GO语言【高并发】
1. 为什么不使用多线程
- python, java c++ 采用多线程和进程变成
- 多线程-每个线程占用的内存比较多,而且系统切换开销很大
2. go语言控制主的goroutine在子协程结束后结束
如何解决主的goroutine在子协程结束后自动结束
使用:sync.WaitGroup
package main
import (
"fmt"
"sync"
)
//如何解决主的goroutine在子协程结束后自动结束
var wg sync.WaitGroup
//WaitGroup提供了三个很有用的函数
/*
Add
Done
Wait
Add的数量和Done的数量必须相等
在主的协程中使用Add, Wait, 子协城中使用Done
*/
func f(n int) {
defer wg.Done()
fmt.Println(n)
}
func main() {
wg.Add(5)
for i := 0; i < 5; i++ {
go f(i)
}
wg.Wait()
}3. 互斥锁
解决问题,数据不同步问题
package main
import (
"fmt"
"sync"
)
/*
锁 - 资源竞争
1. 按理说: 最后的结果应该是0
2. 实际的情况: 1. 不是0 2. 每次的运行结果还不一样
*/
var total int
var wg sync.WaitGroup
var lock sync.Mutex
//互斥锁, 读写锁 同步数据 能不用锁就别用锁 - 性能
//绝大多数的web系统来说 都是读多写少
//有1w个人同时读数据库 A读的时候 B能读吗? 为什么要加锁呢 一定要加锁 写上和读上面加同一把锁
//并发严重下降, B读了一个数据 造成C读了数据产生影响吗? 一定是写和读之间造成的
//如果这边锁可以做到 读之间不会产生影响, 写和读之间才会产生影响 那多好 读写锁
func add() {
defer wg.Done()
for i := 0; i < 100000; i++ {
//先把门锁上
lock.Lock()
total = total + 1 //这个代码和
lock.Unlock()
//放开锁
//1. 从total取出值
//2. 将total+1
//3. 将total+1的计算结果放入到total中
}
}
func sub() {
defer wg.Done()
for i := 0; i < 100000; i++ {
//先把门锁上
lock.Lock()
total = total - 1
lock.Unlock()
//放开锁
}
}
func main() {
wg.Add(2)
go add()
go sub()
wg.Wait()
fmt.Println(total)
}
4. 读写锁
package main
import (
"fmt"
"sync"
"time"
)
/*
锁 - 资源竞争
1. 按理说: 最后的结果应该是0
2. 实际的情况: 1. 不是0 2. 每次的运行结果还不一样
*/
var total int
var wg sync.WaitGroup
var rwLock sync.RWMutex
func read() {
defer wg.Done()
rwLock.RLock()
fmt.Println("开始读取数据")
time.Sleep(time.Second)
fmt.Println("读取成功")
rwLock.RUnlock()
}
func write() {
defer wg.Done()
rwLock.Lock()
fmt.Println("开始修改数据")
time.Sleep(time.Second * 10)
fmt.Println("修改成功")
rwLock.Unlock()
}
func main() {
wg.Add(6)
for i := 0; i < 5; i++ {
go read()
}
for i := 0; i < 1; i++ {
go write()
}
wg.Wait()
fmt.Println(total)
}
5. channel
channels 是一种类型安全的消息队列,充当两个 goroutine 之间的管道,将通过它同步的进行任意资源的交换。chan 控制 goroutines 交互的能力从而创建了 Go 同步机制。当创建的 chan 没有容量时,称为无缓冲通道。反过来,使用容量创建的 chan 称为缓冲通道。
要了解通过 chan 交互的 goroutine 的同步行为是什么,我们需要知道通道的类型和状态。根据我们使用的是无缓冲通道还是缓冲通道,场景会有所不同,所以让我们单独讨论每个场景。
1. 基础
1. 类型
- channel是一种类型,一种引用类型
- 声明管道类型的格式如下
var 变量 chan 元素类型
var ch1 chan int
var ch2 chan bool
var ch3 chan []int2. 创建
- 声明的管道后需要使用make 函数初始化才能使用
- 创建 channel 的格式如下: make(chan 元素类型, 容量)
//创建一个能存储 10 个 int 类型数据的管道
ch1 := make(chan int, 10)
//创建一个能存储 4 个 bool 类型数据的管道
ch2 := make(chan bool, 4)
//创建一个能存储 3 个[]int 切片类型数据的管道
ch3 := make(chan []int, 3)3. 操作
package main
import "fmt"
func main() {
//channel的定义
//ch1 := make(chan int, 10)
//ch2 := make(chan bool, 4)
//ch3 := make(chan []int, 3)
ch := make(chan int, 5)
//向channel写入数据
ch <- 10
ch <- 12
//读channel
v1 := <- ch
fmt.Println("v1", v1)
//关闭channel,close是内置函数,用于关闭channel
close(ch)
v2 := <- ch
fmt.Println("v2", v2)
//当channel关闭且没有值事,读出来的都是零值
v3 := <- ch
fmt.Println("v3", v3)
ch <- 24
//优雅的读channel,ch中没有值时会自动退出for循环
for val := range ch {
fmt.Println(val)
}
}
2. 有缓冲空间
(1)代码定义
msg = make(chan int, 1) //有缓冲空间的
(2)描述
buffered channel 具有容量,因此其行为可能有点不同。当 goroutine 试图将资源发送到缓冲通道,而该通道已满时,该通道将锁住 goroutine并使其等待缓冲区可用。如果通道中有空间,发送可以立即进行,goroutine 可以继续。当goroutine 试图从缓冲通道接收数据,而缓冲通道为空时,该通道将锁住 goroutine 并使其等待资源被发送。
(3)本质
我们在 chan 创建过程中定义的缓冲区大小可能会极大地影响性能。我将使用密集使用 chan 的扇出模式来查看不同缓冲区大小的影响。在我们的基准测试中,一个 producer 将在通道中注入百万个整数元素,而5个 worker 将读取并将它们追加到一个名为 total 的结果变量中。
Send 先于 Receive 发生。
好处: 延迟更小。
代价: 不保证数据到达,越大的 buffer,越小的保障到达。buffer = 1 时,给你延迟一个消息的保障。
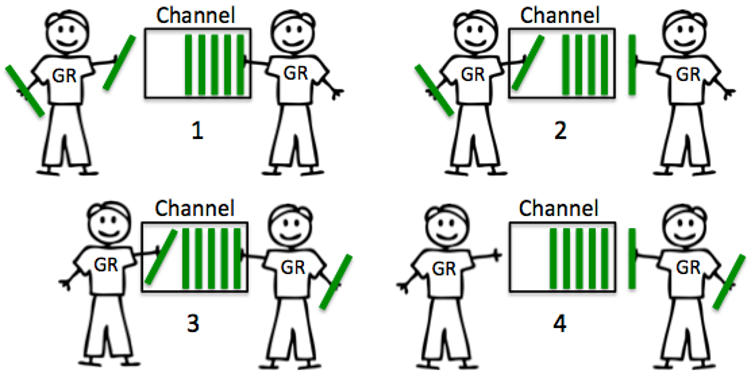
(4)代码示例

3. 无缓冲空间
(1)代码定义
msg = make(chan int) //无缓冲
(2)描述
无缓冲 chan 没有容量,因此进行任何交换前需要两个 goroutine 同时准备好。当 goroutine 试图将一个资源发送到一个无缓冲的通道并且没有goroutine 等待接收该资源时,该通道将锁住发送 goroutine 并使其等待。当 goroutine 尝试从无缓冲通道接收,并且没有 goroutine 等待发送资源时,该通道将锁住接收 goroutine 并使其等待。
(3)本质
无缓冲信道的本质是保证同步。
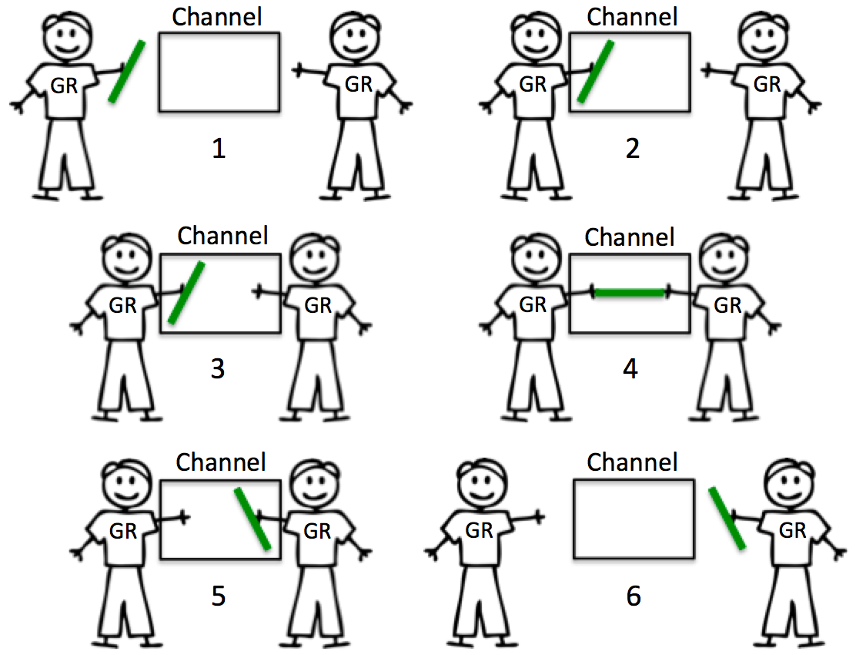
(4)注意
Receive 先于 Send 发生。
好处: 100% 保证能收到。
代价: 延迟时间未知。
(5)代码示例

4. 使用场景
1. timing out
2. moving on pipeline
3. fan-out, fan-in
4. cancellation
Close 先于 Receive 发生(类似 Buffered)。
不需要传递数据,或者传递 nil。
非常适合去掉和超时控制。
5. contex
参考:
https://blog.golang.org/concurrency-timeouts
https://blog.golang.org/pipelines
https://talks.golang.org/2013/advconc.slide#1
https://github.com/go-kratos/kratos/tree/master/pkg/sync
4. 实际场景
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func consumer(queue chan int) {
defer wg.Done()
data := <-queue
fmt.Println(data)
}
func main() {
/*
channel提供了一种通信机制, 定向,python java 消息队列
*/
// 1.定义一个channel
var msg chan int
// 2. 初始化一个channel, 一共有两种
msg = make(chan int) //第一种初始化方式,无缓冲
msg = make(chan int, 1) //第二种初始化方式,有缓冲空间的
// 3.在go中, 使用make初始化的类型有三种, slice map channel
msg <- 1
wg.Add(1)
go consumer(msg)
wg.Wait()
}以上方法只能 给一个值,取一个值,要不然就会报错
下面为 使用for取管道中的值,及关闭管道
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func consumer(queue chan int) {
defer wg.Done()
//for data := range queue{
// fmt.Println(data)
//}
for {
data, ok := <-queue
if !ok {
break
} else {
fmt.Println(data)
time.Sleep(time.Second)
}
}
}
func main() {
/*
channel提供了一种通信机制, 定向,python java 消息队列
*/
// 1.定义一个channel
var msg chan int
// 2. 初始化一个channel, 一共有两种
msg = make(chan int) //第一种初始化方式,无缓冲
msg = make(chan int, 1) //第二种初始化方式,有缓冲空间的
// 3.在go中, 使用make初始化的类型有三种, slice map channel
msg <- 1
wg.Add(1)
go consumer(msg)
msg <- 2
//关闭channel。1 已经关闭的channel不能在发送数据了,2 已经关闭的chanel消费者可以继续消费数据,值到数据取完为止
close(msg)
wg.Wait()
}
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func consumer(msg chan int) {
defer wg.Done()
fmt.Println(<-msg)
}
func main() {
var msg chan int
msg = make(chan int)
wg.Add(1)
go consumer(msg)
msg <- 1 //当你进行 放数据到msg中的时候 这个时候会阻塞的,阻塞之前会获取一把锁, 这把锁什么时候释放 肯定是要等到数据被消费之后
wg.Wait()
//channel是多个goroutine之间线程安全, 如何保证的呢 使用锁?
//如果你是没有缓冲的channel 在没有启动一个消费者之前 你放数据就会报错
//data := <- msg
//fmt.Println(data)
}select语句
第一种使用场景:超时
package main
import (
"fmt"
"time"
)
func main() {
/*
go语言提供了一个select 的功能,作用于channel之上的,多路复用
select 会随机公平的选择一个case的语句进行执行
select 的使用场景,
1. timeout的超时机制
*/
//第一种老的方式
//timeout := false
//go func() {
// // 该goroutine如果执行时间超过了1s, 那么就会报告主的goroutine
// time.Sleep(time.Second * 2)
// timeout = true
//}()
//
//for {
// if timeout {
// fmt.Println("结束")
// break
// }
// time.Sleep(time.Millisecond * 10)
//}
timeout := make(chan bool, 2)
timeout2 := make(chan bool, 2)
go func() {
// 该goroutine如果执行时间超过了1s, 那么就会报告主的goroutine
time.Sleep(time.Second * 2)
timeout <- true
}()
go func() {
// 该goroutine如果执行时间超过了1s, 那么就会报告主的goroutine
time.Sleep(time.Second * 1)
timeout2 <- true
}()
select {
case <-timeout:
fmt.Println("超时了")
case <-timeout2:
fmt.Println("超时了1")
default:
fmt.Println("继续下一次")
}
}获取机器的CPU使用率, 在6秒后自动退出
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
var stop chan bool = make(chan bool)
func cpuInfo() {
defer wg.Done()
for {
select {
case <-stop:
fmt.Println("退出CPU监控")
return
default:
time.Sleep(time.Second * 2)
fmt.Println("CPU信息读取完成")
}
}
}
func main() {
wg.Add(1)
go cpuInfo()
time.Sleep(time.Second * 6)
stop <- true
wg.Wait()
}使用context来完成上述监控,
获取机器的CPU使用率, 在6秒后自动退出
package main
import (
"context"
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func cpuInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Println("退出CPU监控")
return
default:
time.Sleep(time.Second * 2)
fmt.Println("CPU信息读取完成")
}
}
}
func main() {
wg.Add(1)
ctx, cancel := context.WithCancel(context.Background())
go cpuInfo(ctx)
time.Sleep(time.Second * 6)
cancel()
wg.Wait()
}多个调用方式
package main
import (
"context"
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func cpuInfo(ctx context.Context) {
defer wg.Done()
//生成一个子的context, 当父的context取消,那么父的context生成的子的context也会被取消
ctx2, _ := context.WithCancel(ctx)
go memoryInfo(ctx2) //在此也可调用
//go memoryInfo(ctx) //在此也可调用
for {
select {
case <-ctx.Done():
fmt.Println("退出CPU监控")
return
default:
time.Sleep(time.Second * 2)
fmt.Println("CPU信息读取完成")
}
}
}
func memoryInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Println("退出内存监控")
return
default:
time.Sleep(time.Second * 2)
fmt.Println("内存信息读取完成")
}
}
}
func main() {
wg.Add(2)
ctx, cancel := context.WithCancel(context.Background())
go cpuInfo(ctx)
//go memoryInfo(ctx)
time.Sleep(time.Second * 6)
cancel()
wg.Wait()
}context的超时方法
超过一定时间自动退出
package main
import (
"context"
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func cpuInfo(ctx context.Context) {
defer wg.Done()
for {
select {
case <-ctx.Done():
fmt.Println("退出CPU监控")
return
default:
time.Sleep(time.Second * 2)
fmt.Println("CPU信息读取完成")
}
}
}
func main() {
wg.Add(1)
//ctx, cancel := context.WithTimeout(context.Background(), 3*time.Second)
ctx, _ := context.WithTimeout(context.Background(), 3*time.Second)
go cpuInfo(ctx)
time.Sleep(time.Second * 6)
//cancel()
wg.Wait()
}对于context来先介绍一下
在 Go 服务中,每个传入的请求都在其自己的goroutine 中处理。请求处理程序通常启动额外的 goroutine 来访问其他后端,如数据库和 RPC服务。处理请求的 goroutine 通常需要访问特定于请求(request-specific context)的值,例如最终用户的身份、授权令牌和请求的截止日期(deadline)。当一个请求被取消或超时时,处理该请求的所有 goroutine 都应该快速退出(fail fast),这样系统就可以回收它们正在使用的任何资源。
Go 1.7 引入一个 context 包,它使得跨 API 边界的请求范围元数据、取消信号和截止日期很容易传递给处理请求所涉及的所有 goroutine(显示传递)。
其他语言: Thread Local Storage(TLS),XXXContext

使用:
如何将 context 集成到 API 中?
在将 context 集成到 API 中时,要记住的最重要的一点是,它的作用域是请求级别的。
例如,沿单个数据库查询存在是有意义的,但沿数据库对象存在则没有意义。
目前有两种方法可以将 context 对象集成到 API 中:
1. The first parameter of a function call
首参数传递 context 对象,比如,参考 net 包 Dialer.DialContext。此函数执行正常的 Dial 操作,但可以通过 context 对象取消函数调用。

2. Optional config on a request structure
在第一个 request 对象中携带一个可选的 context 对象。例如 net/http 库的 Request.WithContext,通过携带给定的 context 对象,返回一个新的 Request 对象。
![]()
使用注意:
1. Incoming requests to a server should create a Context.
2. Outgoing calls to servers should accept a Context.
3. Do not store Contexts inside a struct type; instead, pass a Context explicitly to each function that needs it.
4. The chain of function calls between them must propagate the Context.
5. Replace a Context using WithCancel, WithDeadline, WithTimeout, or WithValue.
6. When a Context is canceled, all Contexts derived from it are also canceled.
7. The same Context may be passed to functions running in different goroutines; Contexts are safe for simultaneous use by multiple goroutines.
8. Do not pass a nil Context, even if a function permits it. Pass a TODO context if you are unsure about which Context to use.
9. Use context values only for request-scoped data that transits processes and APIs, not for passing optional parameters to functions.
10. All blocking/long operations should be cancelable.
11. Context.Value obscures your program’s flow.
12. Context.Value should inform, not control.
13. Try not to use context.Value.
6. Atomic
1. 使用方式
atomic.Value类型对外暴露的方法就两个:
v.Store(c)- 写操作,将原始的变量c存放到一个atomic.Value类型的v里。c = v.Load()- 读操作,从线程安全的v中读取上一步存放的内容。
下面是一个常见的使用场景:应用程序定期的从外界获取最新的配置信息,然后更改自己内存中维护的配置变量。工作线程根据最新的配置来处理请求。
package main
import (
"fmt"
"sync/atomic"
"time"
)
func loadConfig() map[string]string {
// 从数据库或者文件系统中读取配置信息,然后以map的形式存放在内存里
return make(map[string]string)
}
func requests() chan int {
// 将从外界中接受到的请求放入到channel里
return make(chan int)
}
func main() {
// config变量用来存放该服务的配置信息
var config atomic.Value
// 初始化时从别的地方加载配置文件,并存到config变量里
config.Store(loadConfig())
go func() {
// 每10秒钟定时的拉取最新的配置信息,并且更新到config变量里
for {
time.Sleep(10 * time.Second)
// 对应于赋值操作 config = loadConfig()
config.Store(loadConfig())
}
}()
// 创建工作线程,每个工作线程都会根据它所读取到的最新的配置信息来处理请求
for i := 0; i < 10; i++ {
go func() {
for r := range requests() {
// 对应于取值操作 c := config
// 由于Load()返回的是一个interface{}类型,所以我们要先强制转换一下
c := config.Load().(map[string]string)
// 这里是根据配置信息处理请求的逻辑...
_, _ = r, c
fmt.Println(c)
}
}()
}
}
//应用程序定期的从外界获取最新的配置信息,然后更改自己内存中维护的配置变量。工作线程根据最新的配置来处理请求。
7. errgroup
1. 说明
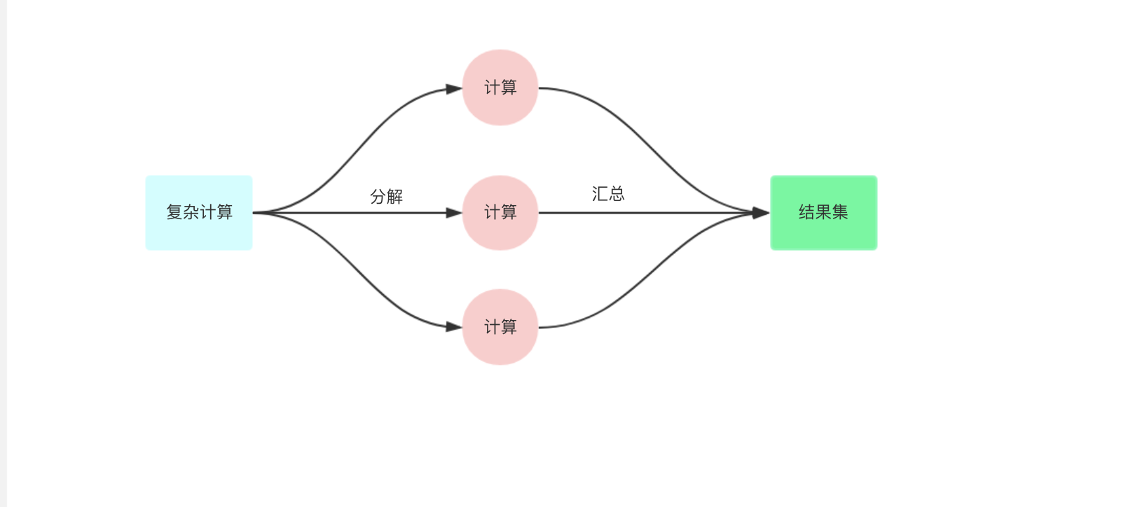
errgroup为goroutine组提供了通知、错误传递、上下文取消功能。
一般在一组goroutine出现错误需要取消全部goroutine的情况使用到
2. 成员与方法
errGroup主要有以下结构
cancel func() : context的cancel方法
wg sync.WiatGroup: 封装sync.WaitGroup
errOnce: 保证只接受一次错误
err error: 保存第一个返回的错误
sem chan token: 控制goroutine活动数量(token实际上是struct{})
3. 使用场景
- 并行工作流
- 错误处理或者优雅降级
- context传播和取消
- 利用局部变量+闭包
8. sync.Pool
sync.Pool 的场景是用来保存和复用临时对象,以减少内存分配,降低 GC 压力(Request-Driven 特别合适)。
Get 返回 Pool 中的任意一个对象。如果 Pool 为空,则调用 New 返回一个新创建的对象。
放进 Pool 中的对象,会在说不准什么时候被回收掉。所以如果事先 Put 进去 100 个对象,下次 Get 的时候发现 Pool 是空也是有可能的。不过这个特性的一个好处就在于不用担心 Pool 会一直增长,因为 Go 已经帮你在 Pool 中做了回收机制。
这个清理过程是在每次垃圾回收之前做的。之前每次GC 时都会清空 pool,而在1.13版本中引入了 victim cache,会将 pool 内数据拷贝一份,避免 GC 将其清空,即使没有引用的内容也可以保留最多两轮 GC。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号