

Imitation Learning in Large State Spaces 大规模状态空间下的模仿学习
这篇博文中的Imitation learning关注于和强化学习的结合,但imitation learning自身其实是一个独立的概念。这篇博文面向强化学习,如果你单纯想了解imitation learning,请参阅其他地方。
We want RL Algorithm that Perform
- Optimization(优化)
- Delayed consequences(延迟结果)
- Exploration(探索)
- Generation(泛化)
- And do it all statistically and computationally efficiently(统计性地,计算高效性地执行以上过程)
Generalization and Efficiency
- 这篇博文将稍后探讨高效探索
- 但学习一个能泛化的MDP存在困难,可能会需要很大数量的采样才能学习到一个好的策略
- 这个数量可能是无法实现的
- 替代思路:使用结构化和额外的知识来帮助约束和加速强化学习
- 这篇博文:模仿学习(Imitation Learning)
- 之后的博文:
- 策略搜索(Policy Search)(可以将领域知识以要使用的策略簇形式来进行编码)
- 策略探索(Strategic exploration)
- 再辅以人工协助(以教导、指定回报、指定动作的形式)
Imitation Learning with Large State Spaces
Consider Montezuma’s revenge
以蒙特祖玛复仇为例,注意下面这张图是训练了五千万帧的结果。演示视频可以在下面那个youtube链接上找到,

So far
到此为止,我们前面博客中所述的成功都是在数据可以轻易获取,并行计算非常容易的条件下取得的。当获取数据代价很高,前述算法可能无法很难取得进展。
- 强化学习:学习受(通常是稀疏的)回报指导的策略(e.g. 在游戏中获胜或失败)
- 好的情况:简单、监督学习代价很低
- 坏的情况:非常高的采样复杂度
在什么情景下能成功? - 在模拟环境中,因为模拟环境数据廉价并且并行简单
- 而不是在:
- 执行一个动作非常缓慢
- 失败的代价非常高或者不允许失败
- 希望能使安全的
以蒙特祖玛复仇为例,稀疏是指,agent必须尝试一系列不同的动作才能获得当前选择的动作是不是正确的新信号。
Reward Shaping

在时间上密集的回报紧密指导着agent
那这些回报是怎么拿出来的呢?
- 手动设计:可行但通常无法实现
- 通过证明隐式指定
比如:给一个汽车驾驶手动指定回报,回报函数会非常非常复杂,因为你要考虑非常多的因素。但手动把车成功开往目的地(证明),然后认为在该过程所采取的动作是好是可行的。这就是从证明中学习的思想
例子:

Learning from Demonstrations
不是很准确的说,learning from demonstrations也能被称为Inverse RL、Imitation Learing,这三者在一些地方还是有区别的。
- 专家提供一系列证明路径:状态和动作序列
- 模仿学习在对专家来说能轻易给出想要的行为的证明的条件下是非常实用的。而并非:
- 指定一个能产生这种行为的回报
- 直接指定想要的策略
Problem Setup
- 输入:
- 状态空间,动作空间
- 变迁模型 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a)
- 没有奖励函数 R R R
- 一个或更多教师的证明 ( s 0 , a 0 , s 1 , s 0 ) (s_0,a_0,s_1,s_0) (s0,a0,s1,s0)(从教师策略 π ∗ \pi^* π∗中抽取的动作)
- 行为克隆(Behavioral Cloning)
- 我们能直接使用监督学习去学习教师的策略吗?
- 反向强化学习(Inverse RL):
- 我们能恢复奖励函数R吗?
- 通过反向强化学习(Inverse RL)进行学徒学习(Apprenticeship Learning)
- 我们能使用R来产生一个好的策略吗?
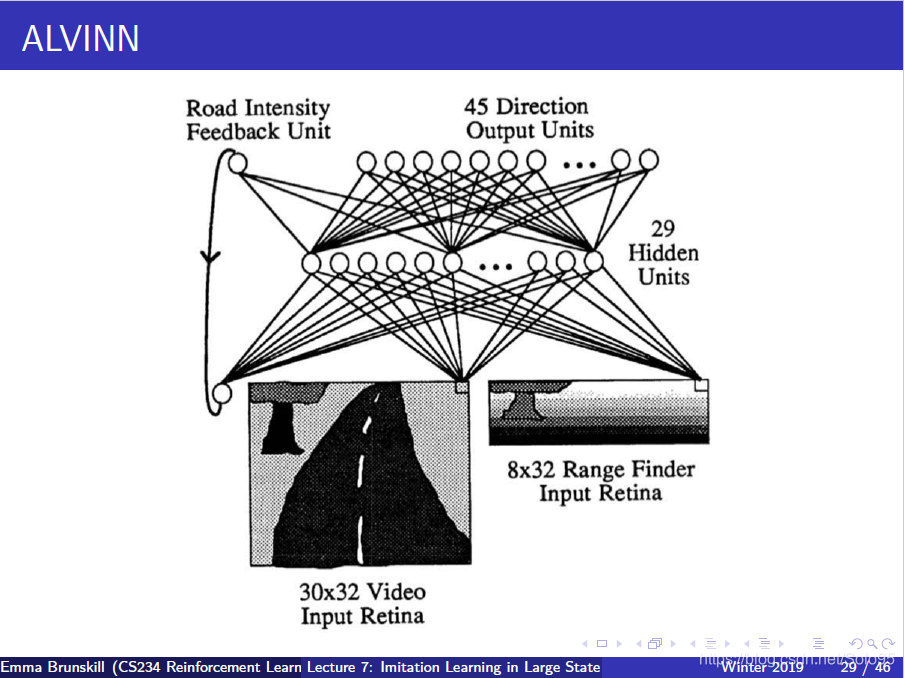
Behavioral Cloning
行为克隆这种方式,就是把它当做标准的监督学习问题对待。
- 将问题形式转化为一个标准的机器学习问题:
- 固定一个策略类(e.g. 神经网络,决策树,等.)
- 从训练样本 ( s 0 , a 0 ) , ( s 1 , a 1 ) , ( s 2 , a 2 ) , . . . (s_0,a_0),(s_1,a_1),(s_2,a_2),... (s0,a0),(s1,a1),(s2,a2),...中评估一个策略
- 两个值得注意的成功例子:
- Pomerleau, NIPS 1989: ALVINN
- Summut et al., ICML 1992: Learing to fly in flight simulator
Problem: Compounding Errors
监督学习假定iid(s,a)二元组并且忽略了在时间误差上的时序结构
独立相同分布(Indepently Indetically Distribution),简写为iid,非常常见的写法。
时间
t
t
t下有\epsilon$概率的误差
E
[
T
o
t
a
l
e
r
r
o
r
s
]
≤
ϵ
T
\mathbb{E}[Total errors]\leq \epsilon\Tau
E[Totalerrors]≤ϵT
强化学习使用在监督学习去实现时,有一个问题,采取的动作其实决定了你见到的数据,而你使用的数据可能不是严格满足iid的,因此采取了数据里没有的行为进入到数据里没有的状态时,agen就不知道该怎么做了,所以不能泛化。
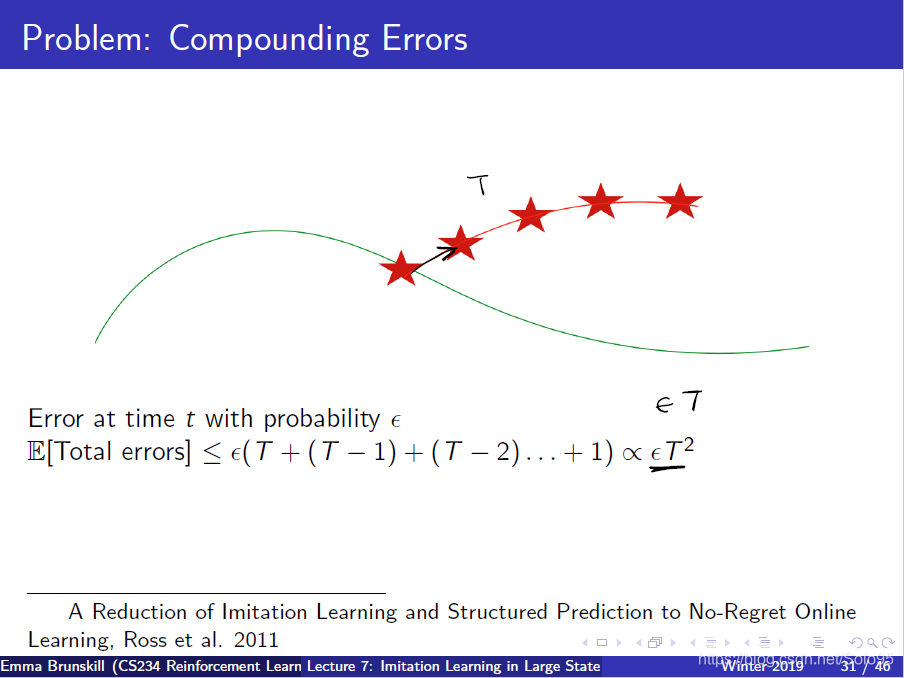
一旦你在一个成功的路径上走错了一步,那么之后的T-1步也都全是错的,而这会在强化学习的过程中重复出现。

数据不匹配问题。
DAGGER: Dataset Aggregation
I
n
i
t
i
a
l
i
z
e
D
←
∅
Initialize \ \mathcal{D} \leftarrow \empty
Initialize D←∅
I
n
i
t
i
a
l
i
z
e
π
^
i
Initialize \hat{\pi}_i
Initializeπ^i to any policy in
Π
\Pi
Π
f
o
r
i
=
1
for \ i=1
for i=1 to
N
N
N do
L
e
t
π
i
=
β
i
π
∗
+
(
1
−
β
i
)
π
^
i
\qquad Let \ \pi_i=\beta_i\pi^*+(1-\beta_i)\hat{\pi}_i
Let πi=βiπ∗+(1−βi)π^i
S
a
m
p
l
e
\qquad Sample
Sample
T
T
T-step trajectories using
π
i
\pi_i
πi
G
e
t
\qquad Get
Get dataset
D
i
=
{
(
s
,
π
∗
(
s
)
)
}
\mathcal{D}_i=\{(s,\pi^*(s))\}
Di={(s,π∗(s))} of visited states by
π
i
\pi_i
πi
A
g
g
r
e
g
a
t
e
\qquad Aggregate
Aggregate datasets:
D
←
D
∪
D
i
\mathcal{D}\leftarrow \mathcal{D} \cup \mathcal{D}_i
D←D∪Di
T
r
a
i
n
\qquad Train
Train classifier
π
^
i
+
1
\hat{\pi}_{i+1}
π^i+1 on
D
\mathcal{D}
D
E
n
d
f
o
r
End \ for
End for
R
e
t
u
r
n
Return
Return best
π
^
i
\hat{\pi}_i
π^i on validation
π ∗ \pi^* π∗专家策略
- 思想:沿着行为克隆计算的策略产生的路径获取更多专家行为的标记数据
- 在约减的分布中获得一个有良好表现得驻点的确定的策略
这假定你有一个专家一直参与其中,这通常是代价非常大的,所以这方面的研究不是很热门。
Inverse Reinforcement Learning
Feature Based Reward Function
Just for your reference. 在很多情况下,其实变迁模型也是未知的,但我们这里假设了变迁模型已知,但其实也有关于在变迁模型未知的条件下的扩展。
- 给定状态空间,动作空间,变迁模型 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a)
- 没有奖励函数 R R R
- 一个或者多个教师证明(demonstrations) ( s 0 , a 0 , s 1 , s 0 , . . . ) (s_0,a_0,s_1,s_0,...) (s0,a0,s1,s0,...)(从教师的策略 π ∗ \pi^* π∗提取出的动作)
- 目标:推测奖励函数 R R R
- 在没有教师策略是最优的假设下,能推断关于
R
R
R的什么?
在没有agent的行为是遵循最优的条件下,无法判断agent采取的行为是好的还是坏的。不能得到任何信息。 - 现在假定教师策略是最优策略。能推断关于
R
R
R的什么?
假定所有的动作回报都是0,那么在这个回报函数下所有的策略都是最优策略,这是最优回报唯一的一个反例。
最优回报不唯一是有Andrew Ng和Stuart Russell在2000年发现的一个问题。
有很多回报函数都和数据相一致。
有很多不同的奖励函数即它们所对应的很多不同的最优策略。所以我们需要打破僵局,引入额外的结构(impose additional structure)。我们尝试在假定专家策略是最优的条件下去推断什么样的回报函数会使得数据看起来是从一个最优策略而来的。
Linear Feature Reward Inverse RL
- 回顾线性价值函数近似
- 同样的,这里考虑当回报在特征上是线性的
- R ( s ) = w T x ( s ) R(s)=\textbf{w}^\Tau x(s) R(s)=wTx(s) where w ∈ R n w \in \mathbb{R}^n w∈Rn, x : S → R n x:S\rightarrow \mathbb{R}^n x:S→Rn
- 目标:在给定一些列证明的条件下找出权重向量 w \textbf{w} w
- 这产生一个策略
π
\pi
π的价值函数,可以表示为
V π = E [ ∑ t = 0 ∞ γ t R ( s t ) ] V^\pi=\mathbb{E}[\sum_{t=0}^{\infty}\gamma^tR(s_t)] Vπ=E[∑t=0∞γtR(st)]
可以重写为:
V
π
=
E
[
∑
t
=
0
∞
γ
t
R
(
s
t
)
∣
π
]
=
E
[
∑
t
=
0
∞
γ
t
w
T
x
(
s
t
)
∣
π
]
=
w
T
E
[
∑
t
=
0
∞
γ
t
x
(
s
t
)
∣
π
]
=
w
T
μ
(
π
)
\begin{aligned} V^\pi=\mathbb{E}[\sum_{t=0}^{\infty}\gamma^tR(s_t)|\pi] & = \mathbb{E}[\sum_{t=0}^{\infty}\gamma^t\textbf{w}^\Tau x(s_t)|\pi] \\ & = \textbf{w}^\Tau\mathbb{E}[\sum_{t=0}^{\infty}\gamma^tx(s_t)|\pi] \\ & = \textbf{w}^\Tau \mu(\pi) \end{aligned}
Vπ=E[t=0∑∞γtR(st)∣π]=E[t=0∑∞γtwTx(st)∣π]=wTE[t=0∑∞γtx(st)∣π]=wTμ(π)
其中
μ
(
π
)
(
s
)
\mu(\pi)(s)
μ(π)(s)被定义为在遵循策略
π
\pi
π下的状态特征的折扣加权频度(frequency)
和之前博文中讨论的驻点分布有关联的地方,但我们现在使用了折扣因子。
使用不同的状态分布来表示不同的策略,这里的不同的策略是针对一个特定的回报函数而言的,它们会到达不同的状态分布。
Apprenticeship Learning
Linear Feature Reward Inverse RL
- 回顾线性价值函数近似
- 同样的,这里考虑当回报在特征上是线性的
- R ( s ) = w T x ( s ) R(s)=\textbf{w}^\Tau x(s) R(s)=wTx(s) where w ∈ R n w \in \mathbb{R}^n w∈Rn, x : S → R n x:S\rightarrow \mathbb{R}^n x:S→Rn
- 目标:在给定一些列证明的条件下找出权重向量 w \textbf{w} w
- 这产生一个策略
π
\pi
π的价值函数,可以表示为
V π = w T μ ( π ) V^\pi=\textbf{w}^\Tau\mu(\pi) Vπ=wTμ(π) - 其中其中 μ ( π ) ( s ) \mu(\pi)(s) μ(π)(s)被定义为在遵循策略 π \pi π下的状态特征的折扣加权频度(frequency)
- 注意
E [ ∑ t = 0 ∞ γ t R ∗ ( s t ) ∣ π ∗ ] = V ∗ ≥ V π = E [ ∑ t = 0 ∞ γ t R ∗ ( s t ) ∣ π ] ∀ π \mathbb{E}[\sum_{t=0}^{\infty}\gamma^tR^*(s_t)|\pi^*]=V^*\geq V^\pi=\mathbb{E}[\sum_{t=0}^{\infty}\gamma^tR^*(s_t)|\pi] \ \forall \pi E[∑t=0∞γtR∗(st)∣π∗]=V∗≥Vπ=E[∑t=0∞γtR∗(st)∣π] ∀π - 因此如果专家的证明是从最优策略而来的,为了找到
w
\textbf{w}
w,以下关于
w
∗
\textbf{w}^*
w∗是充分条件:
w ∗ T μ ( π ∗ ) ≥ w ∗ T μ ( π ) , ∀ π ≠ π ∗ \textbf{w}^{*\Tau}\mu(\pi^*)\geq \textbf{w}^{*\Tau}\mu(\pi),\forall \pi\ne \pi^* w∗Tμ(π∗)≥w∗Tμ(π),∀π=π∗
其实是一个驻点分布,被折扣因子加权。
Feature Matching
这像是在说,我们希望找一个一个回报函数,能满足专家策略和能到达的状态分布在计算价值函数时优于其他分布。所以如果我们找到一个状态分布和专家(策略指定的)的状态相匹配,那么能非常好地实现它。
-
希望找到一个回报函数使得专家策略优于其他策略
-
一个能保证和专家策略 π ∗ \pi^* π∗执行得一样好的策略 π \pi π,能充分证明我们有一个这样的策略,其特征的加权和期望(discounted summed feature expectations)与专家策略相匹配 42 ^{42} 42
-
更确切的,如果
∣ ∣ μ ( π ) − μ ( π ∗ ) ∣ ∣ 1 ≤ ϵ ||\mu(\pi)-\mu(\pi^*)||_1 \leq \epsilon ∣∣μ(π)−μ(π∗)∣∣1≤ϵ
那么对所有满足 ∣ ∣ w ∣ ∣ ∞ ≤ 1 ||w||_{\infty}\leq 1 ∣∣w∣∣∞≤1的 w w w:
∣ w T μ ( π ) − w T μ ( π ∗ ) ∣ ≤ ϵ |w^\Tau\mu(\pi)-w^\Tau\mu(\pi^*)|\leq\epsilon ∣wTμ(π)−wTμ(π∗)∣≤ϵ
μ ( π ∗ ) \mu(\pi^*) μ(π∗)来自证明。
42 ^{42} 42Abbeel and Ng, 2004
这种方式其实是说,我们放弃了寻找真正的回报函数是什么,但是那不要紧,因为我们找到了专家策略。
Apprenticeship Learning
- 以上观点诞生了下面的算法,用于学习一个和专家策略一样好的策略
A s s u m p t i o n : R ( s ) = w T x ( s ) Assumption:R(s)=w^\Tau x(s) Assumption:R(s)=wTx(s)
I n i t i a l i z e Initialize Initialize policy π 0 \pi_0 π0
F o r i = 1 , 2.... For \ i=1,2.... For i=1,2....
F i n d \qquad Find Find a reward function such that the teacher maximally outperforms all previous controllers:
a r g m a x w m a x γ s . t . w T μ ( π ∗ ) ≥ w T μ ( π ) + γ \qquad \mathop{argmax}\limits_{w}\mathop{max}\limits_{\gamma}s.t. w^\Tau\mu(\pi^*)\geq w^\Tau\mu(\pi)+\gamma wargmaxγmaxs.t.wTμ(π∗)≥wTμ(π)+γ ∀ π ∈ π 0 , π 1 , . . . , π i − 1 \forall\pi \in {\pi_0,\pi_1,...,\pi_{i-1}} ∀π∈π0,π1,...,πi−1
s . t . ∣ ∣ w ∣ ∣ 2 ≤ 1 \qquad s.t. \ ||w||_2 \leq 1 s.t. ∣∣w∣∣2≤1
F i n d \qquad Find Find optimal control policy π i \pi_i πi for the current w \textbf{w} w
E x i t i f γ ≤ ϵ / 2 \qquad Exit \ if \ \gamma\leq \epsilon/2 Exit if γ≤ϵ/2
这个算法目前不常用了,所以只是希望你能了解其中的思想。现在大家都用deep neural networks。
- 如果专家策略是次优的那么生成的策略是某种任意策略的混合体,其中包含陷进了凸包(convex hull)的专家策略
- 在实践中:选出一系列中最佳的那一个并选择相应的回报函数
Ambiguity
上述算法也有没解决下面的问题:
- 存在无限多的回报函数,它们都对应最佳策略
- 存在无限多的随机策略,都能匹配到特征计数
- 应该选择哪一个?
Learning from Demonstration / Imitation Learning Pointers
- 许多不同的方法(致力于解决这个问题)
- 两个关键的论文是:
Summary

