
作业3
作业1:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
码云文件夹链接:https://gitee.com/wanghew/homework/tree/master/作业3
- 首先创建scrpy框架:
- 项目结构:
ChinaWeather/
│
├── ChinaWeather/ # 主模块目录
│ ├── __init__.py # 使该目录成为一个Python包
│ ├── items.py # 定义抓取的数据项
│ ├── middlewares.py # 中间件定义
│ ├── pipelines.py # 数据处理管道
│ ├── settings.py # 项目配置
│ └── spiders/ # 爬虫定义
│ ├── __init__.py # 使该目录成为一个Python包
│ └── mySpider.py # 具体的爬虫逻辑
├── images/ # 图片存储目录
├── run.py # 运行爬虫的脚本
└── scrapy.cfg # Scrapy项目的配置文件
items.py:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ChinaWeatherItem(scrapy.Item):
src = scrapy.Field()
mySpider.py:
import scrapy
from ..items import ChinaWeatherItem
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
selector = scrapy.Selector(response)
srcs = selector.xpath('//img/@src | //img/@data-src').extract()
for src in srcs:
if src.startswith('//'):
src = 'http:' + src # 补全URL
elif not src.startswith('http'):
src = response.urljoin(src) # 转换为绝对路径
print(src)
item = ChinaWeatherItem()
item['src'] = src
yield item
# 跟进其他页面链接
for next_page in response.css('a::attr(href)').getall():
if next_page is not None and not next_page.startswith('#'):
next_page = response.urljoin(next_page)
yield response.follow(next_page, self.parse)
pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import os
import urllib.request
from itemadapter import ItemAdapter
class ChinaWeatherPipeline:
count = 0
max_count = 155 # 限制下载的图片数量
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"
}
def process_item(self, item, spider):
if self.count >= self.max_count:
raise scrapy.exceptions.CloseSpider('Download limit reached')
try:
self.count += 1
src = item['src']
if src.endswith(('.jpg', '.jpeg', '.png', '.gif')):
ext = os.path.splitext(src)[1]
else:
ext = ".jpg" # 默认扩展名
req = urllib.request.Request(src, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100).read()
# 确保images目录存在
if not os.path.exists('images'):
os.makedirs('images')
# 将下载的图像文件写入本地文件夹
file_path = os.path.join('images', f"{self.count}{ext}")
with open(file_path, 'wb') as fobj:
fobj.write(data)
print(f"downloaded {file_path} - Total: {self.count}")
except Exception as err:
print(err)
return item
settings.py
BOT_NAME = 'ChinaWeather'
SPIDER_MODULES = ['ChinaWeather.spiders']
NEWSPIDER_MODULE = 'ChinaWeather.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'ChinaWeather.pipelines.ChinaWeatherPipeline': 300,
}
# 设置日志级别
LOG_LEVEL = 'DEBUG'
# 单线程配置
# CONCURRENT_REQUESTS = 1
# DOWNLOAD_DELAY = 1
# 多线程配置
CONCURRENT_REQUESTS = 32
DOWNLOAD_DELAY = 0.5
单线程运行脚本 run_single_thread.py:
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from ChinaWeather.spiders.mySpider import MySpider
def main():
settings = get_project_settings()
settings.set('CONCURRENT_REQUESTS', 1)
settings.set('DOWNLOAD_DELAY', 1)
process = CrawlerProcess(settings)
process.crawl(MySpider)
process.start()
if __name__ == "__main__":
main()
多线程运行脚本 run_multi_thread.py
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from ChinaWeather.spiders.mySpider import MySpider
def main():
settings = get_project_settings()
settings.set('CONCURRENT_REQUESTS', 32)
settings.set('DOWNLOAD_DELAY', 0.5)
process = CrawlerProcess(settings)
process.crawl(MySpider)
process.start()
if __name__ == "__main__":
main()
运行结果:
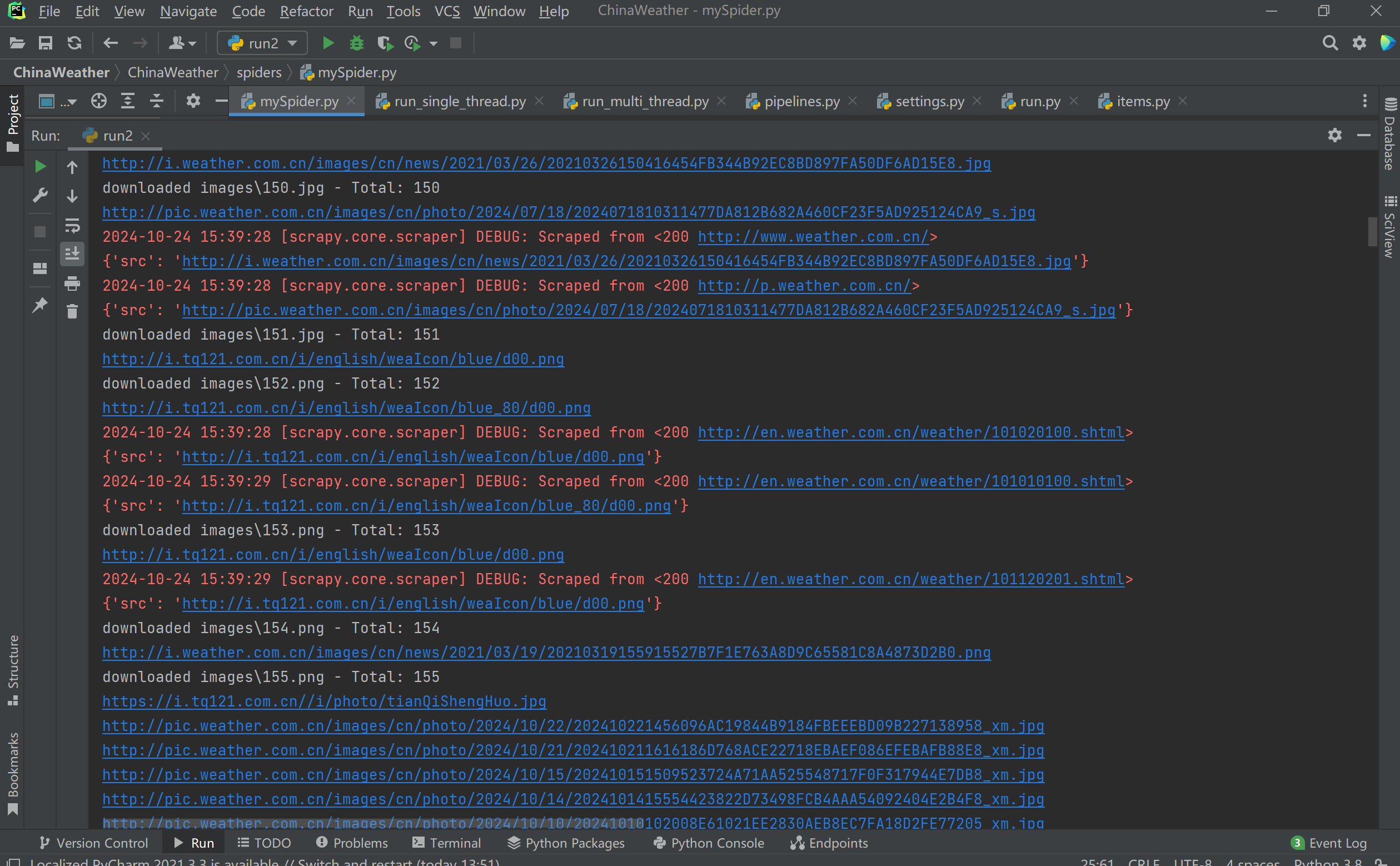
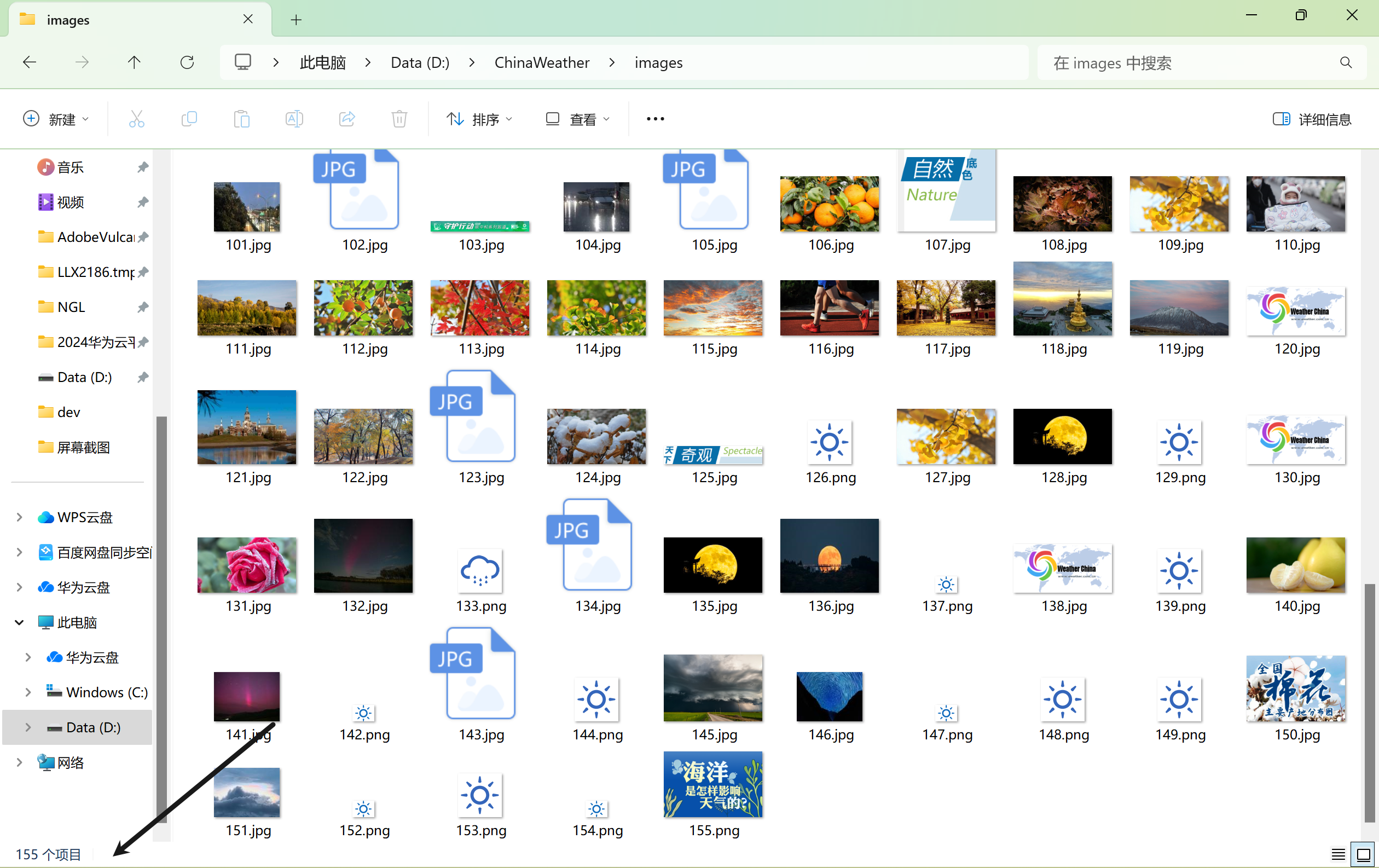
心得体会:
巩固了用scrapy来爬取图片,原本只能爬取50张图片,经过多次尝试成功下载155张图片,但还是一个小bug,程序爬取了155张后,还没有停止运行,后续有时间看能不能解决。
作业②
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
码云链接:https://gitee.com/wanghew/homework/tree/master/作业3
EastmoneyStocks/
│
├── scrapy.cfg
├── run.py
├── spiders
│ └── eastmoney_spider.py
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── eastmoney.db
items.py
import scrapy
class EastmoneyItem(scrapy.Item):
data = scrapy.Field()
number = scrapy.Field()
Eastmoney.py
import scrapy # 导入scrapy库,它是构建网络爬虫的主要框架
import json # 导入json模块,用于解析JSON格式的数据
from ..items import EastmoneyItem # 从项目的items文件中导入定义好的Item类EastmoneyItem
class MoneySpider(scrapy.Spider): # 定义一个名为MoneySpider的爬虫类,继承自scrapy.Spider
name = "money" # 爬虫的名字,必须是唯一的
allowed_domains = ["eastmoney.com"] # 允许爬取的域名列表
start_urls = [ # 起始URL列表,爬虫将从这些URL开始抓取
"http://65.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406736638761710398_1697718587304&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697718587305"
]
def parse(self, response): # 定义parse方法,这是默认的回调函数,处理start_urls中的响应
# 解析JSON数据
response_text = response.text # 获取响应的文本内容
response_text = response_text[42:-2] # 去掉响应文本中的JSONP回调函数包装
data = json.loads(response_text) # 使用json.loads将字符串转换为Python字典
diff_data = data['data']['diff']
number = 1 # 初始化一个计数器
for d in diff_data:
item = EastmoneyItem() # 创建一个EastmoneyItem实例
item['data'] = d # 将当前遍历到的数据项赋值给item的'data'字段
item['number'] = number # 将当前计数器的值赋给item的'number'字段
number += 1 # 计数器加一
yield item # 生成item,将其传递给Scrapy管道进行进一步处理
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import sqlite3
# 定义EastmoneyPipeline类,用于处理数据存储到SQLite数据库相关操作
class EastmoneyPipeline(object):
# 类属性,用于存储数据库连接对象
con = None
# 类属性,用于存储数据库游标对象
cursor = None
# 在爬虫启动时执行的方法
def open_spider(self, spider):
# 连接到名为eastmoney.db的SQLite数据库
self.con = sqlite3.connect("eastmoney.db")
# 创建游标对象,用于执行SQL语句
self.cursor = self.con.cursor()
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS money (
id INTEGER PRIMARY KEY AUTOINCREMENT,
stocksymbol VARCHAR(16),
stockname VARCHAR(16),
LatestPrice VARCHAR(16),
Pricelimit VARCHAR(16),
Riseandfall VARCHAR(16),
volume VARCHAR(16),
turnover VARCHAR(16),
amplitude VARCHAR(16),
max VARCHAR(16),
min VARCHAR(16),
today VARCHAR(16),
yesterday VARCHAR(16)
)
""")
# 提交事务,使表创建操作生效
self.con.commit()
# 处理每个数据项的方法,这里是将数据插入到数据库中
def process_item(self, item, spider):
try:
# 获取item中的'data'部分
data = item['data']
# 执行插入操作,将数据插入到money表中。使用?作为占位符,避免SQL注入
self.cursor.execute("""
INSERT INTO money (stocksymbol, stockname, LatestPrice, Pricelimit, Riseandfall, volume, turnover, amplitude, max, min, today, yesterday)
VALUES (?,?,?,?,?,?,?,?,?,?,?,?)
""", (data['f12'], data['f14'], data['f2'], data['f3'], data['f4'], data['f5'], data['f6'], data['f7'], data['f15'], data['f16'], data['f17'], data['f18']))
print("Successfully inserted")
# 提交事务,使插入操作生效
self.con.commit()
except Exception as e:
print(f"Error inserting data: {e}")
# 如果插入出现错误,回滚事务
self.con.rollback()
return item
# 在爬虫关闭时执行的方法
def close_spider(self, spider):
# 关闭游标
self.cursor.close()
# 关闭数据库连接
self.con.close()
setting.py
# 是否遵守robots.txt规则
ROBOTSTXT_OBEY = False
# 启用的管道
ITEM_PIPELINES = {
'EastmoneyStocks.pipelines.EastmoneyPipeline': 300,
}
# 设置日志级别
LOG_LEVEL = 'INFO'
# 设置并发请求
CONCURRENT_REQUESTS = 16 # 单线程模式下可以设为1
DOWNLOAD_DELAY = 0.5 # 下载延迟,防止被封IP
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl money".split())
效果图:
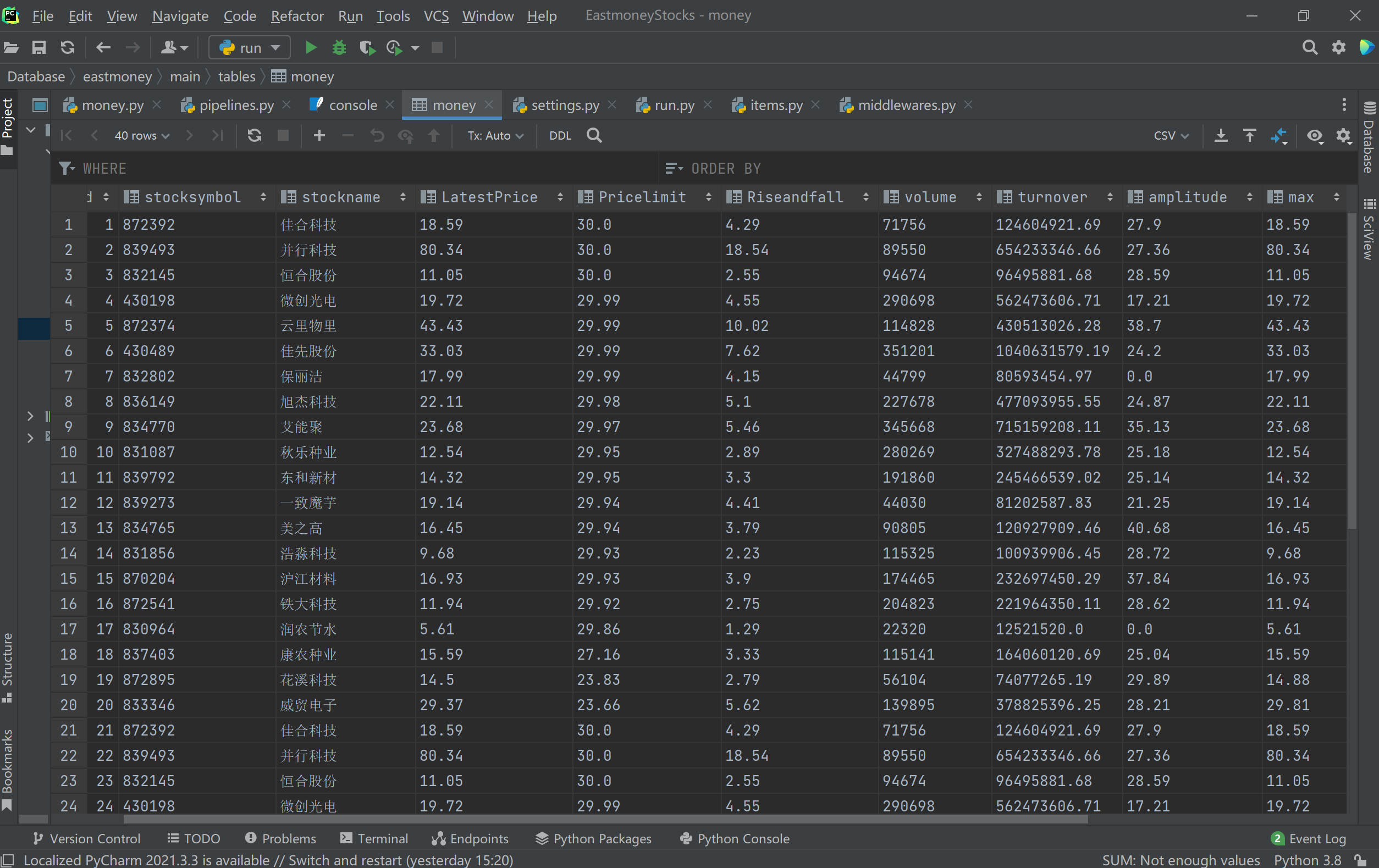
心得体会:
熟练掌握了 Scrapy 框架,了解其核心组件的作用。运用 Xpath 准确提取东方财富网股票信息,虽页面复杂,但耐心分析后能精准定位数据。在 MySQL 存储方面,学会配置连接、设计表结构和插入数据。
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
仓库链接:https://gitee.com/wanghew/homework/tree/master/作业3
- 项目结构
bank_of_china/
├── bank_of_china/
│ ├── spiders/
│ │ ├── __init__.py
│ │ └── bank.py
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── main.py
├── scrapy.cfg
bank.py
import scrapy
# 导入tabulate库用于格式化输出表格
from tabulate import tabulate
# 导入自定义的Item类
from bank_of_china.items import BankOfChinaItem
# 定义一个名为BankSpider的Scrapy爬虫
class BankSpider(scrapy.Spider):
# 设置爬虫名称
name = "bank"
# 如果需要限制爬取的域名,可以取消下面这行的注释并设置相应的域名
# start_requests方法定义了爬虫开始时发送的第一个请求
def start_requests(self):
# 定义要爬取的URL
url = 'https://www.boc.cn/sourcedb/whpj/'
# 发送GET请求,并指定回调函数为parse
yield scrapy.Request(url, callback=self.parse)
# parse方法是处理响应的主要逻辑
def parse(self, response):
try:
# 将响应体解码为字符串
data = response.body.decode()
# 创建Selector对象来解析HTML
selector = scrapy.Selector(text=data)
# 使用XPath选择器选取所有tr元素(除了第一个标题行)
datas = selector.xpath("//body//div//div//div//div//tr[position()>1]")
# 初始化一个空列表来保存数据项
items_list = []
# 定义表头
headers = ['Currency', 'TBP', 'CBP', 'TSP', 'CSP', 'Time']
# 遍历每一个tr元素
for data in datas:
# 创建一个新的Item实例
item = BankOfChinaItem()
# 提取货币名称
item["Currency"] = str(data.xpath("./td[1]//text()").get())
# 提取买入价
item["TBP"] = str(data.xpath("./td[2]//text()").get())
# 提出现钞买入价
item["CBP"] = str(data.xpath("./td[3]//text()").get())
# 提现汇卖出价
item["TSP"] = str(data.xpath("./td[4]//text()").get())
# 提现钞卖出价
item["CSP"] = str(data.xpath("./td[5]//text()").get())
# 提取时间
item["Time"] = str(data.xpath("./td[8]//text()").get())
# 打印提取到的item
print(f"Extracted item: {item}")
# 生成并返回item给Scrapy框架
yield item
# 将item转换为list以便于tabulate处理
row_data = [
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
]
# 添加当前行的数据到items_list
items_list.append(row_data)
# 使用tabulate来格式化输出整个数据列表
formatted_table = tabulate(items_list, headers=headers, tablefmt="grid")
# 打印格式化的表格
print(formatted_table)
except Exception as err:
# 捕获异常并打印错误信息
print(f"Error in parse: {err}")
# 标记爬取失败
print("爬取失败")
items.py
import scrapy
class BankOfChinaItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
pass
pipelines.py
import pymysql # 导入pymysql模块,这是一个纯Python实现的MySQL客户端。
class BankOfChinaPipeline:
def process_item(self, item, spider):
# 建立与数据库的连接。
connection = pymysql.connect(
host='127.0.0.1', # 数据库服务器地址,默认使用本地主机
user='root', # 登录数据库的用户名
password='123456', # 对应的密码
database='bank_of_china', # 要操作的数据库名称
charset='utf8'
)
cursor = connection.cursor() # 创建一个游标对象,用于执行SQL语句。
try:
# 执行插入数据的SQL命令。这里假设item是一个字典或类似结构,
cursor.execute(
"INSERT INTO banks (Currency, TBP, CBP, TSP, CSP, Time) VALUES (%s, %s, %s, %s, %s, %s)",
(item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"])
)
connection.commit() # 提交事务,确保更改被写入数据库。
except Exception as err:
# 如果在执行过程中发生异常,则捕获异常并打印错误信息。
print(f"Error inserting data: {err}")
finally:
# 不论是否发生异常,最终都会关闭游标和数据库连接。
cursor.close()
connection.close()
settings.py
BOT_NAME = "bank_of_china"
SPIDER_MODULES = ["bank_of_china.spiders"]
NEWSPIDER_MODULE = "bank_of_china.spiders"
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
"bank_of_china.pipelines.BankOfChinaPipeline": 300,
}
main.py
import os
import sys
from scrapy import cmdline
sys.path.insert(0, os.path.dirname(os.path.abspath(__file__)))
cmdline.execute(['scrapy', "crawl", "bank"])
效果图:
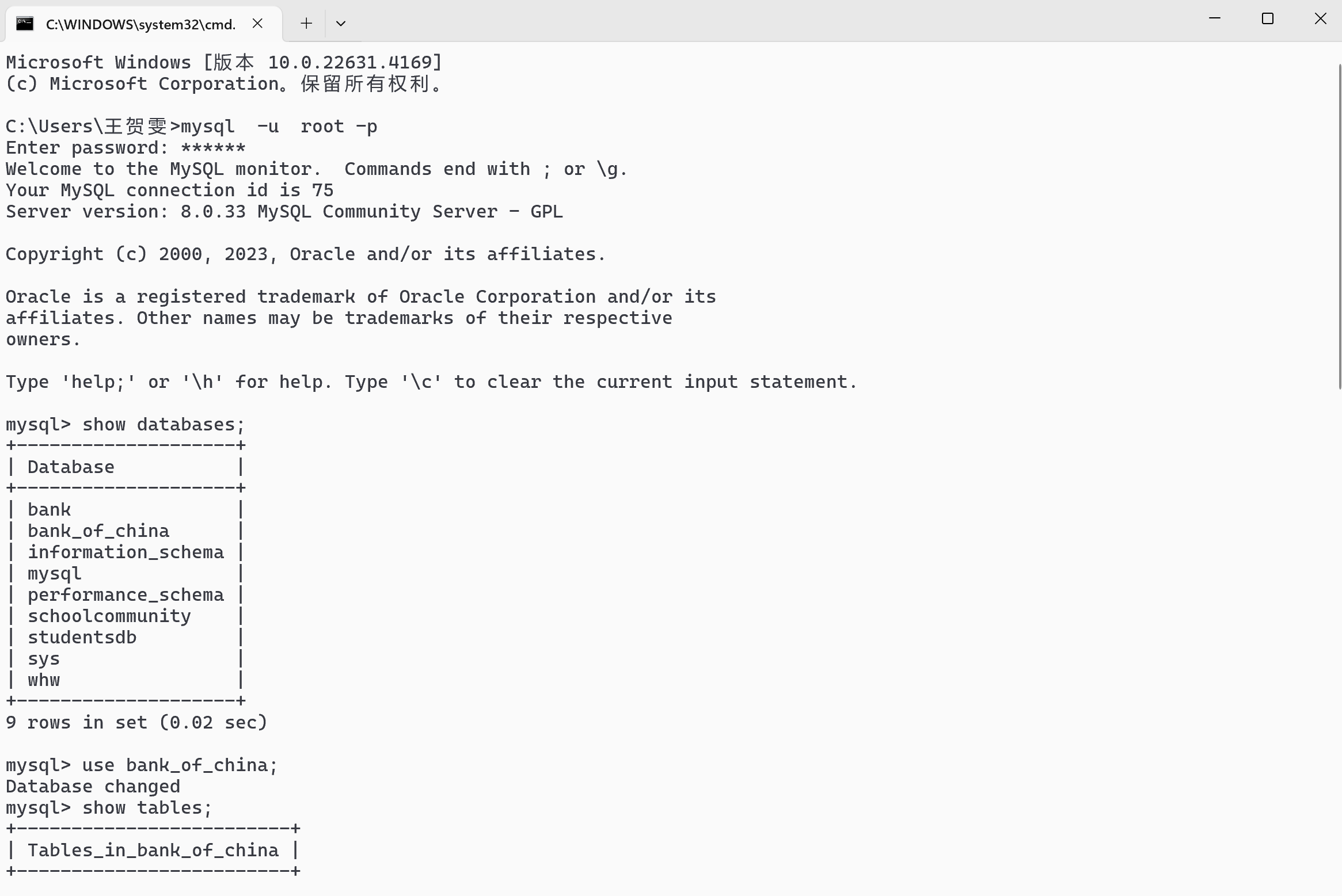
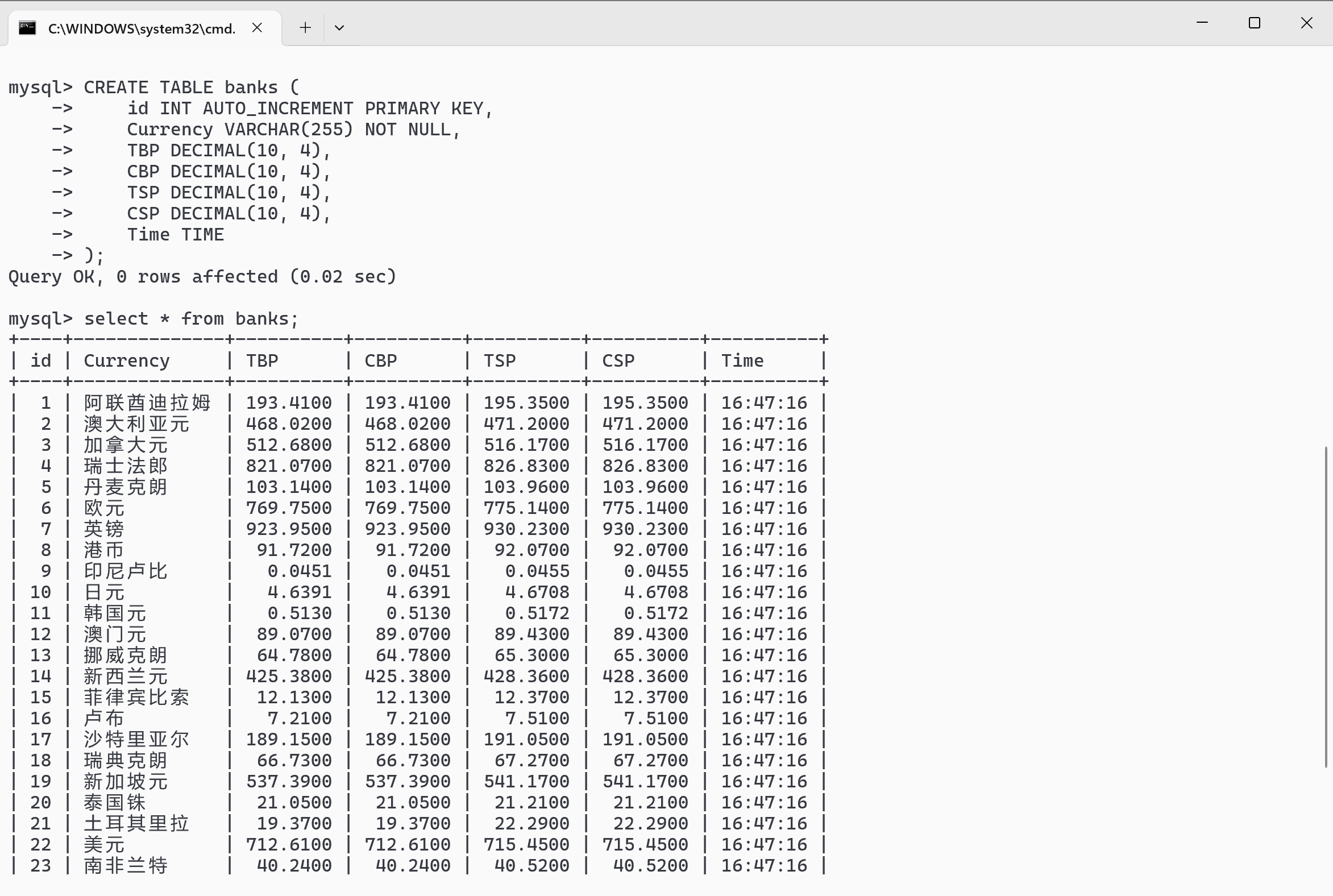
问了ai,在pycharm中可以直接输出结果
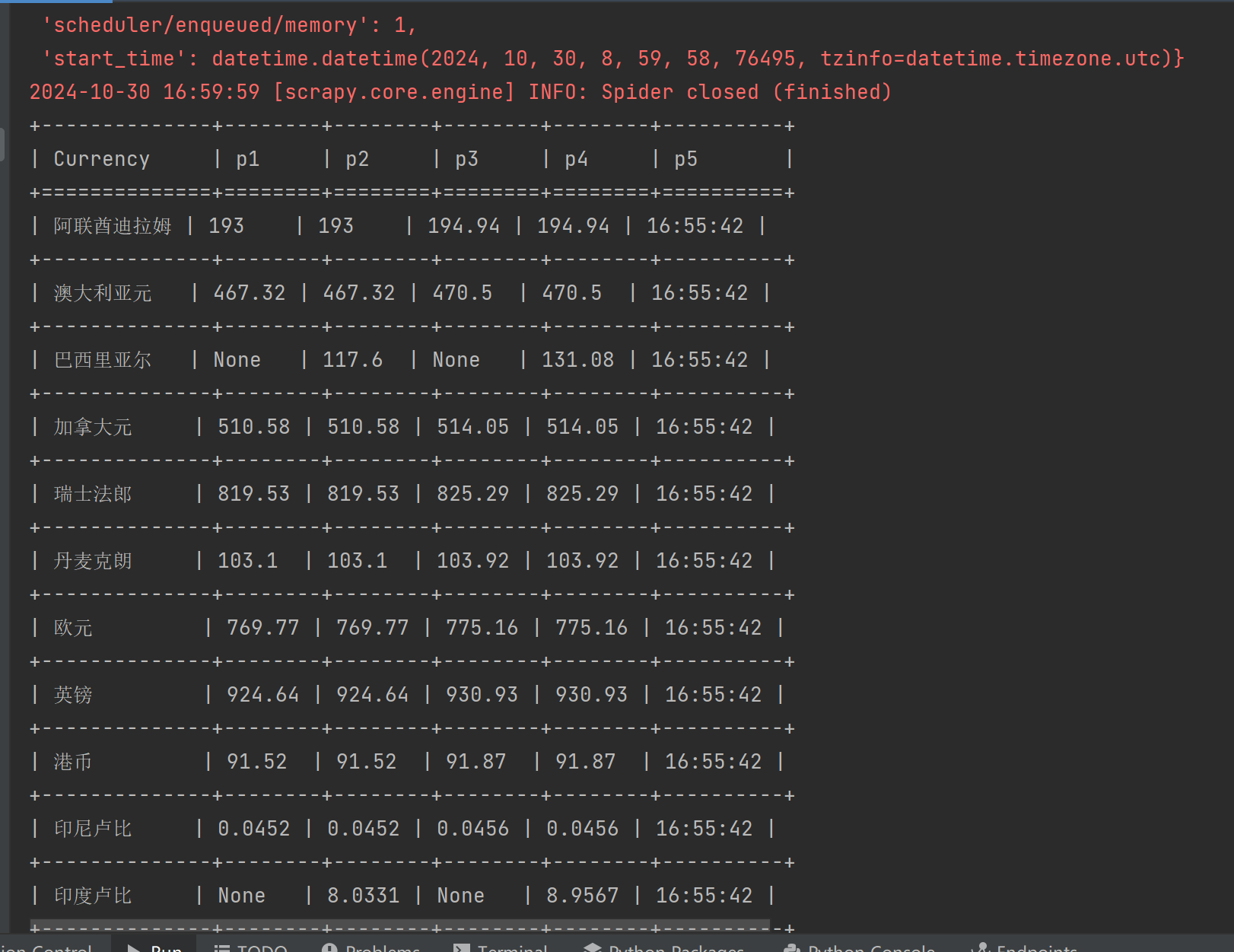
心得体会:
这个难度较大,花费时间较长,出了问题后,在借助AIGC和组长的帮助下,才运行成功,实属不易。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号