
人脸检测和识别以及检测中loss学习 - 12 - Pose-Robust Face Recognition via Deep Residual Equivariant Mapping - 1 - 论文学习
⚠️这个方法还可以用在别的地方,比如要判别一个人不同年龄的照片是不是同一个人,这样这里的yaw coefficient参数就是用来调整照片年龄的不同,而不是人脸角度的不同了!!!!!!!!!
Pose-Robust Face Recognition via Deep Residual Equivariant Mapping
Abstract
由于深度学习的出现,人脸识别获得了非凡的成功。可是,很多当代的人脸检测模型,对比于处理正面人脸,在处理侧面人脸时仍表现得比较差。主要的原因是正面和侧面训练人脸数量的高度不平衡 —— 对比于侧面训练样本,这里有着极其多的正面训练样本。除此之外,本质上来说,训练一个对于大量姿势变量来说是几何不变的深度表征是非常困难的(即不同姿势的人脸的输入经过CNN网络都能对应得到同个表征)。在该论文中,我们假设在正面和侧面人脸中有一个固有的映射,并且最后,它们在深度表征空间中的差异都能够通过一个等价映射连接。为了探究该映射方法,我们制定了一个新的Deep Residual EquivAriant Mapping (DREAM) 块,其有着能够通过适当地添加residuals到输入的深度表征来将一个侧面人脸表征转换为一个规范的姿势来简化识别的能力。对于很多很强的深度网络,如ResNet模型,DREAM块都能够增强它们侧面人脸识别的性能,不需要故意增强侧面人脸的训练数据。该块很容易使用、是轻量级的并有着可忽略的计算开销
1.大概说明

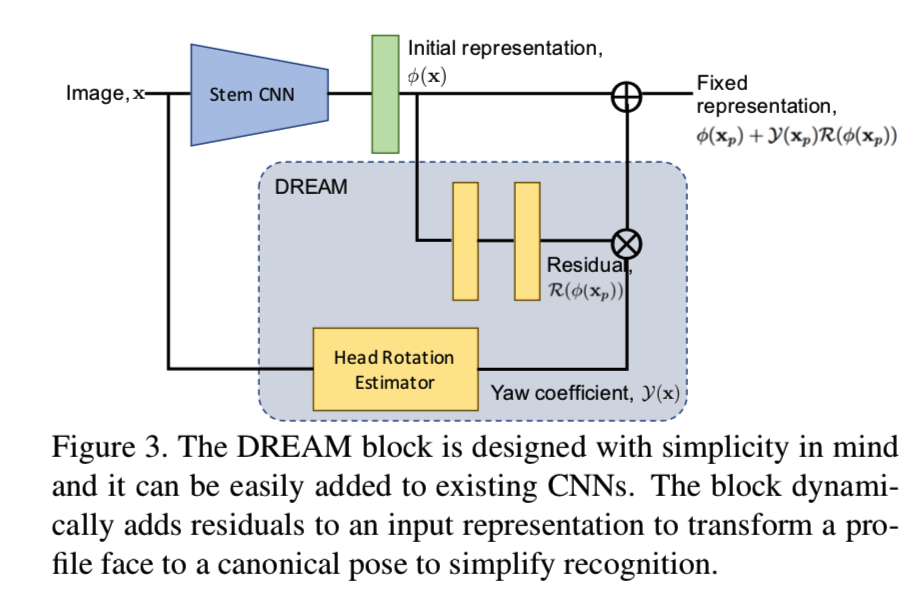
通过上面的图可以了解该DREAM的实现理论就是将人脸输入到人脸识别CNN模型中,得到人脸的一个特征向量,可见正面人脸的特征向量在一个空间中,而侧脸人脸的特征向量在别的空间中,DREAM的目的就是希望经过一定地变换,能够将侧面人脸的特征向量变换到与正面人脸相同的特征向量空间中
为了能够可视化变换后的效果,作者在训练模型同时训练一个GANs网络,使得能够从特征向量重构人脸图像,因此从最下面一层的图像我们可以看见,变换前的侧面人脸重构后为右边的样子,经过DREAM变换后重构的人脸就是一个正面人脸了
其他的论文都是在图像层面进行正面-侧面的转换,而该论文是在特征层面进行的正面-侧面的转换
2.公式说明
该DREAM的公式实现为:
假设g为侧面到正面的变换,在图像层面的变换为gX;Φ表示为人脸识别得到特征向量的CNN网络,因此Φ(X)表示的就是特征向量,Mg则表示在特征层面的侧面到正面的变换。所以我们希望得到的效果就是在图像层面上进行变换后经过CNN网络得到的特征向量与先经过CNN网络得到特征向量,然后再在特征层面进行变换得到的特征向量是相似的:![]()
在该论文中实现右边,将其定义为更简单的形式:
即Xp表示侧面人脸输入,Xf表示正面人脸输入,都是同一个人。
- 先将侧面人脸Xp输入CNN网络得到特征向量Φ(Xp)
- 然后拉出另一个分支,使用DREAM块的residual函数对其进行操作R(Φ(Xp))
- 接着这里有一个参数名为yaw coefficient —— Y(X),这个参数是通过对每张侧面人脸得到的21个landmarks进行计算得到的。将这个参数和上面的分支得到的R(Φ(Xp))相乘得到Y(X)*R(Φ(Xp))
- 然后将这个相乘得到的结果与Φ(Xp)相加即得到了变换后的特征向量了
如下面的公式所示:

这里yaw coefficient —— Y(X)的范围为[0,1],其作为分支residuals的soft gate,即保证当人脸是正面时,Y(X)=0;否则当人脸慢慢地从正面转向完全地侧面时,Y(X)的值就会逐渐地从0增长到1。因此在完全的侧面姿势时,residuals的大小是最大的。没有这个参数,residuals—— R(Φ(X))将盲目地被添加到任意姿势的输入人脸中,影响最后的人脸识别性能
yaw coefficient —— Y(X)该参数是通过计算head rotation estimator得到的,如下面所示:
使用论文[37](即Appearance-based gaze estimation in the wild)中的算法来估计head rotation。具体来说采用的是论文[28](即视线检测Learning-by-synthesis for appearance-based 3d gaze estimation)中的人脸模型和头部坐标体系定义。因此参数yaw coefficient —— Y(X)也是通过一个模型计算得到的。不过该论文中有一点点不同是,其输入不是3D人脸的6个点(即4个眼角点和2个嘴角点),而是使用了21个landmarks,因为这样的到的性能更好
然后我们通过使用EPnP算法[16]估计初始解来拟合模型,并通过非线性优化进一步细化姿势。最后一步的非线性优化使得其范围在[0,1]间,公式为: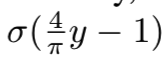
σ表示sigmoid函数,该式子的意思是当侧面人脸的旋转角度大于45度时,(4/Π)*y-1就大于0,那么在sigmoid函数中就会快速趋近于1,越大越接近1。yaw角度为[-90o, 90o]
⚠️yaw的计算方法该论文中并没有给出,所以可能需要自己去查看相应论文理解
3.损失函数
该模型的训练损失函数为:
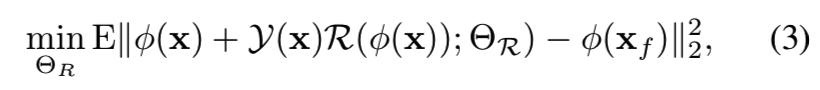
这里的ΘR表示R(.)的参数。上面的说明知道参数yaw coefficient —— Y(X)也是通过网络得到的结果,但是我们并不要训练这个网络,所以会将yaw网络的参数固定
使用SGD随机梯度下降方法,损失计算的是侧面人脸变换后的特征向量和同一个人正面人脸的特征向量的欧氏距离
4.训练
DREAM的使用方式有三种:
1)stitching
即对于给定的基本网络,我们只需将DREAM块缝合到基本网络的最终特征层上,而不需要改变原始模型的任何已知参数。这种方法最简单
2)End-to-End
该提出的轻量级块也可以以端到端的方式与stem CNN一起训练。给定一个简单的基本网络,插入DREAM块,并直接对新网络的所有参数进行随机初始化后进行训练。如果stem CNN不是普通的,而是之前训练过的,我们可以先微调stem CNN,同时使用现有的人脸识别loss(例如,verification loss,identification loss,或者两者都有),以端到端的方式训练DREAM 块。我们将该策略命名为“end2end”。使用这种策略,在侧脸上的表现不能得到保证,因为DREAM块可能无法区分正面和侧脸的情况,因为没有特定的正面-侧脸数据对用于训练该块。
3)End-to-end+retrain
我们一起训练stem CNN和DREAM块,然后分别使用用正脸-侧脸对训练DREAM块。这种方法效果最好
5.对应代码实现:
详细可见:https://github.com/penincillin/DREAM
DREAM块是如何加入模型的,src/end2end/ResNet.py:


class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000, end2end=True): self.inplanes = 64 self.end2end = end2end super(ResNet, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) self.layer4 = self._make_layer(block, 512, layers[3], stride=2) self.avgpool = nn.AvgPool2d(7) self.feature = nn.Linear(512 * block.expansion, 256) if self.end2end: self.fc1 = nn.Linear(256, 256) self.fc2 = nn.Linear(256, 256) self.fc = nn.Linear(256, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def _make_layer(self, block, planes, blocks, stride=1): downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes)) return nn.Sequential(*layers) def forward(self, x, yaw): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = x.view(x.size(0), -1) mid_feature = self.feature(x) # code above is the original arch of resnet if self.end2end: raw_feature = self.fc1(mid_feature) raw_feature = self.relu(raw_feature) raw_feature = self.fc2(raw_feature) raw_feature = self.relu(raw_feature) yaw = yaw.view(yaw.size(0),1) yaw = yaw.expand_as(raw_feature) feature = yaw * raw_feature + mid_feature else: feature = mid_feature feature = F.dropout(feature, p=0.7, training=self.training) pred_score = self.fc(feature) return pred_score
这个代码的作者已经将图片的yaw参数都计算出来了,所以在训练中该参数就作为一个常量输入了
读取该值的函数src/end2end/selfDefine.py:
def load_imgs(img_dir, image_list_file, label_file): imgs = list() max_label = 0 with open(image_list_file, 'r') as imf: with open(label_file, 'r') as laf: record = laf.readline().strip().split() #label_file第一行的数据记录了图片的总量total_num,以及种类数label_num total_num, label_num = int(record[0]), int(record[1]) for line in imf: img_path = os.path.join(img_dir, line.strip())#.strip()移除了头尾的空格 record = laf.readline().strip().split() label,yaw = int(record[0]), float(record[1]) #label_file后面每一行记录的分别是该图片的标签类别和yaw系数 max_label = max(max_label, label) #查看最后得到的最大类别标签是不是总类别数-1 imgs.append((img_path, label, yaw)) assert(total_num == len(imgs)) assert(label_num == max_label+1) return imgs, max_label
这个作者得到yaw运行的是src/test_process_align这个二进制执行文件得到的

