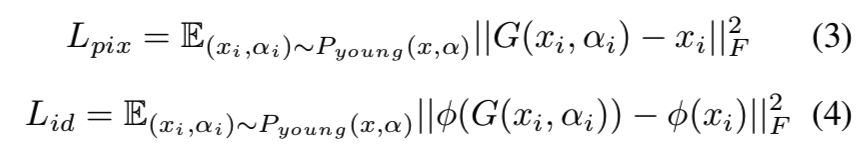
身份损失Lid是使用了另一个已经训练好的identity模型得到一个中间向量来计算得损失,将G合成的老年人脸和其对应的年轻人脸输入都输入这个identity模型,计算两个向量的最小平方损失来让两张图片的身份信息趋近相同。
像素损失λpix就是简单地对生成的老年人脸照片和对应的输入的年轻人脸照片求最小平方差
总之,完整的目标函数为:
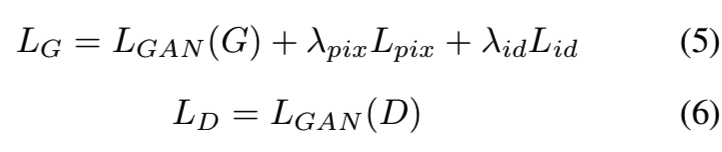
λid和λpix是分别用于平衡身份和像素损失的重要性的系数。我们通过最小化LG和LD来优化模型,直到达到最优结果。
至于权衡参数,λpix和λid首先设置使得损失Lpix和Lid是和损失LGAN(G)有着相同的数量级的,然后除以10来强调对抗损失LGAN(G)的重要性。
4. Experiments
4.6. Ablation Study
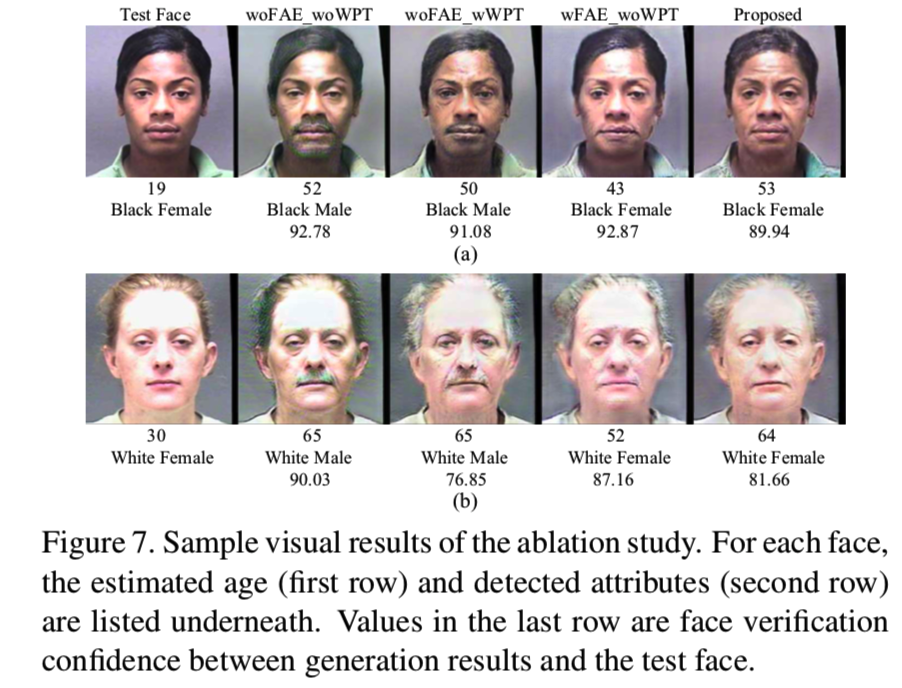
判断人脸属性向量的嵌入(FAE)和小波包转换(WPT)这两部分的影响,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号