
go语言程序设计学习笔记-1
https://www.jb51.net/article/126998.htm
go标准库文档https://studygolang.com/pkgdoc
1.
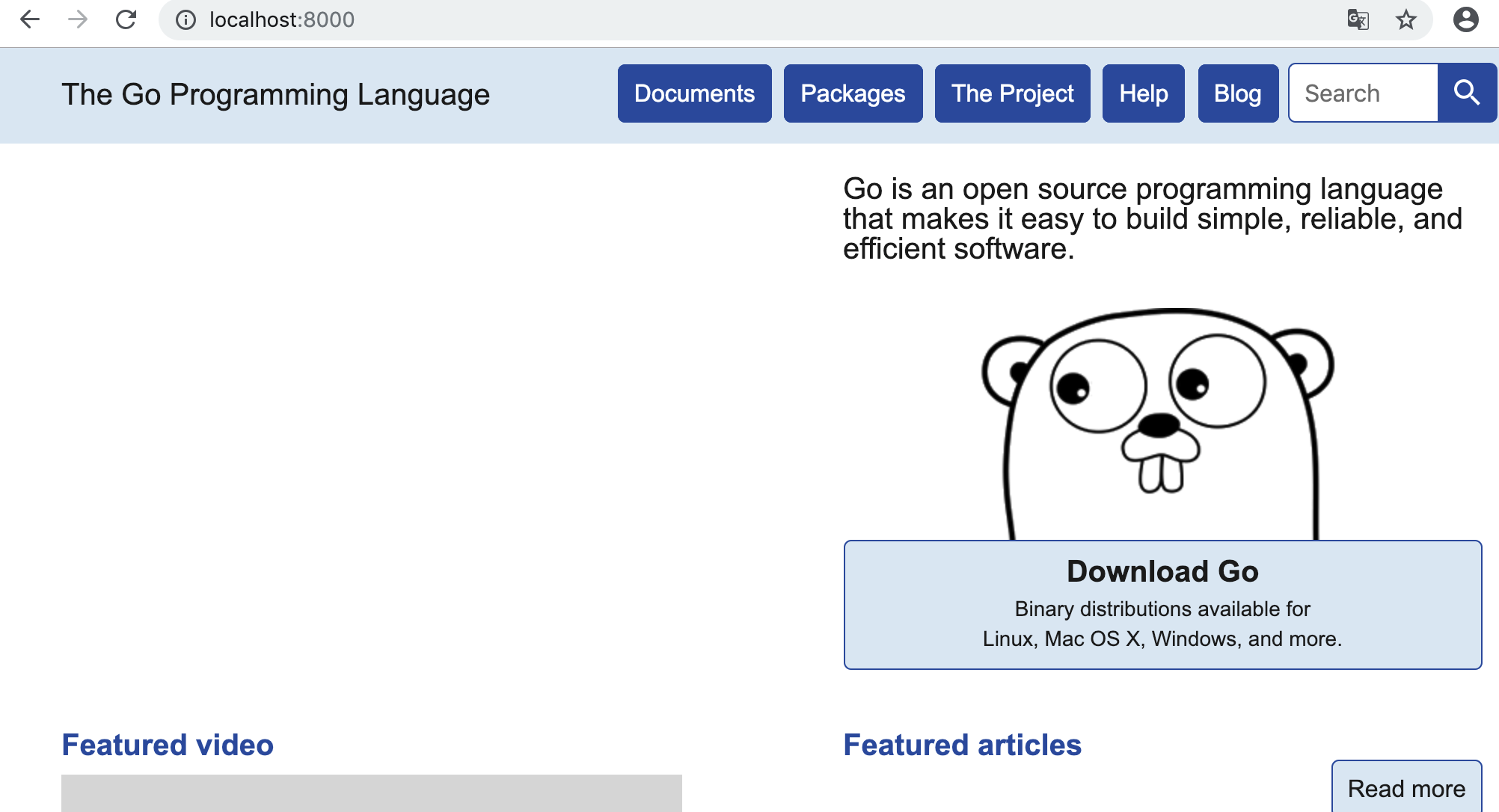
如果想要再本地直接查看go官方文档,可以再终端中运行:
userdeMacBook-Pro:~ user$ godoc -http=:8000
然后在浏览器中运行http://localhost:8000就能够查看文档了,如下图所示:
2.os.Args : Args保管了命令行参数,第一个是程序名
3.所有的go语言代码都只能放置在包中,每一个go程序都必须包含一个main包以及一个main函数。main()函数作为整个程序的入口,在程序运行时最先被执行。实际上go语言中的包还可能包含init()函数,它先于main()函数被执行
4.包名和函数名之间不会发生命名冲突
5.go语言针对处理的单元是包而非文件,如果所有文件的包声明都是一样的,那么他们属于同一个包
6.
1)
package main import ( "fmt" "os" "strings" "path/filepath" ) //"path/filepath"类的引用只需要其最后一部分,即filepath func main(){ who := "world!" //Args保管了命令行参数,第一个是程序名 fmt.Println(os.Args) //返回:[/var/folders/2_/g5wrlg3x75zbzyqvsd5f093r0000gn/T/go-build178975765/b001/exe/test] fmt.Println(filepath.Base(os.Args[0]))//返回传入路径的基础名,即文件名test if len(os.Args) > 1 {//则运行时是带有命令行参数的 who = strings.Join(os.Args[1:]," ")//返回一个由" "分隔符将os.Args[1:]中字符串一个个连接生成一个新字符串 } fmt.Println("Hello", who) //返回:Hello world! }
不带命令行参数的运行返回:
userdeMBP:go-learning user$ go run test.go [/var/folders/2_/g5wrlg3x75zbzyqvsd5f093r0000gn/T/go-build644012817/b001/exe/test] test Hello world!
带命令行参数的运行返回:
userdeMBP:go-learning user$ go run test.go i am the best [/var/folders/2_/g5wrlg3x75zbzyqvsd5f093r0000gn/T/go-build463867367/b001/exe/test i am the best] test Hello i am the best
2)import
支持两种加载方式:
1》相对路径
import "./model"
2》绝对路径
import "shorturl/model"
下面还有一些特殊的导入方式:
1〉点操作
import( . "fmt" )
这个点操作的作用就是这个包导入后,当你想要调用这个包的函数的时候,你就能够省略它的包名了,即fmt.Println()可以省略成Println()
2>别名操作
import( f "fmt" )
就是把上面的fmt包重命名成一个容易记忆的名字,调用可以变成f.Println()
3>_操作
import( _ "github.com/ziutek/mymysal/godrv" )
其作用就是引入该包,而不直接使用包里面的函数或变量,会先调用包中的init函数,这种使用方式仅让导入的包做初始化,而不使用包中其他功能
7.在go语言中,byte类型等同于uint8类型
8.注意:在go中++和--等操作符只会用于语句而非表达式中,可能只可以做成后缀操作符而非前缀操作符。即go中不会出现f(i++)或A[i]=b[++i]这样的表达式
9.相同结构的匿名类型等价,可以相互替换,但是不能有任何方法
任何命名的自定义类型都可以有方法,并且和这些方法一起构成该类型的接口。命名的自定义类型即时结构完全相同,也不能相互替换
接口也是一种类型,可以通过指定一组方法的方式定义。接口是抽象的,因此不可实例化。如果某个具体类型实现了某个接口所有的方法,那么这个类型就被认为实现了该接口。一个类型可以实现多个接口。
空接口(即没有定义方法的接口),用interface{}来表示。由于空接口没有做任何要求(因为它不需要任何方法),它可以用来表示任意值(效果相当于一个指向任意类型值的指针),无论这个值是一个内置类型的值还是一个自定义类型的值,如:
type Stack []interface{}
上面的空接口其实就相当于一个可变长数组的引用
⚠️在go语言中只讲类型和值,而非类、对象或实例
10.go语言的函数和方法均可返回单一值或多个值。go语言中报告错误的管理是函数或方法的最后一个返回值是一个错误值error,如:
item,error := someFunc()
11.无限循环的使用要配合break或return来停止该无限循环
... for{ item,err := haystack.Pop() if err != nil{ break } fmt.Println(item) }
12.
func (stack *Stack) Push(x interface{}){ *stack = append(*stack,x) }
其中(stack *Stack)中的stack即调用Push方法的值,这里成为接收器(在其他语言中是使用this,self来表示的)
如果我们想要修改接收器,就必须将接收器设为一个指针,如上面的*Stack,使用指针的原因是:
- 效率高;如果我们有一个很大的值,那么传入一个指向该值所在的内存地址的指针会比传入该值本身更便宜
- 是一个值可以被修改;将一个变量传入函数中其实只是传入了他的一个副本,对该值的所有改动都不会影响其原始值(即值传递)。所以如果我们想要更改原始值,必须传入指向原始值的指针
*stack表示解引用该指针变量,即引用的是该指针所指之处的实际Stack类型值13.go中的通道(channel)、映射(map)和切片(slice)等数据结构必须通过make()函数创建,make()函数返回的是该类型的一个引用14.如果栈没有被修改,那么可以使用值传递,如:
func (stack Stack) Top(interface{},error){ if len(stack) == 0{ return nil,errors.New("can't Top an empty stack") } return stack[len(stack)-1],nil }
可见该例子的接收器就没有使用指针,因为该例子没有修改栈
15.任何属于defer语句所对应的语句都保证会被执行,但是其后面对应的函数只会在该defer语句所在的函数返回时被调用(即其不马上运行,而是推迟到该函数的其他所有语句都运行完后再返回来运行它),如:
func main(){
....
defer inFile.Close()
....
defer outFile.Close()
....
}
在上面的例子可以保证打开的文件可以继续被它下面的命令使用,然后会在使用完后才关闭,即使是程序崩溃了也会关闭
16.在go语言中,panic是一个运行时错误(翻译为‘异常’)。可以使用内置的panic()函数来触发一个异常,还可以使用recover()函数来调用栈上阻止该异常的传播。理论上,go的panic/recover功能可以用于多用途的错误处理机制,但是我们并不推荐这么使用。更合理的错误处理方式时让函数或者方法返回一个error值。panic/recover机制的目的是处理真正的异常(即不可预料的异常),而不是常规错误
17.PDF中的1.7的例子很好,值得多看
18.打印到终端其实是有返回值的,一般都忽略,但是其实是应该检查其返回的错误值的
count , err := fmt.Println(x) //获取打印的字节数和相应的error值 _ , err := fmt.Println(x) //丢弃打印的字节数,返回error值 count , _ := fmt.Println(x) //获取打印的字节数,丢弃error值 fmt.Println(x) //忽略所有返回值
19.常量赋值的特性
1)使用iota
package main import "fmt" const ( a = iota b c ) func main(){ fmt.Println(a)//0 fmt.Println(b)//1 fmt.Println(c)//2 }
使用iota,则在const的第一个常量中被设为0,接下来增量为1
2)如果b设为字符串"test",那么c的值和b一样,但是iota还是一样递增
package main import "fmt" const ( a = iota b = "test" c d = iota e ) func main(){ fmt.Println(a)//0 fmt.Println(b)//test fmt.Println(c)//test fmt.Println(d)//3 fmt.Println(e)//4 }
3)如果不使用iota,则第一个常量值一定要显示定义值,后面的值和其前一个的值相同:
package main import "fmt" const ( a =1 b = "test" c d = 5 e ) func main(){ fmt.Println(a)//1 fmt.Println(b)//test fmt.Println(c)//test fmt.Println(d)//5 fmt.Println(e)//5 }
20.逻辑操作符
1)|| 和 &&
b1 || b2 :如果b1为true,则不会检测b2,表达式结果为true
b1 && b2 : 如果b1为false,则不会检测b2,表达结果为false
2)< 、<=、 == 、!= 、>= 、>
比较的两个值必须是相同类型的
如果两个是接口,则必须实现了相同的接口类型
如果有一个值是常量,那么它的类型必须和另一个类型相兼容。这意味着一个无类型的数值常量可以跟另一个任意数值类型的值进行比较
不同类型且非常量的数值不能直接比较,除非其中一个被显示地转换成与另一个相同类型的值,类型转换即type(value)
21.整数

go语言允许使用byte来作为无符号uint8类型的同义词
并且使用单个字符(即Unicode码点)的时候提倡使用rune来替代uint32
大多数情况下,我们只需要一种整形,即int
从外部程序(如从文件或者网络连接读写整数时,可能需要别的整数类型)。这种情况下需要确切地知道需要读写多少位,以便处理该整数时不会发生错乱
常用做法是将一个整数以int类型存储在内存中,然后在读写该整数的时候将该值显示地转换为有符号的固定尺寸的整数类型。byte(uint8)类型用于读或写原始的字节。例如,用于处理UTF-8编码的文本
大整数:
有时我们需要使用甚至超过int64位和uint64位的数字进行完美的计算。这种情况下就不能够使用浮点数,因为他们表示的是近似值。
因此Go的标准库种提供了无限精度的整数类型:用于整数的big.Int型以及用于有理数的big.Rat型(即包括可以表示分数的2/3和1.1496.但不包括无理数e或者Π)
但是无论什么时候,最好只使用int类型,如果int型不能满足则使用int64型,或者如果不是特别关心近似值的可以使用float32或者float64类型。
然而如果计算需要完美的精度,并愿意付出使用内存和处理器的代价,那么就使用big.Int或者big.Rat类型
22.Unicode编码——使用四个字节为每个字符编码
它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求
Unicode编码的使用意味着go语言可以包含世界上任意语言的混合,代码页没有任何的混乱和限制
每一个Unicode字符都有一个唯一的叫做“码点”的标识数字,其值从0x0到0x10FFFF,后者在go中被定义成一个常量unicode.MaxRune
23.字符串
go语言的字符串类型在本质上就与其他语言的字符串类型不同。Java的string、C++的std:string和python3的str类型都是定宽字符序列,即字符串中的每个字符的宽度是相同的。但是go的字符串是一个用UTF-8编码的变宽字符串。
UTF-8 使用一至四个字节为每个字符编码,其中大部分汉字采用三个字节编码,少量不常用汉字采用四个字节编码。因为 UTF-8 是可变长度的编码方式,相对于 Unicode 编码可以减少存储占用的空间,所以被广泛使用。
一开始可能觉得其他语言的字符串类型比go的好用,因为他们定长,所以字符串中的单个字符可以通过索引得到,而go语言只有在字符串中的字符都是7位ASCII字符(7位ASCII字符刚好能用一个UTF-8字节来表示,即都用一个单一的UTF-8字节表示)时才能索引
但在实际情况下,其并不是个问题,因为:
- 直接索引用得不多
- go支持一个字符一个字符的迭代,for index,char := range string{},每次迭代都产生一个索引位置和一个码点
- 标准库提供了大量的字符串搜索和操作函数
- 随时可以将字符串转换成一个Unicode码点切片(类型为[]rune),这个切片是可以直接索引的
所以:
[]rune(s)
能将一个字符串s转换成一个Unicode码点
如果想要转回来即:
s := string(chars)//chars的类型即[]rune或[]int32
上面两个时间代价为o(n)
len([]rune(s))
可以得到字符串s中字符的个数,当然你可以使用更快的:
utf8.RuneCountInString()
来替代
[]byte(s)
可以无副本地将字符串s转换成一个原始字节的切片数组,时间代价为o(1)
string(bytes)
无副本地将[]byte或[]uint8转换成一个字符串类型,不保证转换的字节是合法的UTF-8编码字节,时间代价为o(1)
举例:
package main import "fmt" func main(){ s := "hello world,i am coming" uniS := []rune(s) retS := string(uniS) bytS := []byte(s) retBytS := string(bytS) fmt.Println(s)//hello world,i am coming fmt.Println(uniS)//[104 101 108 108 111 32 119 111 114 108 100 44 105 32 97 109 32 99 111 109 105 110 103] fmt.Println(retS)//hello world,i am coming fmt.Println(len([]rune(s)))//23 fmt.Println(bytS)//[104 101 108 108 111 32 119 111 114 108 100 44 105 32 97 109 32 99 111 109 105 110 103] fmt.Println(retBytS)//hello world,i am coming }
⚠️
go中字符串是不可变的,即不能如下这样操作:
var s string = "hello" s[0] = 'c'
如果真的想要修改,可如下:
s := "hello" c := []byte(s)//将其转换成[]byte类型 c[0] = 'c' //然后更改 s2 := string(c) //然后再将其转换回来即可
虽然字符串不能修改,但是它可以进行切片操作
如果想要声明一个多行的字符,可以使用``来声明,如:
m := `hello
world`
使用``括起来的是Raw字符串,即字符串在代码中的形式就是打印时的形式,没有字符转义,换行也原样输出
24.字符串索引和切片
之前有说过,我们完全不需要切片一个字符串,只需要使用for...range循环将其一个字符一个字符地迭代,但是有些时候我们可能还是需要使用切片来获得一个子字符串,这时的解决办法是:
go中有个能够按字符边界进行切片得到索引位置的方法:
即strings包中的函数:
- strings.Index()
- strings.LastIndex()
举例:
package main import( "fmt" "strings" ) func main(){ //目的:得到该行文本的第一个和最后一个字 line := "i am the best" i := strings.Index(line, " ") //获得第一个空格的索引位置 firstWord := line[:i] //切片得到第一个字 j := strings.LastIndex(line, " ") //获得最后一个空格的索引 lastWord := line[j+1:] //切片得到最后一个字 fmt.Println(firstWord, lastWord) //输出:i best }
上面的例子坏处在于不适合处理任意的Unicode空白字符,如U+2028(行分隔符)或U+2029(段分隔符),这时候就使用:
- strings.IndexFunc(s string, f func(rune)bool)int :s中第一个满足函数f的位置i(该处的utf-8码值r满足f(r)==true),不存在则返回-1。
- strings.LastIndexFunc():s中最后一个满足函数f的unicode码值的位置i,不存在则返回-1。
- utf8.DecodeRuneInString():得到输入的string中的码点rune和其编码的字节数
举例:
package main import( "fmt" "strings" "unicode" "unicode/utf8" ) func main(){ line := "ra t@RT\u2028var" i := strings.IndexFunc(line,unicode.IsSpace)//unicode.IsSpace是一个函数 firstWord := line[:i] j := strings.LastIndexFunc(line, unicode.IsSpace) r, size := utf8.DecodeRuneInString(line[j:]) lastWord := line[j+size:] fmt.Println(i,j,size)//2 7 3 fmt.Printf("%U\n",r) //U+2028 fmt.Println(firstWord, lastWord)//ra var }
func IsSpace(r rune) bool,IsSpace报告一个字符是否是空白字符

上面这个就是Unicode字符\u2028的字符、码点和字节,所以上面运行utf8.DecodeRuneInString()得到的r为U+2028,字节size为3

上面 s[0] == 'n',s[ len(s)-1 ] == 'e',但是问题在于第三个字符,其起始索引是2,但是如果我们使用s[2]只能得到该编码字符的第一个UTF-8字节,这并不是我们想要的
我们可以使用:
- utf8.DecodeRuneInString() : 解码输入的string中的第一个rune,最后返回该码点rune和其包含的编码的字节数
- utf8.DecodeLastRuneInString() : 解码输入的string中最后一个rune,最后返回该码点rune和其包含的编码的字节数
当然,实在想要使用索引[]的最好办法其实是将该字符串转换成[]rune(这样上面的例子将创建一个包含5个码点的rune切片,而非上面图中的6个字节),然后就能够使用索引调用了,代价就是该一次性转换耗费了CPU和内存o(n)。结束后可以使用string(char)来将其转换成字符
25.fmt
fmt包中提供的扫描函数(fmt.Scan()\fmt.Scanf()\fmt.Scanln())的作用是用于从控制台、文件以及其他字符串类型中读取数据
26.go语言提供了两种创建变量的语法,同时获得它们的指针:
- 使用内置的new()函数
- 使用地址操作符&
new(Type) === &Type{} (前提是该类型是可以使用大括号{}进行初始化的类型,如结构体、数组等。否则只能使用new()),&Type{}的好处是我们可以为其制定初始值
这两种语法都分配了一个Type类型的空值,同时返回一个指向该值的指针
先定义一个结构体composer:
type composer struct{ name string birthYear int }
然后我们可以创建composer值或只想composer值的指针,即*composer类型的变量
结构体的初始化可以使用大括号来初始化数据,举例:
package main import "fmt" type composer struct{ name string birthYear int } func main(){ a := composer{"user1",2001} //composer类型值 b := new(composer) //指向composer的指针 b.name, b.birthYear = "user2", 2002 //通过指针赋值 c := &composer{} //指向composer的指针 c.name, c.birthYear = "user3", 2003 d := &composer{"user4", 2004} //指向composer的指针 fmt.Println(a) //{user1 2001} fmt.Println(b,c,d) //&{user2 2002} &{user3 2003} &{user4 2004} }
当go语言打印指向结构体的指针时,它会打印解引用后的结构体内容,但会将取址操作符&作为前缀来表示它是一个指针
⚠️上面之所以b指针能够通过b.name来得到结构体中的值是因为在go语言中.(点)操作符能够自动地将指针解引用为它指向的结构体,都不会使用(*b).name这种格式
⚠️make、new操作
make用于内建类型(map、slice和channel)的内存分配。new用于各种类型的内存分配
1)new
new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即*T类型的值(指针),用于指向新分配的类型T的零值
2)make
make(T, args)只能创建map、slice和channel,并且返回的是有初始值(非零)的T类型,而不是*T指针。这是因为指向数据结构的引用在使用前必须被初始化。
比如一个slice是一个包含指向数据(内部array)的指针、长度len、容量cap的三项描述符,因此make初始化其内部的数据结构,然后填充适当的值
27.一旦我们遇到需要在一个函数或方法中返回超过四五个值的情况时,如果这些值是同一类型的话最好使用一个切片来传递,如果其值类型各异则最好传递一个指向结构体的指针。
传递一个切片或一个指向结构体的指针的成本都比较低(在64位的机器上一个切片占16位,一个映射占8字节),同时也允许我们修改数据
28.引用类型-映射、切片、通道、函数、方法
这样子当引用类型作为参数传入函数时,在函数中对该引用类型的改变都会作用于它本身,即引用传递
这是因为一个引用类型的变量指向的是内存中某个隐藏的值,其保存着实际的数据
package main import "fmt" func main(){ grades := []int{2,3,4,5} //整形切片 inflate(grades,3) fmt.Println(grades) //返回[6 9 12 15] } func inflate(numbers []int, factor int){ for i := range numbers{ numbers[i] *= factor } }
在上面的例子中我们没有使用for index,item := range numbers{}是因为这样的操作得到的是切片的副本,它的改变不会改变原始切片的值。所以这里我们使用的是for index := range语法
如果我们定义一个变量来保存一个函数,该变量得到的实际上是该函数的引用
29.数组、切片
- 数组是定长的 a := [3]int{1,2,3}/a := [...]int{1,2,3} ,[...]会自动计算数组长度,声明用 a:=[3]int
- 切片长度不定 b := []int{1,2,3}
a,b是不相同的。数组的cap()和len()函数返回的值是相同的,它也可以进行切片,即[i:j],但是返回的是切片,而非数组
数组是值传递,而切片是引用传递
在go的标准库中的所有公开函数中使用的都是切片而非数组,建议使用切片
当创建一个切片的时候,他会创建一个隐藏的初始化为零值的数组,然后返回一个引用该隐藏数组的切片。所以切片其实就是一个隐藏数组的引用
切片的创建语法:
- make([]Type, length, capacity) ,切片长度小于或等于容量
- make([]Type, length) ,下面三个长度等于容量
- []Type{} == make([]Type,0),空切片
- []Type{value1,...,valueN}
make()内置函数用来创建切片、映射、通道
可以使用append()内置函数来增加切片的容量
除了使用上面的方法还有一种方法:
package main import "fmt" func main(){ s := new([3]string)[:] //new()创建一个只想数组的指针,然后通过[:]得到该数组的切片 s[0], s[1], s[2] = "A", "B", "C" //赋值 fmt.Println(s) //返回[A B C] }
对切片的切片其实也是引用了同一个隐藏数组,所以如果对切片中的某个值进行了更改,那么该切片的切片中如果也包含该值,则发现也被更改了,举例:
package main import "fmt" func main(){ s := []string{"A", "B", "C"} t := s[1:] fmt.Println(s,t) //返回:[A B C] [B C] s[1] = "d" fmt.Println(s,t) //返回: [A d C] [d C] }
因为更改切片其实都是对底层的隐藏数据进行了修改
⚠️切片和字符串不同之处在于它不支持+或+=操作符,但是对切片进行添加、插入或删除的操作是十分简单的
- 遍历切片:for index,item := range amounts[:5] ,可遍历切片的前5个元素
- 修改切片中的项:for i:= range amounts{amounts[i] *= 3},不能使用上面的方法,那样得到的只是切片的副本,但是也有特别的情况,如下:
当切片包含的是自定义类型的元素时,如结构体
package main import "fmt" type Product struct{ name string price float64 } func main(){ products := []*Product{{"user1",11},{"user2",12},{"user3",13}} //等价于products := []*Product{&Product{"user1",11},&Product{"user2",12},&Product{"user3",13}} fmt.Println(products) //会自动调用Product的String方法,返回[user1 (11.00) user2 (12.00) user3 (13.00)] for _, product := range products{ product.price += 50 } fmt.Println(products) //返回[user1 (61.00) user2 (62.00) user3 (63.00)] } func (product Product) String() string{ return fmt.Sprintf("%s (%.2f)", product.name, product.price) }
如果没有定义Product.String()方法,那么%v格式符(该格式符在fmt.Println()以及类似的函数中被显示调用),输出的就是Product的内存地址,而非其内容,如:[0xc42000a080 0xc42000a0a0 0xc42000a0c0]
我们可以看见这里使用的是for index,item ...range迭代,这里能够成功的原因是product被赋值的是*Product的副本,这是一个指向底层数据的指针,所以成功
- 修改切片:append(array, ...args)内置函数,返回一个切片。如果原始切片中没有足够的容量,那么append()函数会隐式地创建一个新的切片,并将其原始切片的项复制进去,再在末尾添加上新的项,然后将新的切片返回,因此需要将append()的返回值赋值给原始切片变量
如果是想要从任意位置插入值,那么需要自己写一个函数,如:
package main import "fmt" func main(){ s := []string{"a","b","c","d"} x := InsertStringSlice(s,[]string{"e","f"},0) y := InsertStringSlice(s,[]string{"e","f"},2) z := InsertStringSlice(s,[]string{"e","f"},len(s)) fmt.Println(x) //[e f a b c d] fmt.Println(y) //[a b e f c d] fmt.Println(z) //[a b c d e f] } func InsertStringSlice(slice, insertion []string, index int)[]string{ return append(slice[:index],append(insertion,slice[index:]...)...) }
因为append()函数接受一个切片和一个或多个值作为参数,因此需要使用...(省略号语法)来将一个切片转换成它的多个元素值,因此上面的例子中使用了两个省略号语法
- 排序切片:sort.Sort(d)-排序类型为sort.interface的切片d、sort.Strings(s)-按升序排序[]string类型的切片s
sort.Sort(d)能够对任意类型进行排序,只要其类型提供sort.Interface接口中定义的方法:
type Interface interface { // Len方法返回集合中的元素个数 Len() int // Less方法报告索引i的元素是否比索引j的元素小 Less(i, j int) bool // Swap方法交换索引i和j的两个元素 Swap(i, j int) }
比如:
package main import( "fmt" "sort" "strings" ) func main(){ files := []string{"Test","uitl","Makefile","misc"} fmt.Printf("Unsorted: %q\n",files) //Unsorted: ["Test" "uitl" "Makefile" "misc"] sort.Strings(files)//区分大小写 fmt.Printf("underlying bytes:%q\n",files) //underlying bytes:["Makefile" "Test" "misc" "uitl"] SortFoldedStrings(files)//不区分大小写 fmt.Printf("Case insensitive:%q\n",files) //Case insensitive:["Makefile" "misc" "Test" "uitl"] } func SortFoldedStrings(slice []string){ sort.Sort(FoldedStrings(slice)) } type FoldedStrings []string func (slice FoldedStrings) Len() int { return len(slice) } func (slice FoldedStrings) Less(i,j int) bool{ return strings.ToLower(slice[i]) < strings.ToLower(slice[j]) } func (slice FoldedStrings) Swap(i,j int){ slice[i], slice[j] = slice[j], slice[i] }
- 搜索切片:sort.Search()
30.映射
map[string]float64:键为string类型,值为float64类型的映射
由于[]byte是一个切片,不能作为映射的键,但是我们可以先将[]byte转换成字符串,如string([]byte),然后作为映射的键字段,等有需要的时候再转换回来,这种转换并不会改变原有切片的数据
如果值的类型是接口类型,我们就可以创建一个满足这个接口定义的值作为映射的值,甚至我们可以创建一个值为空接口(interface{})的映射,这意味着任意类型的值都可以作为这个映射的值
不过当我们需要访问这个值时,需要使用类型开关和类型断言获得这个接口类型的实际类型,或者也可以通过类型检验来获得变量的实际类型
创建方式:
- make(map[keyType]ValueType,initialCapacity),随着加入的项越多,映射会自动扩容
- make(map[keyType]ValueType)
- map[keyType]ValueType{}
- map[keyType]ValueType{key1 : value1,...,keyN : valueN}
第二和第三种的结果是相同的
对于比较大的映射,最好是为其指定恰当的容量来提高性能
映射可以使用索引操作符[],不同在于其里面的值不用是int型,应该是映射的keyType值
映射的键也可以是一个指针,比如:
package main import "fmt" func main(){ triangle := make(map[*Point]string,3) triangle[&Point{89, 47, 27}] = "a" //使用&获得Point的指针 triangle[&Point{86, 65, 86}] = "b" triangle[&Point{7, 44, 45}] = "c" fmt.Println(triangle) //map[(89,47,27):a (86,65,86):b (7,44,45):c] } type Point struct{ x,y,z int} func (point Point) String() string{ return fmt.Sprintf("(%d,%d,%d)",point.x,point.y,point.z) }
如果想要按照某种方式来遍历,如按键序,则可以:
package main import( "fmt" "sort" ) func main(){ populationForCity := map[string]int{"beijing":12330000,"shanghai":11002002,"guangzhou":14559400} cities := make([]string,0,len(populationForCity)) for city := range populationForCity{ cities = append(cities,city) } sort.Strings(cities) for _,city := range cities{ fmt.Printf("%-10s %8d\n", city, populationForCity[city]) } }
该方法就是创建一个足够大的切片去保存映射里的所有键,然后对切片排序,遍历切片得到键,再从映射里得到这个键的值,然后就可以实现键顺序输出了
另一种方法就是:使用一个有序的数据结构,这个之后讲
上面是按键排序,按值排序当然也是可以的——映射反转
前提:映射的值都是唯一的,如:
package main import( "fmt" ) func main(){ populationForCity := map[string]int{"beijing":12330000,"shanghai":11002002,"guangzhou":14559400} cityForPopulation := make(map[int]string,len(populationForCity)) //与上面的populationForCity键值类型相反 for city, population := range populationForCity{ cityForPopulation[population] = city } fmt.Println(cityForPopulation) //map[14559400:guangzhou 12330000:beijing 11002002:shanghai] }
即创建一个与populationForCity键值类型相反的cityForPopulation,然后遍历populationForCity,并将得到的键值反转,然后插到cityForPopulation中即可
返回:
userdeMBP:go-learning user$ go run test.go beijing 12330000 guangzhou 14559400 shanghai 11002002
31.++(递增)\--(递减)操作符
这两个操作符都是后置操作符,并且没有返回值。因此该操作符不能用于表达式和语意不明的上下文。所以i = i++这样的代码是错误的
32.类型断言
一个interface{}的值可以用于表示任意Go类型的值。
我们可以使用类型开关、类型断言或者Go语言的reflect包的类型检查将一个interface{}类型的值转换成实际数据的值
在处理从外部源接收到的数据、想创建一个通用函数及在进行面向对象编程时,我们会需要使用interface{}类型(或自定义接口类型),因为你不知道接收的是什么类型的数据
为了访问底层值,我们需要进行类型断言来确定得到的数据的类型,类型断言的格式为:
resultOfType, boolean := expression.(Type) //安全断言类型 resultOfType := expression.(Type) //非安全断言类型,如果断言失败,则调用内置函数panic()
resultOfType返回的是expression的该Type类型的值,如下面的例子,i.(int)返回的j的值为99
举例说明:
package main import "fmt" func main(){ var i interface{} = 99 var s interface{} = []string{"left","right"} j := i.(int) //j是int类型的数据,或者失败发生了一个panic() // b := i.(bool) //b是bool类型的数据,或者失败发生了一个panic() fmt.Printf("%T -> %d\n", j, j) // fmt.Println(b) if i, ok := i.(int); ok { fmt.Printf("%T -> %d\n", i, i) } if s, ok := s.([]string); ok { fmt.Printf("%T -> %q\n", s, s) } }
返回:
userdeMBP:go-learning user$ go run test.go int -> 99 int -> 99 []string -> ["left" "right"]
如果删除上面的注释:
// b := i.(bool) //b是bool类型的数据,或者失败发生了一个panic() // fmt.Println(b)
将会调用panic()返回:
userdeMBP:go-learning user$ go run test.go panic: interface conversion: interface {} is int, not bool goroutine 1 [running]: main.main() /Users/user/go-learning/test.go:8 +0xe0 exit status 2
在例子中有i, ok := i.(int),在做类型断言的时候将结果赋值给与原始变量同名的变量是很常见的事,这叫做使用影子变量
⚠️只有在我们希望表达式是某种特定类型的值时才使用类型断言(如果目标类型可能是很多类型之一,我们可以使用类型开关)
如果我们输出上面例子的i和s变量,它们可以以int和[]string类型的形式输出。这是因为当fmt包打印函数遇到interface{}类型时,会足够智能地打印实际类型的值
33.类型开关

举例:
1)
package main import "fmt" func main() { classifier(5, -17.9, "ZIP", nil, true, complex(1,1)) } func classifier(items ...interface{}){//...声明这是一个可变参数 for i, x := range items{ switch x.(type){//type为关键字而非一个实际类型,用于表示任意类型 case bool: fmt.Printf("param #%d is a bool\n", i) case float64: fmt.Printf("param #%d is a float64\n", i) case int, int8, int16, int32, int64: fmt.Printf("param #%d is a int\n", i) case uint, uint8, uint16, uint32, uint64: fmt.Printf("param #%d is a unsigned int\n", i) case nil: fmt.Printf("param #%d is a nil\n", i) case string: fmt.Printf("param #%d is a string\n", i) default : fmt.Printf("param #%d's type is unknow\n", i) } } }
返回:
userdeMBP:go-learning user$ go run test.go param #0 is a int param #1 is a float64 param #2 is a string param #3 is a nil param #4 is a bool param #5's type is unknow
2)处理外部数据
想要解析JSON格式的数据,将数据转换成相对应的Go语言数据类型
使用go语言的json.Unmarshal()函数:
func Unmarshal(data []byte, v interface{}) error
解析json编码的数据并将结果存入v指向的值,即将JSON格式的字符串转成JSON
要将json数据解码写入一个接口类型值,函数会将数据解码为如下类型写入接口:
Bool 对应JSON布尔类型 float64 对应JSON数字类型 string 对应JSON字符串类型 []interface{} 对应JSON数组 map[string]interface{} 对应JSON对象 nil 对应JSON的null
如果我们向该函数传入一个指向结构体的指针,该结构体又与该JSON数据相匹配(前提是你事先知道JSON的数据结构),那么该函数就会将JSON数据中对应的数据项填充到结构体的每一个字段,看下面的2.例子
但是如果我们事先不知道JSON数据的结构,那么就不能传入一个结构体,而是应该传入一个指向interface{}的指针,这样json.Unmarshal()函数就会将其设置为引用一个map[string]interface{}类型值,其键为JSON字段的名字,而值则对应的保存为interface{}的值,下面举例说明:
1.
package main import( "fmt" "encoding/json" "bytes" ) func main(){ MA := []byte("{\"name\":\"beijing\", \"area\":27000, \"water\":25.7, \"senators\":[\"John\", \"Scott\"]}") var object interface{} if err :=json.Unmarshal(MA, &object); err != nil{ fmt.Println(err) }else{ jsonObject := object.(map[string]interface{})
fmt.Println(jsonObject)//map[name:beijing area:27000 water:25.7 senators:[John Scott]] fmt.Println(jsonObjectAsString(jsonObject)) } } func jsonObjectAsString(jsonObject map[string]interface{})string{ var buffer bytes.Buffer buffer.WriteString("{") comma := "" for key, value := range jsonObject{ buffer.WriteString(comma) switch value := value.(type){ //影子变量 case nil: fmt.Fprintf(&buffer, "%q: null", key) case bool: fmt.Fprintf(&buffer, "%q: %t", key, value) case float64: fmt.Fprintf(&buffer, "%q: %f", key, value) case string: fmt.Fprintf(&buffer, "%q: %q", key, value) case []interface{}: fmt.Fprintf(&buffer, "%q: [", key) innerComma := "" for _, s := range value{ if s, ok := s.(string); ok{ //因为本例子中该类型的值为string类型 fmt.Fprintf(&buffer, "%s%q", innerComma, s) innerComma = ", " } } buffer.WriteString("]") } comma = ", " } buffer.WriteString("}") return buffer.String() }
如果反序列化失败,即json.Unmarshal返回的err != nil,那么interface{}类型的object变量就会指向一个map[string]interface{}类型的变量,其键为JSON对象中字段的名字
jsonObjectAsString()函数接收一个该类型的映射,同时返回一个对应的JSON字符串
fmt.Fprintf()函数将数据写入到其第一个io.Writer类型的参数。虽然bytes.Buffer不是io.Writer,但*bytes.Buffer却是一个io.Writer,因此在上面的例子中传入了buffer的地址,及&buffer
返回:
userdeMBP:go-learning user$ go run test.go {"name": "beijing", "area": 27000.000000, "water": 25.700000, "senators": ["John", "Scott"]}
中间遇见的问题:
userdeMBP:go-learning user$ go run test.go # command-line-arguments ./test.go:8:14: cannot convert '\u0000' (type rune) to type []byte ./test.go:8:15: invalid character literal (more than one character)
这是因为之前MA是这么写的:
MA := []byte('{"name":"beijing", "area":27000, "water":25.7, "senators":["John", "Scott"]}')
但是单引用会被当作rune类型,所以要使用双引号,而且也不能把里面的键值对的双引号该成单引号,否则会报下面的错误:
invalid character '\'' looking for beginning of object key string
或者也可以写成:
MA := []byte(`{"name":"beijing", "area":27000, "water":25.7, "senators":["John", "Scott"]}`)
如果输入的字符串中只是一个float64的数字,效果如下:
package main import( "fmt" "encoding/json" "bytes" ) func main(){ MA := []byte("62") var object interface{} if err :=json.Unmarshal(MA, &object); err != nil{ fmt.Println(err) }else{ object := object.(float64) fmt.Println(object) //返回62 }
2.如果事先知道原始JSON对象的结构,那么我们就能够很大程度地简化代码
可以使用一个结构体来保存数据,然后使用一个方法以字符串的形式将其输出,举例说明:
package main import( "fmt" "encoding/json" // "strings" ) func main(){ MA := []byte(`{"name":"beijing", "area":27000, "water":25.7, "senators":["John", "Scott"]}`) var state State if err := json.Unmarshal(MA, &state); err != nil{ fmt.Println(err) } fmt.Println(state) //返回{"name": "beijing", "area": 27000, "water": 25.700000,"senators": ["John", "Scott"]} } type State struct{ Name string Senators []string Water float64 Area int } func (state State) String() string { var senators []string for _, senator := range state.Senators{ senators = append(senators, fmt.Sprintf("%q", senator)) } return fmt.Sprintf( `{"name": %q, "area": %d, "water": %f,"senators": [%s]}`, state.Name, state.Area, state.Water, strings.Join(senators,", ")) }
如果没有自定义String()的话,返回的结果为:
{beijing [John Scott] 25.7 27000}
34.for循环
使用break跳出双层循环的两种方法:
假设有一个二维切片(类型为[][]int),想从中搜索看看是否包含某个特定的值
1)
package main import( "fmt" ) func main() { table := [][]int{{1,2}, {3,4}, {5}} x := 4 found := false for row := range table { for column := range table[row] { if table[row][column] == x{ fmt.Println(row, column)//1 1 found = true break } } if found{ break } } }
2)带标签的中断语句,嵌套越深,其效果越好
package main import( "fmt" ) func main() { table := [][]int{{1,2}, {3,4}, {5}} x := 4 FOUND: for row := range table { for column := range table[row] { if table[row][column] == x{ fmt.Println(row, column)//1 1 break FOUND } } } }
break、continue语句后都可以接标签
除此之外还可以使用goto label语法,但是并不推荐使用goto语法,可能造成程序崩溃
35.通信和并发

并发goroutine的go语句创建:
go function(arguments) //之前已有函数 go func(parameters){ block }(arguments) //临时创建的匿名函数
临时调用函数中(parameters)是声明该函数的参数类型,(arguments)是调用该匿名函数传入的参数,即匿名函数声明完后立即调用
被调用函数的执行会立即进行,但是是在另一个goroutine上实行,当前goroutine的执行会从下一条语句开始
大多数情况下,goroutine之间需要相互协作,这通过通信来完成

非阻塞的发送可以使用select语句,或使用带缓冲的通道
通道可以使用内置的make()函数创建:
make(chan Type)
make(chan Type, capacity)
如果没有声明capacity,该通道就是同步的,因此会阻塞直到发送者准备好发送和接受者准备好接受
如果声明了capacity,通道就是异步的.只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么通信就会无阻塞地进行
通道默认是双向的,如果有需要可以将其设置为单向的
举例:
package main import( "fmt" ) func main() { counterA := createCounter(2) counterB := createCounter(102) //这两个函数中的goroutine会阻塞并得到返回的next通道,等待接收通道中数据的请求 for i := 0; i<5 ; i++{ a := <-counterA b := <-counterB //这两句就是对通道数据的请求 fmt.Printf("(A->%d, B->%d)", a, b) } fmt.Println() } func createCounter(start int) chan int{ next :=make(chan int) go func(i int){ //无限循环 for{ next <- i i++ } }(start) //会生成另一个goroutine,因为next没有声明capacity,所以此时会阻塞,直到收到接受请求 return next //上面的goroutine并发时,createCounter()函数会继续往下执行,返回next }
返回:
userdeMBP:go-learning user$ go run test.go (A->2, B->102)(A->3, B->103)(A->4, B->104)(A->5, B->105)(A->6, B->106)
上面生成的两个counterA、counterB通道是无限的,即它们可以无限地发送数据。当然,如果我们达到了int型数据的极限,下一个值就会从头开始
一旦想要接收的五个值都从通道中接收完成,通道将继续阻塞以备后续使用
如果有多个goroutine并发执行,每一个goroutine都有其自身通道。可以使用select语句来监控它们的通信

在一个select语句中,Go语言会按顺序从头到尾评估每一个发送和接收语句。如果其中任意一语句可以继续执行(即没有阻塞),那么就从那些可以执行的语句中任意选择一条来使用。
如果没有一条语句可以执行,那么就会执行default语句,同时程序的执行会从select语句后的语句中恢复
一个包含default语句的select语句是非阻塞的,并且会立即执行。但是如果没有default语句,那么select语句将被阻塞,直到至少有一个通信可以继续进行下去
举例说明:
package main import( "fmt" "math/rand" ) func main() { channels := make([]chan bool, 6) //创建了6个用于发送和接收布尔数据的通道 for i := range channels { channels[i] = make(chan bool) } go func(){ for{ //无限循环,每次迭代都选择从随机生成的[0-6)的值中获得的相应的通道,然后会阻塞,直至接收到数据 channels[rand.Intn(6)] <- true } }() for i:=0; i<36; i++{ var x int select { case <-channels[0]: x = 1 case <-channels[1]: x = 2 case <-channels[2]: x = 3 case <-channels[3]: x = 4 case <-channels[4]: x = 5 case <-channels[5]: x = 6 } fmt.Printf("%d", x) } fmt.Println() }
因为我们没有提供default语句,所以该select语句会阻塞。一旦有一个或者更多个通道准备好了发送数据,那么程序会以伪随机的形式选择一个case语句来执行
由于该select语句在一个普通的for循环内部,它会执行固定数量的次数
返回:
userdeMBP:go-learning user$ go run test.go 646621235132165346636135422514216643
36.defer、panic、recover
1)defer
defer语句用于延迟一个函数或者方法(或者当前所创建的匿名函数)的执行,他会在外围函数或方法返回之前,但是在该返回值(如果有的话)已经计算出来之后执行,这样就有可能在延迟执行的函数或方法中改变返回值
如果一个函数或方法中有多个defer语句,它们会以LIFO(后进先出)的顺序执行
defer最常用的用法是:保证使用完一个文件后将其成功关闭,或者将一个不再使用的通道关闭,或者捕获异常
2)panic()\recover()
这是go提供的一套异常处理机制
go中将错误和异常区别对待:
- 错误是可能出错的东西,例如文件不能打开
- 异常是指“不可能发生”的事情(如一个应该永远为true的条件在实际环境下是false的)
错误的惯用方法是将错误以函数或者方法最后一个返回值的形式将其返回,并在调用它的地方检查返回的错误值
result, err := function() if err != nil { ... }
对于异常则可以调用内置的panic()函数,该函数可以传入任意想要传入的值(例如:一个字符串用于解释为什么那些不变的东西被破坏了)。当内置的panic()函数被调用时,其外围的函数或方法的执行就会立即终止。
然后该外围函数或方法的defer的函数或方法就会被调用。然后就会层层向上递归,就像该外围函数的外围函数也调用了panic()函数一样,直至到达main()函数,不再有其他可以返回的外围函数,然后此时程序就会终止,并将包含传入原始panic()函数中的值的调用栈信息输入到os.Stderr中
如果在上面的过程中的某个defer的函数和方法中包含一个对内置的recover()函数,该异常的展开就会终止。这种情况下,我们就能以任何我们想要的方式响应该异常。
解决方法是完成必要的清理工作,然后手动调用panic()函数来让该异常继续传播
通用的解决办法是创建一个error值,并将其设置成包含recover()调用函数的返回值(或返回值之一)这样就可以将一个异常(即一个panic())转换成错误(即一个error)
绝大多数情况下,go语言标准库使用 error值而非异常。对于我们自己定义的包,最好别使用panic()。或者是如果要使用panic(),也要避免异常离开这个自定义包边界(意思就是不要更上面说的一样层层向上递归),可以通过使用recover()来捕捉异常并返回一个相应的错误值,就像标准库中所做的那样
对于那些只需要通过执行程序(比如你传入的是一个非法的正则表达式)就能够捕捉到的问题,我们应该使用panic(),因为一运行就崩溃的程序我们是不会部署的。要⚠️,只有在程序运行时一定会被调用到的函数中才这样做,比如main包中的main()函数、init()函数等。
对于可能运行也可能不运行的函数或方法,如果调用了panic()函数或者调用了会发生异常的函数或方法,应该使用recover()以保证异常转换成错误
一般recover()函数应该在尽可能接近于相应panic()的地方被调用,并在设置其外围函数的error返回值之前尽可能合理地将程序恢复到健康状态
对于main包的main()函数,我们可以放入一个可以捕获一切异常的recover()函数,用于记录任何捕获的异常。但不幸的是,延迟执行的recover()函数被调用后程序会终止
⚠️recover仅在defer函数中有效,如果将其放在正常的执行过程中,调用recover()会返回nil,并没有其他任何效果。如果当前的goroutine陷入Panic,调用recover可以捕获Panic的输入值,并恢复正常的执行
举例:
1>演示如何将异常转成错误
1)
package main import( "fmt" "math" ) func main() { var t int64 = 2147483648 fmt.Println(math.MinInt32) //-2147483648 fmt.Println(math.MaxInt32) //2147483647 result := CovertInt64ToInt(t) fmt.Println(result) } func CovertInt64ToInt(x int64) int { if math.MinInt32 <= x && x <= math.MaxInt32{ return int(x) } panic(fmt.Sprintf("%d is out of the int32 range", x)) }
返回:
bogon:~ user$ go run testGo.go -2147483648 2147483647 panic: 2147483648 is out of the int32 range goroutine 1 [running]: main.CovertInt64ToInt(0x80000000, 0x1) /Users/user/testGo.go:17 +0xf3 main.main() /Users/user/testGo.go:10 +0xaf exit status 2
为什么这样的函数优先使用panic(),因为我们希望一旦有错就强制崩溃,以便尽早弄清楚程序错误
上面显示的就是没有使用recover时,就会报错,并且层层向上递推指明错误所在
下面就是显示当使用了recover后
2)
一种情况是:
有一个函数调用了一个或多个其他函数,一旦出错我们希望尽快返回到原始调用函数,因此我们让被调用的函数碰到问题时抛出异常,并在调用处使用recover()捕获该异常(无论该异常来自哪里)
一般我们希望包报告错误而非抛出异常,因此常用的做法是在一个包内部使用panic(),同时使用recover()来保证产生的异常不会泄露出去,而只是报告错误
另一种情况是:
将类似panic("unreachable")这样的调用放在一个我们从逻辑上判断不可能到达的地方(例如函数的末尾,但是该函数总是会在到达末尾前通过return语句返回),或者在一个前置或者后置条件被破坏时才调用panic()函数。
这样可以保证如果我们破坏了函数的逻辑,立马就能够知道
3)如果上面的情况都不满足,那么在问题发生时应该避免崩溃,而只是返回一个非空的error值
因此本例子希望如果转换成功就返回一个int型和一个nil;如果失败则返回一个int型和一个非空的错误值
package main import( "fmt" "math" ) func main() { var t int64 = 2147483648 fmt.Println(math.MinInt32) //-2147483648 fmt.Println(math.MaxInt32) //2147483647 result, err := IntFromInt64(t) fmt.Println(result) //0 fmt.Println(err) //2147483648 is out of the int32 range } func IntFromInt64(x int64) (i int, err error){ defer func(){//终止panic,使得函数能够继续执行 if e := recover();e != nil{//获取panic中输入的值e,覆盖err的nil值 err = fmt.Errorf("%v", e) } }() i = CovertInt64ToInt(x) //如果抛出异常,会停止函数接下去执行,然后计算得到return的返回值后,直接调用上面的defer函数,得到error,覆盖之前计算的return的nil值,然后才运行return return i, nil //i为初始值0 } func CovertInt64ToInt(x int64) int { if math.MinInt32 <= x && x <= math.MaxInt32{ return int(x) } panic(fmt.Sprintf("%d is out of the int32 range", x)) }
返回:
userdeMBP:go-learning user$ go run test.go -2147483648 2147483647 0 2147483648 is out of the int32 range
2>展示如何让程序变得健壮
在运行网站时我们希望即使出现异常服务器也能继续运行,同时将任何异常都以日志的形式记录下来,以便我们进行跟踪并在有时间的时间将其修复
代码之后回公司在弄188页
必须保证每一个页面相应函数都有一个调用recover()的匿名函数,以免异常传播到main()函数,导致服务器的终止。
当然,对于一个含有大量页面处理函数的网站,添加一个延迟执行的函数来捕获和记录异常回产生大量重复的代码,并容易遗漏。因此我们应该将每个页面处理函数都需要的代码包装成一个函数来解决这个问题
37.可变参数
其实就是在参数的类型前面写上省略号...
38.自定义函数
如果函数有返回值,则函数必须至少有一个return语句或者最后执行panic()调用
如果返回值是命名的,则return语句可以向没有命名的返回值一样的写法,或者是写一个空的return语句,但是一般不建议写空的return,这种写法太拙劣
如果函数是以抛出异常结束的,go编译器会认为这个函数不需要正常返回,所以不需要return
如果是以if或switch语句结束,且if语句的else分支以return语句结尾或switch的default以return语句结尾,那么无法确定后面需不需要return语句。解决方法是要么不给其添加else语句和default分支,要么将return语句放到if或者switch后面,或者在最后简单地加上一句panic("unreachable")语句
39.函数参数
1)
如果想要传递任何类型的数据,可以将参数的类型定义为interface{}
2)将函数调用作为函数的参数
其实就是将这个调用的函数的返回值作为这个函数的参数,只要两者匹配即可
3)可变参数
其实就是函数的最后一个参数的类型前面添加...
4)可选参数——即增加一个额外结构体
比如说我们有一个函数用来处理一些自定义的数据,默认就是简单地处理所有的数据,但有些时候我们希望可以指定处理第一个first或者最后一个项last,还有是否记录函数的行为,或者对于非法的项做错误处理等
1>一个办法是创建一个签名如下的函数:
ProcessItems(items Items, first, last int, audit bool, errorHandler func(item Item))
如果last的值为0意味着需要取到最后一个item
errorHandler函数只有在不为nil的时候才会被调用
所以说,如果调用该函数时希望是默认行为,只需要写ProcessItems(items, 0, 0, false, nil)即可
2>更好的办法是定义函数为:
ProcessItems(items Items, options Options)
其中Options结构体保存了所有其他参数的值,初始化均为零值,即默认行为
Options结构体的定义:
type Options struct{ First int //要处理的第一项 Last int //要处理的最后一项,0则默认处理从指定的第一项到最后一项 Audit bool //true则左右动作都要被记录 ErrorHandler func(item Item) //如果不是nil,对每一个坏项都用一次 }
使用:
//默认行为,处理所有项,不记录任何动作,对于非法的记录也不调用错误处理函数来处理 processItems(items, Options{}) errorHandler := func(item Item){ log.Println("Invalid: ", item)} //要记录行为,并且在发现非法的项时要做一些相应的处理 processItems(items, Options{Audit: true, ErrorHandler: errorHandler})
40.init()函数、 main()函数
init()函数可以出现在任何包中,一个包中可以有多个init,但是推荐只使用一个,可选
main()函数只能出现在main包中,必有
这两个函数即不可接收任何参数,可不返回任何结果,会自动执行,不需要显示调用
go程序的初始化和执行都从main包开始,init()函数就在main()函数前执行,所以init()中不应该依赖main()中创建的东西

41.运行时动态选择函数
1)使用映射和函数引用来制造分支
比如如果我们想要根据不同的输入去实现不同的操作,以前的方法是使用if或switch,但是这种方法十分死板,如果情况比较复杂是代码会过长
这个时候的一种解决办法是使用映射,比如想要根据输入文件的后缀名来决定调用的函数:
var FunctionForSuffix = map[string]func(string) ([]string, error){ ".gz": GzipFileList, ".tar": TarFileList, ".tar.gz": TarFileList, ".tgz": TarFileList, ".zip": ZipFileList} func ArchiveFileListMap(file string) ([]string, error){ if function, ok := FunctionForSuffix[Suffix(file)]; ok { return function(file) } return nil, errors.New("Unrecognized archive") }
2)动态函数的创建
当我们有两个或者更多的函数实现了相同功能时,比如使用了不同的算法,我们不希望在程序编译时静态绑定到其中任一个函数(例如允许我们动态地选择他们来做性能测试或回归测试)
举个例子,如果我们使用一个7位的ASCII字符,我们可以写一个更加简单的IsPalicdrome()函数,而在运行时动态地创建一个我们所需要的版本
一种做法就是声明一个和这个函数签名相同的包级别的变量IsPalindrome,然后创建一个appropriate()函数和一个init()函数:
var IsPalindrome func(string) bool //是否是回文字符串的声明 func init() { if len(os.Args) > 1 && (os.Args[1] == "-a" || os.Args[1] == "--ascii"){ os.Args = append(os.Args[:1], os.Args[2:]...) //去掉参数os.Args[1] IsPalindrome = func(s string) bool { //简单的ASCII版本 if len(s) <= 1 { return true } if s[0] != s[len(s) - 1] { return false } return IsPalindrome(s[1 : len(s) - 1]) }else { IsPalindrome = func(s string) bool {//UTF-8版本 //... } }
什么代码会被执行完全取决于我们创建的事哪个版本的函数
42.泛型函数
根据传入的参数来确定参数的类型,而不是一开始就指定参数类型,这样一个函数就可以支持所有类型
方法其实就是将参数声明为interface{}类型,比如:
func Minimum(first interface{}, rest ...interface{}) interface{} { //... }
但有一个问题:上面的泛型函数处理不了实际类型为切片的interface{}参数
举例说明:
1)
比如,传入一个切片和与切片的项类型相同的值,返回这个值在切片里第一次出现的索引,如果不存在就返回-1:
package main import( "fmt" ) func main() { xs := []int{2, 4, 6, 8} fmt.Println(" 5 @", Index(xs, 5), " 6 @", Index(xs, 6)) ys := []string{"C", "B", "K", "A"} fmt.Println(" Z @", Index(ys, "z"), " A @", Index(ys, "A")) } func Index(xs interface{}, x interface{}) int { switch slice := xs.(type) { case []int: for i,y := range slice{ if y == x.(int){ return i } } case []string: for i, y := range slice{ if y == x.(string) { return i } } } return -1 }
返回:
users-MacBook-Pro:~ user$ go run testGo.go 5 @ -1 6 @ 2 Z @ -1 A @ 3
我们真正想做的是希望能够有通用的方式对待切片,可以仅用一个循环,然后在里面用特定类型测试:
package main import( "fmt" "reflect" ) func main() { xs := []int{2, 4, 6, 8} fmt.Println(" 5 @", IndexReflectX(xs, 5), " 6 @", IndexReflectX(xs, 6)) ys := []string{"C", "B", "K", "A"} fmt.Println(" Z @", IndexReflectX(ys, "z"), " A @", IndexReflectX(ys, "A")) } func IndexReflectX(xs interface{}, x interface{}) int { if slice := reflect.ValueOf(xs); slice.Kind() == reflect.Slice { for i := 0; i < slice.Len(); i++ { switch y := slice.Index(i).Interface().(type){ case int: if y == x.(int){ return i } case string: if y == x.(string){ return i } } } } return -1 }
跟上面的Index()的返回时一样的
ValueOf()返回一个初始化为xs接口保管的具体值的Value,ValueOf(nil)返回Value零值
reflect.ValueOf(xs)的作用是将传入的任意类型的参数xs转换成一个切片类型reflect.Value
type Value struct { // 内含隐藏或非导出字段 }
然后使用reflect.Value.Interface()函数将其值以interface{}类型提取出来,然后赋值给y,用以保证y和切片里的项有着相同的类型
Kind()返回reflect.Value持有的值的分类,查看是不是切片类型reflect.Slice
Index()返回v持有值的第i个元素。如果v的Kind不是Array、Chan、Slice、String,或者i出界,会panic
Interface()返回reflect.Value当前持有的值(表示为/保管在interface{}类型),因为传进来的值也是赋值给interface{}类型的参数x
简化版本:
package main import( "fmt" "reflect" ) func main() { xs := []int{2, 4, 6, 8} fmt.Println(" 5 @", IndexReflectX(xs, 5), " 6 @", IndexReflectX(xs, 6)) ys := []string{"C", "B", "K", "A"} fmt.Println(" Z @", IndexReflectX(ys, "z"), " A @", IndexReflectX(ys, "A")) } func IndexReflectX(xs interface{}, x interface{}) int { if slice := reflect.ValueOf(xs); slice.Kind() == reflect.Slice { for i := 0; i < slice.Len(); i++ { if reflect.DeepEqual(x, slice.Index(i)) { return i } } } return -1 }
func DeepEqual(a1, a2 interface{}) bool:用来判断两个值是否深度一致
然后我们从返回中可以看出,使用深度对比,则找不到相应的值:
users-MacBook-Pro:~ user$ go run testGo.go 5 @ -1 6 @ -1 Z @ -1 A @ -1
2)
目的:在一个切片中查找某一项的索引
非泛型函数写法:
func IntSliceIndex(xs []int, x int) int { for i, y := range xs { if x ==y { return i } } return -1 }
使用自定义函数将泛型函数的好处(即仅需实现一次算法)和类型特定函数的简便性和高效率结合
如果想要改成string类型,则更改:
type StringSlice []string func (slice StringSlice) EqualTo(i int, x interface{}) bool{ return slice[i] == x.(string) } func (slice StringSlice) Len() int {return len(slice)}
因此当我们使用切片或映射时,通常可以创建泛型函数,这样就不用使用类型测试和类型断言
或者将我们的泛型函数写成高阶函数,对所有特定的类型相关逻辑进行抽象
43.高阶函数
即将一个或者多个函数作为自己的参数,并在函数体中调用它们
44.纯记忆函数
纯函数即对于同一组输入总是产生相同的结果,无副作用
如果一个纯函数执行时开销很大而且频繁地使用相同的参数进行调用,我们可以使用记忆功能来降低处理的开销
记忆技术就是保存计算的结果,当执行下一个相同的计算时,我们能够返回保存的结果而不是重复执行一次计算过程
比如使用递归来计算斐波那契数列的开销是很大的,而且重复计算相同的过程
解决办法就是使用一个非递归的算法
1)首先先创建一个使用递归的具有记忆功能的斐波那契函数
package main import( "fmt" ) func main() { fmt.Println("Fibonacci(45) = ", Fibonacci(45).(int)) //1 } type memorizeFunction func(int, ...int) interface{} var Fibonacci memorizeFunction //声明一个Fibonacci变量来保存这个类型的函数 func init(){ Fibonacci = Memorize(func(x int, xs ...int) interface{} {//Memorize可以记忆任何传入至少一个int参数并返回一个interface{}的函数 if x < 2 { return x } return Fibonacci(x - 1).(int) + Fibonacci(x - 2).(int) //4... }) } func Memorize(function memorizeFunction) memorizeFunction{ cache := make(map[string]interface{}) return func(x int, xs ...int) interface{} { //2 key := fmt.Sprint(x) for _, i := range xs { key += fmt.Sprintf(",%d", i) }
if value, found := cache[key]; found { return value } value := function(x, xs...) //3 cache[key] = value return value } }
使用映射结构cache来保存预先计算的结果,映射的键是将所有的整数参数组合并用逗号分隔的字符串(⚠️go语言的映射要求键必须完全支持==和!=操作,字符串符合,切片不可以)
键key准备好后去查看映射里是否有对应的“键-值对”cache[key],如果有就直接返回缓存结果value;否则我们就执行传入的参数function函数,再将结果缓存到映射中
45.面向对象编程
go的面向对象与c++、Java、python最大的不同就在于其不支持继承,只支持聚合(也叫组合)和嵌入
聚合和嵌入的区别:
type ColoredPoint struct{//其字段可以通过point.Color、point.x、point.y来访问 color.Color //匿名字段,因为其没有变量名(嵌入),来自image/color包类型 x, y int //具名字段(聚合) } //创建point := ColoredPoint{} //其字段可以通过point.Color、point.x、point.y来访问 //注意当访问来自其他包中的类型的字段时,只用到了其名字的最后一部分,如上面是Color,而不是color.Color
go语言与众不同之处在于它的接口、值和方法之间都保持独立。接口用于声明方法签名,结构体用于声明聚合或嵌入的值,方法用于声明在自定义类型(通常为结构体)上的操作
自定义类型的方法和任何特殊接口之间没有显示的联系;但是如果该类型的方法满足一个或者多个接口,那么该类型的值可以用于任何接受该接口的值的地方
其实每一种类型都满足空接口(interface{}),因此任何值都可以用于声明了空接口的地方
声明为匿名字段的好处是:
比如:
package main import( "fmt" ) type Human struct{ name string age int weight int } type Student struct{ Human speciality string } func main() { mark := Student{ Human{"Mark", 25, 120}, "computer"} //获取相应的信息 fmt.Println("his name is: ", mark.name) fmt.Println("His age is: ", mark.age) fmt.Println("His weight is: ", mark.weight) fmt.Println("His speciality is: ", mark.speciality) //修改专业 mark.speciality = "AI" fmt.Println("His changed speciality is: ", mark.speciality) //修改年龄 mark.age = 46 fmt.Println("His changesd age is: ", mark.age) //修改体重 mark.weight += 60 fmt.Println("His changed weight is: ", mark.weight) }
可见,定义为匿名函数,当你想要访问Human中的值的时候,可以简单地使用mark.age来访问
当然,如果参数有重名的,默认会先访问外面的重名值。
如果你想要访问里面的重名值,你可以使用Human作为字段名,使用mark.Human.age来指明你访问的是重名中的那个值
46.自定义类型
语法:
type typeName typeSpecification
typeName可以是一个包或者函数内唯一的任何合法的go标识符
typeSpecification可以是任何内置的类型(如string、int、切片、通道)、一个接口、一个结构体或者一个函数签名,举例:
type Count int type StringMap map[string]string type FloatChan chan float64
这样的自定义类型提升了程序的可读性,也可以在后面改变其底层类型。但是其实并没有什么用,所以一般都只把其当作基本的抽象机制
package main import( "fmt" ) func main() { var i Count = 7 i++ fmt.Println(i) sm := make(StringMap) sm["key1"] = "value1" sm["key2"] = "value2" fmt.Println(sm) fc := make(FloatChan, 1) fc <- 2.299999 fmt.Println(<-fc) } type Count int type StringMap map[string]string type FloatChan chan float64
返回:
userdeMBP:go-learning user$ go run test.go 8 map[key1:value1 key2:value2] 2.299999
向上面的Count、StringMap和FloatChan都是直接基于内置类型创建的,因此可以当作内置类型来使用
因此StringMap也可以调用内置函数append()
但是如果要将其传递给一个接受其底层类型的函数,就必须先将其转换成底层类型(无需成本,因为这是在编译是完成的)
有时我们可能需要将一个内置类型的值升级成一个自定义类型的值,以使用其自定义类型的方法
47.自定义方法
定义方法的语法几乎等同于定义函数,除了需要在func关键字和方法名之间需要写上接受者,接受者的类型总是一个该类型的值,或者该类型值的指针
1)重写方法
package main import( "fmt" ) func main() { special := SpecialItem{Item{"Green", 3, 5}, 207} fmt.Println(special.id, special.price, special.quantity, special.catalogId) fmt.Println(special.Cost()) } type Item struct{ id string //具名字段(聚合) price float64 quantity int } func (item *Item) Cost() float64{ return item.price * float64(item.quantity) } type SpecialItem struct{ Item //匿名字段(嵌入) catalogId int }
返回:
userdeMBP:go-learning user$ go run test.go Green 3 5 207 15
因此我们可以在SpecialItem上调用Item的Cost()方法,即SpecialItem.Cost(),传入的是嵌入的Item值,而非整个调用该方法的SpecialItem
当然,如果Item中有字段和SpecialItem字段同名,比如都有price,那么要调用Item的就使用special.Item.price
当然,我们也可以声明一个Cost()函数来覆盖Item的Cost()函数,有三种写法:
func (item *LuxuryItem) Cost() float64{ //太冗长
return item.Item.Price * float64(item.Item.quantity) * item.makeup
}
func (item *LuxuryItem) Cost() float64{ //没必要重复
return item.price * float64(item.quantity) * item.makeup
}
func (item *LuxuryItem) Cost() float64{ //完美
return item.Item.Cost() * item.makeup
}
整体代码:
package main import( "fmt" ) func main() { luxury := LuxuryItem{Item{"Green", 3, 5}, 20} fmt.Println(luxury.id, luxury.price, luxury.quantity, luxury.makeup) fmt.Println(luxury.Cost()) } type Item struct{ id string //具名字段(聚合) price float64 quantity int } func (item *Item) Cost() float64{ return item.price * float64(item.quantity) } type LuxuryItem struct{ Item //匿名字段(嵌入) makeup float64 } func (item *LuxuryItem) Cost() float64{ //完美 return item.Item.Cost() * item.makeup }
返回:
userdeMBP:go-learning user$ go run test.go Green 3 5 20 300
2)方法表达式
就像对函数进行赋值和传递一样,也可以对方法进行赋值和传递
⚠️方法表达式是一个必须将方法类型作为第一个参数的函数
var part Part asStringV := Part.String //声明asStringV的有效签名为func(Part) string sv := asStringV(part) //将类型为Part的part作为第一个参数 hasPrefix := Part.HasPrefix //声明hasPrefix的有效签名为func (Part, string) bool asStringP := (* Part).String //声明asStringP的有效签名为func (*Part) string sp := asStringP(&part) lower := (*Part).LowerCase //声明lower的有效签名为func(* Part) lower(&part) fmt.Println(sv, sp, hasPrefix(part, "w"), part)
以上的自定义类型都有一个潜在的致命错误,都没有对自定义类型进行限制,Part.Id等字段可以被设置为任何想要设置的值,所以要进行下面的验证
3)验证类型
package main import( "fmt" ) type Place struct{ latitude, longitude float64 //需要验证 Name string } //saneAngle()函数:接受一个旧的角度值和一个新的角度值,如果新值在其范围内则返回新值 func New(latitude, longitude float64, name string) *Place{//保证总是能够创建一个合法的*place.Place,go惯例调用New()构造函数 return &Place{saneAngle(0, latitude), saneAngle{0, longitude}, name} } func (place *Place) Latitude() float64 { return place.latitude} func (place *Place) SetLatitude(latitude float64){ place.latitude = saneAngle(place.latitude, latitude) } func (place *Place) Longitude() float64 { return place.longitude} func (place *Place) SetLongitude(longitude float64){ place.longitude = saneAngle(place.longitude, longitude) } func (place *Place) String() string { return fmt.Sprintf("(%.3f, %.3f)%q", place.latitude, place.longitude, place.name) }
48.接口嵌入
即在某个接口中嵌入其他接口
type LowerCaser interface{ LowerCase() } type UpperCaser interface{ UpperCase() } type LowerUpperCaser interface{ LowerCaser UpperCaser } //实际上就等价于 type LowerUpperCaser interface{ LowerCase() UpperCase() }
但是上面比下面的写法好的一点在于,如果LowerCaser和UpperCaser接口添加或删减了方法,LowerUpperCaser接口也会相应地进行变化,无需改变其代码
1)interface值
那么interface 里面到底能够存什么值呢?
如果我们定义了一个interface的变量,那么该变量就能够存储实现了这个interface的任意类型的对象,如下面的例子:
package main import "fmt" type Human struct{ name string age int phone string } type Student struct{ Human//匿名字段 school string loan float32 } type Employee struct { Human//匿名字段 company string money float32 } //该interface被Human、Employee、Student都实现了 type Men interface{ SayHi() Sing(lyrics string) } //Human实现SayHi方法 func (h Human) SayHi(){ fmt.Printf("hi i am %s ,you can call me on %s\n", h.name, h.phone) } //Human实现SayHi方法 func (h Human) Sing(lyrics string){ fmt.Println("la la la la ...", lyrics) } //Employee重载Human的SayHi方法 func (e Employee) SayHi(){ fmt.Printf("hi i am %s, i work at %s. Call me on %s\n", e.name, e.company, e.phone) } func main() { mike := Student{Human{"Mike", 25, "222-222-xxx"}, "MIT", 0.00} paul := Student{Human{"Paul", 26, "111-222-xxx"}, "Harvard", 100} sam := Employee{Human{"Sam", 36, "444-222-xxx"}, "Golang Inc.", 1000} tom := Employee{Human{"Tom", 36, "333-444-xxx"}, "Tings Ltd.", 5000} //定义一个interface Men的变量 var i Men //i能存储Human、Student和Employee的值 i = mike fmt.Println("this is mike, a student") i.SayHi() i.Sing("rain") i = tom fmt.Println("this is tom, a Employee") i.SayHi() i.Sing("wild") //也可以定义一个切片Men来分别存储三种Human、Student和Employee的值 x := make([]Men, 3) x[0], x[1], x[2] = paul, sam, mike for _, value := range x{ value.SayHi() } }
返回:
userdeMBP:go-learning user$ go run test.go his name is: Mark His age is: 25 His weight is: 120 His speciality is: computer His changed speciality is: AI His changesd age is: 46 His changed weight is: 180 userdeMBP:go-learning user$ go run test.go this is mike, a student hi i am Mike ,you can call me on 222-222-xxx la la la la ... rain this is tom, a Employee hi i am Tom, i work at Tings Ltd.. Call me on 333-444-xxx la la la la ... wild hi i am Paul ,you can call me on 111-222-xxx hi i am Sam, i work at Golang Inc.. Call me on 444-222-xxx hi i am Mike ,you can call me on 222-222-xxx
2)interface函数参数
从上面的可知,interface的变量可以持有任意实现该interface类型的对象。
这样我们就想是否可以通过定义interface参数,让函数接受各种类型的参数。在这里举例的是fmt包中的Println函数,我们发现它能够接受任意类型的数据。
首先在fmt的源码中定义了一个interface:
type Stringer interface { String() string }
定义任何实现了String()方法,即Stringer interface的类型都能够作为参数被fmt.Println调用
所以,如果你想要某个类型能被fmt包义特殊格式输出,那么你就要实现该interface;如果你没有实现,那么就会义默认的方式输出,如下:
package main import( "fmt" ) type Human struct{ name string age int phone string } func main() { Bob := Human{"Bob", 39, "000-777-xxx"} fmt.Println("this human is : ", Bob) }
上面将以默认的格式输出:
userdeMBP:go-learning user$ go run test.go this human is : {Bob 39 000-777-xxx}
如果实现了interface,如下:
package main import( "fmt" "strconv" ) type Human struct{ name string age int phone string } func (h Human) String() string{ return " " + h.name + " - " + strconv.Itoa(h.age) + " years - phone : " + h.phone } func main() { Bob := Human{"Bob", 39, "000-777-xxx"} fmt.Println("this human is : ", Bob) }
以特殊格式返回:
userdeMBP:go-learning user$ go run test.go this human is : Bob - 39 years - phone : 000-777-xxx
3)那么我门如何反向知道目前的interface变量中存储的是什么类型呢?使用:
value, ok = element.(T)//T为类型,即int,[]string,Student value = element.(type) //返回element的类型
49.反射
反射就是动态运行时的状态。一般是使用reflect包
使用reflect包一般分为下面三步:
1)如果要去反射一个类型的值(这些值都实现了空interface),首先需要将它转化成reflect对象(使用reflect.Type或reflect.Value,根据不同的情况去调用不同的函数):
t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素 v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值
2)转化成reflect对象后就能够进行一些操作,即将reflect对象转化成相应的值,如:
tag := t.Elem().Field(0).Tag //获取定义在struct里面的标签 name := v.Elem().Field(0).String() //获取存储在第一个字段里面的值
获取反射值能返回相应的类型和数值:
package main import( "fmt" "reflect" ) func main() { var x float64 = 3.4 v := reflect.ValueOf(x) fmt.Println("type : ", v.Type()) //type : float64 fmt.Println("kind is float64 :", v.Kind() == reflect.Float64) //kind is float64 : true fmt.Println("value : ", v.Float()) //value : 3.4 }
3)反射的字段必须是可修改的,即可读写的,那么就要引用传递
如果按下面这样写,就会发生错误:
var x float64 = 3.4 v := reflect.ValueOf(x) v.SetFloat(7.1)
应该写成:
var x float64 = 3.4 p := reflect.ValueOf(&x) v := p.Elem() v.SetFloat(7.1)
这只是简单的介绍,更详细的介绍看go标准库的学习-reflect
50.结构体
当值(在结构体中叫字段)来自不同类型时,它不能存储在一个切片中(除非我们使用[]interface{}),比如:
package main import( "fmt" ) func main() { xs := make([]interface{}, 4) map1 := make(map[int]int) map1[0] = 2 map2 := make(map[int]string) map2[1] = "A" xs[0] = map1 xs[1] = map2 fmt.Println(xs) //返回:[map[0:2] map[1:A] <nil> <nil>] }
结构体字段的调用,切片使用[]索引,结构体则是.
package main import( "fmt" ) func main() { points := []struct{x, y int} {{4,6}, {}, {-7, 11}} for _, point := range points{ fmt.Printf("(%d, %d)", point.x, point.y) } fmt.Println() }
返回:
userdeMBP:go-learning user$ go run test.go (4, 6)(0, 0)(-7, 11)
结构体除了可以聚合和嵌入一个具体的类型外,也可以聚合和嵌入接口。但是反之在接口中聚合或嵌入结构体是不行的,因为接口是完全抽象的概念,这样的聚合和嵌入毫无意义
当一个结构体包含聚合(具名的)或嵌入(匿名的)接口类型的字段时,这意味着该结构体可以将任意满足该接口规格的值存储在该字段中
51.并发编程goroutine
main()函数就是由一个单独的goroutine来执行的
Go 程序中使用 go 关键字为一个函数创建一个 goroutine。一个函数可以被创建多个 goroutine,一个 goroutine 必定对应一个函数。
使用格式:
go 函数名( 参数列表 )
可见上面并不需要返回值,在goroutine 中返回数据使用的是通道chan
⚠️所有goroutine在main函数结束时会一同结束
陷阱:
1)主goroutine在其他工作goroutine还没有完成时就提前退出:所以必须保证所有工作goroutine都完成后才让主goroutine退出
2)死锁
1》即使所有工作都已经完成,但是主goroutine和工作goroutine还存活。一般是由于工作完成了,但是主goroutine无法获得工作goroutine的完成状态
2》当两个不同的goroutine都锁定了受保护的资源,而且同时尝试去获得对方资源的时候,即使用锁的时候会出现。但是在go中并不多见,因为go中使用通道来避免使用锁
1)为了避免程序提前退出或不能正常退出,常见用法是让主goroutine在一个done通道上等待,根据接收到的消息来判断工作是否完成
2)另一种避免这些陷阱的方法就是使用sync.WaitGroup来让每个工作goroutine报告自己的完成状态。但是使用sync.WaitGroup本身也会产生死锁,特别是当所有的工作goroutine都处于锁定状态的时候(等待接受通道的数据)调用sync.WaitGroup.Wait()
就算只使用通道,仍然可能发生死锁。假如有若干个goroutine可以互相通知对方去执行某个函数(向对方发一个请求),现在,如果这些被请求执行的函数中有一个函数向执行它的goroutine发送了一些东西,例如数据,死锁就发生了

通道为并发运行的goroutine之间提供了一种无锁通信方式
本质上说在通道中传输布尔类型、整形或float64类型的值都是安全的,因为它们都是通过复制的方法来传送的
1)但是go不保证在通道中发送指针或者引用类型(如切片或映射)的安全性,因为指针指向的内容或者所引用的值可能在对方接收到时就已经被发送方修改。因此对这些值的访问必须要串行进行
2)除了使用互斥量实现串行访问,另一种办法就是设定一个规则,一旦指针或者引用发送之后发送方就不会再访问它,然后让接受者来访问和释放指针或者引用指向的值。如果双方都发送指针或者引用的话,就双方都要接受这种机制
3)第三种方法就是让所有导出的方法不能修改其值,所有可修改其值的方法都不引出。这样外部可以通过引出的这些方法进行并发访问,但是内部实现只允许一个goroutine去访问它的非导出方法
使用并发的最简单的一种方式就是用一个goroutine来准备工作,然后让另一个goroutine来执行处理,让主goroutine和一些通道来安排一切事情
举例说明:
func main() { jobs := make(chan Job) done := make(chan bool, len(jobList)) go func(){ for _, job := range jobList{ jobs <- job //阻塞,等待接收方接收 } close(jobs) }() go func(){ for job := range jobs{ //等待发送方发送数据 fmt.Println(job) done <- true //只要接收到一个数据就传送一个true } }() for i := 0; i < len(jobList); i++{//该代码目的是确保主goroutine等到所有的工作完成后才退出,即接收到len(jobList)个长度的true <- done } }
可以在声明时将通道设置为单向的
chan <- Type :声明一个只允许别人朝该通道中发送数据的通道,即只写
<-chan Type :声明一个只允许将通道中的数据发送出去的通道,即只读
52.并发的grep(cgrep)
并发编程更常见的一种方式就是我们有很多工作需要处理,且每个工作都可以独立完成。比如go语言标准库中的net/http包的HTTP服务器利用这种模式来处理并发,每个请求都在一个独立的goroutine里处理,和其他的goroutine之间没有任何通信
这里我们实现一个cgrep程序来实现这一种模式。
目的:从命令行中读取一个正则表达式和一个文件列表,然后输出文件名、行号,和每个文件中所有匹配这个表达式的行。没匹配的话就什么也不输出
这里有很多例子都没有看,之后再转回来看!!!!!!!
参考http://c.biancheng.net/golang/concurrent/
53.调整并发的运行性能(使用runtime标准库)
在 Go 程序运行时(runtime)实现了一个小型的任务调度器。这套调度器的工作原理类似于操作系统调度线程,Go 程序调度器可以高效地将 CPU 资源分配给每一个任务。传统逻辑中,开发者需要维护线程池中线程与 CPU 核心数量的对应关系。同样的,Go 地中也可以通过 runtime.GOMAXPROCS() 函数做到,格式为:
runtime.GOMAXPROCS(逻辑CPU数量)
func GOMAXPROCS
func GOMAXPROCS(n int) int
GOMAXPROCS设置可同时执行的最大CPU数,并返回先前的设置。 若 n < 1,它就不会更改当前设置;n = 1,单核运行;n > 1,多核并发运行
本地机器的逻辑CPU数可通过 NumCPU 查询。
本函数在调度程序优化后会去掉。
func NumCPU
func NumCPU() int
NumCPU返回本地机器的逻辑CPU个数。
所以最终的设置版本为:
runtime.GOMAXPROCS(runtime.NumCPU())
GO 语言在 GOMAXPROCS 数量与任务数量相等时,可以做到并行执行,但一般情况下都是并发执行。
goroutine 属于抢占式任务处理,已经和现有的多线程和多进程任务处理非常类似。应用程序对 CPU 的控制最终还需要由操作系统来管理,操作系统如果发现一个应用程序长时间大量地占用 CPU,那么用户有权终止这个任务。
54.通道(chan)
函数和函数间需要交换数据才能体现并发执行函数的意义
在go语言中提倡使用通道(chan)的方法代替内存
在任何时候,同时只能有一个 goroutine 访问通道进行发送和获取数据。
1)通道声明:
var 通道变量 chan 通道类型
chan 类型的空值是 nil,声明后需要配合 make 后才能使用。
可以在声明时将通道设置为单向的:
- chan <- Type :声明一个只允许别人朝该通道中发送数据的通道,即只写
- <-chan Type :声明一个只允许将通道中的数据发送出去的通道,即只读
举例:
ch := make(chan int) // 声明一个只能发送的通道类型, 并赋值为ch,即只写入 var chSendOnly chan<- int = ch //声明一个只能接收的通道类型, 并赋值为ch,即只读出 var chRecvOnly <-chan int = ch
但是,一个不能填充数据(发送)只能读取的通道是毫无意义的。即<-chan Type
使用的方式有将其作为一个计时器,在标准库time中可见
type Ticker
type Ticker struct { C <-chan Time // 周期性传递时间信息的通道 r runtimeTimer }
Ticker保管一个通道,并每隔一段时间向其传递"tick"。
func Tick
func Tick(d Duration) <-chan Time
Tick是NewTicker的封装,只提供对Ticker的通道的访问。如果不需要关闭Ticker,本函数就很方便。
实现代码:
func Tick(d Duration) <-chan Time { if d <= 0 { return nil } return NewTicker(d).C }
func NewTicker
func NewTicker(d Duration) *Ticker
NewTicker返回一个新的Ticker,该Ticker包含一个通道字段,并会每隔时间段d就向该通道发送当时的时间。它会调整时间间隔或者丢弃tick信息以适应反应慢的接收者。如果d<=0会panic。关闭该Ticker可以释放相关资源。
实现代码;
func NewTicker(d Duration) *Ticker { if d <= 0 { panic(errors.New("non-positive interval for NewTicker")) } // Give the channel a 1-element time buffer. // If the client falls behind while reading, we drop ticks // on the floor until the client catches up. c := make(chan Time, 1) t := &Ticker{ C: c, r: runtimeTimer{ when: when(d), period: int64(d), f: sendTime, arg: c, }, } startTimer(&t.r) return t }
单向通道有利于代码接口的严谨性。
2)通道创建:
因为是引用类型,需要使用make来创建:
通道实例 := make(chan 数据类型)
3)通道接收有如下特性:
① 通道的收发操作在不同的两个 goroutine 间进行。
② 接收将持续阻塞直到发送方发送数据。
③ 每次接收一个元素。
4)通道数据接受
通道的数据接收一共有以下 4 种写法。
1) 阻塞接收数据
阻塞模式接收数据时,将接收变量作为<-操作符的左值,格式如下:
data := <-ch
执行该语句时将会阻塞,直到接收到数据并赋值给 data 变量。
2) 非阻塞接收数据
使用非阻塞方式从通道接收数据时,语句不会发生阻塞,格式如下:
data, ok := <-ch
- data:表示接收到的数据。未接收到数据时,data 为通道类型的零值。
- ok:表示是否接收到数据。
非阻塞的通道接收方法可能造成高的 CPU 占用,因此使用非常少。
如果需要实现接收超时检测,可以配合 select 和计时器 channel 进行,可以参见后面的内容。
3) 接收任意数据,忽略接收的数据
阻塞接收数据后,忽略从通道返回的数据,格式如下:
<-ch
执行该语句时将会发生阻塞,直到接收到数据,但接收到的数据会被忽略。这个方式实际上只是通过通道在 goroutine 间阻塞收发实现并发同步。
4)循环接受——使用for range
for data := range ch { ... }
5)通道的多路复用——同时处理接收和发送多个通道的数据
办法就是使用select。select 的每个 case 都会对应一个通道的收发过程。多个操作在每次 select 中挑选一个进行响应。
格式为:
select{ case 操作1: 响应操作1 case 操作2: 响应操作2 … default://有default则说明是非阻塞的,当没有任何操作时,则默认执行default中的语句 没有操作情况 }
case中的操作语句的类型分为下面的三种:
- 等待接收任意数据:case <- ch
- 等待接收数据并赋值到变量中: case d := <- ch
- 等待发送数据: case ch <- 100
6)关闭通道后(使用close())如何继续使用通道
通道是一个引用对象,和 map 类似。map 在没有任何外部引用时,Go 程序在运行时(runtime)会自动对内存进行垃圾回收(Garbage Collection, GC)。类似的,通道也可以被垃圾回收,但是通道也可以被主动关闭。
格式:
使用 close() 来关闭一个通道:
close(ch)
关闭的通道依然可以被访问,访问被关闭的通道将会发生一些问题。
给被关闭通道发送数据将会触发panic
被关闭的通道不会被置为 nil。如果尝试对已经关闭的通道进行发送,将会触发宕机,代码如下:
package main import "fmt" func main() { // 创建一个整型的通道 ch := make(chan int) // 关闭通道 close(ch) // 虽然通道已经被关闭了,但是还是能够打印通道的指针, 容量和长度 fmt.Printf("ptr:%p cap:%d len:%d\n", ch, cap(ch), len(ch)) // 但是如果给关闭的通道发送数据 ch <- 1 }
返回:
userdeMBP:go-learning user$ go run test.go ptr:0xc000062060 cap:0 len:0 panic: send on closed channel goroutine 1 [running]: main.main() /Users/user/go-learning/test.go:16 +0x144 exit status 2
从已关闭的通道接收数据时将不会发生阻塞
package main import "fmt" func main() { // 创建一个整型带两个缓冲的通道 ch := make(chan int, 2) // 给通道放入两个数据 ch <- 0 ch <- 1 // 关闭缓冲 close(ch) // 遍历缓冲所有数据, 且多遍历1个,故意造成这个通道的超界访问 for i := 0; i < cap(ch)+1; i++ { // 从通道中取出数据 v, ok := <-ch // 打印取出数据的状态 fmt.Println(v, ok) } }
返回:
userdeMBP:go-learning user$ go run test.go 0 true 1 true 0 false
运行结果前两行正确输出带缓冲通道的数据,表明缓冲通道在关闭后依然可以访问内部的数据。
运行结果第三行的“0 false”表示通道在关闭状态下取出的值。0 表示这个通道的默认值,false 表示没有获取成功,因为此时通道已经空了。我们发现,在通道关闭后,即便通道没有数据,在获取时也不会发生阻塞,但此时取出数据会失败。
7)竞态检测——检测代码在并发环境下可能出现的问题
通道内部的实现依然使用了各种锁,因此优雅代码的代价是性能。在某些轻量级的场合,原子访问(atomic包)、互斥锁(sync.Mutex)以及等待组(sync.WaitGroup)能最大程度满足需求。
1》原子访问
当多线程并发运行的程序竞争访问和修改同一块资源时,会发生竞态问题。
下面的代码中有一个 ID 生成器,每次调用生成器将会生成一个不会重复的顺序序号,使用 10 个并发生成序号,观察 10 个并发后的结果。
package main import ( "fmt" "sync/atomic" ) var ( // 序列号 seq int64 ) // 序列号生成器 func GenID() int64 { // 尝试原子的增加序列号 atomic.AddInt64(&seq, 1) //这里故意没有使用 atomic.AddInt64() 的返回值作为 GenID() 函数的返回值,因此会造成一个竞态问题。 return seq } func main() { //生成10个并发序列号 for i := 0; i < 10; i++ { go GenID() } fmt.Println(GenID()) }
如果正常运行:
userdeMBP:go-learning user$ go run test.go 9 //并不是期待的结果
在运行程序时,为运行参数加入-race参数,开启运行时(runtime)对竞态问题的分析:
userdeMBP:go-learning user$ go run -race test.go ================== WARNING: DATA RACE Write at 0x000001212840 by goroutine 7: sync/atomic.AddInt64() /usr/local/Cellar/go/1.11.4/libexec/src/runtime/race_amd64.s:276 +0xb main.GenID() /Users/user/go-learning/test.go:17 +0x43 Previous read at 0x000001212840 by goroutine 6: main.GenID() /Users/user/go-learning/test.go:19 +0x53 Goroutine 7 (running) created at: main.main() /Users/user/go-learning/test.go:26 +0x4f Goroutine 6 (finished) created at: main.main() /Users/user/go-learning/test.go:26 +0x4f ================== 10 Found 1 data race(s) exit status 66
可见第6个goroutine和第7个goroutine之间发生了竞态问题
但是如果我们将GetID()的返回更改成:
func GenID() int64 { // 尝试原子的增加序列号 return atomic.AddInt64(&seq, 1) }
竞态问题就解决了,然后返回:
userdeMBP:go-learning user$ go run -race test.go 10
本例中只是对变量进行增减操作,虽然可以使用互斥锁(sync.Mutex)解决竞态问题,但是对性能消耗较大。在这种情况下,推荐使用原子操作(atomic)进行变量操作。
2》互斥锁(sync.Mutex)
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个 goroutine 可以访问共享资源
package main import ( "fmt" "sync" ) var ( // 逻辑中使用的某个变量 count int // 与变量对应的使用互斥锁,一般情况下,建议将互斥锁的粒度设置得越小越好,降低因为共享访问时等待的时间 countGuard sync.Mutex //保证修改 count 值的过程是一个原子过程,不会发生并发访问冲突 ) func GetCount() int { // 锁定,此时如果另外一个 goroutine 尝试继续加锁时将会发生阻塞,直到这个 countGuard 被解锁 countGuard.Lock() // 在函数退出时解除锁定 defer countGuard.Unlock() return count } func SetCount(c int) { countGuard.Lock() count = c countGuard.Unlock() } func main() { // 可以进行并发安全的设置 SetCount(1) // 可以进行并发安全的获取 fmt.Println(GetCount()) }
返回:
userdeMBP:go-learning user$ go run -race test.go 1 userdeMBP:go-learning user$ go run test.go 1
3》读写互斥锁(sync.RWMutex)
在读多写少的环境中,可以优先使用读写互斥锁(sync.RWMutex),它比互斥锁更加高效。sync 包中的 RWMutex 提供了读写互斥锁的封装。
将上面互斥锁例子中的一部分代码修改为读写互斥锁:
var ( // 逻辑中使用的某个变量 count int // 与变量对应的使用读写互斥锁,差别就是当另一个goroutine也要读取改数据时,不会发生阻塞 countGuard sync.RWMutex ) func GetCount() int { // 锁定 countGuard.RLock() // 在函数退出时解除锁定 defer countGuard.RUnlock() return count }
4》等待组(sync.WaitGroup)
除了可以使用通道(channel)和互斥锁进行两个并发程序间的同步外,还可以使用等待组进行多个任务的同步,等待组可以保证在并发环境中完成指定数量的任务
WaitGroup用于等待一组线程的结束。父线程调用Add方法来设定应等待的线程的数量。每个被等待的线程在结束时应调用Done方法。同时,主线程里可以调用Wait方法阻塞至所有线程结束。
三个方法:
func (*WaitGroup) Add
func (wg *WaitGroup) Add(delta int)
Add方法向内部计数加上delta,delta可以是负数;如果内部计数器变为0,Wait方法阻塞等待的所有线程都会释放,如果计数器小于0,方法panic。注意Add加上正数的调用应在Wait之前,否则Wait可能只会等待很少的线程。一般来说本方法应在创建新的线程或者其他应等待的事件之前调用。
func (*WaitGroup) Done
func (wg *WaitGroup) Done()
Done方法减少WaitGroup计数器的值,即-1,应在线程的最后执行。
func (*WaitGroup) Wait
func (wg *WaitGroup) Wait()
Wait方法阻塞直到WaitGroup计数器减为0。
举例说明,当我们添加了 N 个并发任务进行工作时,就将等待组的计数器值增加 N。每个任务完成时,这个值减 1。同时,在另外一个 goroutine 中等待这个等待组的计数器值为 0 时,表示所有任务已经完成:
package main import ( "fmt" "net/http" "sync" ) func main() { // 声明一个等待组 var wg sync.WaitGroup // 准备一系列的网站地址 var urls = []string{ "http://www.github.com/", "https://www.qiniu.com/", "https://www.golangtc.com/", } // 遍历这些地址 for _, url := range urls { // 每一个任务开始时, 将等待组增加1 wg.Add(1) // 开启一个并发 go func(url string) { // 使用defer, 表示函数完成时将等待组值减1 // wg.Done() 方法等效于执行 wg.Add(-1) defer wg.Done() // 使用http访问提供的地址 // Get() 函数会一直阻塞直到网站响应或者超时 _, err := http.Get(url) //在网站响应和超时后,打印这个网站的地址和可能发生的错误 fmt.Println(url, err) // 通过参数传递url地址 }(url) } // 等待所有的网站都响应或者超时后,任务完成,Wait 就会停止阻塞。 wg.Wait() fmt.Println("over") }
返回:
userdeMBP:go-learning user$ go run test.go https://www.golangtc.com/ <nil> http://www.github.com/ <nil> https://www.qiniu.com/ Get https://www.qiniu.com/: dial tcp 124.200.113.148:443: i/o timeout over
55.实现远程过程调用(RPC)
使用通道chan代替socket实现RPC的例子:
package main import( "fmt" "time" "errors" ) //模拟RPC客户端的请求和接收消息封装 func RPCClient(ch chan string, req string) (string, error){ //向服务端发送数据 ch <- req //等待服务端返回数据 select{ case ack := <- ch: return ack, nil case <- time.After(time.Second): return "", errors.New("time out") } } func RPCServer(ch chan string){ for{ //接收客户的请求 data := <-ch //打印接收到的数据 fmt.Println("server received: ", data) //并给客户反馈结果 ch <- "received" } } func main() { //创建一个无缓冲字符串通道 ch := make(chan string) //并发执行服务器 go RPCServer(ch) //客户端请求数据并接收数据 recv, err := RPCClient(ch, "hello server") if err != nil{ fmt.Println(err) }else{ //打印接收到的数据 fmt.Println("client received : ", recv) } }
⚠️time.After(time.Second):用于实现超时操作
返回:
userdeMBP:go-learning user$ go run test.go
server received: hello server
client received : received
模拟超时:
package main import( "fmt" "time" "errors" ) //模拟RPC客户端的请求和接收消息封装 func RPCClient(ch chan string, req string) (string, error){ //向服务端发送数据 ch <- req //等待服务端返回数据 select{ case ack := <- ch: return ack, nil
//time.After即一段时间后,这里是一秒后 case <- time.After(time.Second): //因为这里如果客户端处理超过1秒就会返回超时的错误 return "", errors.New("time out") } } //模拟超时主要改的是客户端 func RPCServer(ch chan string){ for{ //接收客户的请求 data := <-ch //打印接收到的数据 fmt.Println("server received: ", data) // 通过睡眠函数让程序执行阻塞2秒的任务 time.Sleep(time.Second * 2) //然后再给客户反馈结果 ch <- "received" } } func main() { //创建一个无缓冲字符串通道 ch := make(chan string) //并发执行服务器 go RPCServer(ch) //客户端请求数据并接收数据 recv, err := RPCClient(ch, "hello server") if err != nil{ fmt.Println(err) }else{ //打印接收到的数据 fmt.Println("client received : ", recv) } }
返回:
userdeMBP:go-learning user$ go run test.go server received: hello server time out
56.使用通道响应计时器——使用标准库time
1)使用time.AfterFunc()实现等待一段时间后调用函数,并直到该函数生成的另一goroutine结束后才结束main()函数的goroutine
package main import( "fmt" "time" ) func main() { //声明一个用于退出的通道 exit := make(chan int) fmt.Println("start") //过1秒后,就会开一个新goroutine来运行匿名函数 time.AfterFunc(time.Second, func(){ //该匿名函数的作用就是在1秒后打印结果,并通知main()函数可以结束主goroutine fmt.Println("one second after") exit <- 0 }) //main()正在等待从exit通道中接受数据来结束主goroutine <- exit }
返回:
userdeMBP:go-learning user$ go run test.go
start
one second after
如果不使用通道来控制,主goroutine一定会在一秒内先结束,这样永远不会运行到匿名函数中的内容:
package main import( "fmt" "time" ) func main() { //声明一个用于退出的通道 exit := make(chan int) fmt.Println("start") //过1秒后,就会开一个新goroutine来运行匿名函数 time.AfterFunc(time.Second, func(){ //该匿名函数的作用就是在1秒后打印结果,并通知main()函数可以结束主goroutine fmt.Println("one second after") exit <- 0 }) //main()正在等待从exit通道中接受数据来结束主goroutine // <- exit //如果没有这个,我们会发现主goroutine会在1秒前结束,同时结束上面的goroutine,这样根本就不会输出"one second after" fmt.Println("if there is not <- exit, won't print one second after") }
返回:
userdeMBP:go-learning user$ go run test.go start if there is not <- exit, won't print one second after
2)定点计时
计时器(Timer)的原理和倒计时闹钟类似,都是给定多少时间后触发。
打点器(Ticker)的原理和钟表类似,钟表每到整点就会触发。
这两种方法创建后会返回 time.Ticker 对象和 time.Timer 对象,里面通过一个 C 成员,类型是只能接收的时间通道(<-chan Time),使用这个通道就可以获得时间触发的通知。
详细内容可见go标准库的学习-time
下面代码创建一个打点器Ticker,每 500 毫秒触发一起;创建一个计时器Timer,2 秒后触发,只触发一次。
package main import( "fmt" "time" ) func main() { //创建一个打点器,每500毫秒触发一次 ticker := time.NewTicker(time.Millisecond * 500) //创建一个计时器,2秒后触发 timer := time.NewTimer(time.Second * 2) //声明计数变量 var count int //不断检查通道情况 for{ //多路复用通道 select{ case <- timer.C://计时器到时了,即2秒已到 fmt.Println("time is over,stop!!") goto StopLoop case <- ticker.C://打点器触发了,说明已隔500毫秒 count++ fmt.Println("tick : ", count) } } //停止循环所到的标签 StopLoop: fmt.Println("ending") }
返回:
userdeMBP:go-learning user$ go run test.go tick : 1 tick : 2 tick : 3 tick : 4 time is over,stop!! ending
53.文件处理
没认真看,之后再补
54.包
我们的程序和包最好是放在GOPATH源码目录下的一个src的目录中。如果这个包只属于某个应用程序,那么可以直接放在应用程序的子目录下。但是如果希望这个包可以被其他的应用程序共享,那就应该放在GOPATH的src目录下.
每个包单独放在一个目录下,如果两个不同的包放在同一个目录下,会出现命名冲突的编译错误
包的源码应该放在一个同名的文件夹下,同一个包里可以有多个文件,文件后缀为.go。如果一个包中有多个文件,其中必定有一个文件的名字和包名相同

