

(一)Transformer模型架构
2017 年,Transformer模型使用Self-Attention结构取代了在NLP任务中常用的RNN网络结构。相比RNN网络结构,其最大的优点是可以并行计算。
Transformer的整体模型架构如图所示:
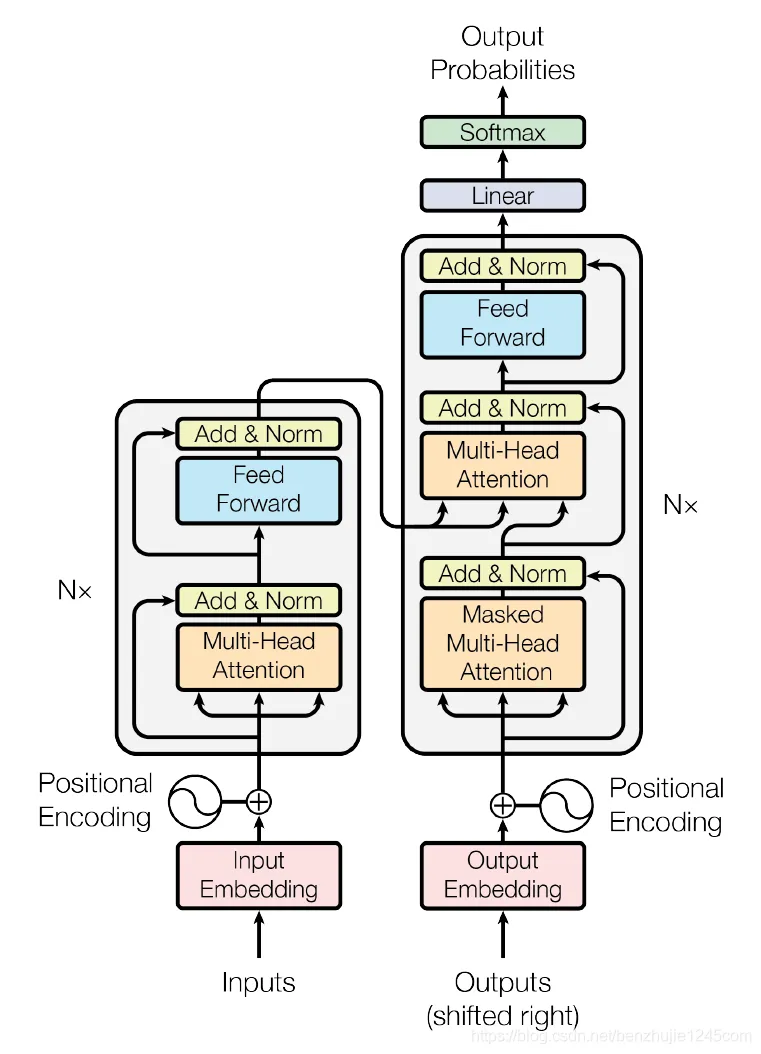
Transformer模型架构
(二)Transformer概述
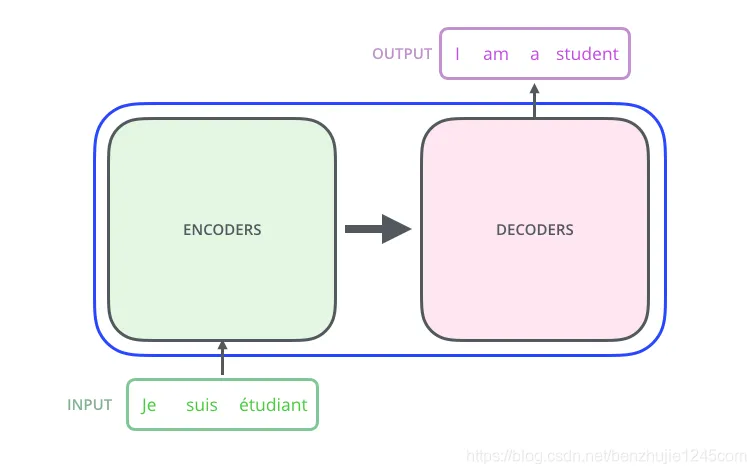
将Transformer模型视为一个黑盒,如图所示。在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出:

Transformer 模型(黑盒模式)
Encoder-Decoder
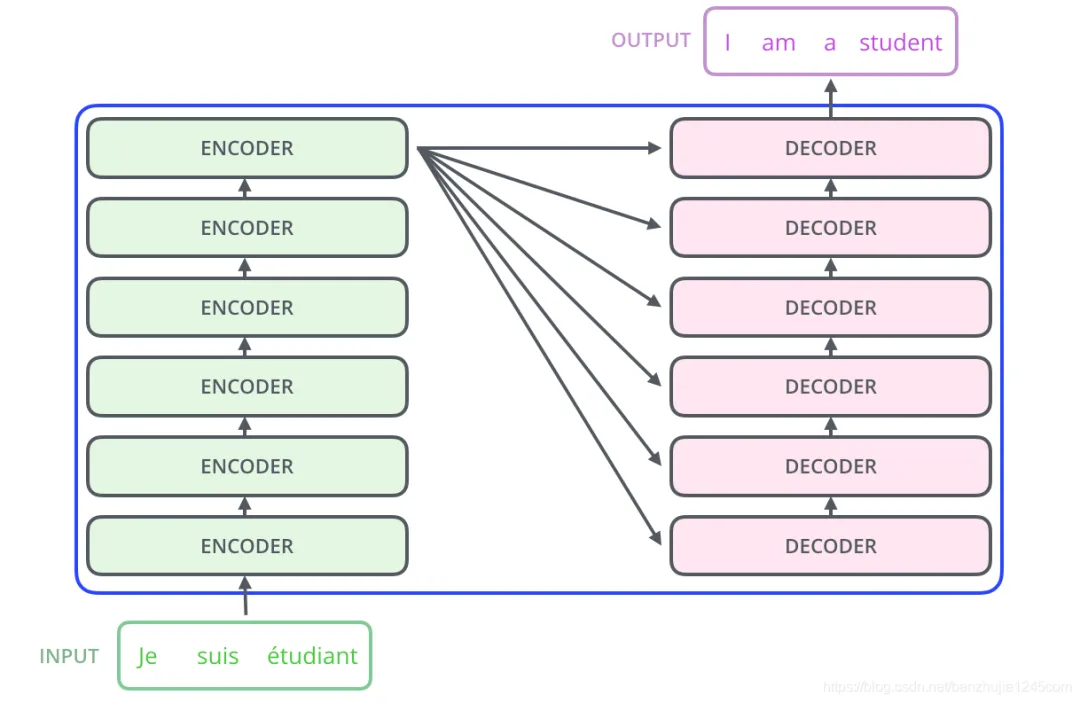
Transformer本质上是一个Encoder-Decoder架构。因此中间部分的Transformer可以分为两个部分:编码组件和解码组件.
Transformer 模型(Encoder-Decoder 架构模式)
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中你可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。
编码器组成
每个编码器由两个子层组成:每个编码器的结构都是相同的,但是它们使用不同的权重参数(6个编码器的架构相同,但是参数不同)
-
Self-Attention层(自注意力层) -
Position-wise Feed Forward Network(前馈网络,缩写为FFN
编码器的输入会先流入 Self-Attention 层,它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息。可以理解为当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息,上下文环境。
然后,Self-Attention 层的输出会流入前馈网络。
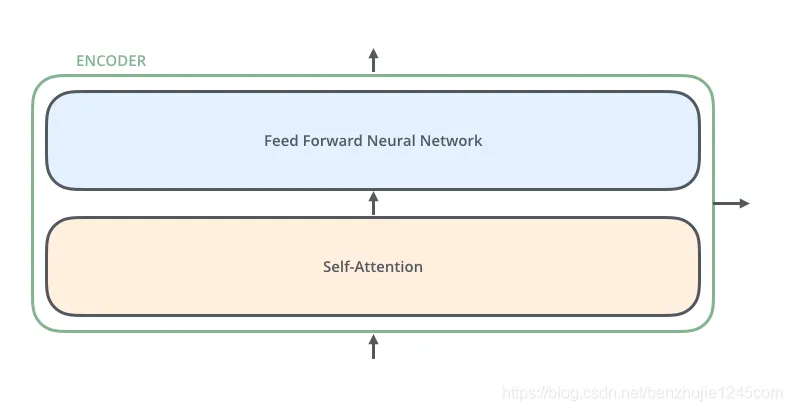
Encoder编码器组成
解码器组成
解码器也有编码器中这两层,但是它们之间还有一个注意力层(即 Encoder-Decoder Attention),其用来帮忙解码器关注输入句子的相关部分(类似于seq2seq模型中的注意力)
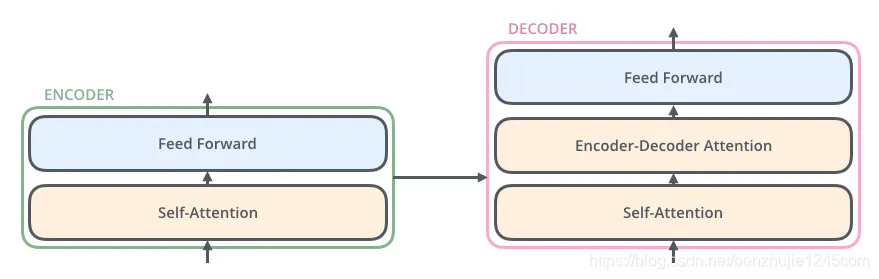
Decoder编码器组成


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」