作业1
一、作业内容
作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
码云地址:https://gitee.com/wanghew/homework/commit/ade5cf8437fdb827773b88b53dbefb41a8a9e916
import urllib.request
from bs4 import BeautifulSoup
import csv
# 定义爬取和解析网页的函数
def scrape_university_rankings(url):
# 使用urllib获取网页内容
with urllib.request.urlopen(url) as response:
html_content = response.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名信息的表格
table = soup.find('table')
# 创建一个列表来存储所有行的数据
rows_data = []
# 遍历表格的每一行
for row in table.find_all('tr')[1:]: # 跳过表头
cols = row.find_all('td')
ranking = cols[0].text.strip()
university_name = cols[1].text.split('\n')[0].strip() # 假设中文名称在第一行
province = cols[2].text.strip()
type_of_university = cols[3].text.strip()
total_score = cols[4].text.strip()
# 将当前行数据添加到列表中
rows_data.append([ranking, university_name, province, type_of_university, total_score])
# 将数据写入CSV文件
with open('university_rankings.csv', mode='w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Ranking', 'University Name', 'Province', 'Type of University', 'Total Score']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for data_row in rows_data:
writer.writerow({'Ranking': data_row[0],
'University Name': data_row[1],
'Province': data_row[2],
'Type of University': data_row[3],
'Total Score': data_row[4]})
# 爬取并打印大学排名信息
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
scrape_university_rankings(url)
效果如下:

优化后:
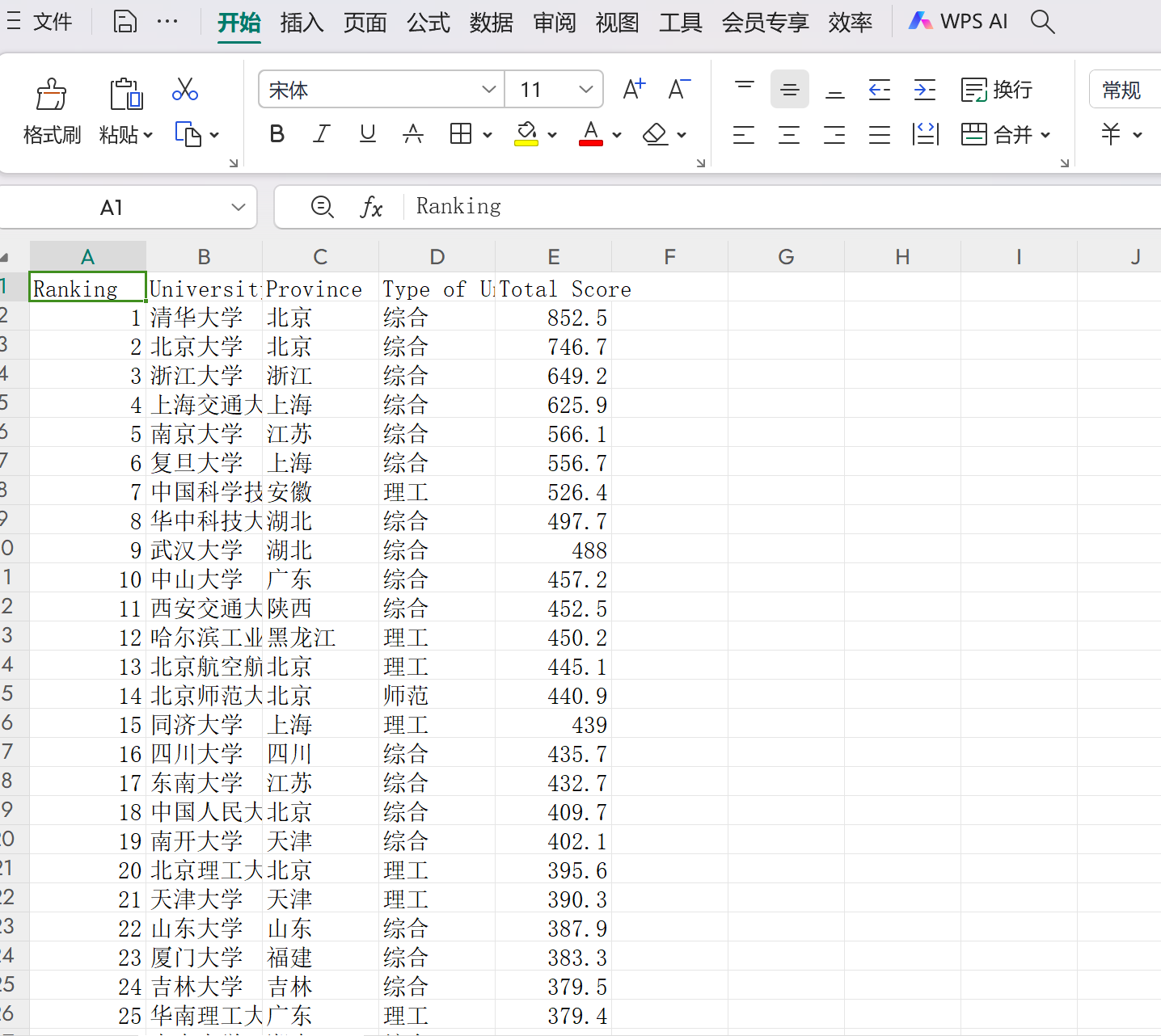
心得体会:
通过编写这个简单的网页爬虫,我体验到了数据抓取与处理的全过程。首先,利用urllib.request获取了上海软科发布的中国大学排名网页内容,接着使用BeautifulSoup库解析HTML文档,从中抽取了包含排名信息的表格。这一过程让我深刻理解了网络资源的结构化表示以及如何有效地从这些结构中提取所需信息。此外,我还学习了如何将提取到的数据整理成列表,并最终以CSV格式保存下来,便于后续分析或分享。
作业②:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
码云地址:https://gitee.com/wanghew/homework/commit/ade5cf8437fdb827773b88b53dbefb41a8a9e916
import requests
import re
from html import unescape
# 修改URL以访问第二页
url = r'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2'
try:
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
except Exception as e:
print(f"Error in request: {e}")
else:
data = req.text
# 查找商品列表的开始位置
match = re.search(r'<ul class="bigimg cloth_shoplist" id="component_59">.*?</ul>', data, re.DOTALL)
if match:
data = match.group(0)
# 初始化计数器
i = 1
# 循环查找每个商品项
while True:
start = re.search(r'<li', data)
if not start:
break # 如果没有找到<li>标签,则退出循环
end = re.search(r'</li>', data)
if not end:
break # 如果没有找到</li>标签,则退出循环
my_data = data[start.end():end.start()]
# 提取价格
price_match = re.search(r'<span class="price_n">(.*?)</span>', my_data)
price = price_match.group(1) if price_match else 'N/A'
# 解码HTML实体
price = unescape(price)
# 提取商品名
title_match = re.search(r'title="(.*?)"', my_data)
name = title_match.group(1) if title_match else 'N/A'
# 打印结果
print(i, name, price, sep='\t')
# 更新data为下一个商品之后的内容
data = data[end.end():]
# 计数器递增
i += 1
else:
print("No matching content found for the product list.")
效果如下:

心得:
通过这次实践,我体验了使用Python进行网页数据抓取的过程,并且成功获取了当当网上关于“书包”关键词搜索结果第二页的商品信息。利用requests库发送HTTP请求并处理响应,结合正则表达式从HTML内容中提取所需的数据,这个过程让我对网络爬虫有了更深入的理解。
总结
整个过程中,我学会了如何构造正确的URL以访问特定页面,以及如何有效地解析和提取网页中的结构化数据。面对复杂的HTML文档时,选择合适的正则表达式模式至关重要,这要求我们不仅要熟悉目标网站的结构,还要具备良好的模式匹配技能。
作业③:
要求:爬取一个给定网页( https://news.fzu.edu.cn)或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
码云地址:https://gitee.com/wanghew/homework/commit/ade5cf8437fdb827773b88b53dbefb41a8a9e916
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 目标URL
url = 'https://news.fzu.edu.cn'
# 发送HTTP请求
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 创建保存图片的目录
output_dir = 'downloaded_images'
os.makedirs(output_dir, exist_ok=True)
# 查找所有图片标签
images = soup.find_all('img')
for img in images:
# 获取图片链接
img_url = img.get('src')
if not img_url:
continue # 跳过没有src属性的图片标签
# 处理相对路径
full_img_url = urljoin(url, img_url)
# 检查图片扩展名是否为.jpeg或.jpg
if not (full_img_url.lower().endswith('.jpg') or full_img_url.lower().endswith('.jpeg')):
continue # 如果不是,则跳过
# 获取图片名称
img_name = os.path.basename(full_img_url)
# 请求图片数据
img_response = requests.get(full_img_url, headers=headers)
img_response.raise_for_status()
# 保存图片
with open(os.path.join(output_dir, img_name), 'wb') as f:
f.write(img_response.content)
print("JPEG/JPG图片下载完成!")
效果如下:

心得:
通过这次实践,我体验了使用Python进行网页图片抓取的全过程。首先,我利用requests库发送带有适当User-Agent的HTTP请求,成功获取了福州大学新闻网的页面内容。接着,借助BeautifulSoup解析HTML文档,从中定位所有图片标签,并处理了相对路径问题以构建完整的图片URL。在过滤出.jpg和.jpeg格式的图片后,再次使用requests下载这些图片到本地文件夹中。
总结
此次项目主要实现了从指定网站自动下载JPEG/JPG格式图片的功能。过程中涉及的关键技术包括设置合适的请求头来模拟浏览器访问、使用BeautifulSoup解析HTML文档以提取图片链接、处理URL的相对路径确保能正确访问资源,以及将图片数据写入本地文件系统。
二、不足与反思
在爬取第一个作业的时候,出现了爬取的序号和名称对应混乱,修改后较好,后续添加了csv.
在爬取第三个作业的时候,爬取https://news.fzu.edu.cn/yxfd.htm只出现了三张图片,于是我换了一个网https://news.fzu.edu.cn/,爬取多张照片,为后续将再次尝试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号