

偏差、方差和数据不匹配
整理并翻译自吴恩达深度学习结构化机器学习第二周2.5。
数据的划分
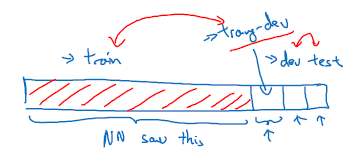
目前使用的数据划分pattern如上图所示,分为以下四个部分:
- train set(用来训练,前向传播、后向传播)
- train-dev set (增加这一部分是为了检验你从训练集得到的参数能否泛化到该数据集)
- dev set (dev set是为了衡量多个Classifier在该数据集上的表现)
- test set (检验最终结果是否能够很好地解决实际问题,能否实际部署)
从各个数据集的error上获得的信息
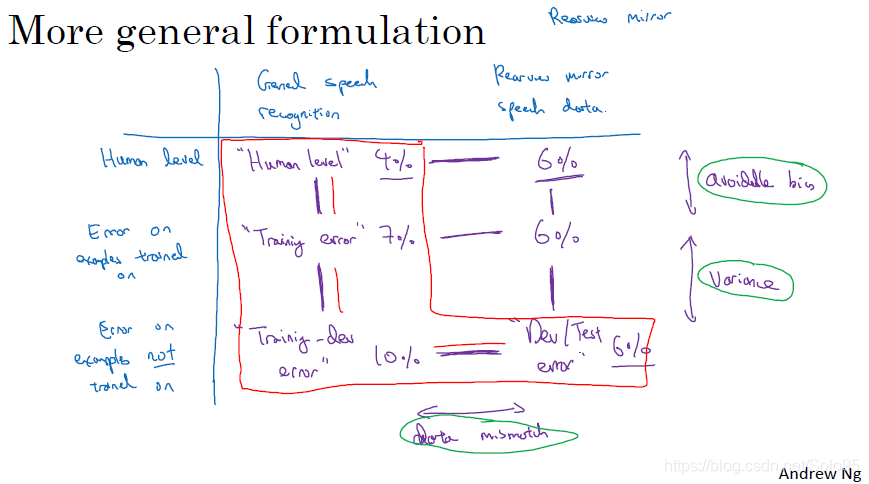
Human-level指人类在目标问题上的error,比如人眼识别猫,人会识别错的error。
- Human-level和Training error之间体现的是avoidable bias,可以通过训练更长的时间,选择更深的网络等单纯降低Bias的方法来降低。
- Training error和Training-dev error之间体现的是Variance, 可以通过正则化、改变网络结构等单纯降低Variance的方法来降低。
- Training-dev error和Dev/Test error之间体现的是data mismatch,即training set和test set的数据分布可能会有很大差别,导致你通过训练得到的参数无法很好的应用于解决实际问题。该问题可以用人工合成数据等方法使你的training set尽可能接近Dev/Test set,吴恩达这个视频的下一个视频对此有专门的解释说明。

