mysql隔离级别
说起mysql的隔离级别,大家可能都知道。主要就是以下几种。

但是为什么mysql的默认隔离级别是可重复读呢,今天我们就针对这一隔离级别来探索。首先我们来看下可重复读的实现方式。
可重复读指的是当前事务A查询了一条数据值为5,另一个事务B将值改为3并提交,事务A再次查询值还是5。为什么能够实现呢,使用的方法是MVCC多版本并发控制(Multi-Version Concurrency Control)。
InnoDB的MVCC是通过在每行记录后面保存两个隐藏的列来实现。这两个列,一个保存行的创建时间,一个保存行的过期时间(或删除时间)。当然存储的并不是实际的时间值,而是系统版本号。每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行记录的版本号进行比较。MVCC在可重复读的隔离级别的操作如下。
SELECT
InnoDB会根据以下两个条件检查每行记录:
a.InnoDB只查找版本早于当前事务版本的数据行(也就是。行的系统版本号小于或等于事务的系统版本号),这样就可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或修改过的。
b.行的删除版本要么未定义,要么大于当前事务版本号。这可以确保事务读取到的行,在事务开始之前未被删除。
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为行版本号。
DELETE
InnoDB为删除的每一行保存当前系统版本号作为行删除标识。
UPDATE
InnoDB为插入一行新纪录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。
保存这两个额外系统版本号,使大多数读操作都可以不用加锁。这样设计是的读数据库操作很简单,性能很好,并且也能保证只会读到符合标准的行。不足之处是每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
MVCC只在可重复读和读已提交两个隔离级别下工作。其他两个隔离级别都和MVCC不兼容。读未提交总是读取最新的数据行,而不是符合当前事务版本的数据行。儿串行化则会对所有读取的行都加锁。
其实就是每条数据都对应一个版本,当你查询的时候获取此时的版本号,后续有其他事务操作这条数据时版本号值会加1,而操作查询的时候默认会有一个条件就是版本号<=当前获取的版本号。那么其他事物操作后的数据就查不到了。根据开头说的场景进行一下模拟。
假设初始版本号为1,首先往库里插入一条值为5的数据。insert into table (id,value) values (1,'5');这时候数据表示如下:
| id | value | create_version | delete_version |
| 1 | 5 | 1 |
现在事务A对这条数据进行查询,select * from table where id = 1;此时读到的创建版本号为1,删除版本号为空。另外一个事务B更新这条数据值为3,update table set value = '3' where id = 1;因为开启了一个新事务,所以此时的版本号加一变为了2。此时数据表示如下:
| id | value | create_version | delete_version |
| 1 | 5 | 1 | 2 |
| 1 | 3 | 2 |
这时,事务A再次查询记录的时候,因为他当前的版本号为1,删除版本号为2大于当前版本号。所以他只能查到value=5的这条记录。所以就实现了对同一数据可重复读。
Oracle的默认隔离级别是读已提交的,那么为什么mysql的默认隔离级别设置为可重复读呢?这是因为mysql的历史问题,假如有如下操作:
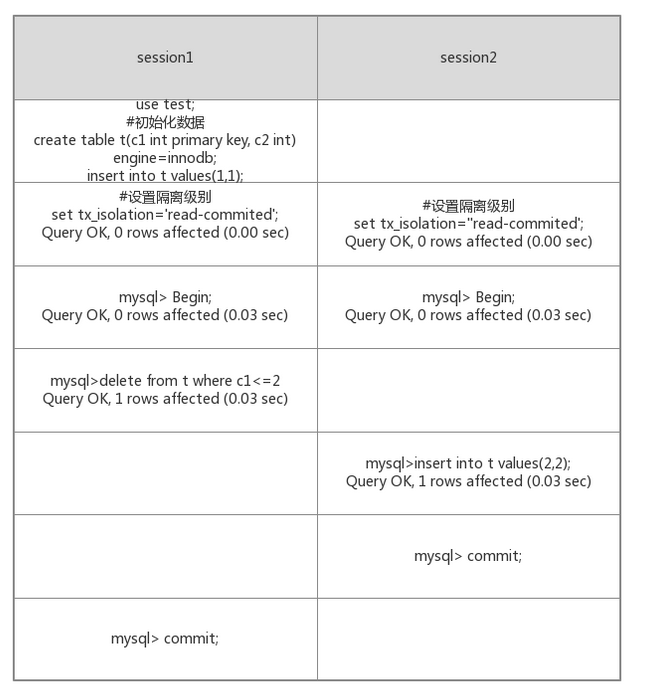
那么在binlog日志中会先记录inset语句,然后再记录删除语句。binlog是基于事务来记录用户对数据库操作的SQL语句(不包括查询)的二进制日志。这样就会在主从复制的时候造成数据不一致的情况。
解决方案有两种:
(1)隔离级别设为可重复读(Repeatable Read),在该隔离级别下引入间隙锁。当Session 1执行delete语句时,会锁住间隙。那么Ssession 2执行插入语句就会阻塞住。
(2)将binglog的格式修改为row格式,此时是基于行的复制,自然就不会出现sql执行顺序不一样的问题,但是在5.1及以后,MySQL才提供了Row和Mixed这两个Binlog格式。
引用:
https://blog.csdn.net/sanyuesan0000/article/details/90235335
https://blog.csdn.net/m0_37774696/article/details/88951846
https://www.cnblogs.com/lmj612/p/10598971.html
