实验4
作业1
要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:
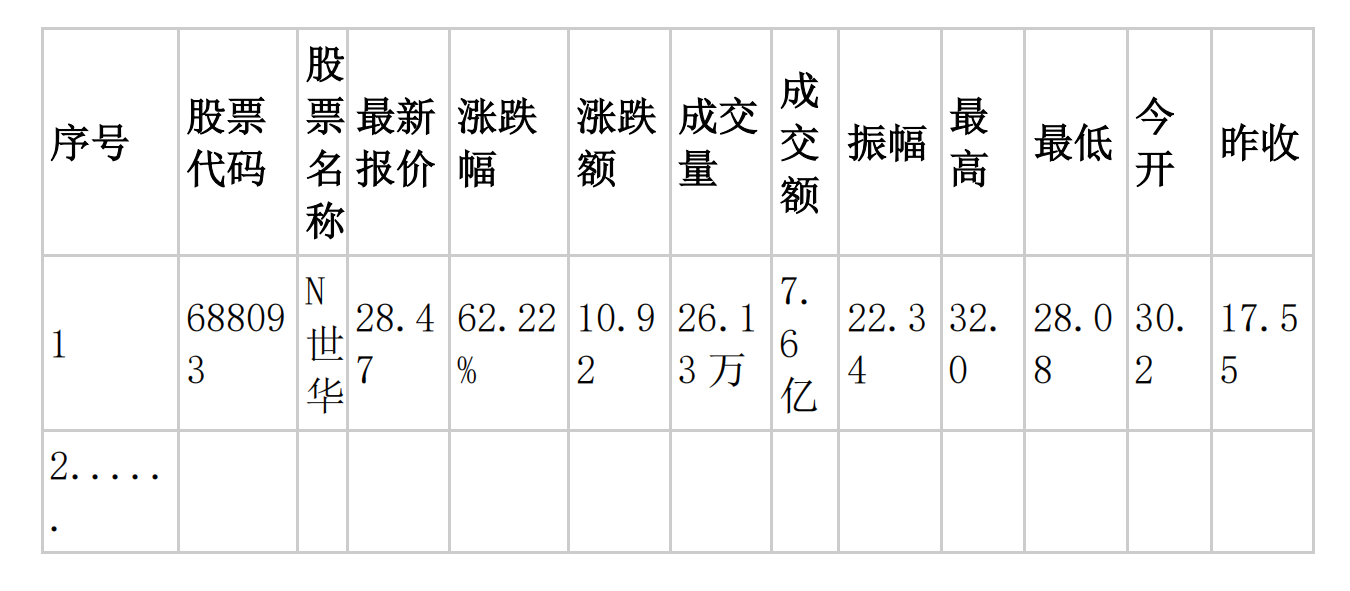
MYSQL 数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
码云地址:https://gitee.com/wanghew/homework/tree/master/作业4
import re
import sqlite3
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from bs4 import BeautifulSoup
import pymysql
import json
from bs4 import UnicodeDammit
import urllib.request
from selenium.webdriver.common.by import By
# 股票数据库类
class stockDB:
# 打开数据库连接
def openDB(self):
# 连接到名为stocks.db的SQLite数据库
self.con = sqlite3.connect("stocks.db")
self.cursor = self.con.cursor()
try:
# 创建名为stocks的表,如果不存在的话
# 表结构包含股票的各种信息字段
self.cursor.execute("create table if not exists stocks (Num varchar(16),"
" Code varchar(16),names varchar(16),"
"Price varchar(16),"
"Quote_change varchar(16),"
"Updownnumber varchar(16),"
"Volume varchar(16),"
"Turnover varchar(16),"
"Swing varchar(16),"
"Highest varchar(16),"
"Lowest varchar(16),"
"Today varchar(16),"
"Yesday varchar(16))")
except Exception as e:
print(f"创建表时出错: {e}")
# 关闭数据库连接
def closeDB(self):
self.con.commit() # 提交事务
self.con.close() # 关闭数据库连接
# 向数据库插入股票数据
def insert(self, Num, Code, names, Price, Quote_change, Updownnumber, Volume, Turnover, Swing, Highest, Lowest,
Today, Yesday):
try:
self.cursor.execute(
"insert into stocks(Num,Code,names,Price,Quote_change,Updownnumber,Volume,Turnover,Swing,Highest,Lowest,Today,Yesday)"
" values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(Num, Code, names, Price, Quote_change, Updownnumber, Volume, Turnover, Swing, Highest, Lowest, Today,
Yesday))
except Exception as err:
print(f"插入数据时出错: {err}")
# 从数据库中查询并显示所有股票数据
def show(self):
self.cursor.execute("select * from stocks")
rows = self.cursor.fetchall()
for row in rows:
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}".format(row[0], row[1],
row[2], row[3],
row[4], row[5],
row[6], row[7],
row[8], row[9],
row[10],
row[11],
row[12]))
# 获取股票信息的函数
def get_stock(url, insertDB):
service = Service(
executable_path="C:/Python38/Scripts/chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url)
# 使用XPath在网页中查找tbody下的tr元素(每行股票数据)
trs = driver.find_elements(By.XPATH, '//tbody/tr')
stocks = []
for tr in trs:
# 在每行中查找td元素(每个数据单元格)
tds = tr.find_elements(By.XPATH, './td')
td = [x.text for x in tds]
stocks.append(td)
stockInfo = []
for stock in stocks:
# 提取每行股票数据中的指定列信息
stockInfo.append((stock[0], stock[1], stock[2], stock[4], stock[5], stock[6], stock[7], stock[8], stock[9],
stock[10], stock[11], stock[12], stock[13]))
return stockInfo
def main():
insertDB = stockDB()
insertDB.openDB()
print("开始爬取中...")
print("{:4}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}\t{:16}\t{:8}\t{:8}\t{:8}\t{:8}\t{:8}".format('序号', '代码', '名称',
'最新价', '涨跌幅(%)',
'跌涨额(¥)',
'成交量(手)',
'成交额(¥)', '振幅(%)',
'最高', '最低', '今开',
'昨收'))
urls = ["http://quote.eastmoney.com/center/gridlist.html#hz_a_board",
"http://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"http://quote.eastmoney.com/center/gridlist.html#sz_a_board"]
count = 0
all_stockInfo = []
for url in urls:
if count == 0:
market_name = "沪深A股"
elif count == 1:
market_name = "上证A股"
elif count == 2:
market_name = "深证A股"
else:
market_name = ""
stockInfo = get_stock(url, insertDB)
for st in stockInfo:
# 将每条股票数据插入数据库
insertDB.insert(st[0], st[1], st[2], st[3], st[4], st[5], st[6], st[7], st[8], st[9], st[10], st[11], st[12])
count += 1
print("第{}个 - {}".format(count, market_name))
all_stockInfo.extend(stockInfo)
# 从数据库中查询并显示所有股票数据
insertDB.show()
insertDB.closeDB()
df = pd.DataFrame(all_stockInfo)
columns = {0: '序号', 1: '代码', 2: '名称', 3: '最新价', 4: '涨跌幅(%)', 5: '跌涨额(¥)', 6: '成交量(手)', 7: '成交额(¥)', 8: '振幅(%)',
9: '最高', 10: '最低', 11: '今开', 12: '昨收'}
df.rename(columns=columns, inplace=True)
if count >= 1:
df.to_csv('沪深 A 股.csv', encoding='utf-8-sig', index=False)
if count >= 2:
df.to_csv('上证 A 股.csv', encoding='utf-8-sig', index=False)
if count >= 3:
df.to_csv('深证 A 股.csv', encoding='utf-8-sig', index=False)
if __name__ == '__main__':
main()
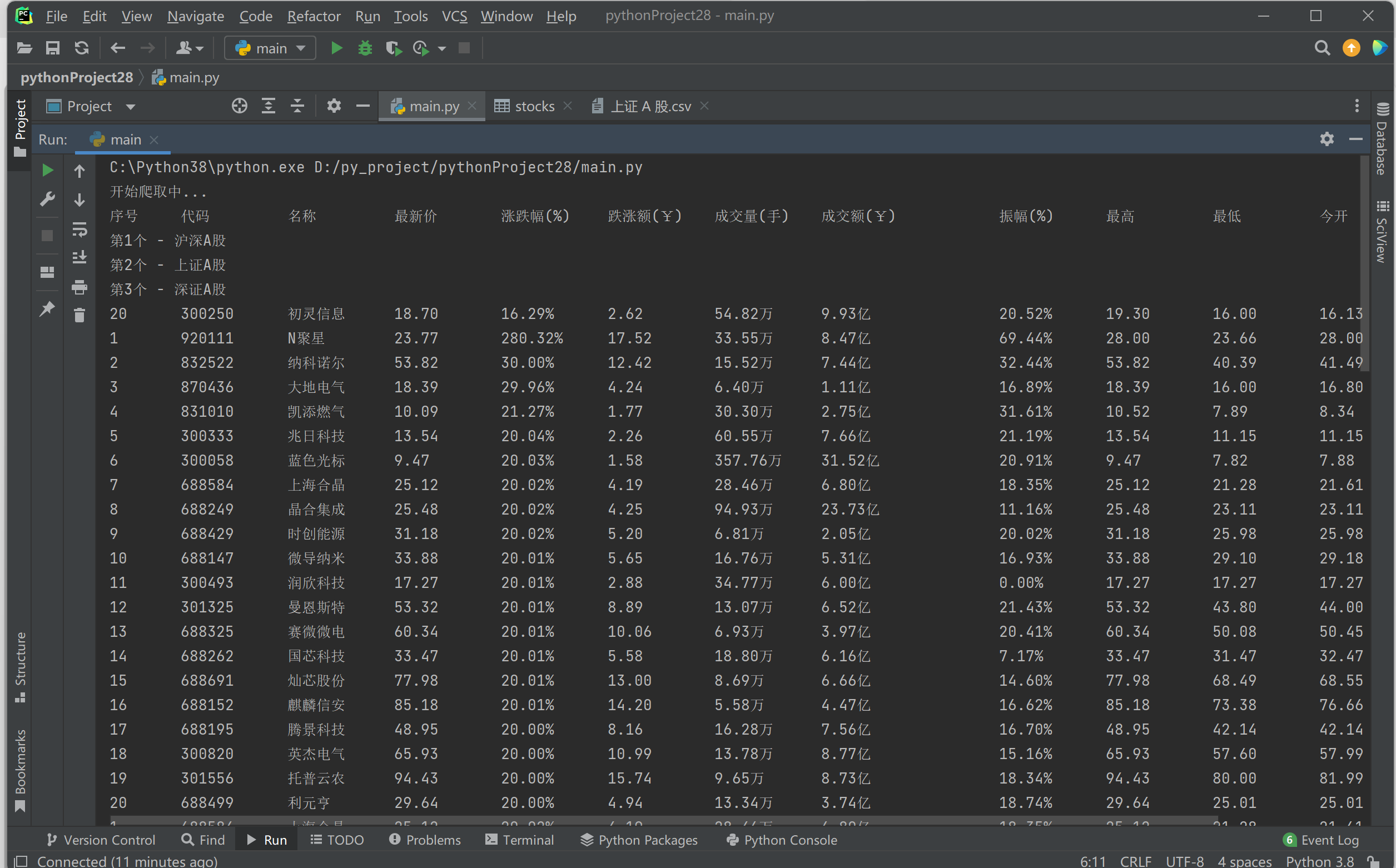
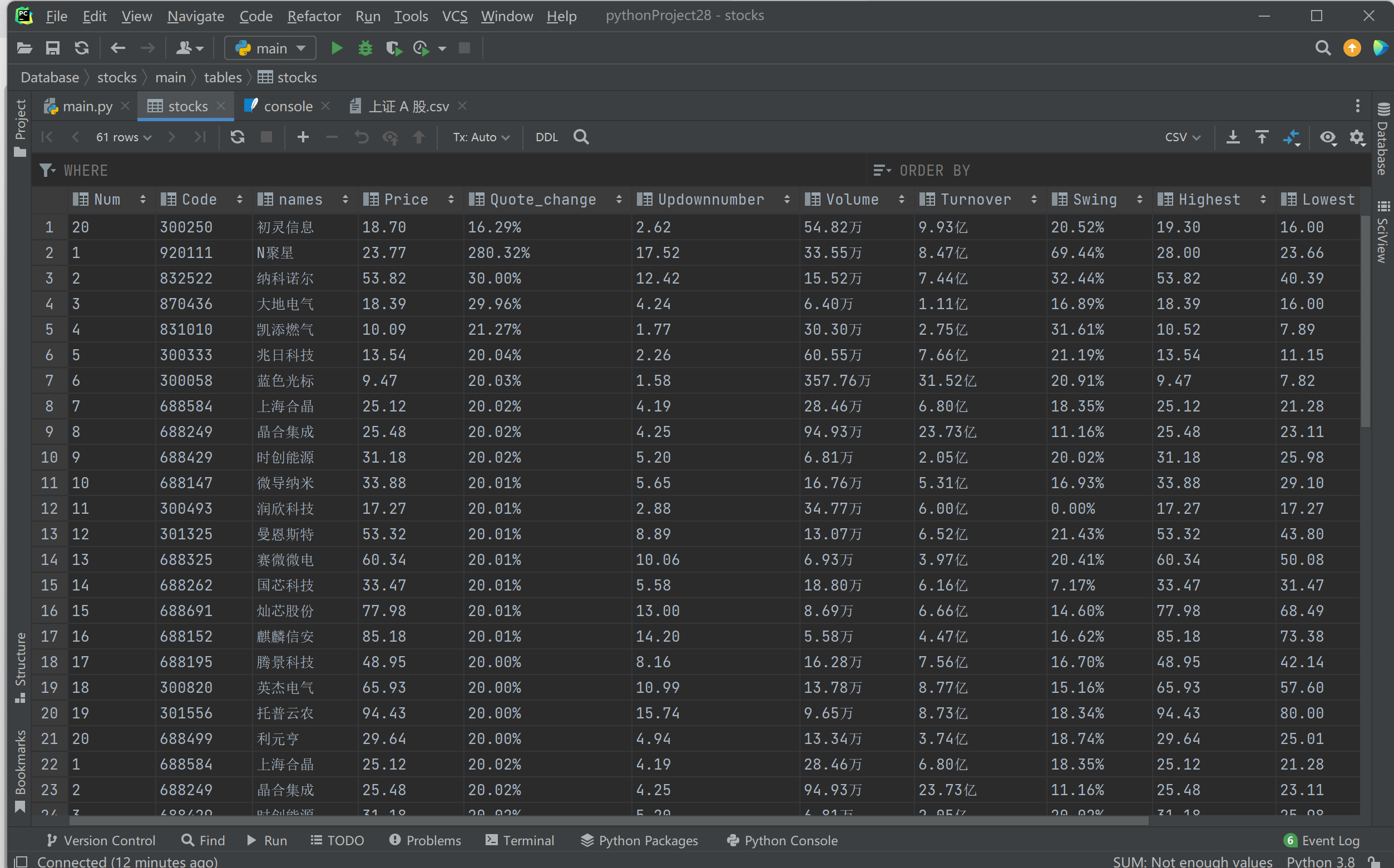
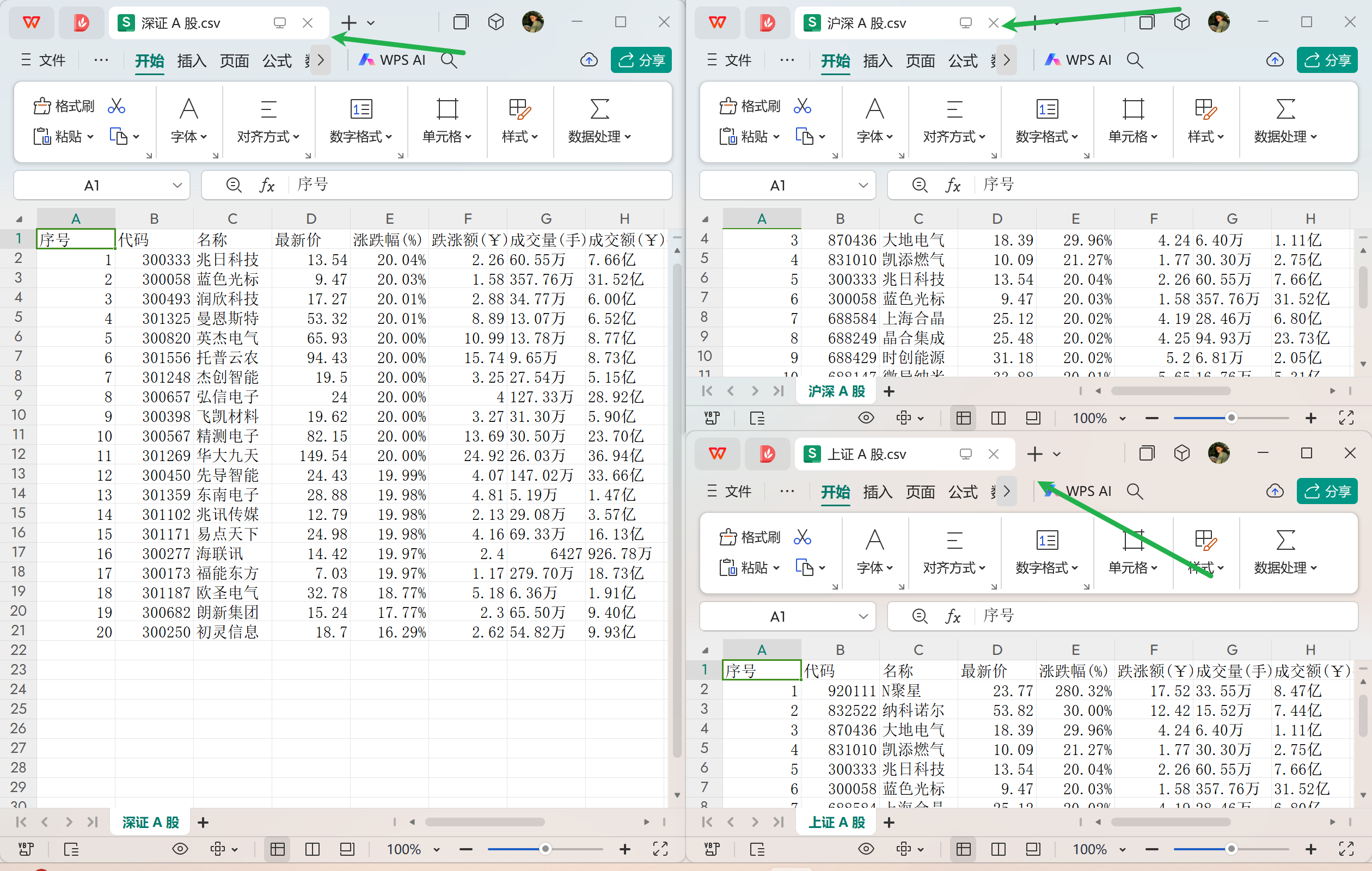
运行结果:
心得体会:
完成这个作业的过程中,我深刻体会到了Selenium的强大之处,尤其是在处理动态加载的数据时。通过学习如何查找HTML元素、等待页面元素加载以及爬取Ajax网页数据,我更加了解自动化浏览和数据抓取的核心技能。整个项目让我对Web爬虫有了更深入的理解,并激发了我对数据分析领域的兴趣。
作业2
要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
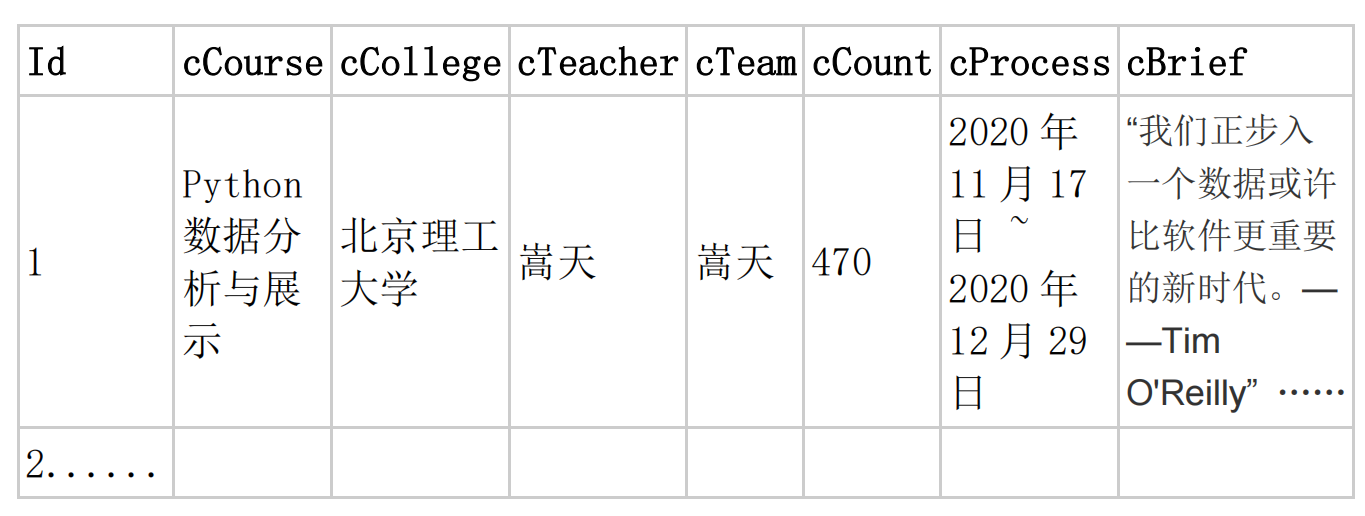
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
输出信息:
MYSQL 数据库存储和输出格式
码云地址:https://gitee.com/wanghew/homework/tree/master/作业4
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import sqlite3
# 设置数据库
def setup_database():
conn = sqlite3.connect('mooc.db')
cursor = conn.cursor()
cursor.execute("DROP TABLE IF EXISTS mooc")
cursor.execute("""
CREATE TABLE mooc (
Id INTEGER PRIMARY KEY AUTOINCREMENT,
course_name TEXT,
college_name TEXT,
teacher_name TEXT,
team_name TEXT,
count_info TEXT,
process_info TEXT,
brief_description TEXT
)
""")
return conn, cursor
# 登录函数
def login(driver, account, password, login_url):
driver.get(login_url)
time.sleep(1)
# 切换到手机号登录方式
phone_login_btn_selector = "//ul[@class='ux-tabs-underline_hd']//li"
phone_login_btn = driver.find_element(By.XPATH, phone_login_btn_selector)
phone_login_btn.click()
# 切换到登录框iframe
iframe_selector = "//div[@class='ux-login-set-container']/iframe"
driver.switch_to.frame(driver.find_element(By.XPATH, iframe_selector))
# 输入账号密码并登录
account_input_selector = "//input[@class='dlemail j-nameforslide']"
password_input_selector = "//input[@class='j-inputtext dlemail']"
login_button_selector = "//a[@class='u-loginbtn btncolor tabfocus ']"
account_input = driver.find_element(By.XPATH, account_input_selector)
password_input = driver.find_element(By.XPATH, password_input_selector)
login_button = driver.find_element(By.XPATH, login_button_selector)
account_input.send_keys(account)
password_input.send_keys(password)
login_button.click()
time.sleep(2)
print("登录成功")
# 搜索函数
def search(driver, keyword, url):
driver.get(url)
time.sleep(1)
try:
search_input_selector = '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div/div[1]/span'
search_input = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.XPATH, search_input_selector))
)
driver.execute_script("arguments[0].click();", search_input)
driver.execute_script("arguments[0].scrollIntoView();", search_input)
search_box_selector = '//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[1]/div/div/div[1]/span/input'
search_box = driver.find_element(By.XPATH, search_box_selector)
search_box.send_keys(keyword)
search_box.send_keys(Keys.ENTER)
time.sleep(2)
print("搜索完成,准备开始爬取")
except Exception as e:
print("未能找到或无法与搜索框交互:", e)
def process_spider(driver, conn, cursor, max_pages=9):
page_num = 0
while page_num < max_pages:
page_num += 1
print(f"爬取第 {page_num} 页")
data_list_selector = "//div[@class='cnt f-pr']"
data_list = driver.find_elements(By.XPATH, data_list_selector)
time.sleep(2)
for data in data_list:
try:
course_name_selector = "./div[@class='t1 f-f0 f-cb first-row']"
college_name_selector = ".//a[@class='t21 f-fc9']"
teacher_name_selector = ".//a[@class='f-fc9']"
team_name_selector = ".//a[@class='f-fc9']"
count_info_selector = ".//span[@class='hot']"
process_info_selector = ".//span[@class='txt']"
brief_description_selector = ".//span[@class='p5 brief f-ib f-f0 f-cb']"
course_name = data.find_element(By.XPATH, course_name_selector).text
college_name = data.find_element(By.XPATH, college_name_selector).text
teacher_name = data.find_element(By.XPATH, teacher_name_selector).text
team_name = data.find_element(By.XPATH, team_name_selector).text
count_info = data.find_element(By.XPATH, count_info_selector).text
process_info = data.find_element(By.XPATH, process_info_selector).text
brief_description = data.find_element(By.XPATH, brief_description_selector).text
cursor.execute(
"INSERT INTO mooc (course_name, college_name, teacher_name, team_name, count_info, process_info, brief_description) VALUES (?,?,?,?,?,?,?)",
(course_name, college_name, teacher_name, team_name, count_info, process_info, brief_description)
)
conn.commit()
print(course_name)
except Exception as e:
print("爬取数据失败:", e)
pass
try:
end_selector = "//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']"
driver.find_element(By.XPATH, end_selector)
print("爬取结束")
break
except:
next_page_selector = "//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']"
next_page = driver.find_element(By.XPATH, next_page_selector)
next_page.click()
time.sleep(3)
def main():
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
conn, cursor = setup_database()
account = input("请输入你的账号:")
password = input("请输入你的密码:")
keyword = input("请输入要搜索的课程:")
login(driver, account, password, "https://www.icourse163.org/member/login.htm#/webLoginIndex")
search(driver, keyword, "https://www.icourse163.org")
process_spider(driver, conn, cursor, max_pages=3)
driver.quit()
conn.close()
if __name__ == "__main__":
main()
效果图:

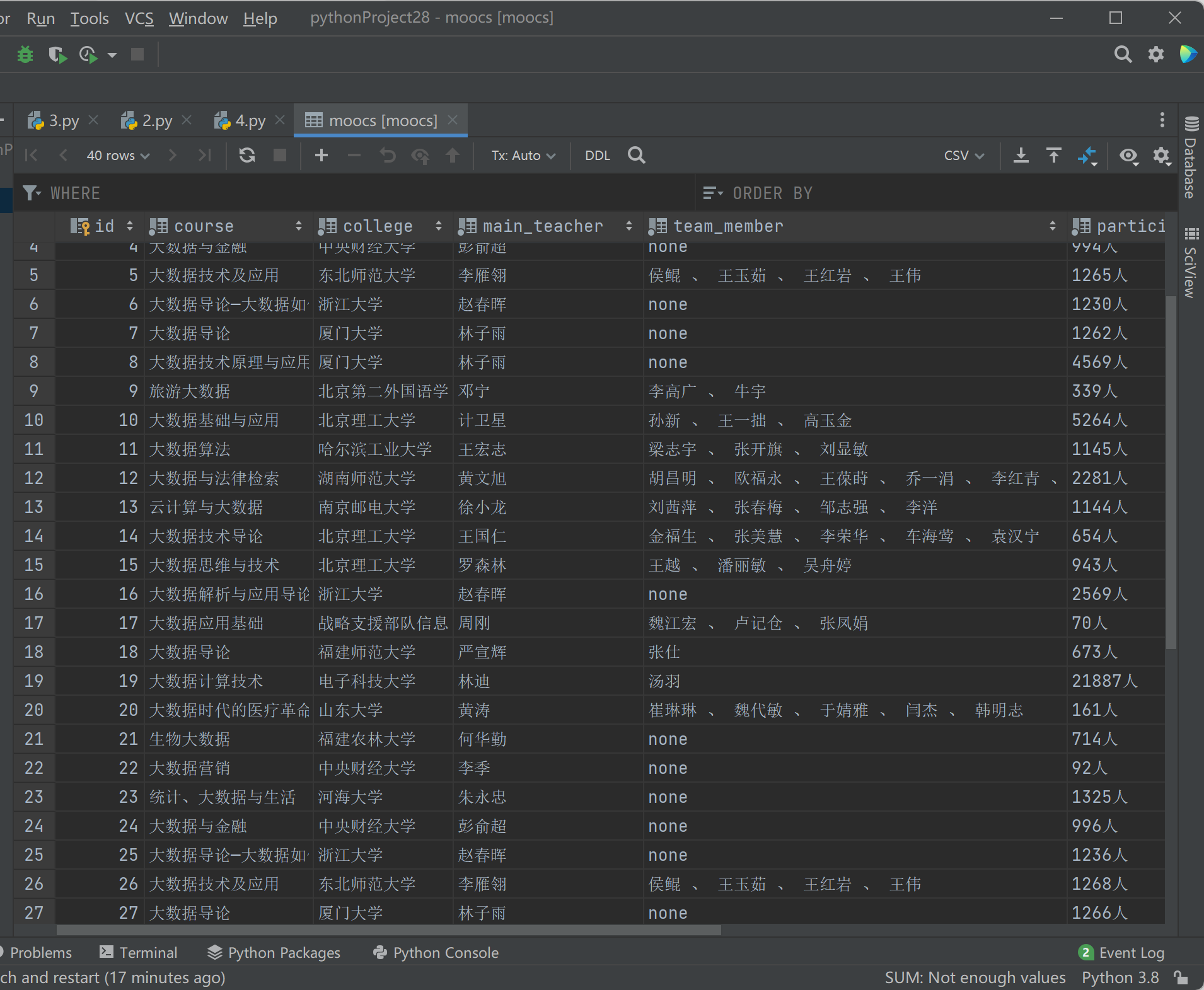
心得体会:
完成这个基于Selenium和MySQL的中国MOOC网课程资源信息爬取项目,确实是一段充满挑战的经历。过程中遇到了许多技术难题,例如实现用户模拟登录、精确获取动态加载的数据等,都需要不断调试与优化。虽然面对着复杂的网页结构和频繁变化的页面元素感到压力山大,但通过查阅资料、反复实践,最终成功实现了数据的高效抓取与存储。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
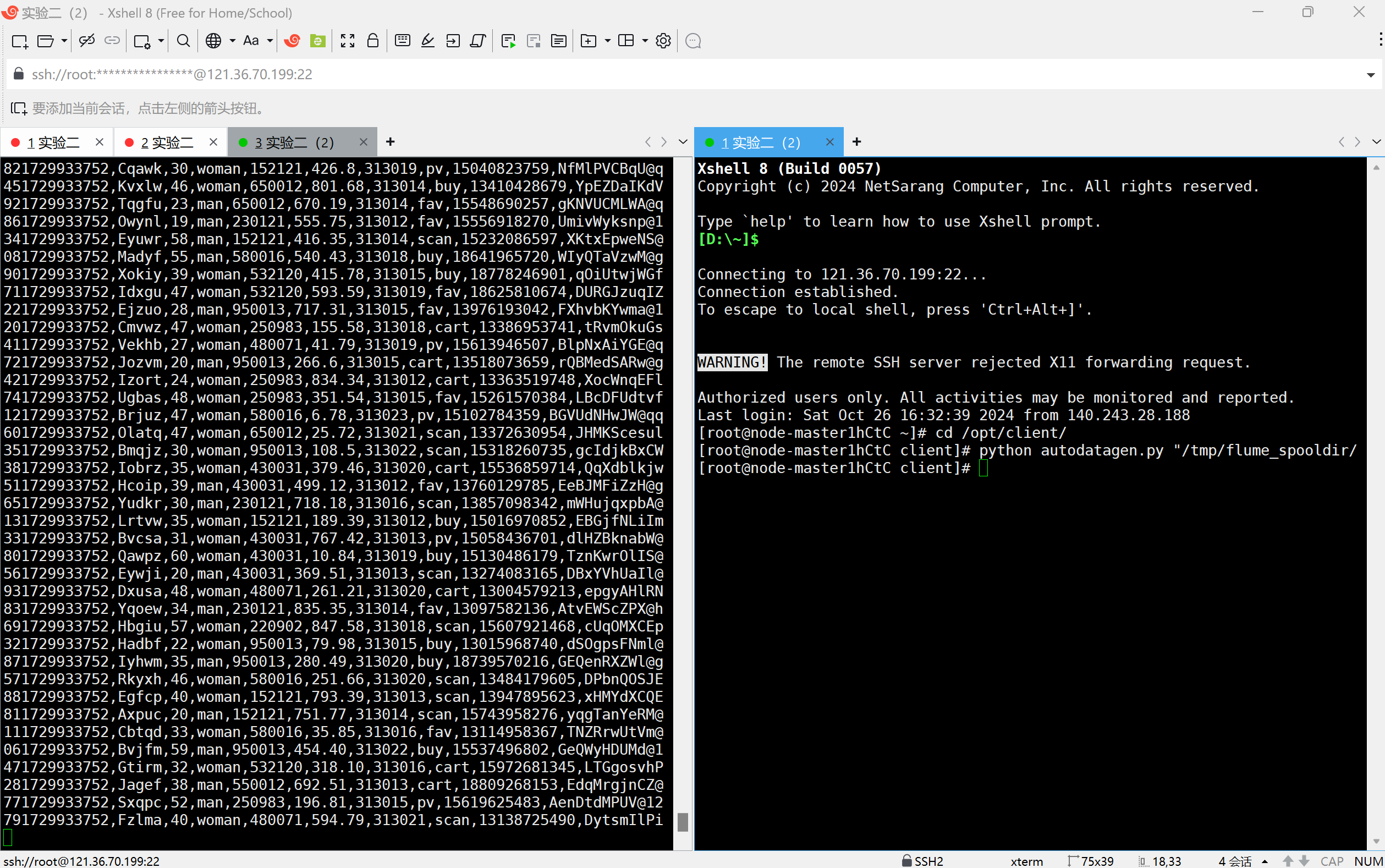
任务一:Python脚本生成测试数据

复制脚本代码
创建存放测试的数据目录
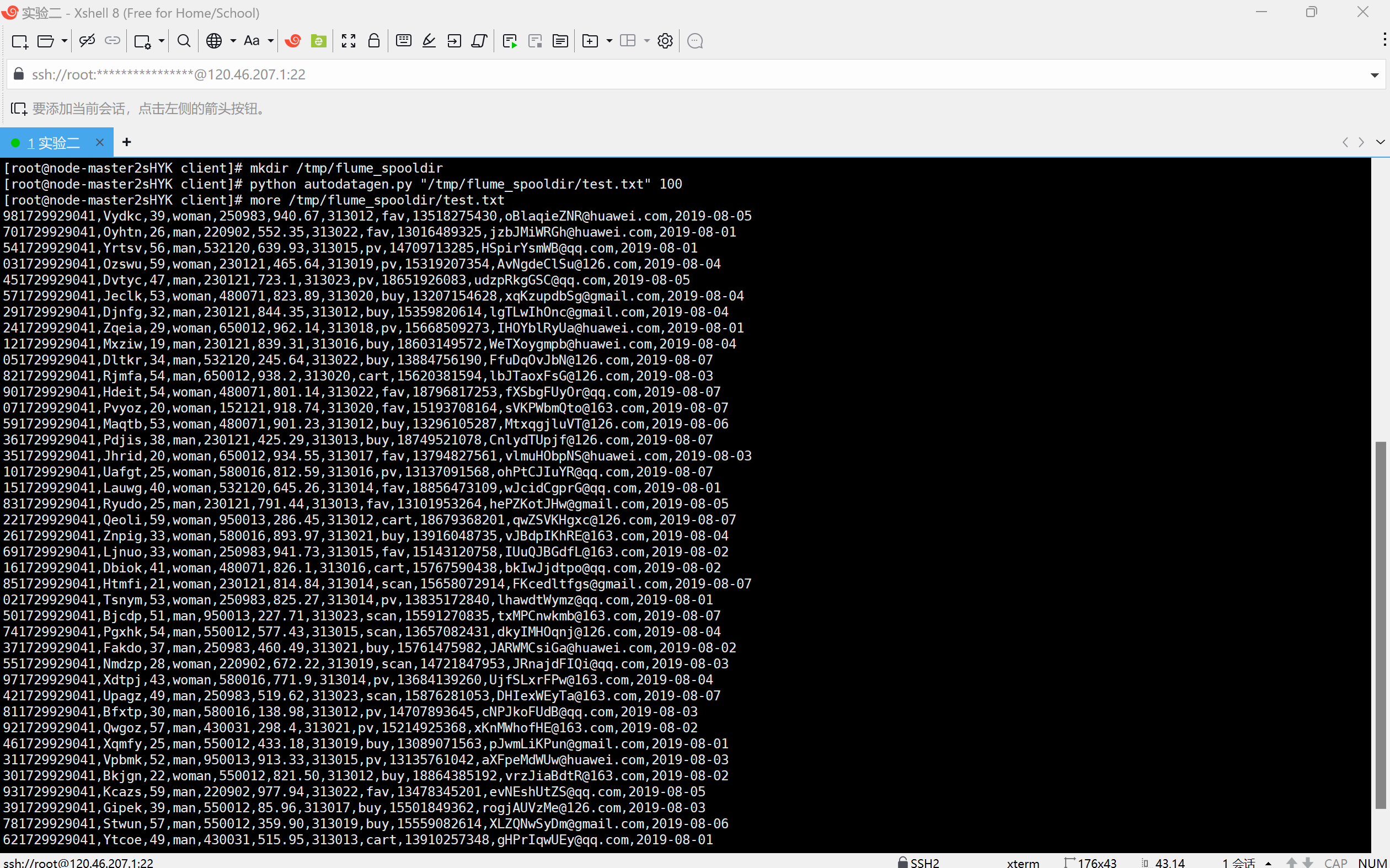
执行测试
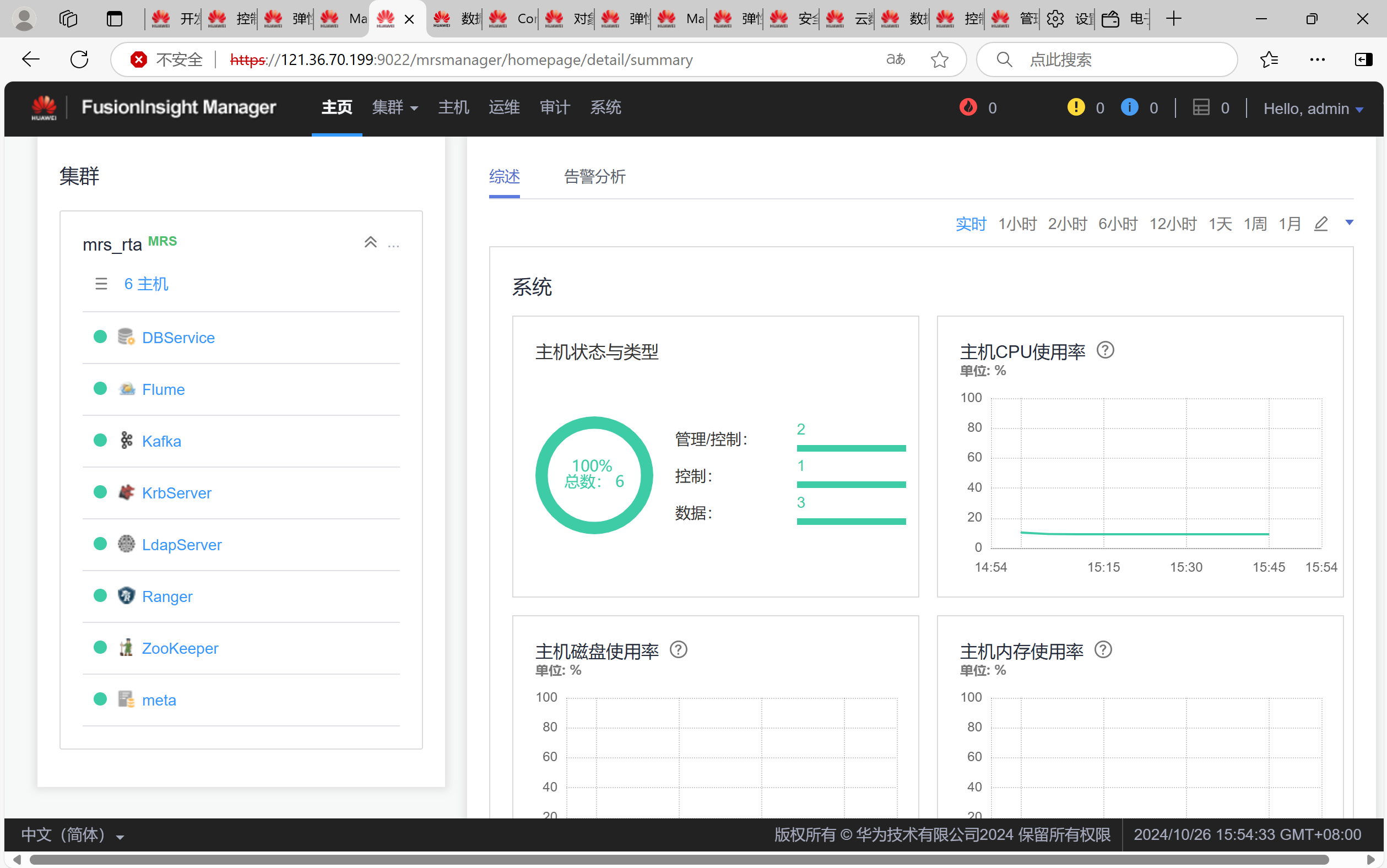
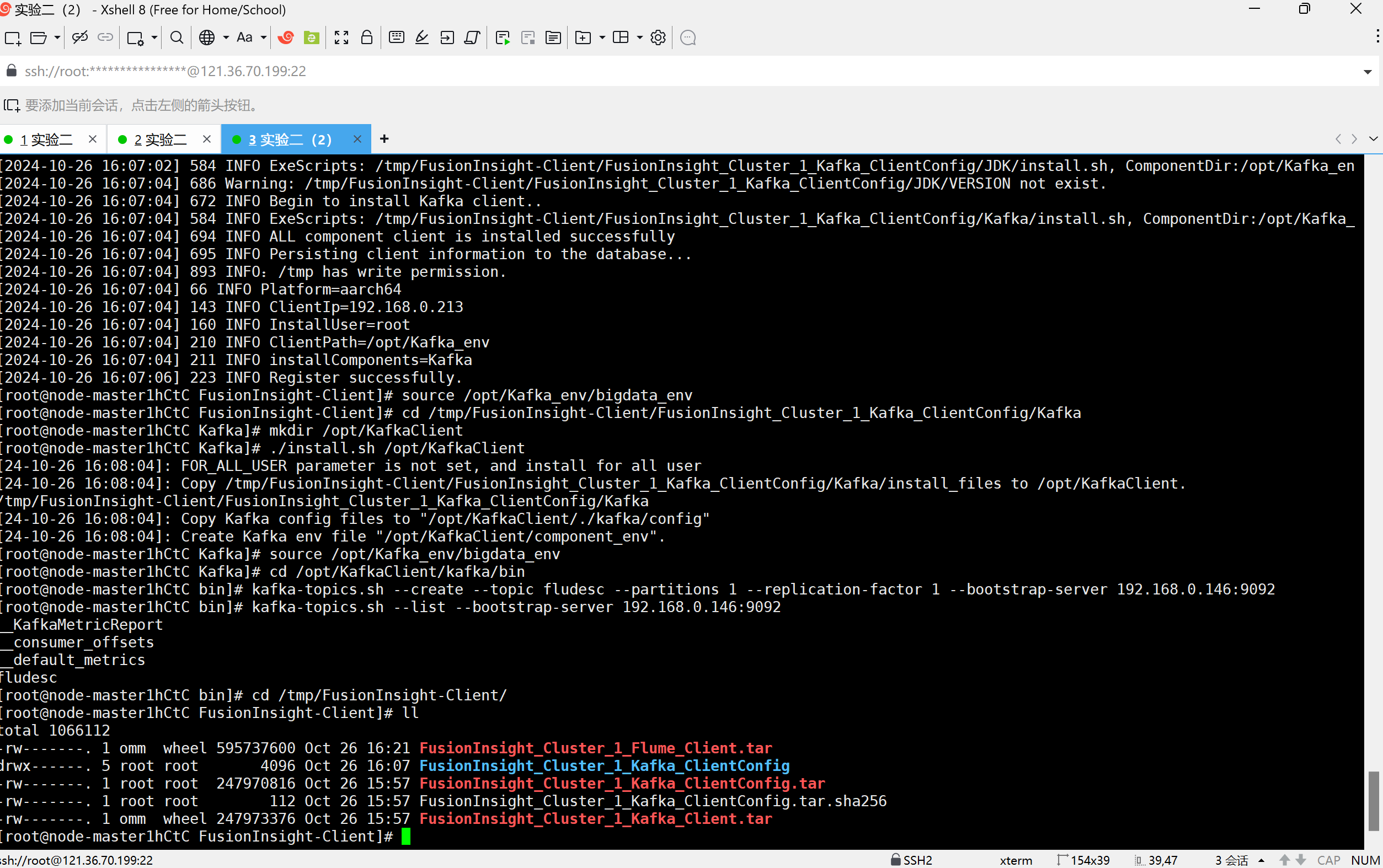
任务二:配置Kafka
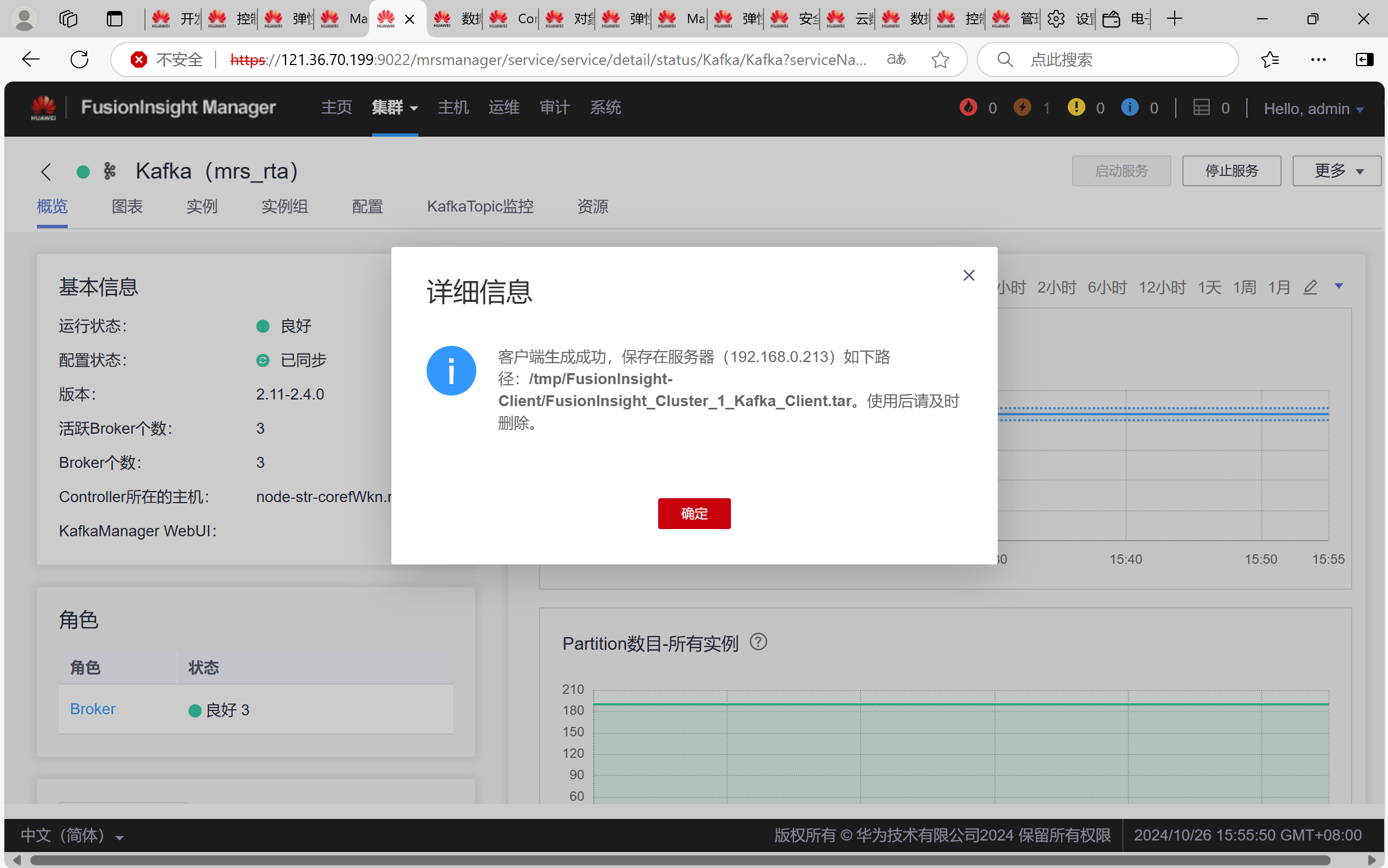
校验下载的客户端文件包
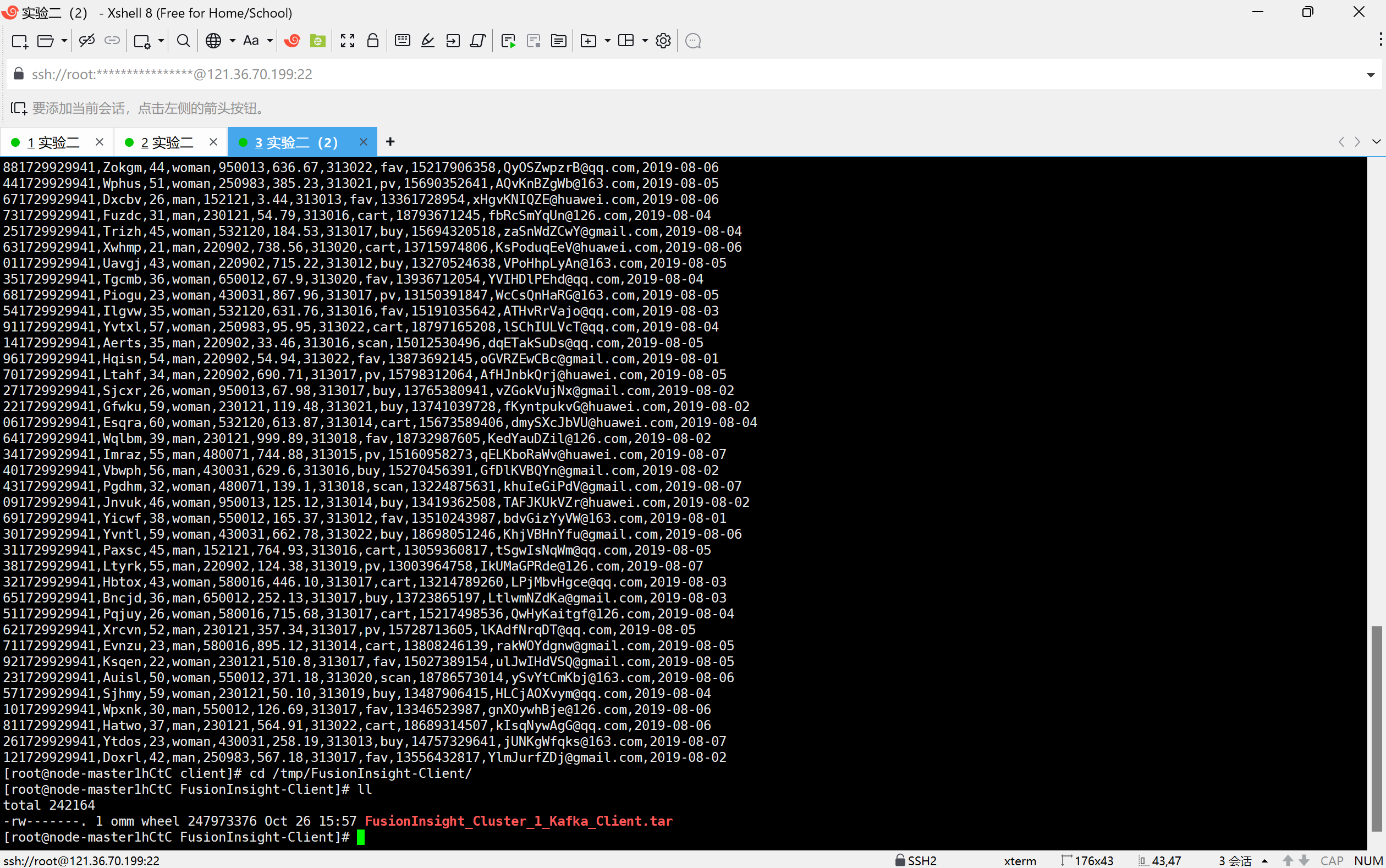
安装Kafka运行环境

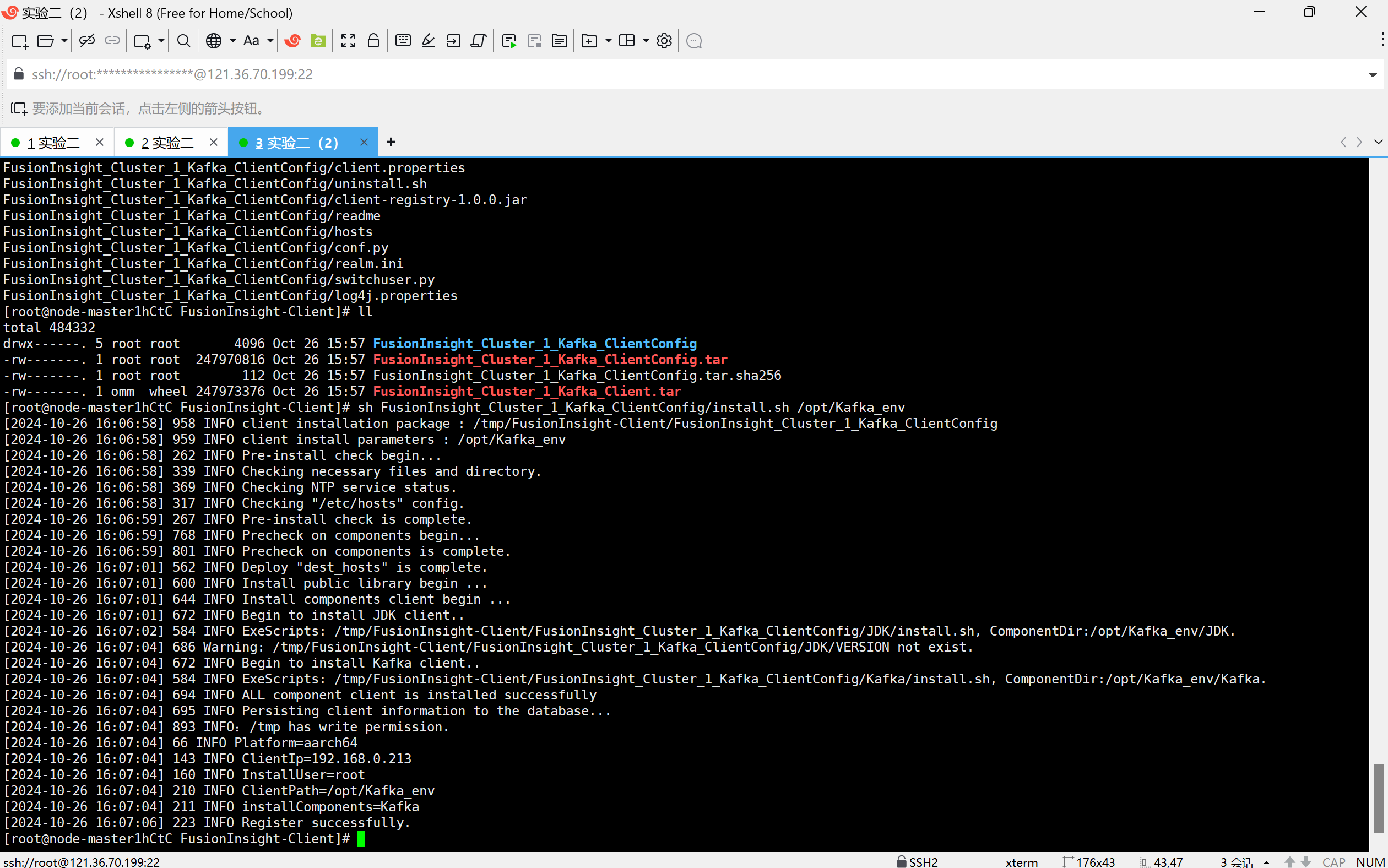
安装Kafka客户端
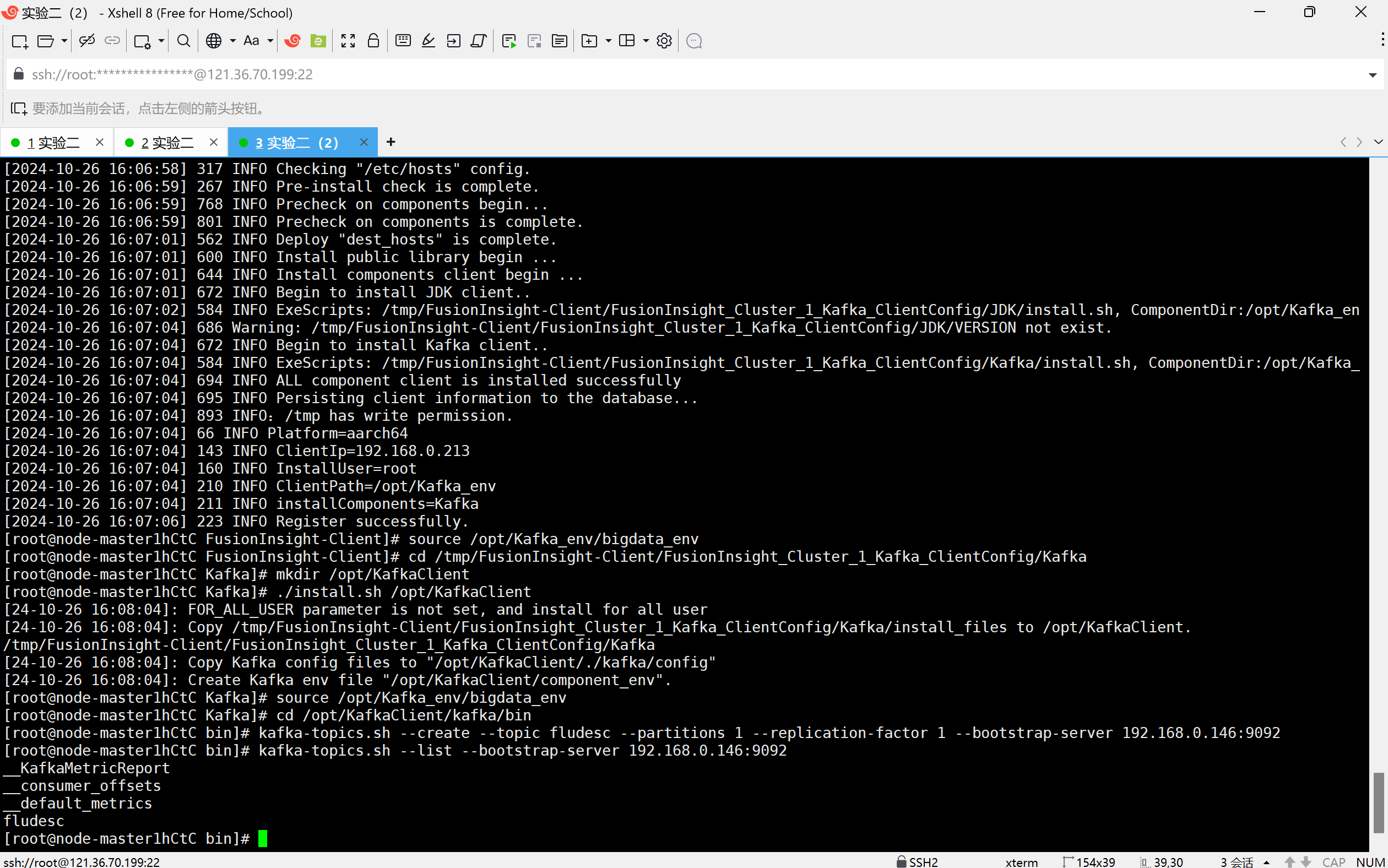
任务三: 安装Flume客户端
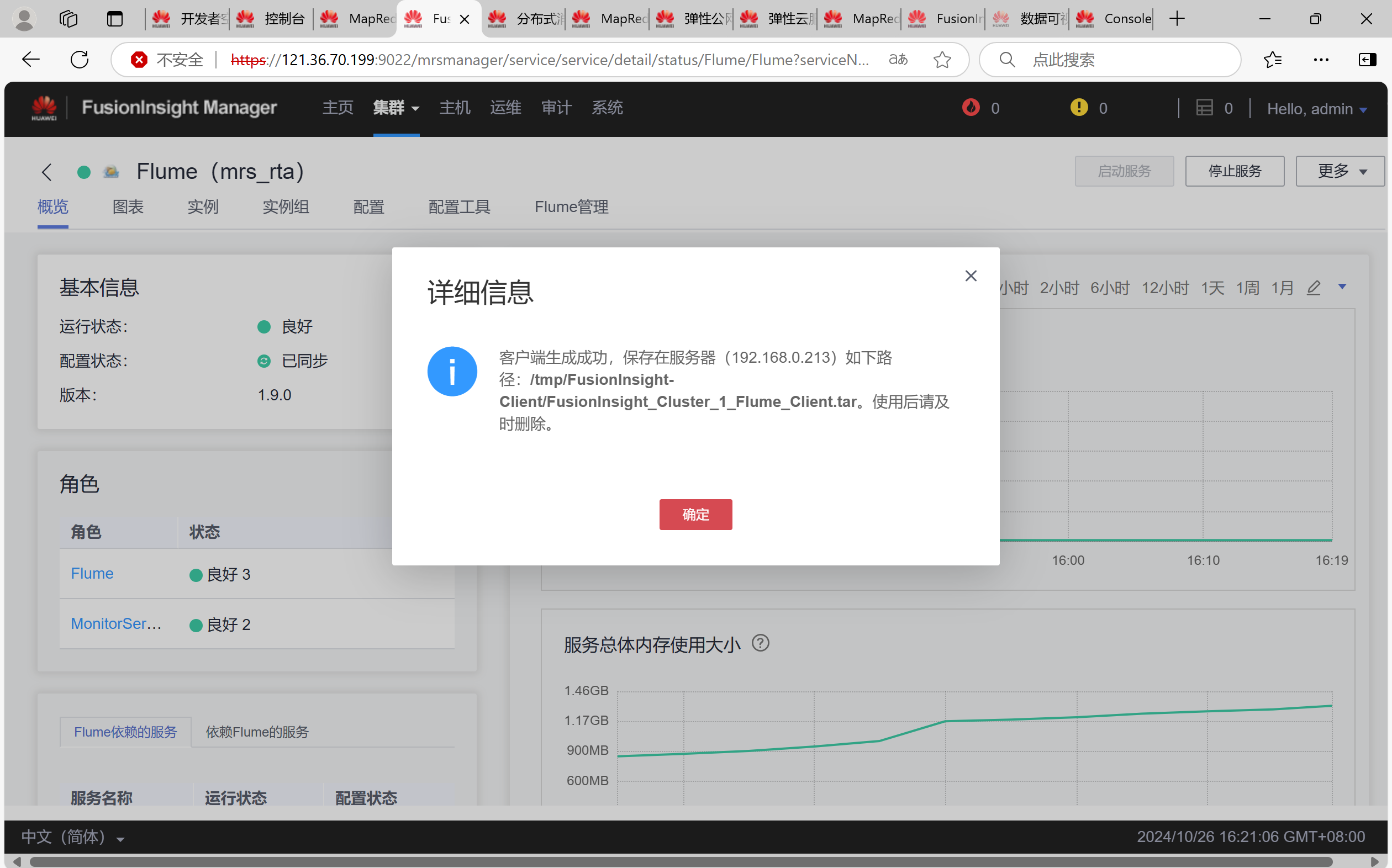
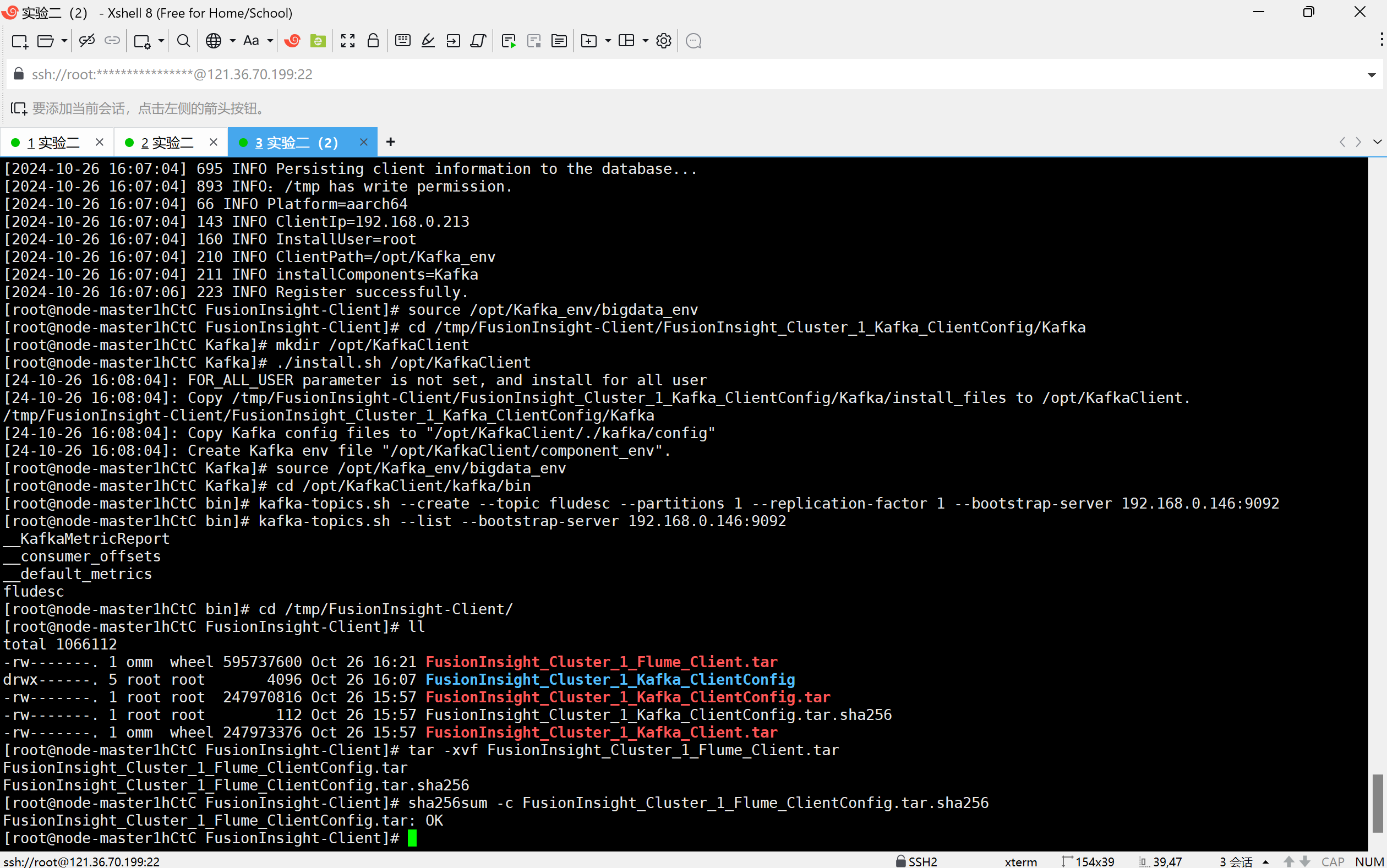

任务四:配置Flume采集数据
心得体会
完成这一系列任务后,我深刻体验到了大数据处理流程中的各个环节是如何协同工作的。首先,通过Python脚本生成测试数据不仅提高了我对Python编程的理解,还让我认识到准备高质量测试数据的重要性。接着,在配置Kafka时,了解到消息队列对于构建可扩展且可靠的系统是多么关键。安装并配置Flume客户端则进一步加强了我对数据收集工具的认识,特别是它在从不同源高效地聚合日志数据方面的能力。整个过程虽然充满了技术上的挑战,如环境配置问题、版本兼容性等,但也极大地丰富了我的实战经验,增强了我在分布式系统中的工作能力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号