C++网络编程
昨天学习了一些C++网络编程的一些相关知识,今天回忆复习一下
1. 相关知识
1.1 局域网和广域网
局域网:局域网将一定区域内的各种计算机、外部设备和数据库连接起来形成计算机通信的私有网络。
广域网:又称广域网、外网、公网。是连接不同地区局域网或城域网计算机通信的远程公共网络。
IP(Internet Protocol):本质是一个整形数,用于表示计算机在网络中的地址。
IP 协议版本有两个:IPv4 和 IPv6
-
IPv4(Internet Protocol version4):
-使用一个 32 位的整形数描述一个 IP 地址,4 个字节,int 型
也可以使用一个点分十进制字符串描述这个 IP 地址: 192.168.247.135
分成了 4 份,每份 1 字节,8bit(char),最大值为 255
0.0.0.0 是最小的 IP 地址
255.255.255.255 是最大的 IP 地址
按照 IPv4 协议计算,可以使用的 IP 地址共有 232 个 -
IPv6(Internet Protocol version6):
使用一个 128 位的整形数描述一个 IP 地址,16 个字节
也可以使用一个字符串描述这个 IP 地址:2001:0db8:3c4d:0015:0000:0000:1a2f:1a2b
分成了 8 份,每份 2 字节,每一部分以 16 进制的方式表示
按照 IPv6 协议计算,可以使用的 IP 地址共有 2128 个 -
端口
端口的作用是定位到主机上的某一个进程,通过这个端口进程就可以接受到对应的网络数据了。
端口也是一个整形数 unsigned short ,一个 16 位整形数,有效端口的取值范围是:0 ~ 65535(0 ~ 216-1) -
OSI/ISO 网络分层模型
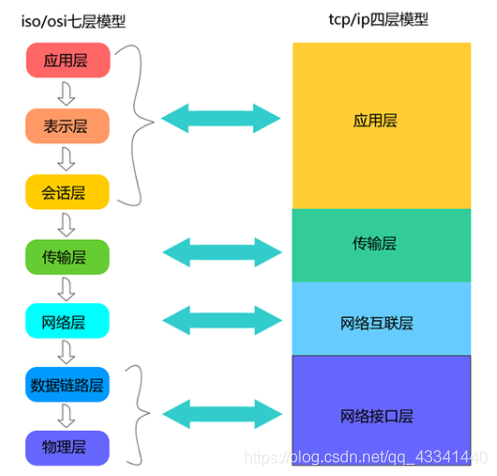
1.2 Socket编程
Socket 套接字由远景研究规划局(Advanced Research Projects Agency, ARPA)资助加里福尼亚大学伯克利分校的一个研究组研发。其目的是将 TCP/IP 协议相关软件移植到 UNIX 类系统中。设计者开发了一个接口,以便应用程序能简单地调用该接口通信。这个接口不断完善,最终形成了 Socket 套接字。Linux 系统采用了 Socket 套接字,因此,Socket 接口就被广泛使用,到现在已经成为事实上的标准。与套接字相关的函数被包含在头文件 sys/socket.h 中。
通过上面的描述可以得知,套接字对应程序猿来说就是一套网络通信的接口,使用这套接口就可以完成网络通信。网络通信的主体主要分为两部分:客户端和服务器端。在客户端和服务器通信的时候需要频繁提到三个概念:IP、端口、通信数据。
2. TCP通信流程
TCP 是一个面向连接的,安全的,流式传输协议,这个协议是一个传输层协议。
- 面向连接:是一个双向连接,通过三次握手完成,断开连接需要通过四次挥手完成。
- 安全:tcp 通信过程中,会对发送的每一数据包都会进行校验,如果发现数据丢失,会自动重传
- 流式传输:发送端和接收端处理数据的速度,数据的量都可以不一致
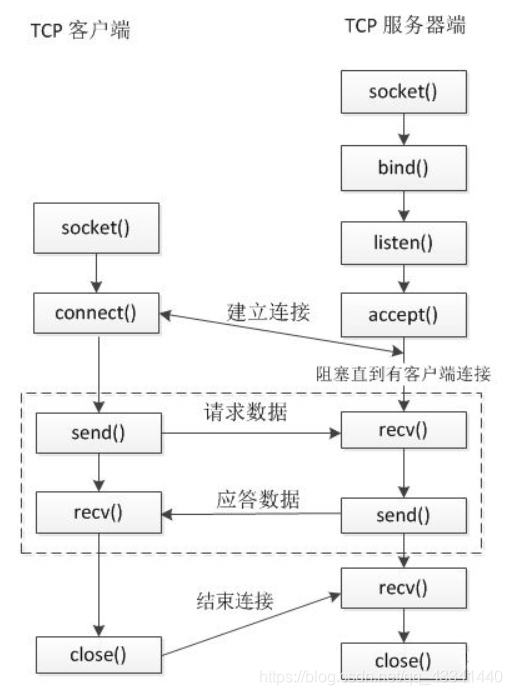
2.1 相关说明
在 tcp 的服务器端,有两类文件描述符
-
监听的文件描述符
只需要有一个
不负责和客户端通信,负责检测客户端的连接请求,检测到之后调用 accept 就可以建立新的连接 -
通信的文件描述符
负责和建立连接的客户端通信
如果有 N 个客户端和服务器建立了新的连接,通信的文件描述符就有 N 个,每个客户端和服务器都对应一个通信的文件描述符
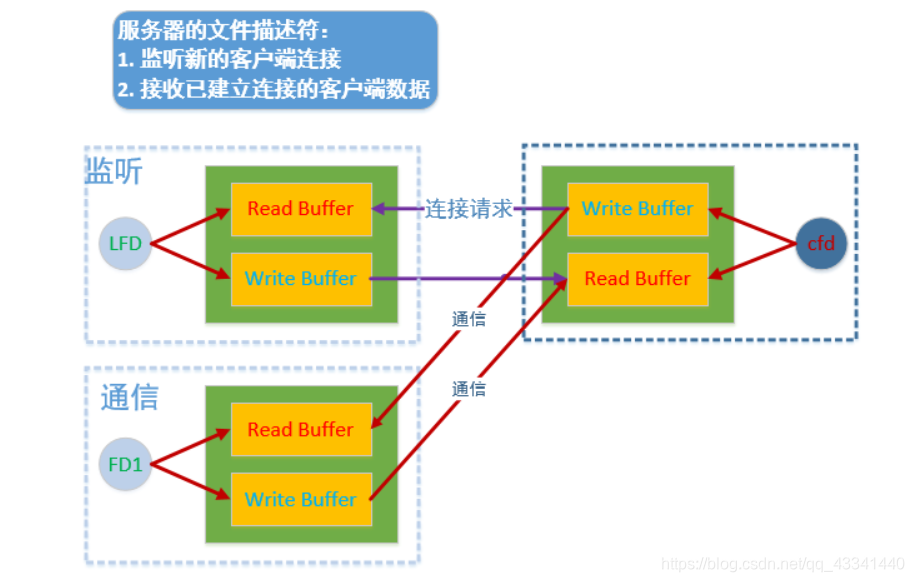
- 文件描述符
说明一下,一个文件文件描述符对应两块内存, 一块内存是读缓冲区, 一块内存是写缓冲区
对于监听的文件描述符而言,它会一直监听文件描述符的读缓冲区,检测不到数据,该函数阻塞,如果有数据,解除阻塞,新的连接建立。
对于通信的文件描述符而言,send()/write()函数,并不是直接将数据发送到网络当中,而且将数据写入到对应的写缓冲区中,当系统内核检测到通信的文件描述符写缓冲区中有数据,内核会将数据发送到网络中,同理,对read()/recv()函数而言也是如此
3. 服务器并发
进程场景下,服务器是无法处理多连接的,解决方案也有很多,常用的有三种:
- 使用多线程实现
- 使用多进程实现
- 使用 IO 多路转接(复用)实现
- 使用 IO 多路转接 + 多线程实现
当我们使用方法四时,服务器的性能会很棒,使用多线程和多进程的区别就是,多线程的性能会更好一些。
然后在底层,不同的线程在栈区做了划分,而在全局数据区和堆区,是可以共同访问的,因此当多个线程访问共享数据的时候,我们就要考虑同步的问题了
然后写这篇文章的时候,我其实是对底层的栈堆不是很懂,特地去学习了一波
3.1 栈,堆
栈是为执行线程留出的内存空间。当函数被调用的时候,栈顶为局部变量和一些 bookkeeping 数据预留块。当函数执行完毕,块就没有用了,可能在下次的函数调用的时候再被使用。栈通常用后进先出(LIFO)的方式预留空间;因此最近的保留块(reserved block)通常最先被释放。这么做可以使跟踪堆栈变的简单;从栈中释放块(free block)只不过是指针的偏移而已。
堆(heap)是为动态分配预留的内存空间。和栈不一样,从堆上分配和重新分配块没有固定模式;你可以在任何时候分配和释放它。这样使得跟踪哪部分堆已经被分配和被释放变的异常复杂;有许多定制的堆分配策略用来为不同的使用模式下调整堆的性能。
每一个线程都有一个栈,但是每一个应用程序通常都只有一个堆(尽管为不同类型分配内存使用多个堆的情况也是有的)。
- 当线程创建的时候,操作系统(OS)为每一个系统级(system-level)的线程分配栈。通常情况下,操作系统通过调用语言的运行时(runtime)去为应用程序分配堆。
- 栈附属于线程,因此当线程结束时栈被回收。堆通常通过运行时在应用程序启动时被分配,当应用程序(进程)退出时被回收。
- 当线程被创建的时候,设置栈的大小。在应用程序启动的时候,设置堆的大小,但是可以在需要的时候扩展(分配器向操作系统申请更多的内存)。
- 栈比堆要快,因为它存取模式使它可以轻松的分配和重新分配内存(指针/整型只是进行简单的递增或者递减运算),然而堆在分配和释放的时候有更多的复杂的 bookkeeping 参与。另外,在栈上的每个字节频繁的被复用也就意味着它可能映射到处理器缓存中,所以很快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号