

介绍:
GPT-4o是OpenAI推出的首个原生多模态模型,能够处理文本、视觉和音频输入,并生成相应的多模态输出。
工作原理:
1)架构
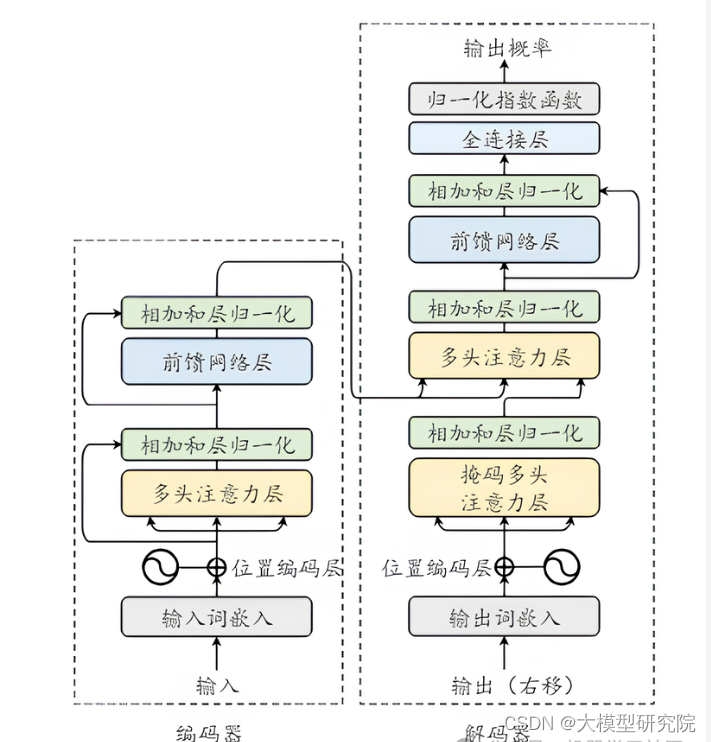
GPT-4o采用多层变换器(Transformer)架构,基于注意力机制(Attention Mechanism)实现高效的语言处理。
2)端到端训练
GPT-4o通过端到端的方式进行训练,这意味着模型从输入到输出的整个过程都在同一个网络中进行。
这种方法允许模型在训练过程中学习到如何在不同模态之间进行信息的无缝转换和融合。训练数据包括大量的文本、图像和音频,确保模型能够有效地处理和生成多模态内容。
3)模态间的信息融合
传统多模态模型通常为不同模态分别设计编码器和解码器,这样容易导致信息融合的效率低下。
而GPT-4o将所有模态的数据统一到一个神经网络只中处理,创新在于其早期融合策略,从训练初期就将所有模态的数据映射到一个共同的表示空间中,使模型能够自然地处理和理解跨模态的信息。
Transformer架构:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号