

(一)Seq2Seq概述
Seq2Seq(Sequence to Sequence,序列到序列模型) 是一种循环神经网络的变种,包括编码器 (Encoder) 和解码器 (Decoder) 两部分,编码器和解码器通常使用RNN结构。
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
RNN 结构及使用
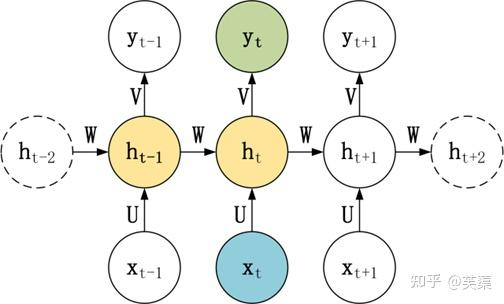
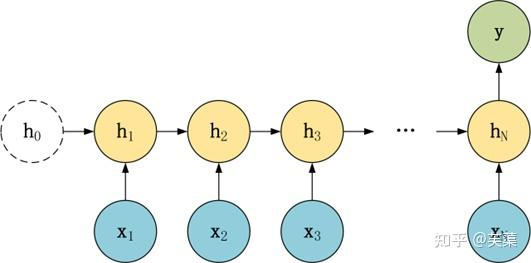
RNN基本的模型如上图所示,每个神经元接受的输入包括:前一个神经元的隐藏层状态h(用于记忆)和当前的输入x(当前信息)。
神经元得到输入之后,会计算出新的隐藏状态h和输出y,然后再传递到下一个神经元。因为隐藏状态h的存在,使得RNN具有一定的记忆功能。
RNN结构变种
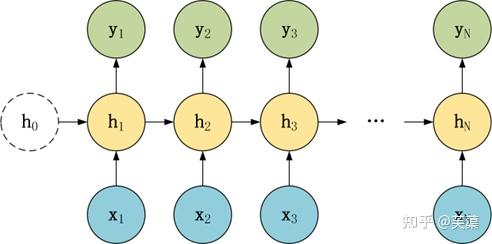
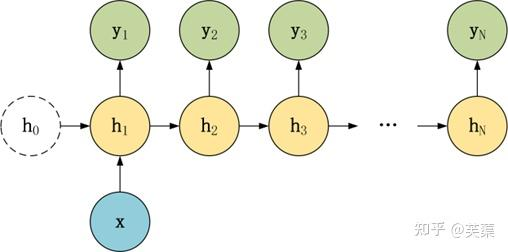
常要对RNN模型结构进行少量的调整,根据输入和输出的数量,分为三种比较常见的结构:N vs N、1 vs N、N vs 1。
N vs N
1 vs N
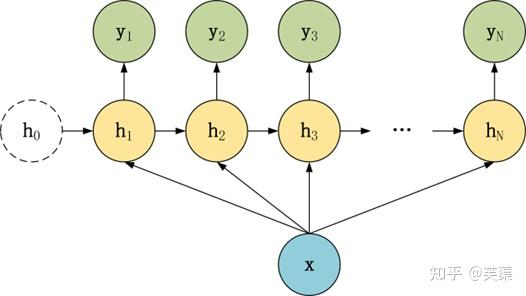
N vs 1
(二)Seq2Seq架构
Seg2Seg架构是一种在自然语言处理只领域中非常重要的模型结构,广泛应用于诸如机器翻译、文本摘要、对话系统等任务。
该架构的核心思想是将输入序列映射为一个中间表示,然后再从这个中间表示生成目标序列。
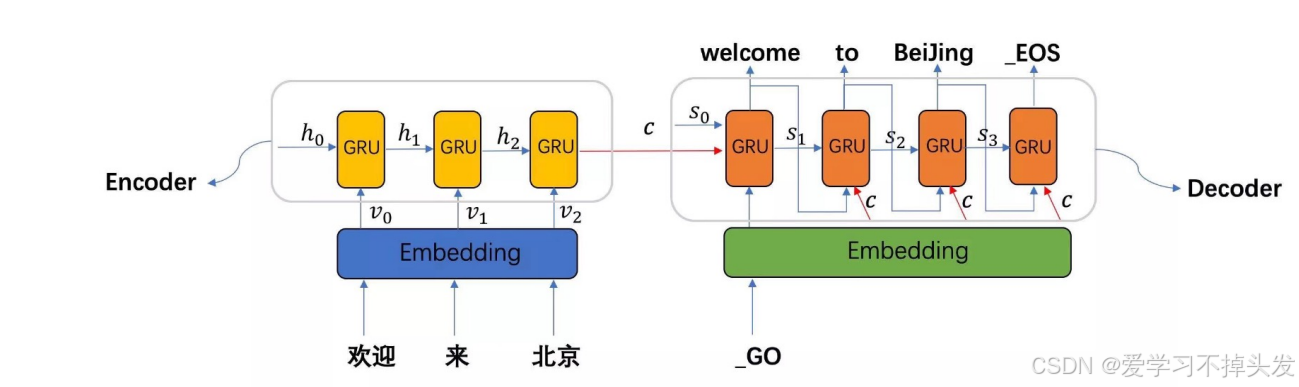
seq2seq模型架构包括三部分,分别是:
- encoder(编码器)
- decoder(解码器)
- c(中间语义张量)
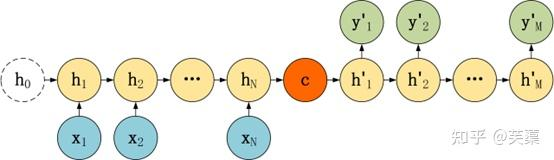
Seq2Seq是一种重要的 RNN 模型,也称为Encoder-Decoder模型,可以理解为一种 N×M 的模型。
模型包含两个部分:Encoder用于编码序列的信息,将任意长度的序列信息编码到一个向量C里。
而Decoder是解码器,解码器得到上下文信息向量C之后可以将信息解码,并输出为序列。
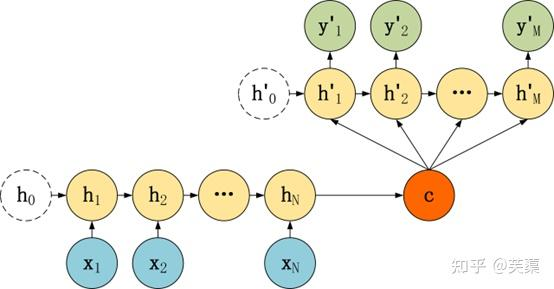
Seq2Seq模型结构有很多种,下面是几种比较常见的:
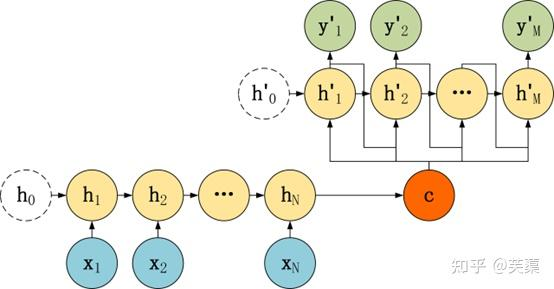
(三)Seq2Seq编解码
Seq2Seq模型的主要区别在于Decoder,它们的Encoder都是一样的。
编码
以下图为例:
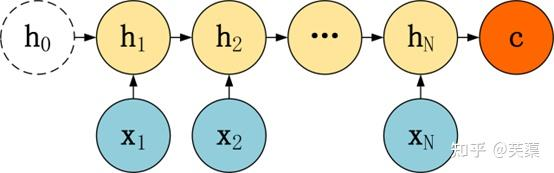
(1)编码器
编码器负责将输入序列(例如一段文本)映射成一个中间的表示,即中间语义张量C,通常是一个固定长度的向量。
常用的编码器结构是循环神经网络(RNN)或者长短时记忆网络(LSTM),近年来也包括了Transformer模型编码器工作流程。
(2)编码器工作流程
对输入的文本序列每个时间步都会产生一个隐藏状态,这些隐藏状态会捕捉到输入序列的信息,并被传递给下一个时刻。
在Seq2Seq中,编码器会将整个输入序列处理完后,最后一个时刻的隐藏状态会被用作解码器的初始隐藏状态。
(3)编码流程
1个时间步1个时间步的编码,每个时间步有隐藏层输出,最终组合成中间语义张量C。
(4)张量计算
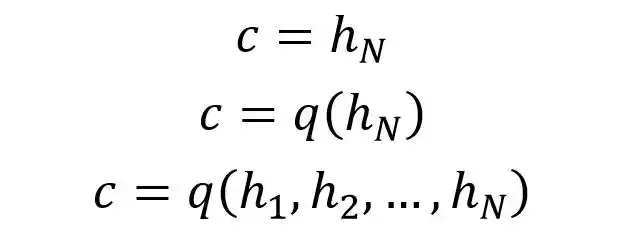
例子中编码器Encoder与一般的RNN区别不大,只是中间神经元没有输出,其中的上下文向量C可以采用多种方式进行计算。
C可以直接使用最后一个神经元的隐藏状态hN表示,也可以在最后一个神经元的隐藏状态上进行某种q函数变换hN而得到,等等。
得到上下文向量C之后,需要传递到Decoder。
解码
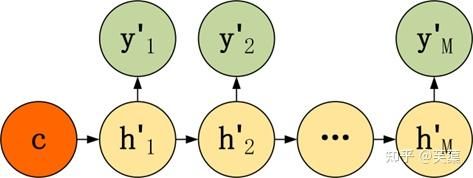
Decoder有多种不同的结构,列举三种:
- 第一种
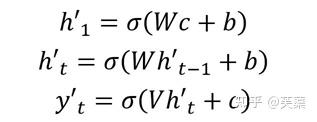
- 第二种
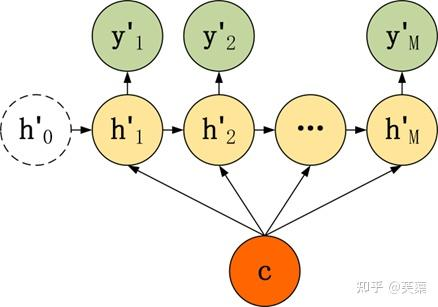
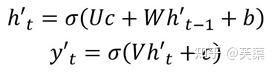
有了自己的初始隐藏层状态h'0,不再把上下文向量C当成是RNN的初始隐藏状态,而是当成RNN每一个神经元的输入。
- 第三种
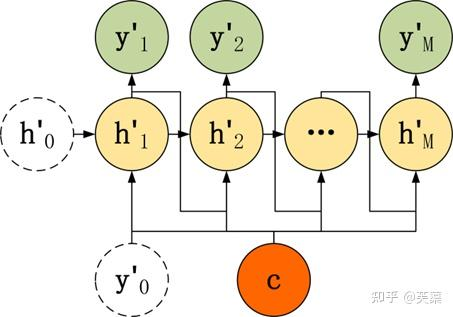
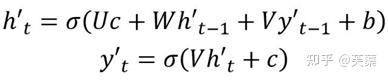
和第二种类似,但是在输入的部分多了上一个神经元的输出y'。即每一个神经元的输入包括:上一个神经元的隐藏层向量h',上一个神经元的输出y',当前的上下文向量输入C。
(1)解码器
解码器接受编码器传递过来的初始隐藏状态,并逐步生成目标序列。
解码器也是一个RNN系列模型,通常会包含一个额外的注意力机制,以便在生成目标序列过程中动态地关注输入席列的不同部分。
(2)解码器的工作流程
一个时间步一个时间步的解码,采用自回归机制进行解码,上一个时间步的输出作为下一个的输入。
每个时间步都会用到中间语义张量C。
(3)解码流程
每个时间步输入input和ht-1,输出output和ht。
再接一个全连接层+softmax做一个分类,从分类结果中找一个预测结果即可。
(四)注意力机制
(1)为什么引入注意力机制
上述的seq2seq看似没有什么问题,其实有一个很大的问题就是使用的是encoder-decoder的结构,我们希望能把不论多长的句子的信息都包含在一个固定的向量C里面去表达。
对于较长的句子,根本没办法包含所有有用的信息;序列较长的时候,梯度消失就会变得明显,尤其是RNN机制实际中存在长程梯度消失的问题。对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降。
如果我们想翻译一个段落,一篇文章,难道我们需要将所有段落都运行encoder到一个常量C,再去翻译这个常量?很明显不是,我们会一句一句地去翻译,我们每次都是注意力集中在一部分去翻译,而且翻译每一句话,也是注意力集中在某几个词汇上的,只使用最后一个神经元得到的向量C效果不理想。
(2)引入注意力机制
接下来就是大名鼎鼎的attention模型了,attention模型就跟人的注意力一样,跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。
如下图所示,当我们翻译“knowedge”时,只需将注意力放在源句中“知识”的部分;当翻译“power”时,只雲将注意力集中在“力量”。这样,当我们decoder预测目标翻译的时候就可以看到encoder的所有信息,而不仅局限于原来模型中定长的隐藏向量,并且不会丧失长程的信息。
换句话说,attention模型并不像前面提到的Encoder的结构一样对整个句子用一个C表征,它对于每个单词都有一个以单词为中心的表征。使用了Attention后,Decoder 的输入就不是固定的上下文向量C了,而是会根据当前翻译的信息计算当前的C。
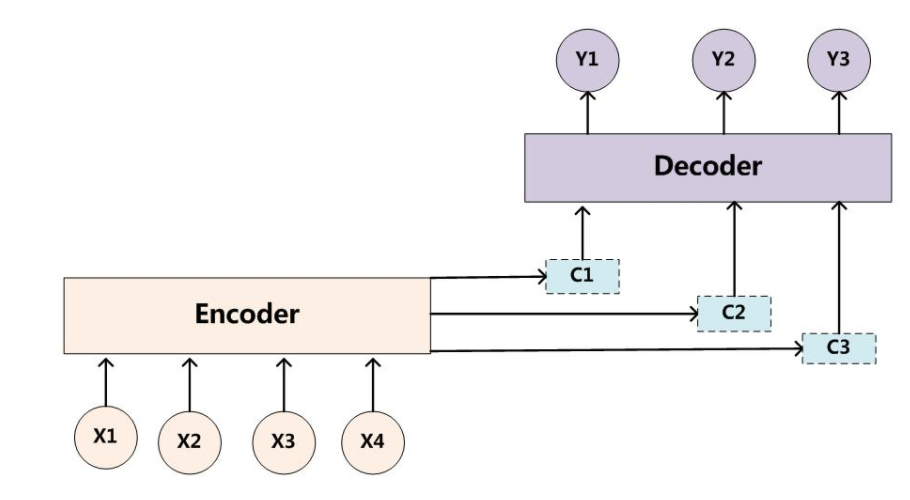
相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息,而且这种方法在翻译任务中取得了非常不错的成果。
(3)引入注意力机制
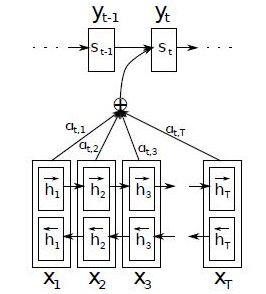
使用了Attention后,Decoder的输入就不是固定的上下文向量C了,而是会根据当前翻译的信息,计算当前的C,如上图显示。
Attention需要保留Encoder每一个神经元的隐藏层向量h,然后Decoder的第t个神经元要根据上一个神经元的隐藏层向量h't-1计算出当前状态与Encoder每一个神经元的相关性et。
神经元相关性et是一个N维的向量(Encoder神经元个数为N),若et的第i维越大,则说明当前节点与Encoder第i个神经元的相关性越大。et的计算方法有很多种,即相关性系数的计算函数a有很多种。
si表示解码器i时刻的隐藏状态,计算公式是
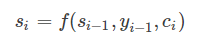
ci是由编码时的隐藏向量序列(h1,…,hTx)按权重相加得到的。
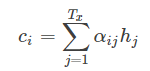
αij又是怎么得到的呢?这个其实是由第i-1个输出隐藏状态si−1和输入中各个隐藏状态共同决定的,也即是
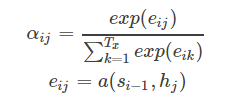
我们现在再把公式按照执行顺序汇总一下:
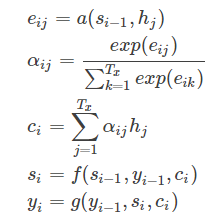
(五)编解码举例
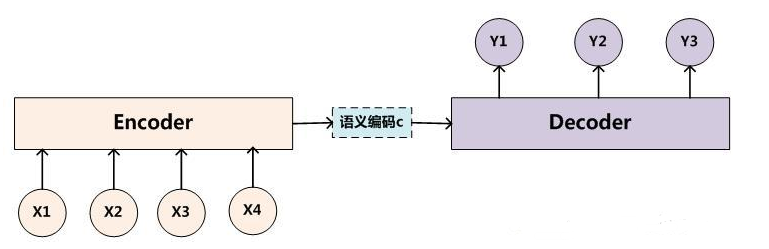
其中,X、Y均由各自的单词序列组成:
X = <x1,x2,...,xm>
Y = <y1,y2,...,yn>
Encoder:是将输入序列通过非线性变换编码成一个指定长度的向量C(中间语义表示)。
C = F(x1,x2,...,xm)
Decoder:是根据向量C(encoder的输出结果)和之前生成的历史信息y1,y2,...,yn来生成i时刻要生成的单词yi。
yi = G(C,y1,y2,...,yn-1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号