作业2
一、作业内容
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
Gitee文件夹链接:https://gitee.com/wanghew/homework/tree/master/作业2
from bs4 import BeautifulSoup # 用于解析HTML和XML文档
from bs4.dammit import UnicodeDammit # 用于处理编码问题
import urllib.request # 用于发送网络请求
import sqlite3 # 用于与SQLite数据库交互
# 定义一个天气数据库类
class WeatherDB:
def __init__(self):
self.cursor = None # 数据库游标
self.con = None # 数据库连接对象
# 打开数据库连接,并尝试创建表
def openDB(self):
self.con = sqlite3.connect("weathers.db") # 连接到 SQLite 数据库文件 weathers.db
self.cursor = self.con.cursor() # 创建游标对象
try:
# 尝试创建表 weathers,如果不存在的话
self.cursor.execute(
"create table weathers (wCity varchar(16), wDate varchar(16), wWeather varchar(64), wTemp varchar(32), constraint pk_weather primary key (wCity, wDate))")
except Exception as err:
print(err) # 如果创建失败(比如表已存在),则打印错误信息
self.cursor.execute("delete from weathers") # 清空表中的数据
# 关闭数据库连接
def closeDB(self):
self.con.commit() # 提交事务
self.con.close() # 关闭连接
# 向数据库中插入一条天气记录
def insert(self, city, date, weather, temp):
try:
# 插入城市、日期、天气状况和温度到表中
self.cursor.execute("insert into weathers (wCity, wDate, wWeather, wTemp) values (?, ?, ?, ?)", (city, date, weather, temp))
except Exception as err:
print(err) # 如果插入失败,则打印错误信息
# 显示所有天气记录
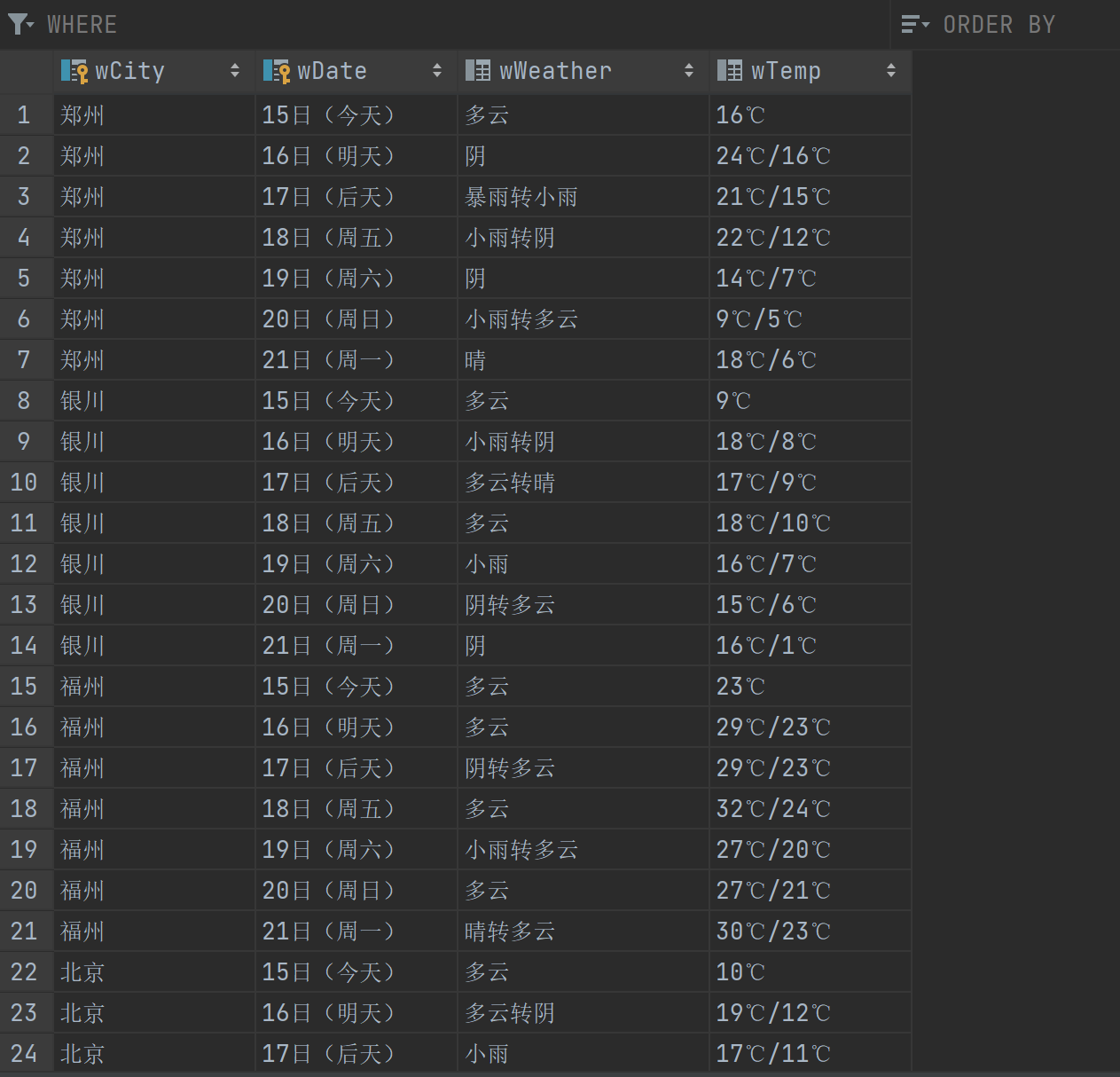
def show(self):
self.cursor.execute("select * from weathers") # 查询表中的所有记录
rows = self.cursor.fetchall() # 获取查询结果
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp")) # 打印表头
for row in rows: # 遍历每条记录
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3])) # 打印每条记录
# 定义一个天气预报类
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
} # 设置请求头,模拟浏览器访问
self.cityCode = {"郑州": "101180101", "银川": "101170101", "福州": "101230101", "北京": "101010100"} # 城市代码字典
# 根据城市名称获取并存储天气预报
def forecastCity(self, city):
if city not in self.cityCode.keys(): # 检查城市是否在城市代码字典中
print(city + " 找不到代码") # 如果不在,则打印错误信息
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" # 构造请求URL
try:
req = urllib.request.Request(url, headers=self.headers) # 创建请求对象
data = urllib.request.urlopen(req) # 发送请求
data = data.read() # 读取响应内容
dammit = UnicodeDammit(data, ["utf-8", "gbk"]) # 使用UnicodeDammit来解决编码问题
data = dammit.unicode_markup # 解码后的文本
soup = BeautifulSoup(data, "lxml") # 使用BeautifulSoup解析HTML
lis = soup.select("ul[class='t clearfix'] li") # 选择天气列表项
x = 0 # 计数器,用于区分今天和其他天
for li in lis: # 遍历每个列表项
try:
date = li.select('h1')[0].text # 提取日期
weather = li.select('p[class="wea"]')[0].text # 提取天气状况
if x == 0: # 如果是今天的天气
x += 1
temp = li.select('p[class="tem"] i')[0].text # 提取温度
else: # 如果不是今天的天气
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text # 提取最高温和最低温
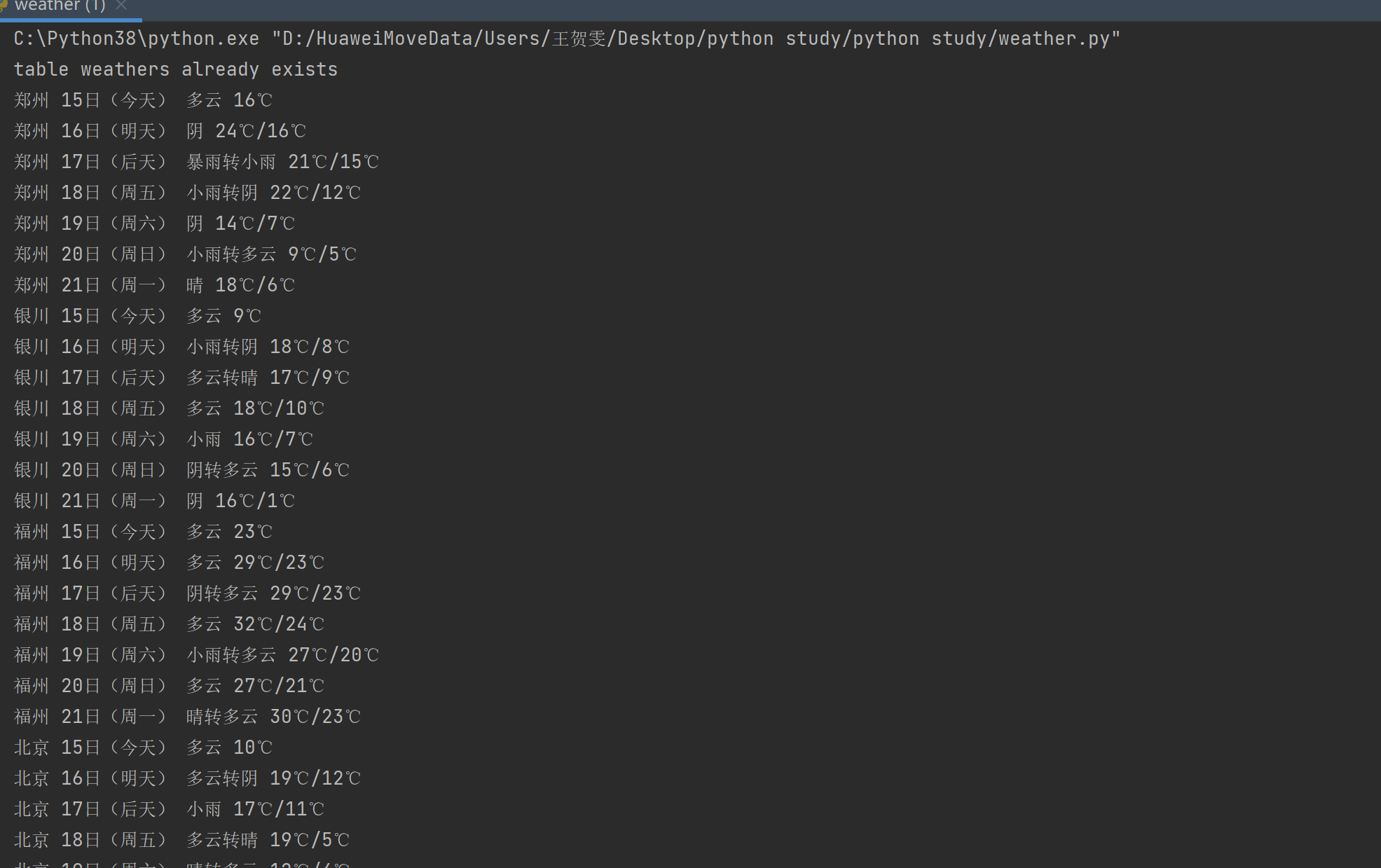
print(city, date, weather, temp) # 打印天气信息
self.db.insert(city, date, weather, temp) # 插入数据库
except Exception as err:
print(err) # 如果提取过程中出错,则打印错误信息
except Exception as err:
print(err) # 如果请求过程中出错,则打印错误信息
# 处理多个城市的天气预报
def process(self, cities):
self.db = WeatherDB() # 创建WeatherDB实例
self.db.openDB() # 打开数据库连接
for city in cities: # 遍历城市列表
self.forecastCity(city) # 对每个城市调用forecastCity方法
# self.db.show() # 可选:显示数据库中的所有天气记录
self.db.closeDB() # 关闭数据库连接
# 创建WeatherForecast实例
ws = WeatherForecast()
# 调用process方法处理四个城市的天气预报
ws.process(["郑州", "银川", "福州", "北京"])
print("completed") # 打印完成信息
效果:
心得体会
通过这次实践,我深刻体会到了Python在数据抓取与处理方面的强大能力。利用BeautifulSoup库解析网页结构、提取天气信息的过程让我对HTML文档的结构有了更清晰的认识。同时,使用SQLite数据库来存储数据,不仅学习了如何操作数据库,还理解了数据持久化的重要性。虽然过程中遇到了不少挑战,比如处理不同城市的数据格式差异等,但最终成功实现功能让我感到非常有成就感
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。东方财富网:https://www.eastmoney.com/
码云地址:https://gitee.com/wanghew/homework/tree/master/作业2
import csv # 导入处理CSV文件的库
import json # 导入处理JSON数据的库
import requests # 导入发送HTTP请求的库
from prettytable import PrettyTable # 导入用于生成表格的库
def main():
# 定义请求的URL和请求头
url = 'https://22.push2.eastmoney.com/api/qt/clist/get?pn=1&pz=6000&po=1&fid=f3&fs=m:1+t:2&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
# 获取数据
result = getData(url, headers)
# 打印数据
printData(result)
# 保存数据到CSV文件
saveData(result)
def getData(baseUrl, headers):
# 发送GET请求获取数据
response = requests.get(url=baseUrl, headers=headers)
# 解析JSON响应数据
data = json.loads(response.text)['data']['diff']
result = []
for key, value in data.items():
# 提取并格式化需要的字段
latest_price = '%.2f' % (value['f2'] / 100) # 最新价
change_rate = '%.2f' % (value['f3']) + '%' # 涨跌幅
change_amount = '%.2f' % (value['f4'] / 100) # 涨跌额
volume = '%.2f' % (value['f5'] / 10000) + '万' # 成交量(手)
amount = '%.2f' % (value['f6'] / 100000000) + '亿' # 成交额
# 将提取的数据添加到结果列表中
result.append([
key,
value['f12'],
value['f14'],
latest_price,
change_rate,
change_amount,
volume,
amount
])
return result # 返回处理后的数据列表
def printData(result):
# 创建一个PrettyTable对象
table = PrettyTable()
# 设置表头
table.field_names = [
"序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量(手)", "成交额"
]
# 添加数据行
table.add_rows(result)
# 打印表格
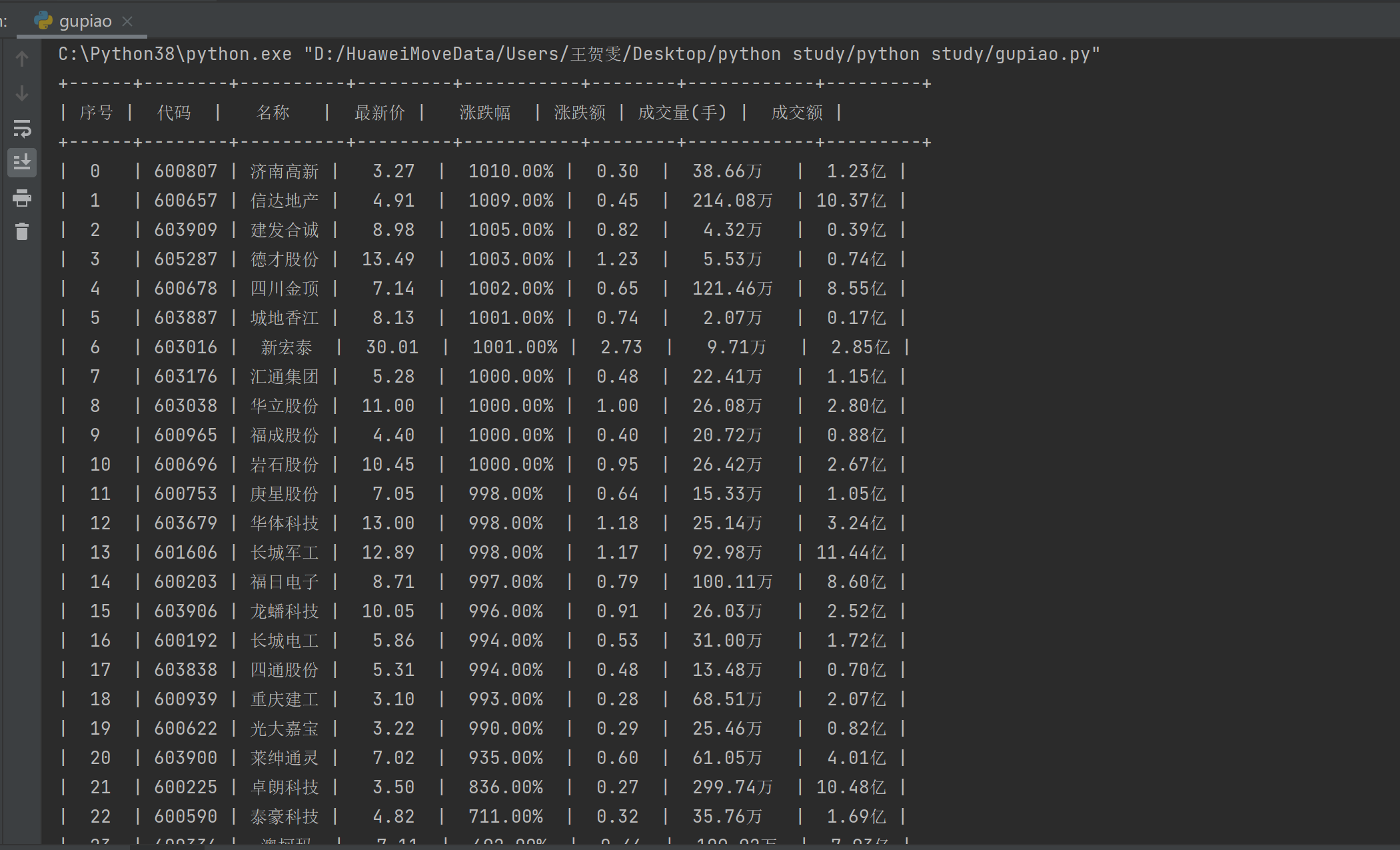
print(table)
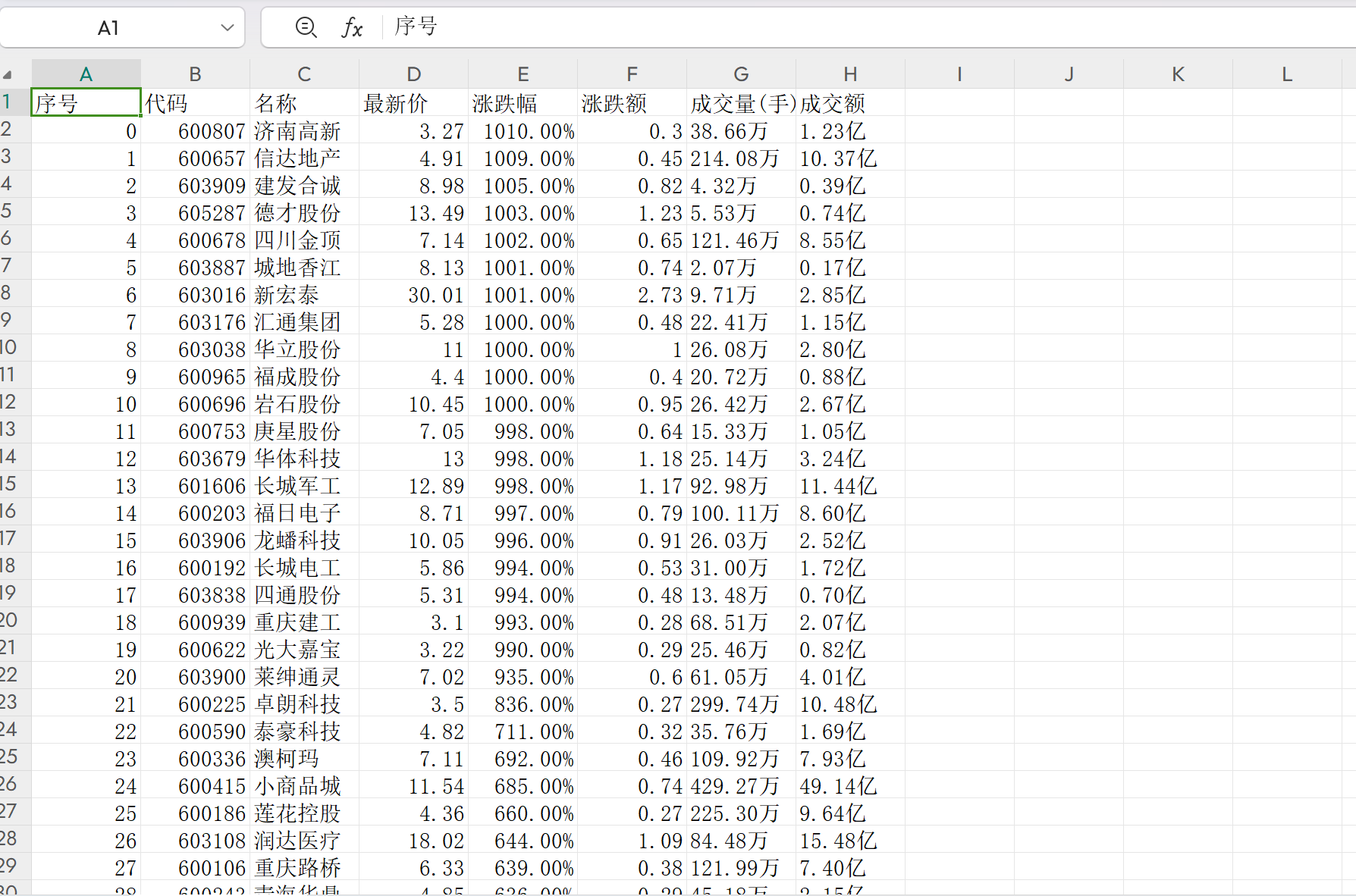
def saveData(result):
# 打开CSV文件,准备写入
with open('上证A股股票数据.csv', 'w', encoding='utf-8', newline='') as file:
writer = csv.writer(file)
# 写入表头
writer.writerow([
"序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量(手)", "成交额"
])
# 写入数据行
writer.writerows(result)
if __name__ == "__main__":
main()
效果:
心得体会:
整个过程让我更加深入理解了数据抓取与处理的实际应用,并且增强了我的编程实践能力。尽管遇到了一些挑战,比如对API返回的数据结构不够了解,但经过查阅文档和调试后最终顺利完成了任务
作业③:
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021) 所有院校信息,并存储在数据库中
码云地址:https://gitee.com/wanghew/homework/tree/master/作业2
import urllib.request
from bs4 import BeautifulSoup
import sqlite3
# 定义爬取和解析网页的函数
def scrape_university_rankings(url):
# 使用urllib获取网页内容
with urllib.request.urlopen(url) as response:
html_content = response.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 连接SQLite数据库(如果数据库不存在会自动创建)
conn = sqlite3.connect('university_rankings.db')
cursor = conn.cursor()
# 创建表格(如果尚不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS rankings (
id INTEGER PRIMARY KEY AUTOINCREMENT,
ranking TEXT,
university_name TEXT,
province TEXT,
type_of_university TEXT,
total_score TEXT
)
''')
# 打印表头
print("{:<10} {:<30} {:<10} {:<10} {:<10}".format("排名", "学校名称", "省市", "学校类型", "总分"))
print("-" * 70)
# 遍历表格的每一行
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
ranking = cols[0].text.strip()
# 只提取中文名称,跳过英文名称
university_name = cols[1].text.split('\n')[0].strip() # 假设中文名称在第一行
province = cols[2].text.strip()
type_of_university = cols[3].text.strip()
total_score = cols[4].text.strip()
# 打印每行的信息,使用格式化对齐
print("{:<10} {:<30} {:<10} {:<10} {:<10}".format(ranking, university_name, province, type_of_university, total_score))
# 插入数据到数据库
cursor.execute('''
INSERT INTO rankings (ranking, university_name, province, type_of_university, total_score)
VALUES (?, ?, ?, ?, ?)
''', (ranking, university_name, province, type_of_university, total_score))
# 提交更改并关闭连接
conn.commit()
conn.close()
# 爬取并打印大学排名信息
scrape_university_rankings('http://www.shanghairanking.cn/rankings/bcur/2021')
效果图:
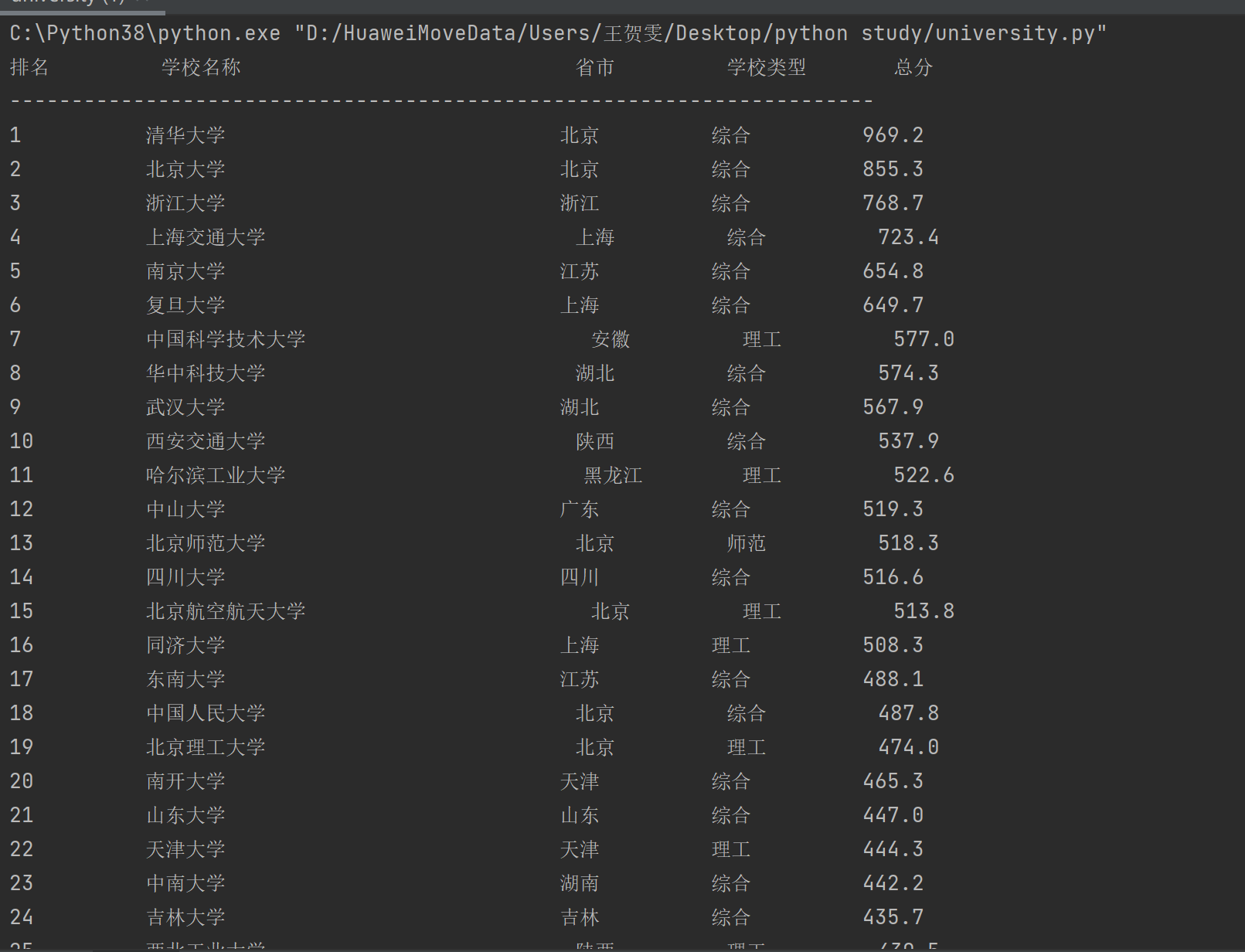
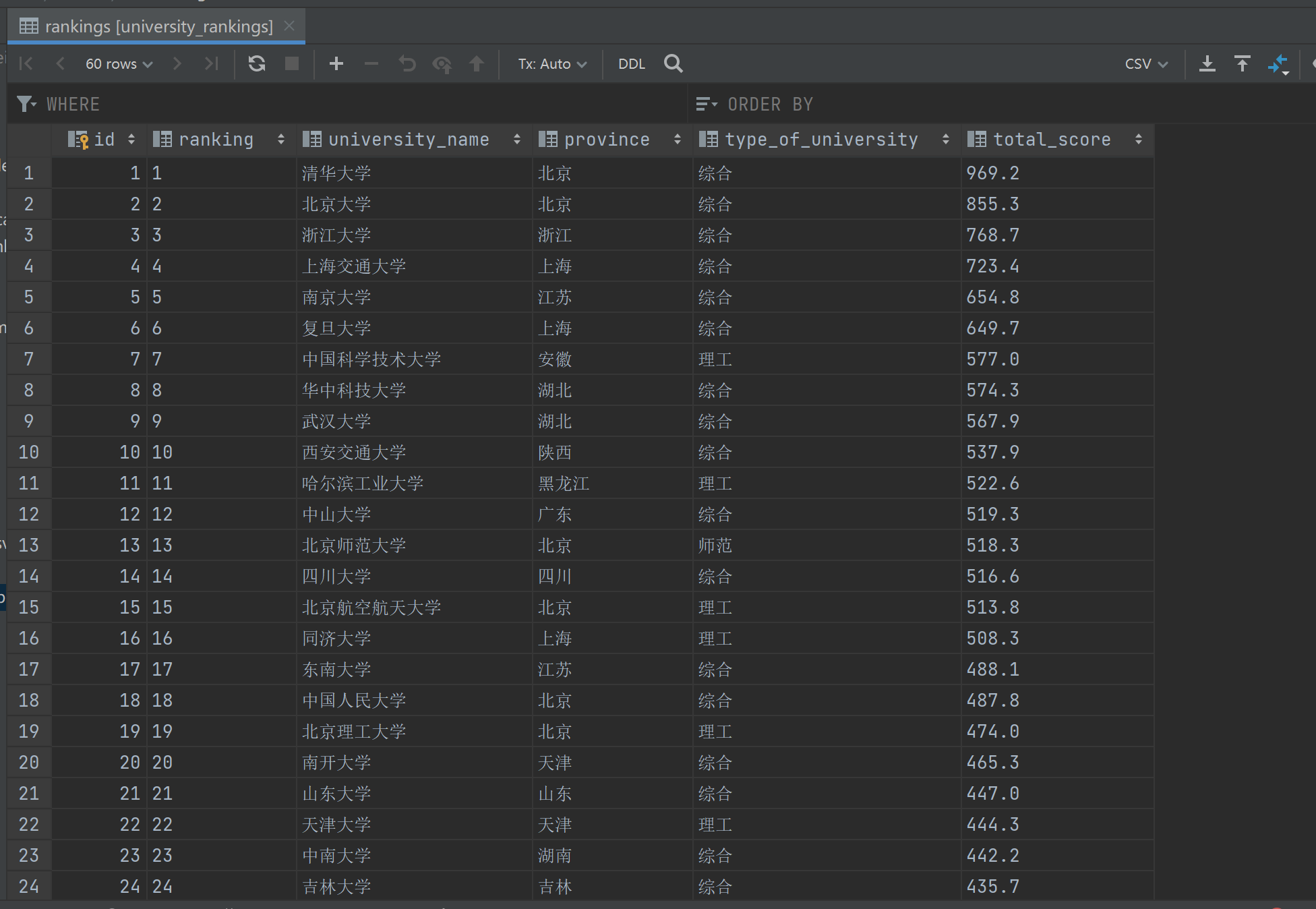
心得体会:
使用urllib.request库轻松地从网页获取了内容,并借助BeautifulSoup解析HTML结构,这让我能够高效地定位和提取所需的数据。整个过程不仅加强了我对网络请求、HTML文档解析的理解,也提升了我的数据库操作技能,尤其是如何创建表以及执行SQL语句进行数据的插入。
分析过程:

总结与反思
作业反思
在完成本次作业的过程中,我遇到了一些挑战并学到了宝贵的经验。首先,在爬取中国气象网的7日天气预报时,由于网站结构较为复杂且部分数据是通过动态加载的,使用requests和BeautifulSoup直接解析HTML存在困难。此外,缺乏对网络请求异常的处理导致程序稳定性不足。其次,在爬取东方财富网股票信息时,要注意爬出的序号和文字的对应,否则对应不上,会爬取出错。最后,在视频转换gif时频频出错,如果有好用的软件请分享给我。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号