3月7日学习内容整理:restframework的序列化组件
rest中的序列化组件主要干两件事:
1、序列化queryset类型数据
2.、对请求体的数据进行校验
一、queryset数据的序列化
# 内置的序列化类都在这里面 from rest_framework import serializers
1、自定义序列化类,继承serializers.Serializer
一定要注意,特殊字段例如一对多和多对多字段如何显示
一对多和choices的字段要用到source参数
多对多字段的显示要用到SerializerMethodField类,然后自定义方法显示
from rest_framework import serializers # 这个类是举例只显示model中的普通字段 class RolesSerializer(serializers.Serializer): # 定义要显示的字段,这个字段必须是model中定义的字段,如果 # 在model中没有定义会报错 # 在前端就会以字段名作为key显示 id = serializers.IntegerField() title = serializers.CharField() # 这个类是举例如何显示model中的有choices参数的字段以及一对多和多对多字段 class UserInfoSerializer(serializers.Serializer): xxxxx = serializers.CharField(source="user_type") # row.user_type # 对于有choices参数的字段,要利用source参数,这个参数会先判断参数值是否可调用 # 若可调用则直接加括号执行,所以这里我们用get_字段名_display来获取choices参数 # 数字对应的值 oooo = serializers.CharField(source="get_user_type_display") # row.get_user_type_display() username = serializers.CharField() password = serializers.CharField() # 对于一对多的字段,我们就可以直接使用ORM句点符查询 # 一对多字段.关联表的字段从而显示出我们想要的被关联表的字段值 # 这个gp也就是在前端显示的key,可以取任何值 gp = serializers.CharField(source="group.title") # 对于多对多字段,就不能用source参数了,而是要用到SerializerMethodField,来做自定义显示 # 这里的rls是我们自定义的名字,也就是在前端显示的key rls = serializers.SerializerMethodField() # 自定义显示 # 定义方法,名字必须是get_自定义key,参数row指的就是具体的某个model对象 # 返回的数据完全自定义,我们想显示多对多关联表的什么字段就可以写什么字段 # 返回什么在前端对应key的value就显示什么 def get_rls(self,row): role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret class RolesView(APIView): def get(self,request,*args,**kwargs): # 方式一: # ORM查询得到queryset强转为列表,再进行序列化返回 roles = models.Role.objects.all().values('id','title') roles = list(roles) ret = json.dumps(roles,ensure_ascii=False) # 方式二:对于 [obj,obj,obj,] # ORM查询得到的queryset roles = models.Role.objects.all() # 实例化自定义序列化类 # instance参数就是queryset数据 # many为true代表是多个对象 ser = RolesSerializer(instance=roles,many=True) # 对象.data就是可以进行序列化的数据了,直接json序列化就可以了 ret = json.dumps(ser.data, ensure_ascii=False) # 对于单个的model对象 role = models.Role.objects.all().first() ser = RolesSerializer(instance=role, many=False) # ser.data 已经是转换完成的结果 ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
2、自定义序列化类,继承serializers.ModelSerializer
使用Meta类,对于特殊字段显示仍然要用自定义字段的方法
这里一定要注意depth参数的用法,深度值代表最多找几层的关系去查询
class UserInfoSerializer(serializers.ModelSerializer): oooo = serializers.CharField(source="get_user_type_display") # row.user_type rls = serializers.SerializerMethodField() # 自定义显示 # 需要用到Meta class Meta: # 指定是哪张表 model = models.UserInfo # __all__代表显示所有字段 # fields = "__all__" # 列表形式的话就只显示写好的字段 # 对于其中的一对多多对多choices字段,还是要用自定义字段的方法,列表中就放自定义key fields = ['id','username','password','oooo','rls'] extra_kwargs = { # 这个字段名就必须是model中定义的字段名了 "字段名":{ #这里就可以加一些显示的约束条件 } } # 深度参数,1就代表再往下一层取数据,对于一对多和多对多用这个参数就可以直接返回 # 被关联表的字段值了,这个值不能写太多,范围一般是1-10,但是我们写到3就基本是最大了, # 就不要再往大写了 depth = 1 # 自定义方法显示多对多字段 def get_rls(self, row): role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret class UserInfoView(APIView): def get(self,request,*args,**kwargs): users = models.UserInfo.objects.all() # 仍然实例自定义序列化类,把查询的queryset传过去 # 如果是多个对象many就是true,单个对象many就是false ser = UserInfoSerializer(instance=users,many=True) # 对象.data就可以直接json序列化了 ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
3、不常用,就是自定义字段不使用serializers中的field类,而是用自定义类
class MyField(serializers.CharField): # 自定义字段使用的自定义类,必须有to_representation方法 # 这个方法返回什么就显示什么 # value就是实例化时source参数对应的值 def to_representation(self, value): print(value) return "xxxxx" class UserInfoSerializer(serializers.ModelSerializer): oooo = serializers.CharField(source="get_user_type_display") # row.user_type rls = serializers.SerializerMethodField() # 自定义显示、 # x1这个字段就是用的自定义类 x1 = MyField(source='username') class Meta: model = models.UserInfo # 在fields中写上自定义类的自定义字段 fields = ['id','username','password','oooo','rls','x1' def get_rls(self, row): role_obj_list = row.roles.all() ret = [] for item in role_obj_list: ret.append({'id':item.id,'title':item.title}) return ret class UserInfoView(APIView): def get(self,request,*args,**kwargs): users = models.UserInfo.objects.all() # 仍然实例自定义序列化类,把查询的queryset传过去 # 如果是多个对象many就是true,单个对象many就是false ser = UserInfoSerializer(instance=users,many=True) # 对象.data就可以直接json序列化了 ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
4、restful规范中,对于返回的内容可以有指向别的API的URL链接,这里介绍一种利用类生成链接的方法
class UserInfoSerializer(serializers.ModelSerializer): # 利用HyperlinkedIdentityField这个类 # 参数view_name就是url中设置的name属性值,也就是别名 # 参数lookup_field就是URL中的参数,也就是无名或有名分组中要传的值 # 这个值必须是数据库对应的字段名,不能是ORM查询语句,比如一对多字段 # 就会在model中定义的字段加上_id # 参数lookup_url_kwarg就是url中有名分组的关键字 group = serializers.HyperlinkedIdentityField(view_name='gp',lookup_field='group_id', lookup_url_kwarg='xxx') class Meta: model = models.UserInfo # fields = "__all__" # 写上要写显示的字段 # group就会显示根据别名反向出来的url地址了 fields = ['id', 'username', 'password','group'] depth = 0 # 0 ~ 10 class UserInfoView(APIView): def get(self, request, *args, **kwargs): users = models.UserInfo.objects.all() # 要做反向url地址的话也就是用到HyperlinkedIdentityField这个类 # 实例对象的时候就一定要加上context={'request': request}这个参数 ser = UserInfoSerializer(instance=users, many=True, context={'request': request}) ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
二、对请求体数据进行校验
1、代码
# 自定义校验类 class XXValidator(object): def __init__(self, base): self.base = base # 数据一提交过来就会调用__call__方法 # vlaue就是提交过来的值 def __call__(self, value): if not value.startswith(self.base): message = '标题必须以 %s 为开头。' % self.base raise serializers.ValidationError(message) def set_context(self, serializer_field): """ This hook is called by the serializer instance, prior to the validation call being made. """ # 执行验证之前调用,serializer_fields是当前字段对象 pass class UserGroupSerializer(serializers.Serializer): # error_messages就是对应的错误提示什么 # validators参数是自定义校验规则 title = serializers.CharField( error_messages={'required': '标题不能为空'}, validators=[XXValidator('老男人'), ] ) class UserGroupView(APIView): def post(self, request, *args, **kwargs): # 实例话对象时要把解析器分析完的数据传过去 ser = UserGroupSerializer(data=request.data) # is_valid方法就是进行校验 if ser.is_valid(): # validated_data就是所有校验通过的数据,是一个有序字典OrderedDict print(ser.validated_data['title']) else: # errors就是错误信息 print(ser.errors) return HttpResponse('提交数据')
2、钩子函数
class UserGroupSerializer(serializers.Serializer): title = serializers.CharField( error_messages={'required':'标题不能为空'}, validators=[XXValidator('老男人'),]) # 钩子函数,必须以validate_字段名来命名,这里的字段名是上面的自定义字段名title # 传入参数value就代表的是该字段对应的字段值 def validate_title(self, value): from rest_framework import exceptions # 当校验不合格时就抛这个异常 raise exceptions.ValidationError('看你不顺眼') # 校验合格时就把字段值返回 return value
三、源码流程:
注意对于多个对象也就是many=true时实际是调用ListSerializer处理
对于单个对象实际是调用Serializer处理
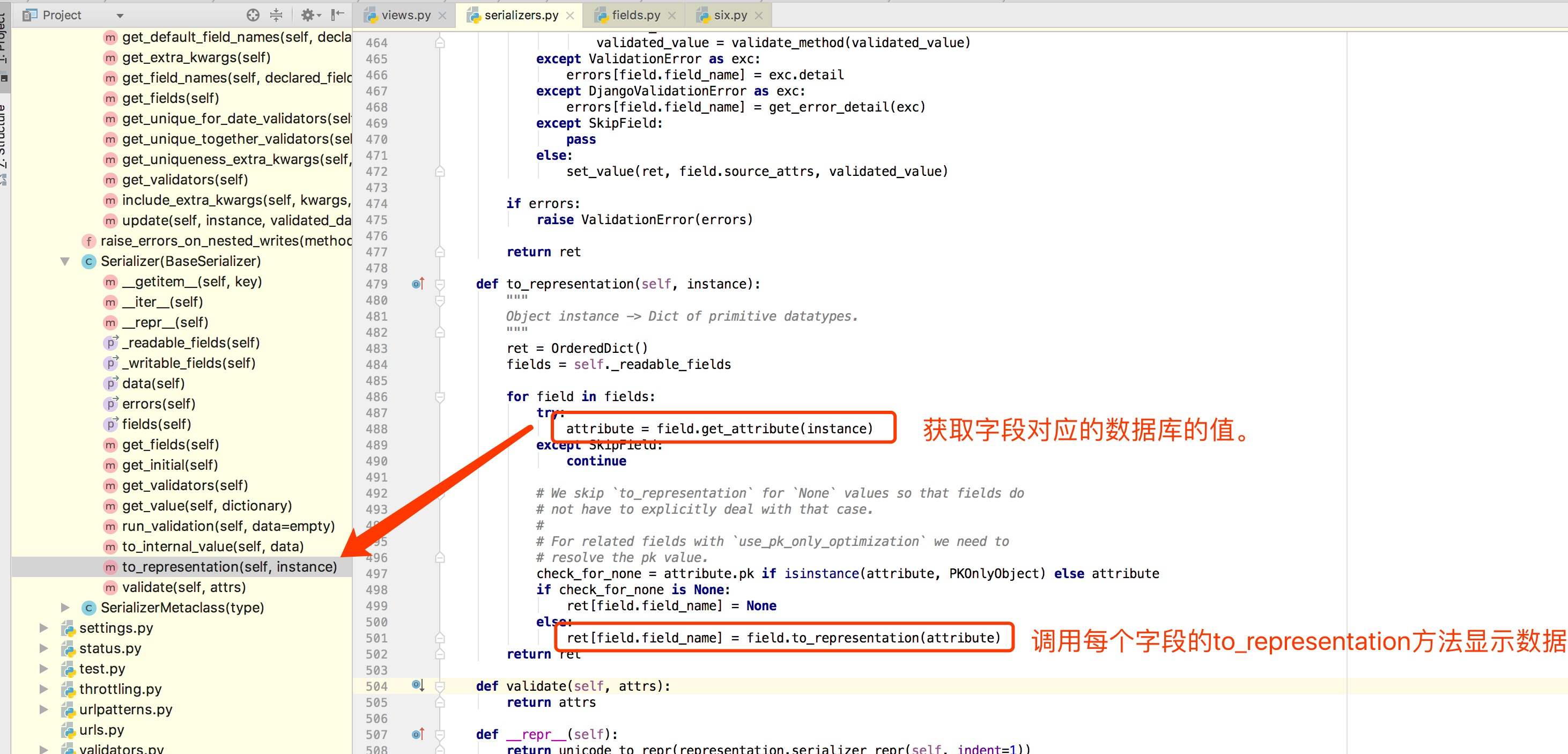
都是执行to_representation方法
以自定义序列化类的对象的data方法为入口
先是执行BaseSerializer的data方法,其中会调用to_representation的方法,也就是自定义序列化类的to_representation方法,没有的话就去找继承类的,以ModelSerializer为例,没有,再找继承,实际执行的是Serializer的to_representation方法,如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号