

Policy Gradient 算法
常见的policy gradient算法,写出来挺简单的,但是有一个复杂的推导过程,这里就略去了。

Vanilla Policy Gradient Algorithm

G
t
i
G_t^i
Gti可以是TD estimate、bootsrap,也可以是简单的从t开始的reward。
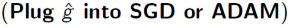
图示即为实现monototic imporvement
G
t
i
=
∑
t
′
=
t
T
r
t
i
G_t^i=\sum_{t'=t}^\Tau r_t^i
Gti=∑t′=tTrti
A
^
t
i
=
G
t
i
−
b
(
s
t
)
\hat{A}_t^i=G_t^i-b(s_t)
A^ti=Gti−b(st)
上面两行是为了更好地得到梯度的估计,在使用少量数据的情况下,并减少variance。
两部分都很重要,实现的是不一样的东西。

R
t
i
^
\hat{R_t^i}
Rti^的计算方式如下:


