

注意力机制(Attention Mechanism)
注意力机制起源于应用于NLP的RNN模型,但也在其他的领域有所应用。对注意力机制的理解也是算法面试经常提及的一道基础面试题,在这篇博文里我们汇总吴恩达深度学习视频序列模型3.7和3.8以及台大李宏毅教授对Attenion Mechanism以及相关参考文献对注意力机制给出详细的介绍的解释。
注意力机制(Attention Mechanism)
注意力机制是深度学习中一个非常重要的思想,在NLP领域尤为重要。
为什么要引入Attention Mechanism?
在一个Encoder和Decoder的翻译模型中,翻译一段法语到英文大致是整个序列输进Encoder然后Decoder再输出整个结果。也就是说模型是观测了整个要翻译的序列,然后再按序做的翻译(时间步模型)。
随着输入序列边长,对模型输出结果的Bleu score评估会呈现这样的变化:

绿线代表人类翻译的水平,蓝线代表机器翻译的水平,之间的Gap能衡量模型记忆长序列的能力。
而人工翻译则是看一部分,翻译一部分,再看下一部分,再翻译一部分,如此往复。因为对人来说,要记忆整个序列是非常困难的。
总结下来:
- 输入序列非常长时,原始的Encoder-Decoder翻译的质量会出现明显下降,因为整个模型要处理的feature过多,并且这些feature不一定对翻译特定的单词有所助益。一说模型难以学到足够合理的向量表示。
- 原始的时间步方式翻译的模型在设计上有缺陷。具体来讲,整个序列无论长短都被Encoder编码到固定长度,这使得Decoder的能力受限。因为翻译前后,源语言和目标语言不一定长度一致。
- 时间步编解码器的结构缺乏有效的理论支撑和经验指导,导致设计困难,模型效果不好。
注意力机制直观理解
如同前面讲过的人工翻译是一部分一部分看,一部分一部分翻译一样,注意力机制旨在实现在计算某个时间步的输出时,将注意力集中在一段序列上,段的大小可以由一个窗口来决定,并且为该段序列每一个时间步都赋以权值,以决定它们对最终输出的影响权重。这样使得前面所述问题得到一定程度的解决。
注意力机制
实例说明:

如图所示,在计算Encoder的输出上下文
c
0
c^0
c0时,维持窗口大小为4,即一个时间步输出由四个时间步输入决定。
c
0
=
∑
i
=
1
4
α
0
^
i
h
i
c^0=\sum_{i=1}^4\hat{\alpha_0}^ih^i
c0=i=1∑4α0^ihi
那么每个时间步的权重
α
0
i
\alpha_0^i
α0i如何计算,通过一个match机制来实现,具体而言,可以使用一个小型的网络协同训练来得到一个具体match函数。
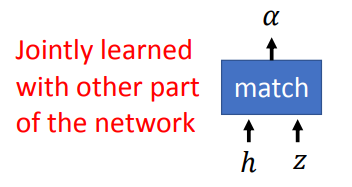
图中z是上一个时间步的输出,吴恩达notation里写作
s
<
t
−
1
>
s^{<t-1>}
s<t−1>。
可以使用softmax来实现:

使用softmax是为了窗口内部所有时间步权重相加等于1。
除此之外还有一些其他的实现方式:

- 余弦相似度
- 小型网络(前述)
- 使用只有一个权重的计算公式,权重可以交由原网络来训练
如上所述,重复以上过程指导所有时间步的输出都计算完成,这样就得到了最终结果的序列。
虽然使用attention机制会明显增加计算量,但是整个模型的输出结果质量得到有效提升。因为与单纯的Encoder-Decoder模型不同。面对大量的features我们只关注窗口内部那部分features,而且窗口内部每一个时间步如何影响最后的序列生成都由权重控制,这使得整个过程更加的科学合理。
注意力机制的应用
虽然我们以NLP为例,但注意力机制在其他领域也有一些应用。
-
文本翻译(Text Translation)
吴恩达课程为例,Attention机制被应用在翻译一个单词时应该重点关注哪些原词。 -
语义蕴含(Entailment)
Attention机制被用来关联假设和前提两者中词与词之间的对应关系。 -
语音识别(Audio Recognition)
Attention机制被用来关联每个输入语音序列的某些部分和相应音素的对应关系。 -
文本摘要(Text Summary)
Attention机制被用来关联输入文本中的一些重要词汇和生成的摘要里的词汇之间的对应关系。 -
图像描述(Image Caption)
在计算机视觉领域,Attention机制可以帮助卷积神经网络决定在生成文本描述时应该重点关注图像的哪一部分。

