【go语言】错误处理
1. sentinel error
预定义的特定错误,我们叫为 sentinel error,这个名字来源于计算机编程中使用一个特定值来表示不可能进行进一步处理的做法。所以对于 Go,我们使用特定的值来表示错误。
if err == ErrSomething { … }
类似的 io.EOF,更底层的 syscall.ENOENT。
使用 sentinel 值是最不灵活的错误处理策略,因为调用方必须使用 == 将结果与预先声明的值进行比较。当您想要提供更多的上下文时,这就出现了一个问题,因为返回一个不同的错误将破坏相等性检查。
甚至是一些有意义的 fmt.Errorf 携带一些上下文,也会破坏调用者的 == ,调用者将被迫查看 error.Error() 方法的输出,以查看它是否与特定的字符串匹配。
不依赖检查 error.Error 的输出。
- 不应该依赖检测 error.Error 的输出,Error 方法存在于 error 接口主要用于方便程序员使用,但不是程序(编写测试可能会依赖这个返回)。这个输出的字符串用于记录日志、输出到 stdout 等。
- Sentinel errors 成为你 API 公共部分。
如果您的公共函数或方法返回一个特定值的错误,那么该值必须是公共的,当然要有文档记录,这会增加 API 的表面积。 如果 API 定义了一个返回特定错误的 interface,则该接口的所有实现都将被限制为仅返回该错误,即使它们可以提供更具描述性的错误。 比如 io.Reader。像 io.Copy 这类函数需要 reader 的实现者比如返回 io.EOF 来告诉调用者没有更多数据了,但这又不是错误。
- Sentinel errors 在两个包之间创建了依赖
sentinel errors 最糟糕的问题是它们在两个包之间创建了源代码依赖关系。例如,检查错误是否等于 io.EOF,您的代码必须导入 io 包。这个特定的例子听起来并不那么糟糕,因为它非常常见,但是想象一下,当项目中的许多包导出错误值时,存在耦合,项目中的其他包必须导入这些错误值才能检查特定的错误条件(in the form of an import loop)。
- 结论: 尽可能避免 sentinel errors。
我的建议是避免在编写的代码中使用 sentinel errors。在标准库中有一些使用它们的情况,但这不是一个您应该模仿的模式。
2. Error types
Error type 是实现了 error 接口的自定义类型。例如 MyError 类型记录了文件和行号以展示发生了什么。
package main
import "fmt"
type MyError struct {
Msg string
File string
Line int
}
func (e *MyError) Error() string {
return fmt.Sprintf("%s:%d: %s", e.File, e.Line, e.Msg)
}
func test() error {
return &MyError{"Something happend", "server.go", 22}
}
func main() {
err := test()
switch err := err.(type) {
case nil:
fmt.Printf("没有错误")
// call success
case *MyError:
fmt.Println("error occurred on line:", err.Line)
default:
//unknown error
}
}因为 MyError 是一个 type,调用者可以使用断言转换成这个类型,来获取更多的上下文信息。
与错误值相比,错误类型的一大改进是它们能够包装底层错误以提供更多上下文。 一个不错的例子就是 os.PathError 他提供了底层执行了什么操作、那个路径出了什么问题。
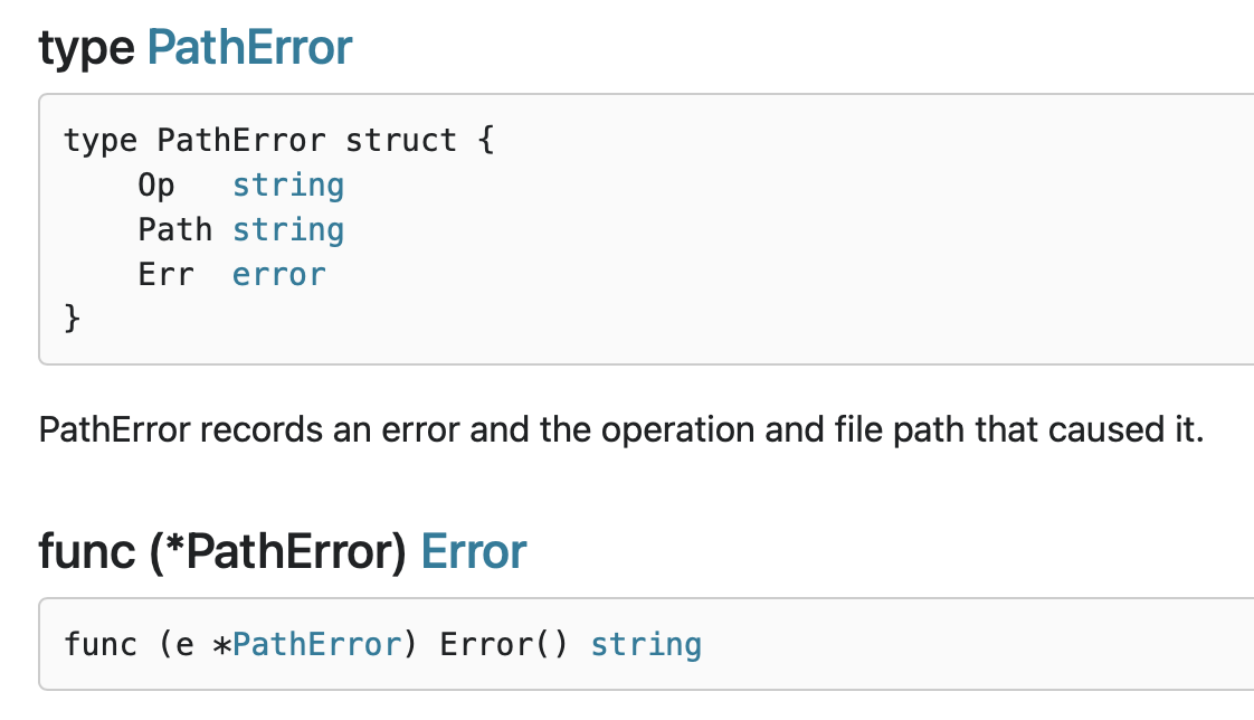
调用者要使用类型断言和类型 switch,就要让自定义的 error 变为 public。这种模型会导致和调用者产生强耦合,从而导致 API 变得脆弱。 结论是尽量避免使用 error types,虽然错误类型比 sentinel errors 更好,因为它们可以捕获关于出错的更多上下文,但是 error types 共享 error values 许多相同的问题。 因此,我的建议是避免错误类型,或者至少避免将它们作为公共 API 的一部分。
3. Opaque errors
不透明的error处理
在我看来,这是最灵活的错误处理策略,因为它要求代码和调用者之间的耦合最少。 我将这种风格称为不透明错误处理,因为虽然您知道发生了错误,但您没有能力看到错误的内部。作为调用者,关于操作的结果,您所知道的就是它起作用了,或者没有起作用(成功还是失败)。
这就是不透明错误处理的全部功能–只需返回错误而不假设其内容。
缺点:拿不到错误的上下文,只能拿到一些字符串
1. Assert errors for behaviour, not type
在少数情况下,这种二分错误处理方法是不够的。例如,与进程外的世界进行交互(如网络活动),需要调用方调查错误的性质,以确定重试该操作是否合理。在这种情况下,我们可以断言错误实现了特定的行为,而不是断言错误是特定的类型或值。考虑这个例子:
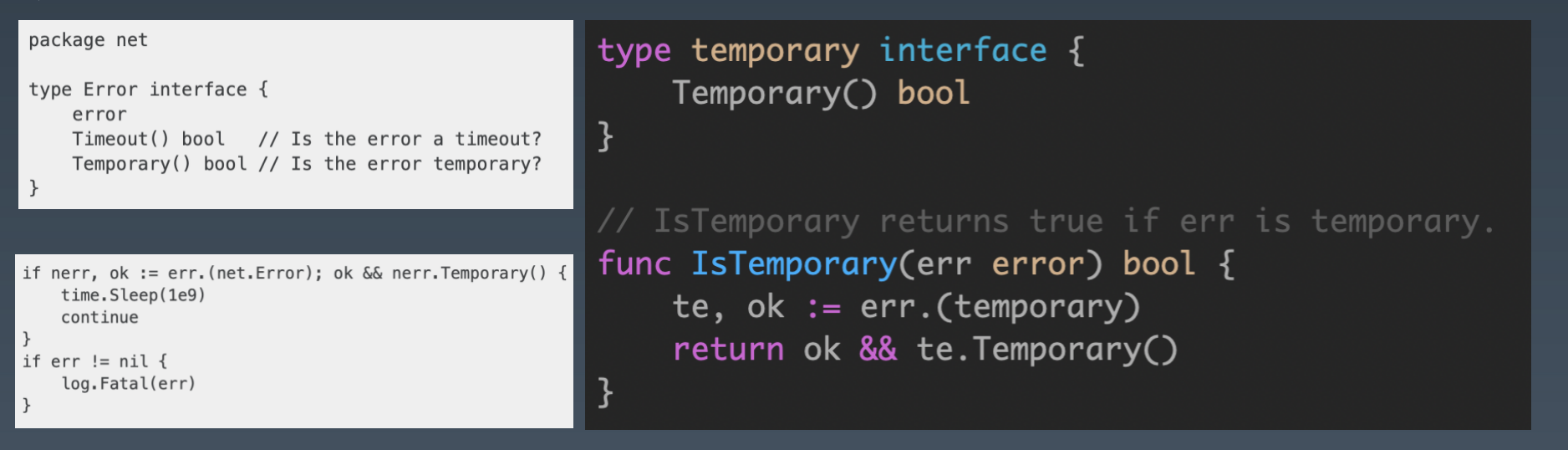
这里的关键是,这个逻辑可以在不导入定义错误的包或者实际上不了解 err 的底层类型的情况下实现——我们只对它的行为感兴趣。
3. Handling Error
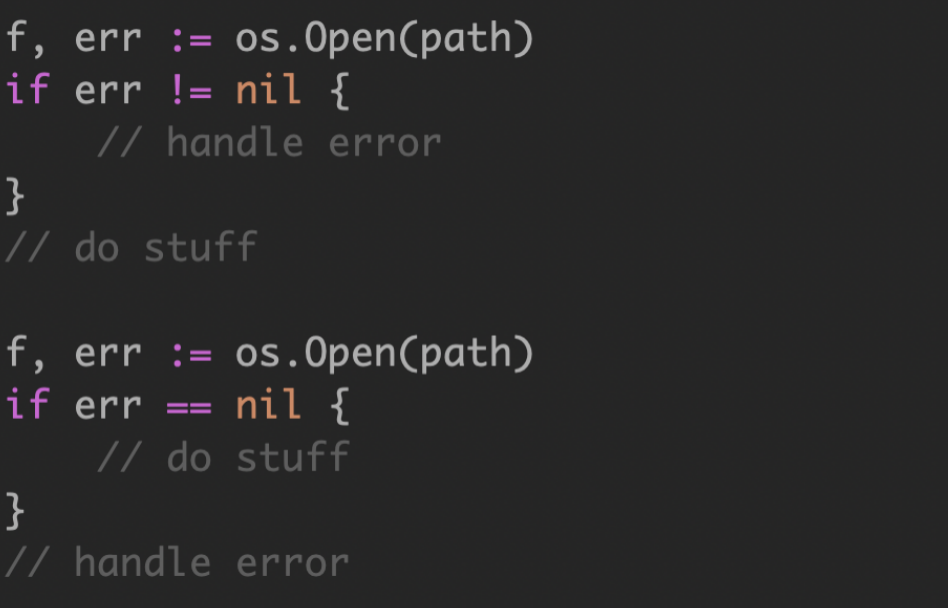
1. Indented flow is for errors
无错误的正常流程代码,将成为一条直线,而不是缩进的代码。
2. Eliminate error handling by eliminating errors
下面的代码有啥问题?
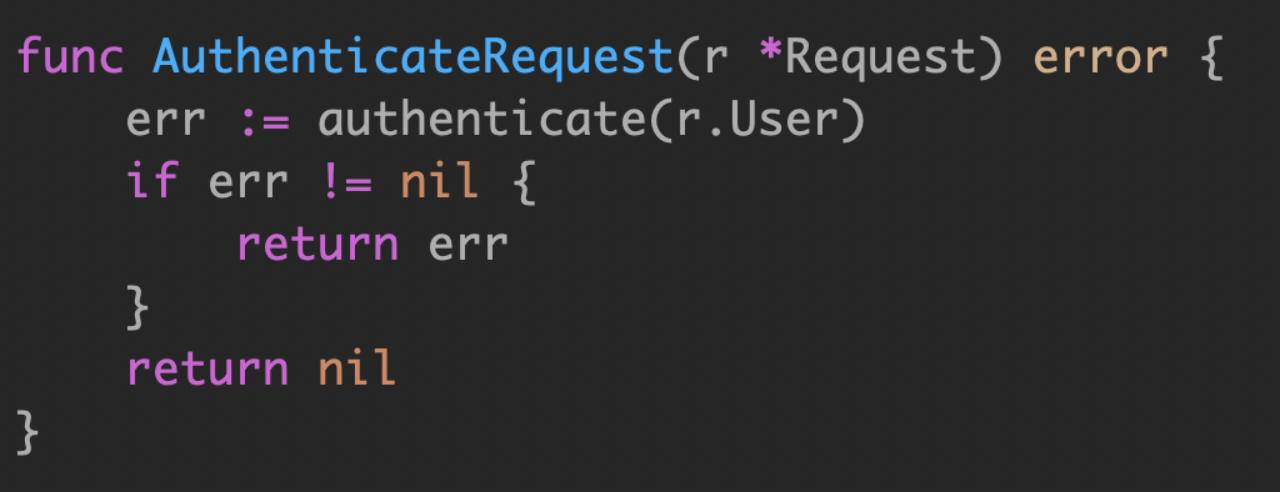
直接可以这样写啊
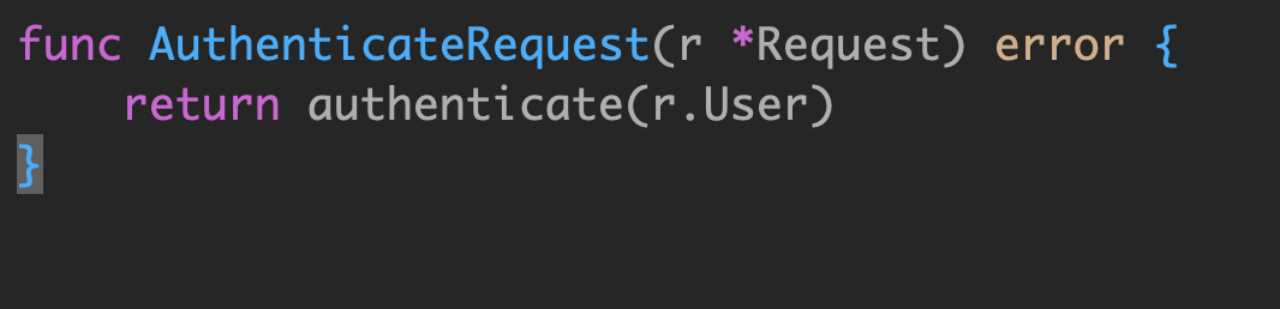
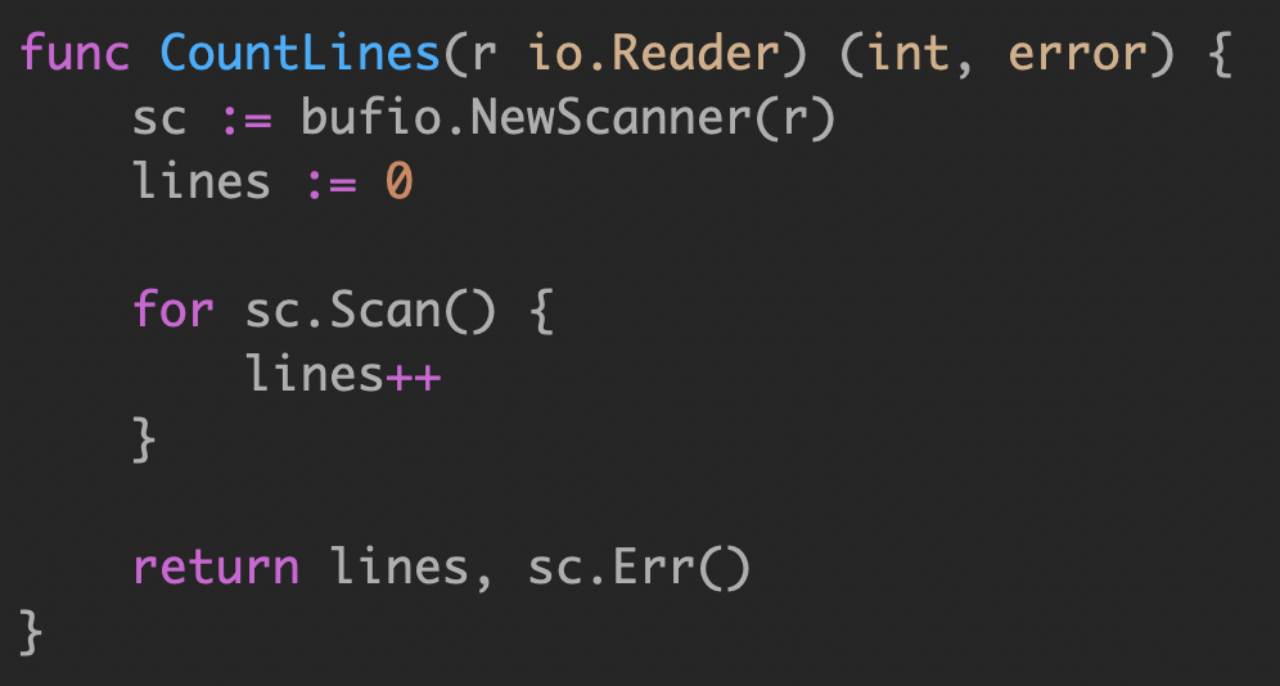
统计 io.Reader 读取内容的行数 :

改进版本:
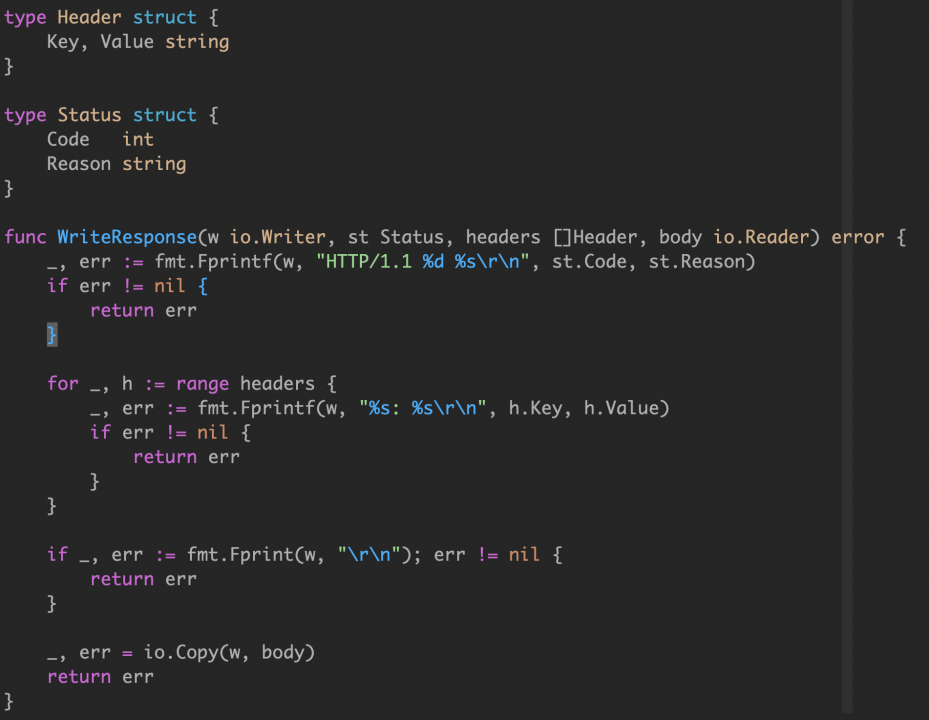
再来看一组
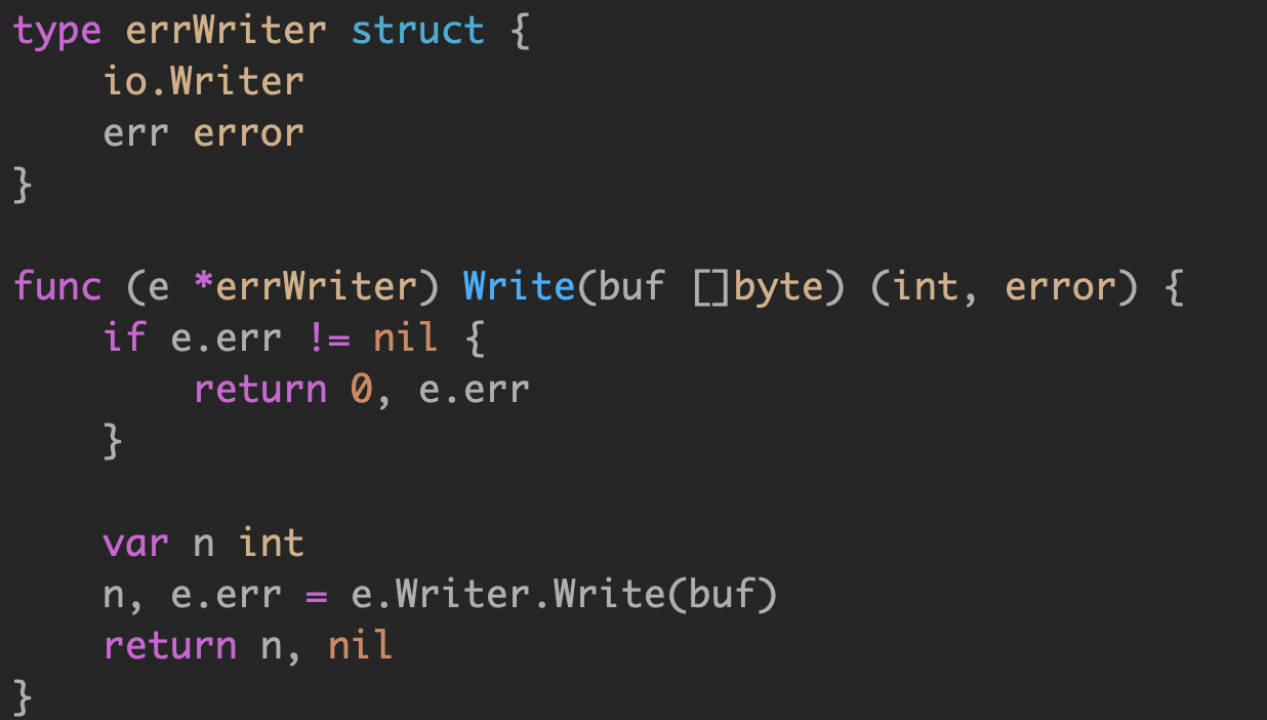
改进后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号