

知识图谱上简单问题的知识问答
简单问题的界定是能通过查找一个事实就可以解答。本文关注baseline方法,是一篇概述博客。
本文介绍的方法属于pipeline风格,即分解问题到几个阶段,分阶段用对应的模块解决,最后的模块输出最后的结果。最新的研究进展也有构建知识图谱,然后在图上跑强化学习方法来进行解答路径选择。
知识图谱上的简单问题知识问答
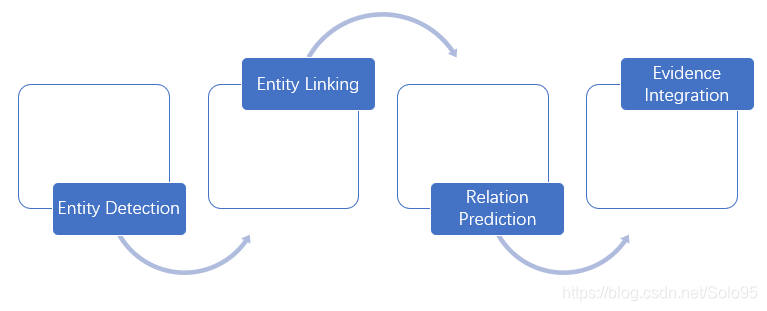
该问题可以直接分解为实体检测(entity detection)、关系链接(entity linking)、关系预测(relation prediction)、证据整合(evidence integration) 四个阶段。
有一个相关数据集:SIMPLEQUESTIONS。
实体检测(entity detection)
给定一个问题,实体检测的目标是识别被查询的实体。这很自然的就是一个序列标注问题,对每一个标识符(token),分配ENTITY或者NOTENTITY两个标签中的一个。
序列标注问题很明显能使用RNN来做。RNN这里不再赘述,可以参考之前的博文。
在RNN出现之前使用的方法是Conditional Random Fields(CRFs),是当时的state-of-art。
实体链接(entity linking)
实体检测的输出是一系列代表候选实体的标识符,需要把它们链接起来以构成一个知识图谱。Freebase中将每一个节点使用一个机器标识符(MID, Machine Identifier)。除此之外,可以简单的当作一个模糊字符匹配来处理。
关系预测(Relation Prediction)
关系预测的目标是识别被查询的关系。
可以被看做是整个问题上的分类问题。可以使用RNN、CNN、LR等分类器来进行。
证据整合(Evidence Integration)
在由前述3个步骤给定 m m m个实体, r r r个关系之后,最终任务是整合所有的证据抵达作为最终结果的一个 ( e n t i t y , r e l a t i o n ) (entity,relation) (entity,relation)预测。
可以通过以下方法来做:
首先生成 m ∗ r m*r m∗r个 ( e n t i t y , r e l a t i o n ) (entity, relation) (entity,relation)元组,使用前述组件的得分(scores)相乘得到每一个元组的得分,因为前述三个步骤是独立进行的,所以很多组合会是没有意义上的(例:在知识图谱中没有对应的关系存在),把这些无意义的组合剪去。剪去之后你会发现得分交叉(scoring ties),因为知识图谱上有重名结点。可以简单的通过选取入边最多的结点作为一个简单的代理结点(proxy)来打破交叉。进一步的,还可以选取有映射到维基百科的实体,这些实体出现在维基百科上,说明他们是流行的,或者说人们所关注的。
参考文献
Strong Baselines for Simple Question Answering over Knowledge Graphs with and without Neural Networks. Salman Mohammed, Peng Shi, and Jimmy Lin, NAACL-HLT (2) 2018: 291-296.

