
Focal Loss for Dense Object Detection - 1 - 论文学习
迄今为止,精确度最高的目标探测器是基于R-CNN推广的两阶段方法,其中分类器应用于稀疏的候选对象位置集合。相比之下,对可能的目标位置进行常规、密集采样的单级探测器有可能更快、更简单,但迄今仍落后于两阶段探测器的精度。在这篇文章中,我们研究为什么会这样。我们发现,在高密度探测器的训练过程中所遇到的极度前、后级不平衡是其主要原因。我们建议通过重塑标准的交叉熵损失来解决这类不平衡,这样它就可以降低分类良好的例子的损失。我们的新Focal loss损失集中在一组稀疏的困难例子的训练,并防止训练期间大量的容易检测的负样本压倒探测器。为了评估损失的有效性,我们设计并训练了一个简单的高密度探测器,我们称之为RetinaNet。我们的结果表明,当使用Focal loss训练时,RetinaNet能够达到以前单阶段探测器的速度,同时超过所有现有的最先进的两阶段探测器的精度。代码是:https://github.com/facebookresearch/Detectron.
目前最先进的目标探测器是基于一个两阶段,proposal驱动的机制。正如R-CNN框架[11]所推广的那样,第一阶段生成一组稀疏的候选对象位置,第二阶段使用卷积神经网络将每个候选位置分类为前景类或背景类。通过一系列的改进[10,28,20,14],这个两阶段的框架始终能够在具有挑战性的COCO基准[21]上达到最高的精度。
尽管两级探测器已经取得了成功,一个很自然的问题是:一个简单的单级探测器能否达到同样的精度?一级检测器应用于对象位置、尺度和宽高比的常规、密集采样。最近在单级探测器上的研究,如YOLO[26,27]和SSD[22,9],展示了有希望的结果,与最先进的两级方法相比,能产生10- 40%精度的更快的探测器。
本文进一步推动了这一领域的研究:我们首次提出了一种单级目标探测器,该探测器可与更复杂的两级探测器的最新COCO AP相匹配,如特征金字塔网络(FPN)[20]或Faster R-CNN[28]的Mask R-CNN[14]变体。为了实现这一结果,我们确定了在训练期间的不平衡是阻碍单级探测器实现最先进的精度的主要障碍,并提出了消除这一障碍的新损失函数。
类不平衡问题在类R-CNN检测器中通过两阶段级联和采样启发来解决。proposal阶段(如 Selective Search[35]、EdgeBoxes[39]、DeepMask[24, 25]、RPN[28])迅速将候选对象位置的数量缩小到一个小的数量(如1-2k),过滤掉大部分背景样本。在第二个分类阶段,采样启发式,如一个固定的前背景比(1:3),或困难样本挖掘(OHEM)[31],是执行以保持前景和背景之间有一个易于管理的平衡。
相比之下,一个单级探测器必须处理一组更大的候选对象位置,这些对象位置是通过图像定期采样的。在实践中,这通常相当于枚举约100k个位置,这些位置密集地覆盖了空间位置、尺度和宽高比。虽然也可以使用类似的抽样启发法,但它们的效率很低,因为训练过程仍然由容易分类的背景样本主导。这种低效率是对象检测中的一个经典问题,通常通过引导bootstrapping[33,29]或困难样本挖掘[37,8,31]等技术来解决。
在这篇论文中,我们提出了一个新的损失函数,作为一个更有效的替代方法来处理类不平衡问题。损失函数是一个动态缩放的交叉熵损失,当对正确类的置信度增加时,比例因子衰减为零,见图1:
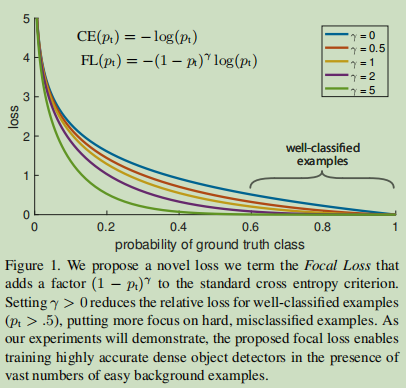
直观地,这个比例因子可以自动降低训练过程中简单样本的贡献,并快速地将模型集中在困难样本上。实验表明,我们提出的Focal loss使我们能够训练一个高精度的单级检测器,它的性能显著优于使用采样启发法或困难样本挖掘的训练方法,后者是训练单级检测器的最新技术。最后,我们注意到Focal loss的确切形式并不重要,我们还展示了其他实例化可以获得类似的结果。
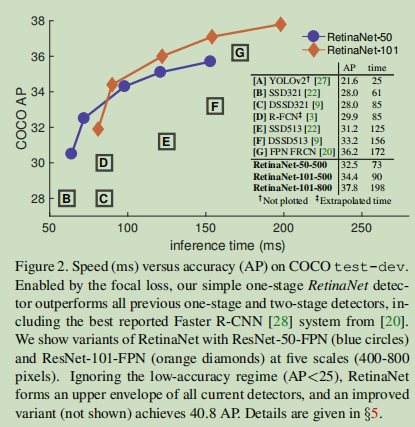
为了证明提出的Focal loss的有效性,我们设计了一个简单的单级目标探测器,称为RetinaNet,它的名字来源于它对输入图像中目标位置的密集采样。它的设计特点是高效的网络内特征金字塔和anchor boxes的使用。它借鉴了来自[22,6,28,20]的各种最新思想。RetinaNet是高效且准确的;我们的最佳模型,基于ResNet-101-FPN主干,在以5 fps运行的情况下,实现了COCO test-dev AP 39.1的结果,超过了以前发布的来自一个和两个阶段检测器的最佳单模型结果,参见图2:
Classic Object Detectors: 滑动窗口模式是使用后网络中有一个分类器是应用在一个密集的图像网格的方法,其有一个悠久而丰富的历史。最早的成功案例之一是LeCun等人的经典著作,他们将卷积神经网络应用于手写体数字识别[19,36]。Viola和Jones[37]使用增强的对象检测器进行人脸检测,从而导致了此类模型的广泛采用。HOG[4]和integral channel features[5]的引入,为行人检测提供了有效的方法。DPMs[8]帮助将密集探测器扩展到更通用的对象类别,并在PASCAL[7]上获得了多年的顶级结果。虽然滑动窗口方法是经典计算机视觉中最主要的检测范式,但是随着深度学习[18]的复苏,下面将介绍的两级检测器很快就开始主导对象检测。
Two-stage Detectors: 现代对象检测的主要范式是基于两阶段方法。作为选择性搜索工作[35]的先驱,第一阶段生成一个稀疏的候选建议集,它应该包含所有的对象,同时过滤掉大部分的负样本位置,第二阶段将建议分类为前景类/背景类。R-CNN[11]将第二阶段的分类器升级为一个卷积网络,在准确率上获得了巨大的提升,迎来了现代的目标检测时代。多年来,R-CNN在速度[15,10]上和使用学习对象建议[6,24,28]方面都得到了改进。区域建议网络(RPN)将第二阶段分类器生成的建议集成到单个卷积网络中,形成Faster RCNN框架[28]。对这一框架提出了许多扩展,如[20,31,32,16,14]。
One-stage Detectors: OverFeat[30]是第一款基于深度网络的单级目标探测器。最近,SSD[22,9]和YOLO[26,27]重新对单阶段方法产生了兴趣。这些探测器已经调整了速度,但其准确性落后于两阶段的方法。SSD的AP降低了10-20%,而YOLO侧重于更极端的速度/准确性权衡。参见图2。最近的工作表明,只要降低输入图像的分辨率和proposals的数量,就可以使两级检测器快速工作,但是,即使在较大的计算预算[17]的情况下,单级方法在准确性上仍然落后。相比之下,这项工作的目的是了解在以相似或更快的速度运行时,单级探测器是否能与两级探测器的精度相匹配或超过后者。
我们的RetinaNet探测器的设计与之前的密集探测器有很多相似之处,特别是RPN[28]引入的“anchors ”概念和SSD[22]和FPN[20]中特征金字塔的使用。我们强调,我们的简单的检测器之所以能取得最好的结果,不是因为网络设计上的创新,而是因为我们的新损失。
Class Imbalance: 无论是经典的单级对象检测方法,如boosted检测器[37,5]和DPMs[8],还是较新的方法,如SSD[22],在训练过程中都面临较大的类不平衡。这些探测器每幅图像评估104-105个候选位置,但只有少数位置包含物体。这种不平衡导致了两个问题:
(1)训练效率低,大部分地点容易出现负样本,没有有用的学习信号;(2)整体而言,容易判断的负样本(即大量的背景样本)会压倒训练,导致模型退化。一个常见的解决方案是执行某种形式的困难样本挖掘[33,37,8,31,22],在训练期间采样困难样本或更复杂的采样/重估方案[2]。相反,我们展示了我们提出的Focal loss自然地处理了单级探测器所面临的类不平衡问题,并允许我们在所有的例子上进行有效的训练,而不需要采样,也没有出现简单判断的负样本会颠覆损失和计算出的梯度。
Robust Estimation: 人们对设计鲁棒的损失函数(例如Huber loss[13])非常感兴趣,该函数通过降低具有较大错误的样本(困难样本)的损失的权重来减少异常值的贡献。相比之下,我们的重点损失并不是处理异常值,而是通过减少inliers(简单样本)的权重比来解决阶级不平衡,这样即使inliers的数量很大,它们对总损失的贡献也很小。换句话说,Focal loss起到了与鲁棒性损失相反的作用:它将训练集中在一组稀疏的困难例子上。

其中y∈{±1}指定是否为真实类(1表示为真实类,-1表示为非真实类),p∈[0,1]为标签y = 1的类的模型估计概率。为了便于标记,我们定义pt:
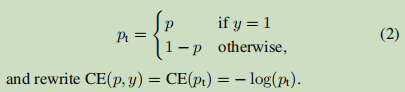
CE损失如图1中的蓝色(顶部)曲线所示。这种损失的一个值得注意的性质是,即使是很容易分类的例子(即pt远远大于0.5)也会产生不小的损失。当对大量简单的示例进行求和时,这些小的损失值可能会淹没很少的类(即不容易分类的类)。
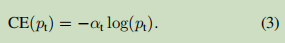
这种损失是对CE的简单扩展,我们将其作为我们提出的focal loss的实验基线。
正如我们的实验所显示的,在训练密集探测器的过程中所遇到的数量大的类的不平衡抵消了交叉熵损失。容易分类的负样本(即背景类)构成了大部分的损失,并主导了梯度。虽然α平衡了正/负例子的重要性,但是不区分容易/难的样本。相反,我们建议重塑损失函数来降低简单样本的权重,从而将训练集中在困难的负样本。
更正式来说,我们建议添加一个调节因子(1 - pt)γ的交叉熵损失,用可调节的focusing参数γ≥0。我们将focal loss定义为:
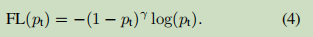
focal loss中设置γ为γ∈[0, 5]重的几个不同的值的可视化结果如图1所示。我们注意到focal loss的两个特性:(1)当一个例子被错误分类且pt值很小时(说明这是个困难样本),调制因子接近1且focal loss不受影响。当pt→1时,调制因子趋近于0,该损失对于分类良好的样本(即正样本p趋于1,负样本p趋于0,所以分类良好的简单样本pt趋于1)的损失是权重下降的(因为希望更加注意在困难样本中。即那些处于中间的样本,容易为正或负,这样子训练出来的网络更好)。(2)focusing参数γ平稳调整简单样本权重下降的速率。当γ= 0,FL相当于CE,当γ增加时,调制因子的影响也同样增加了(我们发现当设置γ= 2时我们的实验效果最好)。
直观地说,调制因子减少了来自简单样本的损失贡献,并扩展了样本获得低损失的范围。例如,γ= 2,一个例子分类为pt = 0.9时与CE相比将得到降低100倍的损失, pt≈0.968时相比,将得到降低1000倍的损失。这反过来增加纠正错误分类的例子的重要性(对于pt≤0.5且γ= 2时,其损失是按比例缩小最多4倍,这样这个损失就比容易分类的损失大得多得多了)。
在实践中我们使用一个α-balanced focal loss的变体:
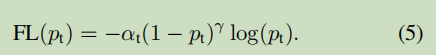
在我们的实验中采用了这种形式,因为它对比没有α-balanced形式的损失的精度略提高了一点。最后,我们注意到连接了计算用于损失的p的sigmoid操作的损失层的实现获得了更大的数值稳定性。
虽然在我们的主要实验结果中我们使用了上面的focal loss定义,但它的精确形式并不重要。在附录中,我们考虑了其他实例的focal loss,并证明这些同样有效。
默认情况下,将二进制分类模型初始化为概率相等的输出,为y = -1或1。在这样的初始化下,在类不平衡的情况下,频繁类能主导整体的损失,导致早期训练的不稳定性。为了解决这个问题,我们在训练开始的时候引入了“先验”的概念来表示由模型估计的稀有类(foreground)的p值。我们用π表示该先验并设置它,这样模型用于稀有类样本的估计p值是低的,例如0.01。我们注意到这是模型初始化的一个变化(参见§4.1),而不是损失函数的变化。我们发现在严重的类不平衡的情况下,这可以改善交叉熵和focal loss的训练稳定性。
两阶段探测器通常使用没有使用α-balancing或我们提议的损失的交叉熵损失来训练。相反,他们通过两种机制来解决类不平衡:(1)两阶段级联和(2)有偏 minibatch抽样。第一个级联阶段是一个对象proposal机制[35,24,28],它将几乎无限的可能的对象位置集数量减少到1000或2000。重要的是,所选择的proposals不是随机的,而是可能与真实的目标位置相对应的,这就消除了绝大多数容易判断的负样本。在训练第二阶段时,有偏抽样通常用于构建包含正、负样本比例为1:3的小批量。这个比例就像是通过采样实现的一个隐式α-balancing因素。我们提出的focal loss设计是为了在一个单阶段检测系统中直接通过该损失函数来解决这些机制。
RetinaNet是一个单一的、统一的网络,由一个主干网络和两个特定于任务的子网络组成。主干负责计算整个输入图像上的卷积特征映射,是一个自定义卷积网络。第一个子网络对主干的输出进行卷积对象分类;第二个子网络执行卷积边界框回归。这两个子网具有一个简单的设计,我们特别针对单级密集检测提出了这个设计,参见图3:
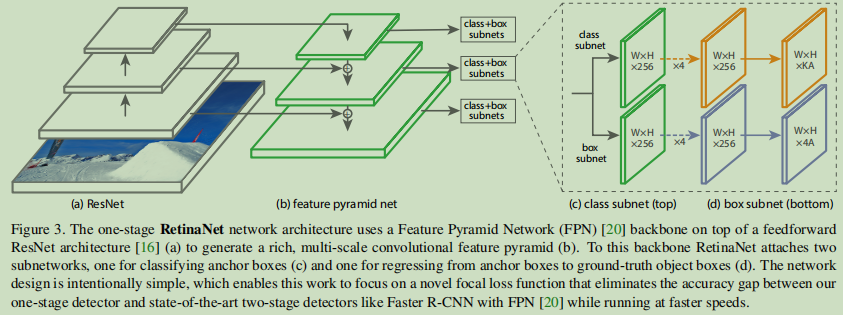
虽然这些组件的细节有许多可能的选择,但大多数设计参数对实验中显示的精确值不是特别敏感。
接下来,我们将介绍RetinaNet的各个组成部分。
特征金字塔网络backbone: 我们采用来自[20]的特征金字塔网络(FPN)作为支持网络的backbone。简而言之,FPN通过自顶向下的路径和横向连接扩展了标准的卷积网络,使得该网络能够有效地从单个分辨率输入图像构建丰富的多尺度特征金字塔,如图3(a)-(b)所示。金字塔的每一层都可以用来探测不同尺度的物体。FPN改进了全卷积网络(FCN)[23]的多尺度预测,从它对RPN[28]和DeepMask-style proposals[24]的改进,以及对两阶段检测器如Fast R-CNN[10]或Mask R-CNN[14]的改进可以看出。
遵循[20],我们在ResNet架构[16]之上构建FPN。我们构建了一个从P3到P7的金字塔,其中l表示金字塔级别(Pl层有着比输入低2l倍的分辨率)。在[20]中,所有金字塔级别都有C = 256通道。金字塔的细节通常遵循[20],只有一些细微的差别。虽然许多设计选择并不重要,但我们强调使用FPN backbone是很重要的;仅使用最后一层的特征进行的初步实验获得了较低的AP。
Anchors: 我们使用translation-invariant的anchor boxes,类似于[20]中的RPN变体。在P3至P7的金字塔级别上,anchors的面积分别为322至5122。在[20]中,在每个金字塔级别,我们使用三个宽高比比例的anchors,即{1:2,1:1,2:1}。对于比[20]更密集的尺度覆盖,我们在每一层添加尺寸为原来3个宽高比anchors集的{20、21/3、22/3}倍。这在我们的设置中改进了AP。每层总共有9个锚点,它们覆盖了32-813像素范围内的网络输入图像。
每个anchors都有一个长度为K的分类目标值的one-hot向量,其中K为目标类的数量,以及一个长度为4的边界框回归目标值向量。我们使用来自RPN[28]的赋值规则,但对多类检测进行了修改,使用调整的阈值。具体来说,anchors使用阈值为0.5及以上的交并比(IoU)来说明该anchors为真实目标对象框;如果他们的IoU是在[0,0.4]范围中,则说明该anchors是背景。由于每个anchors最多分配给一个真实对象框,我们将其长度为K的label向量中的对应条目设置为1,而所有其他条目设置为0。如果一个anchors没有被分配(即不是对象框也不是背景),这说明该anchors的IoU结果在[0.4,0.5]之间,它在训练中被忽略。框回归目标被计算为每个anchor与其分配的对象框之间的偏移量,如果没有分配,则省略。
classification Subnet: 分类子网预测A个anchors和K个目标类在每个空间位置中出现的概率。这个子网是连接到每个FPN级别的一个小FCN网络;这个子网的参数在所有金字塔级别上共享。它的设计很简单。从一个给定的金字塔级别获取一个带有C通道的输入特征图,子网应用4个3×3的卷积层,每个层使用C个过滤器,每个过滤器后都使用ReLU激活函数,然后使用一个带有K*A个过滤器的3×3的卷积层。最后,sigmoid激活函数被附加到输出每个空间位置的K*A的二元预测,见图3 (c)。我们在大多数实验中使用c = 256和A = 9。
与RPN[28]相比,我们的对象分类子网更深,只使用3×3 convs,并且不与box regression子网共享参数(后面将介绍)。我们发现这些更高级的设计决策比超参数的特定值更重要。
Box Regression Subnet: 与对象分类子网并行,我们将另一个小FCN网附加到每个金字塔级别上,以便将每个anchor box的偏移量回归到附近的真实对象框上(如果存在的话)。框回归子网的设计与分类子网相同,除了该子网每个空间位置的输出为4A的线性输出,参见图3 (d)。对于每个空间位置的A个anchors,这四个输出预测真实框和anchor之间的相对偏移量(我们使用R-CNN中的标准框参数[11])。我们注意到,与最近的工作不同,我们使用了一个类不可知的边界框回归器,它使用更少的参数,我们发现它同样有效。对象分类子网和框回归子网虽然共享同一结构,但使用不同的参数。
4.1. Inference and Training
推论:RetinaNet形成一个单独的FCN,由一个ResNet-FPN主干、一个分类子网和一个框回归子网组成,见图3。因此,推理只涉及在网络中前向传播图像。为了提高速度,我们只对每个FPN级别的前1k个最高得分的预测进行解码,然后将检测器置信度设置为0.05。将所有级别的最高预测进行合并,并使用阈值为0.5的非最大抑制来产生最终的检测结果。
Focal loss: 我们使用本文中介绍的focal loss作为分类子网输出的loss。§5中我们将展示,我们发现当γ= 2时在实践中的效果比较好,当γ∈[0.5,5]时RetinaNet效果相对鲁棒。我们强调,在训练RetinaNet时,将Focal loss应用于每个采样图像中所有约100k个的anchors。这与通常使用启发式抽样(RPN)或困难样本挖掘(OHEM, SSD)方法来为每个小批量选择一组锚点(例如,256)形成了对比。图像的总focal loss计算为所有约100k个anchors的focal loss之和,由分配给真实框的anchors数量进行标准化。我们用分配的anchors的数量来进行归一化,而不是用全部的anchors,因为绝大多数的anchors都是容易被否定的,并且在focal loss下接收到的损失值可以忽略不计。最后我们要注意α值,该权重分配到罕见的类,也有一个稳定的范围内,但它与γ一起就有必要同时选择这两个参数的值(见表1 a和1 b):
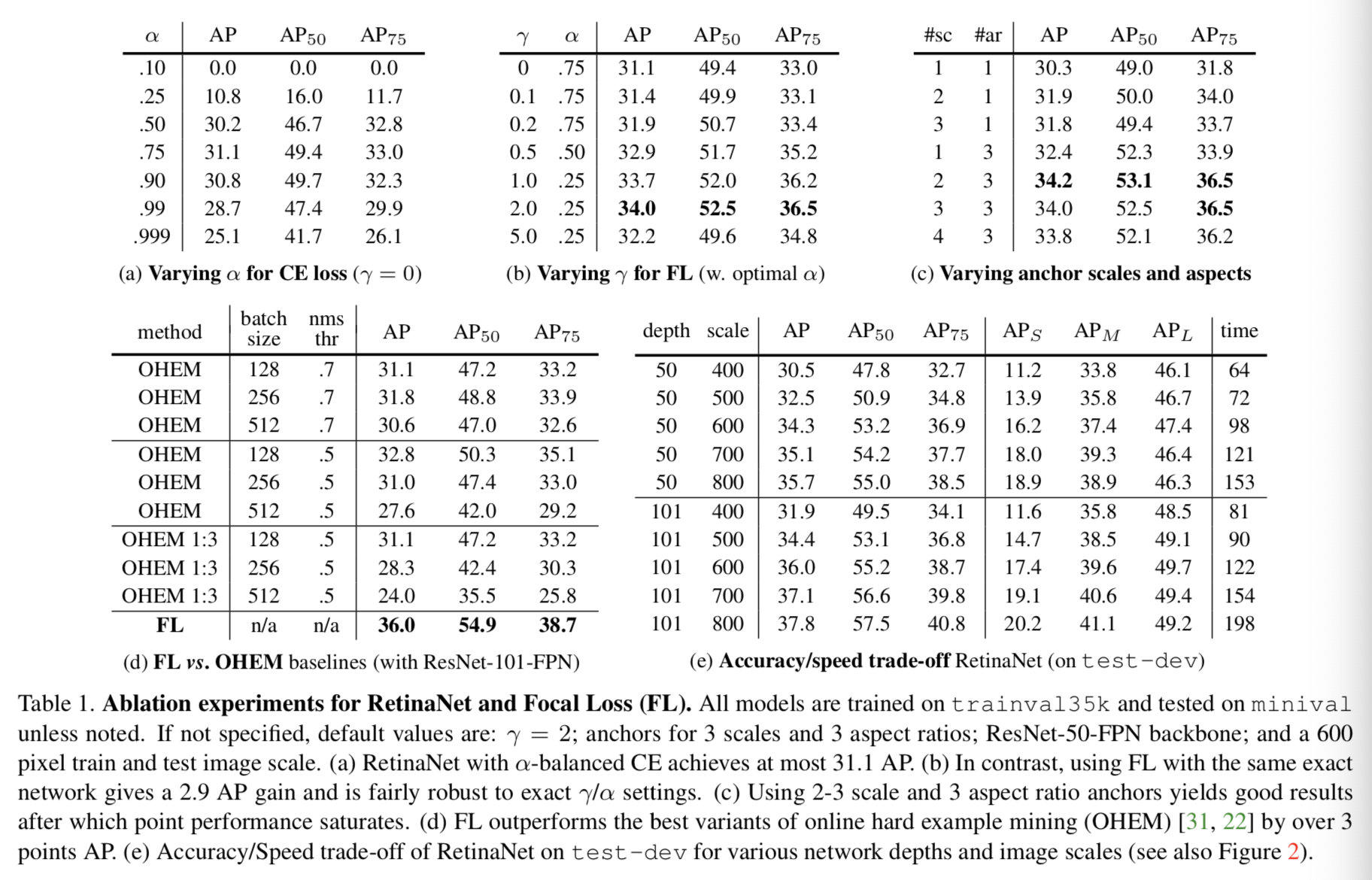
当γ增加时,一般α应该稍微降低(γ= 2,α= 0.25的效果最好)。
initialization: 我们用ResNet-50-FPN和ResNet-101-FPN的backbones[20]进行实验。在ImageNet1k上对基础ResNet-50和ResNet-101模型进行预训练;我们使用[16]发布的模型。在[20]中初始化为FPN添加的新层。RetinaNet子网中除了最后一层的所有新conv层都初始化为偏差b = 0和Gaussian权重使用σ= 0.01。分类子网的最后conv层,我们设置了偏差初始化为b =−log((1−π)/π),在π指定在每一个anchor的训练开始都应该被标记为置信度约为π的foreground。在所有的实验中,我们使用π= . 01,虽然结果对精确值来说是鲁棒的。正如§3.3中所解释的,这种初始化可以防止大量的背景anchors在训练的第一次迭代中产生较大的、不稳定的损失值。
optimization: 用随机梯度下降法(SGD)训练RetinaNet。我们在8个GPU上使用同步的SGD,每个minibatch总共有16张图片(每个GPU 2张)。除非另有说明,所有模型都接受了90k迭代的训练,初始学习率为0.01,然后在60k时除以10,在80k迭代时再除以10。除非另有说明,我们使用水平图像翻转作为唯一的数据增强形式。使用0.0001的权重衰减值和0.9的动量值。训练损失是focal loss与用在框回归值[10]中的标准平滑L1损失之和。表1e中模型的训练时间为10到35小时。
5. Experiments
省略
6. Conclusion
在这项工作中,我们确定类不平衡是阻止单阶段对象检测器超越性能最好的两阶段方法的主要障碍。为了解决这一问题,我们提出了focal loss,它将调制项应用于交叉熵损失,以便将学习集中在困难的负样本上。我们的方法简单而高效。我们通过设计一个全卷积的单阶段检测器来证明它的有效性,并报告了大量的实验分析,结果表明它达到了最先进的精度和速度。代码可见https://github.com/facebookresearch/Detectron [12]
focal loss 代码实现可见Class-Balanced Loss Based on Effective Number of Samples - 2 - 代码学习

