pod
生命周期
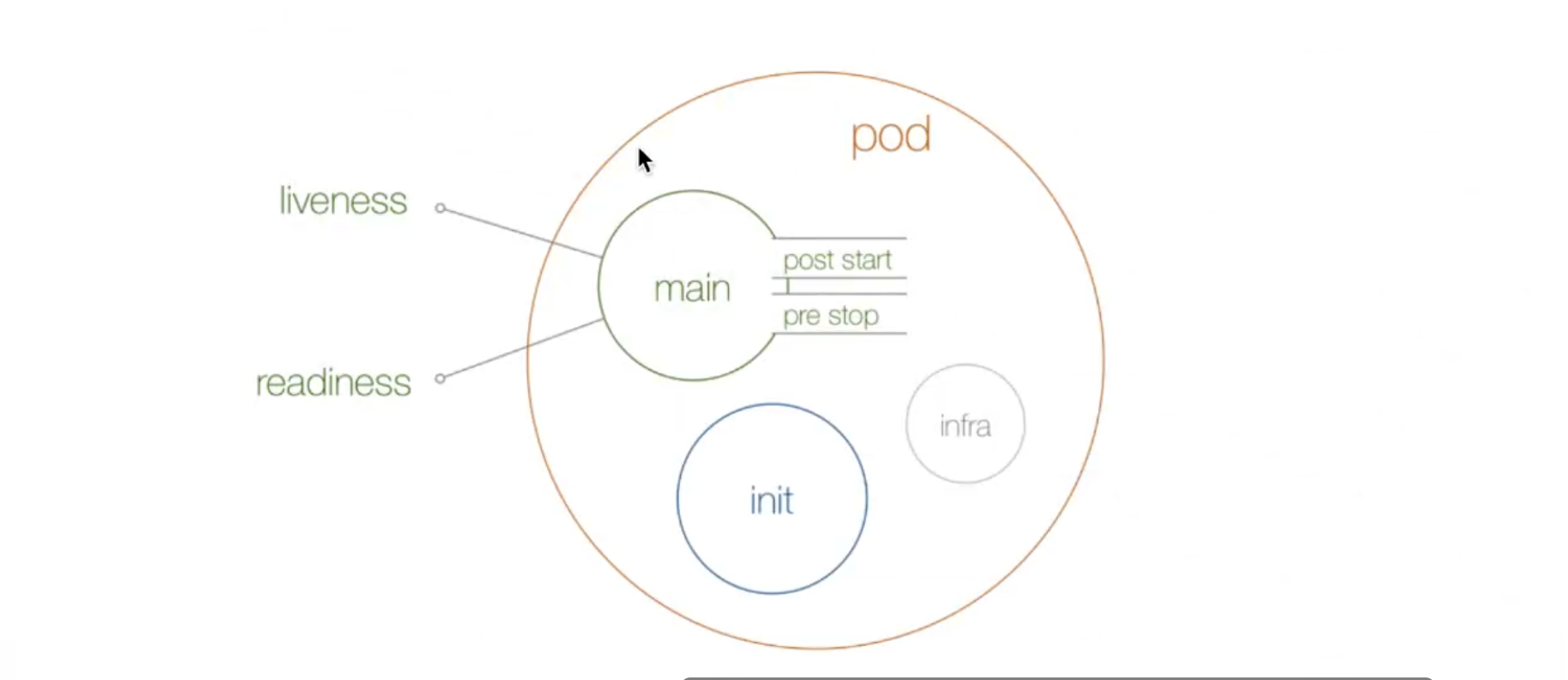
1. 强制删除
kubectl delete pod hook-demo1 --force --grace-period=0
默认所有的优雅退出时间都在30秒内。kubectl delete 命令支持 --grace-period=<seconds>选项,这个选项允许用户用他们自己指定的值覆盖默认值。值’日•代表强制删除pod。 在kubectl 1.5 及以上的版本里,执行强制删除时必须同时指定--force --grace-period=0.
强制删除一个 pod 是从集群状态还有etcd 里立刻删除这个 pod,只是当Pod 被强制删除时, APIServer 不会等待来自Pod 所在节点上的kubelet的确认信息:pod 己经被终止。在API 里pod 会被立刻删除,在节点上,pods 被设置成立刻终止后,在强行杀掉前还会有一个很小的宽限期,
以下示例中,定义了一个Nginx pod,其中设置了prestop钩子西数,即在容器退出之前,优雅的关闭 Nginx: (pod-prestop. yaml)

apiVersion: v1
kind: Pod
metadata:
name: hook-demo2
namespace: default
spec:
containers:
- name: hook-demo2
image: nginx:latest
lifecycle:
preStop:
exec:
command: ["/user/sbin/nginx", "-s", "quit"]
---
apiVersion: v1
kind: Pod
metadata:
name: hook-demo3
spec:
volumes:
- name: message
hostPath:
path: /tmp
containers:
- name: hook-demo2
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: message
mountPath: /usr/share/
lifecycle:
preStop:
exec:
command: ['/bin/sh', '-c', "echo Hello from the preStop Handler > /usr/share/message"]
2. 健康检查
现在在Pod 的整个生命周期中,能影响到Pod 的就只剩下健康检查这一部分了。在Kubernetes 集群当中,我们可以通过配置1iveness probe(存活探针)和readiness probe (可读性探针) 来影响容器的生命周期:
-
kubelet 通过使用 liveness probe 来确定你的应用程序是否正在运行,通俗点将就是是否还活着。一般来说,如果你的程序一旦崩溃了,Kubernetes 就会立刻知道这个程序已经终止了,然后就会重启这个程康。而我们的liveness probe 的目的就是来捕获到当前应用程序还没有终止,还没有崩溃,如果出现了这些情况,那么就重启处于该状态下的容器,使应用程序在存在 bug 的情况下依然能够继续运行下去。
- kubelet 使用 readiness probe 来确定容器是否已经就绪可以接收流量过来了。这个探针通俗点讲就是说是否准备好了,现在可以开始工作了。只有当Pod 中的容器都处于就绪状态的时候 kubelet 才会认定该pod 处于就绪状态,因为-个pod 下面可能会有多个容器。当然Pod 如果处于非就绪状态,那么我们就会将他从 service 的Endpoints列表中移除出来,这样我们的流量就不会被路由到这个 Pod 里面来了。
和前面的钩子函数一样的,我们这两个探针的支持下面几种配置方式:
- exec:执行一段命令
- http:检测某个http 请求
- tcpsocket:使用此配置,kubelet 将尝试在指定端口上打开容器的套接字。如果可以建立连接,容器被认为是健康的,如果不能就认为是失败的。实际上就是检查端口。
我们先来给大家演示下存活探针的使用方法,首先我们用exec 执行命令的方式来检测容器的存活,如下:(liveness-exec.yaml)
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- C
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5 # 每隔5秒去执行
successThreshold: 1
failureThreshold: 3 # 失败几次
timeoutSeconds: 1 # 超市时间
我们这里需要用到一个新的属性: IivenessProbe,下面通过 exec 执行一段命令:
- periodseconds :表示让 kubelet 每隔5秒执行一次存活探针,也就是每5秒执行一次上面的cat /tmp/healthy命令,如果命令执行成功了,将返回0,那么kubelet 就会认为当前这个容器是存活的,如果返回的是非日值,那么kubelet 就会把该容器杀掉然后重启它。默认是10秒,最小1秒。
- initialDelay Seconds:表示在第一次执行探针的时候要等待5秒,这样能够确保我们的容器能够有足够的时间启动起来。大家可以想象下,如果你的第一次执行探针等候的时间太短,是不是很有可能容器还没正常启动起来,所以存活探针很可能始终都是失败的,这样就会无休止的重启下去了,对吧?
意思是说在容器最开始的30秒內创建了一个/tmp/healthy文件,在这30秒内执行cat /tmp/healtoy命令都会设尚二不成功的返回码。30 秒后,我们删除这个文件,现在执行cat /tmp/healthy是不是就会失败了(默认检测失败3次才认为失败),所以这个时候就会重启容器了。
我们来创建下该 Pod,然后在 30 秒内,查看pod 的Event:
kubectl apply -f liveness-exec.yaml
kubectl describe pod liveness-exec
同样的,我们还可以使用HTTP GET 请求来配置我们的存活探针,我们这里使用一个 liveness 镜像来验证演示下:(liveness-http.yaml)
apiVersion: v1
kind: Pod
metadata:
name: liveness-http
spec:
containers:
- name: liveness
image: cnych/liveness
args:
- /server
livenessProbe:
httpGet:
path: /health
port: 8080
httpHeaders:
- name: X-Custom-Geader
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
同样的,根据 periodseconds 属性我们可以知道kubelet 需要每隔3秒执行一次liveness probe, 该探针特向容器中的server 的 808日 端口发送-个HTTP GET 请求。如果server 的/healthz 路径的 handler 返回-个成功的返回码,kubelet 就会认定该容器是活着的并且很健康,如果返回失败的返回码,kubelet 将杀掉该容器并重启它。
initialDelayseconds 指定kubelet 在该执行第一次探测之前需要等待3秒钟。
通常来说,任何大于^200°小于‘400^的状态码都会认定是成功的返回码。其他返回码都会被认为是失败的返回码。
我们可以来查看下上面的healthz 的实现:
http.HandleFunc("/healthz", func(w http.ResponseWriter, r *http.Request) {
duration := time.Now Isub(started)
if duration. Seconds() > 10 {
w.WriteHeader(500)
w.Write([]byte(fmt.Sprintf("error: %v", duration.Seconds())))
} else {
w.WriteHeader(200)
w.Write ([]byte( "ok"))
}
})
除了上面的 exec 和httpGet 两种检测方式之外,还可以通过 tcpSocket 方式来检测端口是否正常,大家可以按照上面的方式结合kubectl explain命令自己来验证下这种方式。
另外前面我们提到了探针里面有一个initialDelaySeconds的属性,可以来配置第一次执行探针的等待时间,对于启动非常慢的应用这个参数非常有用,比如Jenkins、Gitlab 这类应用,但是如何设置一个合适的初始延迟时间呢?这个就和应用具体的环境有关系了,所以这个值往往不是通用的,这样的话可能就会导致一个问题,我们的资源清单在别的环境下可可能就会健康检查失败了,为解決这个问题,在kubernetes v1.16 版本官方特地新增了一个 startupProbe(启动探针),该探针将推迟所有其他探针,直到 Pod 完成启动为止,使用方法和存活探针一样:

比如上面这里的配置表示我们的慢速容器最多可以有5分钟 (30个检查 * 10秒=300s)来完成启动。
有的时候,应用程序可能暂时无法对外提供服务,例如,应用程序可能需要在启动期间加载大量数据或配置文件。在这种情况下,您不想杀死应用程序,也不想对外提供服务。那么这个時候我们就可以使用readiness probe来检测和减轻这些Pod 中的容器可以报告自己还没有准备,不能处理 Kubernetes 服务发送过来的流量。readiness probe的配置跟liveness probe基本上一致的。唯一的不同是使用readinessProbe而不是livenessProbe。两者如果同时使用的话就可以确保流量不会到达还末准备好的容器,准备好过后,如果应用程序出现了错误,则会重新启动容器。对于就绪探针我们会在后面 service 的章节和大家继续介绍,
另外除了上面的initialDelayseconds和period Seconds属性外,探针还可以配置如下几个参数:
- tineoutSeconds:探测超时时间,默认1秒,最小1秒。
- success Threshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1,但是如果是liveness则必须是1。最小值是 1。
- failureThreshold :探测成功后,最少连续探测失败多少次才被认定为失败。默认是 了,最小值是 1。
3. pod资源配置
实际上上面几个步骤就是影响一个pod 生命周期的大的部分,但是还有一些细节也会在 pod 的启动过程进行设置,比如在容器启动之前还会为当前的容器设置分配的 CPU、内存等资源,
我们知道我们可以通过 CGroup 来对容器的资源进行限制,同样的,在pod 中我们也可以直接配置某个容器的使用的 CPU 或者内存的上限。那么pod 是如何来使用和控制这些资源的分配的呢?
首先对于 CPU,我们知道计算机里 CPU 的资源是按”时间片“的方式来进行分配的,系统里的每一个操作都需要 CPU 的处理,所以,哪个任务要是申请的 CPU 时间片越多,那么它得到的 CPU 资源就越多,这个很容器理解。
然后还需要了解下 CGroup 里面对于 CPU 资源的单位换算:
1 CPU = 1000 millicpu (1 Core = 1000m)
0.5 CPU = 500 millicpu (0.5 Core = 500m)
这里的 m就是毫、毫核的意思,Kubernetes 集群中的每一个节点可以通过操作系统的命令来确认本节点的 CPU 内核数量,然后将这个数量乘以1000,得到的就是节点总CPU 总毫数。比如一个节点有四核,那么该节点的CPU 总毫量为4000m,如果你要使用0.5 core, 则你要求的是 4000*0.5= 2000m。在Pod 里面我们可以通过下面的两个参数来现在和请求 CPU 资源:
- spec.containers[].resources. linits.cpu:CpU 上限值,可以短暂超过,容器也不会被停让
- spec. containers[].resources.requests.cpu:CpU请求值,Kubernetes 调度算法里的依据值,可以超过
这里需要明白的是,如果resources.requests.cpu设置的值大于集群里每个节点的最大 CPU 校心数,那么这个Pod 将无法调度,因为没有节点能满足它。
到这里应该明白了,requests 是用于集群调度使用的资源,而 linits 才是真正的用于资源限制的配置,如果你需要保证的你应用优先级很高,也就是资源吃紧的情况下最后再杀掉你的 Pod,那么你就把你的requests 和 limits 的值设置成一致,在后面应用的 Qos 中会具体讲解。
比如,现在我们定义个pod,给容器的配置如下的资源:(pod-resource-demo1.yaml)
apiVersion: v1
kind: Pod
metadata:
name: resource-demo1
spec:
containers:
- name: resource-demo1
image: nginx
ports:
- containerPort: 80
resources:
requests:
memory: 50Mi
cpu: 50m
limits:
memory: 100Mi
cpu: 100m
这里,CPU 我们给的是 50m,也就是 0.05core,这0.05 core 也就是占了 1CPU 里的5% 的资源时问。而限制资源是给的是 100m,但是需要注意的是 CPU 资源是可压缩资源,也就是容器达到了这个设定的上限后,容器性能会下降,但是不会终止或退出。比如我们直接创建上面这个 pod:
创建后登陆容器查看限制详情:
crictl ps
crictl inspect 3c4fe4a440d89
# 找到cgroupsPath的路径
# "cgroupsPath": "kubepods-burstable-podbca27df8_0577_471c_bfd6_b5f24cdc99d4.slice:crio:3c4fe4a440d8979164595d442834abfaa19c7b6ae7d9c5d324b0e41f26c2e095",
#进入cgroop的目录
cd /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podbca27df8_0577_471c_bfd6_b5f24cdc99d4.slice
cat cpu.max
其中 cpu.cfs_quota_us就是CPU 的限制值,如果要查看具体的容器的资源,我们也可以进入到容器目录下面去查看即可
最后我们了解下内存这块的资源控制,内存的单位换算比较简单:
1 MiB=1024 KiB,内存这块在 Kubernetes 里一般用的是n单位,当然你也可以使用ki、Gi甚至pi,看具体的业务需求和资源容量。
!!!warning "单位换算"
这里注意的是〝MiB * MB^,MB 是十进制单位,MiB 是二进制,平时我们以为 MB 等于 1024KB,其实^1MB=1000KB’,1MiB才等于1024KB。中面带字母 讠 的是国际电工协会(IEC)定的,走1024乘积;KB、MB、GB是国际单位制,走1000乘积。
4. 静态pod
在kubernetes 集群中除了我们经常使用到的普通的pod 外,还有一种特殊的pod,叫做staticpod, 也就是我们说的静态Pod,静态pod 有什么特殊的地方呢?
静态 pod 直接由节点上的kubelet 进程来管理,不通过 master 节点上的apiserver。无法与我们常用的控制器Deployment 或者 Daemonset 进行关联,它由 kubelet 进程自己来监控,当pod 崩溃时会重启该 pod, kubelet 也无法对他们进行健康检查。静态pod 始终绑定在某一个kubelet 上,并且始终运行在同一个节点上。kubelet 会自动为每个静态 pod 在Kubernetes 的apiserver 上创建一个镜像Pod, 因此我们可以在 apiserver 中查询到该 pod,但是不能通过 apiserver 进行控制(例如不能删除)。
创建静态 pod 有两种方式:配置文件和 HTTP 两种方式
1. 配置文件
配置文件就是放在特定目录下的标准的JSON 或 YAML 格式的pod 定义文件。用kubelet --pod-manifest-path=sthedirectory-来启动 kubelet进程,kubelet定期的去扫描这个目录,根据这个目录下出现或消失的YAML/JSON 文件来创建或删除静态 pod。
比如我们在nodee1 这个节点上用静态 pod 的方式来启动一个nginx 的服务。我们登录到nodeo1节点上面,可以通过下
面命令找到 kubelet 对应的启动配置文件
静态pod不能使用kubelet的命令操作
systemctl status kubelet
配置文件的路径为
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
找到,文件路径进行编辑
vim /var/lib/kubelet/kubeadm-flags.env
添加参数:
--pod-manifest-path=/etc/testpod/yaml
如下所示
KUBELET_KUBEADM_ARGS="--container-runtime-endpoint=unix:///var/run/crio/crio.sock --pod-manifest-path=/etc/testpod/yaml --pod-infra-container-image=registry.k8s.io/pause:3.9"
重启kubelet
root@node02:/etc/systemd/system/kubelet.service.d# systemctl daemon-reload
root@node02:/etc/systemd/system/kubelet.service.d# systemctl restart kubelet
创建目录
mkdir /etc/testpod/yaml
增加nginx.yaml文件
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
app: static
spec:
containers:
- name: web
image: nginx
ports:
- containerPort: 80
name: web
查看是否创建
root@master01:/data/pod# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-demo-98c8d48ff-ntqsg 1/1 Running 0 4d3h
resource-demo1 1/1 Running 0 81m
static-web-node02 1/1 Running 0 94s
2. 通过http创建静态pod
kubelet 周期地从-manifest-url-参数指定的地址下载文件,并且把它翻译成 JSOW/YAML_ 格式的 pod定义,此后的操作,方式与-pod-manifest-path=相同,kubelet 会不时地重新下载该文件,当文件变化时对应地终止或启动静态 pod。
kubelet 启动时,由--pod-manifest-path= 或--manifest-url=参数指定的目录下定义的所有 pod 都会自动创建,例如,我们示例中的 static-web。
其实我们用kubeadn 安装的集群,master 节点上面的几个重要组件都是用静态Pod 的方式运行的,我们登陆到master节点上查看/etc/kubernetes /manifests目录:
$ ls/etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
现在明白了吧,这种方式也为我们将集群的一些组件容器化提供了可能,因为这些 pod 都不会受到 apiserver 的控制,不然我们这里kube-apiserver怎么自己去控制自己呢? 万一不小心把这个 Pod 删掉了呢?所以只能有kubelet自己来进行控制,这就是我们所说的静态 Pod。
5. downward api
前面我们从 Pod 的原理到生命周期介绍了pod的一些使用,作为Kubernetes 中最核心的资源对象、最基本的调度单元,我们可以发现Pod 中的属性还是非常繁多的,前面我们使用过一个 volumes 的属性,表示声明一个数据卷,我们可以通过命令
kubectl explain pod.spec.volumes
去查看该对象下面的属性非常多,前面我们只是简单使用了hostpath和emptyoirc了这两种模式,其中还有一种模式叫做downwardAPI,这个模式和其他模式不一样的地方在于它不是为了存放容器的数据也不是用来进行容器和宿主机的数据交换的,而是让 Pod 里的容器能够直接获取到这个 pod 对象本身的一些信息.
目前 Downward APT 提供了两种方式用于将 pod 的信息注入到容器内部:
- 环境变量:用于单个变量,可以将 pod 信息和容器信息直接注入容器内部
- volume 挂载:将Pod 信息生成为文件,直接挂载到容器内部中去
1. 环境变量
我们通过 Downward API 来将pod 的IP、名称以及所对应的 namespace 注入到容器的环境变量中去,然后在容器中打印全部的环境变量来进行验证,对应资源清单文件如下:(env-pod.yaml)
apiVersion: v1
kind: Pod
metadata:
name: env-pod
namespace: kube-system
spec:
containers:
- name: env-pod
image: busybox
command: ["/bin/sh", "-c", "env", ";", "sleep 600"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
我们可以看到上面我们使用了一种新的方式来设置 env 的值:valueFrom,由于pod 的name 和namespace属于元数据,是在Pod 创建之前就已经定下来了的,所以我们可以使用metata就可以获取到了,但是对于 pod的工P则不一样,因为我们知道Pod IP 是不固定的,Pod 重建了就变了,它属于状态数据,所以我们使用 status 这个属性去获取。另外除了使用 fieldRef 获取Pod 的基本信息外,还可以通过 resourceFieldRef 去获取容器的资源请求和资源限制信息。
2. volume 挂载
Dowrward API除了提供环境变量的方式外,还提供了通过 volume 挂载的方式去获取 Pod 的基本信息。接下来我们通过Downward API将 pod 的 Label、Annotation 等信息通过 volume 挂载到容器的某个文件中去,然后在容器中打印出该文件的值来验证,对应的资源清单文件如下所示:(volume-pod. yaml)
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
namespace: kube-system
labels:
k8s-app: test-volume
node-env: test
annotations:
own: wang
build: test
spec:
volumes:
- name: podinfo
downwardAPI:
items:
- path: labels
fieldRef:
fieldPath: metadata.labels
- path: annotations
fieldRef:
fieldPath: metadata.annotations
containers:
- name: volume-pod
image: busybox
args:
- sleep
- "3600"
volumeMounts:
- mountPath: /etc/podinfo
name: podinfo
我们将元数据 labels和annotaions 以文件的形式挂载到了 /etc/podinfo 目录下,创建上面的 pod,查看容器/etc/podinfo目录即可看到信息
目前,Downward Api 支持的字段已经非常丰富啦,比如
1. 使用fieldRef 可以声明使用: spec.nodeName -宿主机名字 status.hostIP - 宿主机IP metadata.name - Pod的名字 metadata.namespace - Pod的Namespace status.podIP - Pod的IP spec.serviceAccountName - Podf的Service Account的名字 metadata.uid - Pod的UID metadata. Labels['-KEY>’〕-指定-KEY>的Label值 metadata.annotations['<KEY>'] -指定<KEY>的Annotation值 metadata.labels -Pod的所有Label metadata.annotations -Pod的所有Annotation
2. 使用resourceFieldRef 可以声明使用:
容器的 CPU limit
容器的 CPU request
容器的 memory limit
容器的 memory request
!!! warning"注意”
需要注意的是,Downward API能够获取到的信息,一定是Pod 里的容器进程启动之前就能够确定下来的信息。而如果你想要获取 pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用,那就肯定不能使用‘Download API’而应该考虑在 pod 里定义一个sidecar 容器来获取了。
在实际应用中,如果你的应用有获取pod 的基本信息的需求,一般我们就可以利用Downward API来获取基本信息,然后编写一个启动脚本或者利用initcontainer将 Pod 的信息注入到我们容器中去,然后在我们自己的应用中就可以正常的处理相关逻辑了。
除了通过 Downward API 可以获取到 pod 本身的信息之外,其实我们还可以通过映射其他资源对象来获取对应的信息,比如 Secret、ConfiigMp资源对象,同样我们可以通过环境变量和挂载 volume 的方式来获取他们的信息,但是,通过环境变量获取这些信息的方式,不具备自动更新的能力。所以,一般情况下,都建议使用 volume 文件的方式获取这些信息,因为通过 volume 的方式挂载的文件在pod 中会进行热更新。
6. PodPreset
我们已经学习了很多 pod 的知识点,但是可能有部分同学还是觉得 Pod 的字段属性太多了,很多记不住,查询文档效率不高,你是不是希望kubernetes能够提供一个功能为 pod 自动填充一些字段呢?这个需求还是很实际的,比如我们按照命名空间来划分不同的环境,然后我们在不同的环境上部署 pod 后自动为我们加上环境相关的 Labels、Annotations等等信息,这样就大大提高了编写 YAML 的效率,为此,在Kubernetes v1.11 版本后就提供了一个叫做podPreset (pod预设值)的功能可以来解决这个问题。
PodPreset是用来在 Pod 被创建的时候向其中注入额外的信息的API 资源。您可以使用label selector 来匹配为哪些 Pod 应用PodPreset
kubernetes提供了一个准入控制器(PodPreset),当启用后,PodPreset会将应用创建请求传入到该控制器上。当有 Pod 创建请求发生时,系统将执行以下操作:
- 检索所有可用的PodPresets
- 检查有PodPreset的标签选择器上的标签与正在创建的Pod 上的标签是否匹配。
- 尝试将由PodPreset定义的各种资源合并到正在创建的Pod 中。
- 出现错误时,在该 Pod 上引发记录合并错误的事件,PodPreset 不会注入任何资源到创建的 Pod 中。
- 注释刚生成的修改过的 Pod spec,以表明它已被 PodPreset 修改过。注释的格式为 podpreset.admission.kubernetes.io/podpreset-<pod-preset name>": "<resource version>"。
每个 Pod 可以匹配零个或多个 PodPrestet;并且每个 PodPreset 可以应用于零个或多个 Pod。 PodPreset 应用于一个或多个 Pod 时,Kubernetes 会修改 Pod Spec。对于 Env、EnvFrom 和 VolumeMounts 的更改,Kubernetes 修改 Pod 中所有容器的容器 spec;对于 Volume 的更改,Kubernetes 修改 Pod Spec。
可能在某些情况下,您希望 Pod 不会被任何 Pod Preset 突变所改变。在这些情况下,您可以在 Pod 的 Pod Spec 中添加注释:podpreset.admission.kubernetes.io/exclude:"true"。
1. 启用 PodPreset
要启用PodPreset功能,需要确保你使用的是kubernetes 1.8版本以上,然后需要在准入控制中加入PodPreset,另外为了定义PodPreset对象,还需要其中podpreset的API 类型:
- —admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota,PodPreset
- —runtime-config=rbac.authorization.k8s.io/v1alpha1=true,settings.k8s.io/v1alpha1=true
注意上面的kube-apiserver中的启动参数(前面是两个-),参数修改完成后,重启kube-apiserver即可。
比如我们将我们上面的sentry的环境变量定义成一个PodPreset对象:(sentry-podpreset.yaml)
apiVersion: settings.k8s.io/v1alpha1 kind: PodPreset metadata: name: sentry-env namespace: kube-ops spec: selector: matchLabels: app: sentry env: - name: C_FORCE_ROOT value: "true" - name: SENTRY_REDIS_HOST value: "redis" - name: SENTRY_REDIS_PORT value: "6379" - name: SENTRY_REDIS_DB value: "2" - name: SENTRY_RABBITMQ_HOST value: "rabbitmq:5672" - name: SENTRY_RABBITMQ_USERNAME value: "root" - name: SENTRY_RABBITMQ_PASSWORD value: "root" - name: SENTRY_SECRET_KEY value: "xxxxxxxxxxxxx" - name: SENTRY_POSTGRES_HOST value: "postgresql" - name: SENTRY_POSTGRES_PORT value: "5432" - name: SENTRY_DB_NAME value: "sentry" - name: SENTRY_DB_USER value: "sentry" - name: SENTRY_DB_PASSWORD value: "sentry321"
我们可以看到定义的PodPreset匹配了一个标签:app: sentry,所有带有该标签的 POD 都会被注入上面的环境变量。
sentry的部署文件就可以简化成这样了:(sentry-deployment.yaml)
apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: sentry name: sentry namespace: kube-ops spec: template: metadata: labels: app: sentry spec: containers: - image: sentry:8.22.0 imagePullPolicy: Always name: sentry ports: - containerPort: 9000 name: web - image: sentry:8.22.0 imagePullPolicy: Always name: sentry-worker command: ["sentry", "run", "worker"] - image: sentry:8.22.0 imagePullPolicy: Always name: sentry-cron command: ["sentry", "run", "cron"]
然后执行命令:
$ kubectl create -f sentry-podpreset.yaml
$ kubectl create -f sentry-deployment.yaml
然后我们可以去 dashboard 中或者通过 kubectl 命令查看创建的 sentry POD已经被注入了所有的环境变量了。



