

pandas知识点总结
pandas学习笔记
1.一维数据结构 Series 对象
b=pd.Series(data=[1,2,3]) #利用数组创建Series对象
b
>>>
0 1
1 2
2 3
dtype: int64
type(b)
>>>pandas.core.series.Series
a = {'1':'whj','2':'xhl','3':'xj'} #利用字典dict创建Series对象
c = pd.Series(data=a)
c
>>>
1 whj
2 xhl
3 xj
dtype: object
type(c)
>>> pandas.core.series.Series
c.index #获取下标
>>> Index(['1', '2', '3'], dtype='object')
c.values #获取值
>>> array(['whj', 'xhl', 'xj'], dtype=object)
c[0] #利用下标进行索引
>>>'whj'
c[1]
>>>'xhl'
c + ' nihao!' #进行拼接
>>>
1 whj nihao!
2 xhl nihao!
3 xj nihao!
dtype: object
c
>>>
1 whj
2 xhl
3 xj
dtype: object
2.二维数据结构 DataFrame 对象
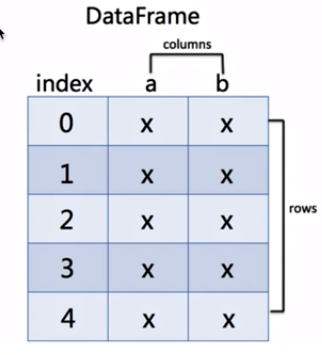
a = pd.DataFrame(data = [[85,90,95],[82,86,90],[90,60,75]],
columns=['语文','数学','英语'],
index=['熊寒露','王韩健','熊健'])
a
>>>
语文 数学 英语
熊寒露 85 90 95
王韩健 82 86 90
熊健 90 60 75
a['语文']
>>>
熊寒露 85
王韩健 82
熊健 90
Name: 语文, dtype: int64
del a['英语'] #删除列
a
>>>
语文 数学
熊寒露 85 90
王韩健 82 86
熊健 90 60
#层次化索引,复合索引
data = pd.DataFrame(data={'month':[12,3,6,9],'year':[2013,2014,2014,2014],'salary':[55,46,73,89]},)
data
>>>
month year salary
0 12 2013 55
1 3 2014 46
2 6 2014 73
3 9 2014 89
data.set_index(['year','month'])
>>>
salary
year month
2013 12 55
2014 3 46
6 73
9 89
data = pd.DataFrame(data={'year':[2020,2020,2019,2020],'month':[1,5,6,9],'salary':['4k','5k','4k','5k']},)
data
>>>
year month salary
0 2020 1 4k
1 2020 5 5k
2 2019 6 4k
3 2020 9 5k
data.set_index(['year','month'])
>>>
salary
year month
2020 1 4k
5 5k
2019 6 4k
2020 9 5k
3.重置索引 reindex()
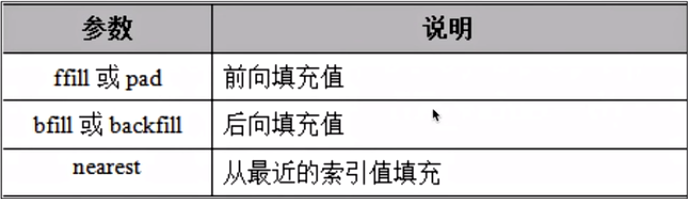
a.reindex(['a','b','c','d','e','f','g'],fill_value=10)
>>>
0
a 10
b 10
c 10
d 10
e 10
f 10
g 10
a.reindex(['a','b','c','d','e','f','g'],copy=True)
>>>
0
a NaN
b NaN
c NaN
d NaN
e NaN
f NaN
g NaN
data
>>>
year month salary
0 2020 1 4k
1 2020 5 5k
2 2019 6 4k
3 2020 9 5k
data.reindex(['a','b','c','d','e','f'])
>>>
year month salary
a NaN NaN NaN
b NaN NaN NaN
c NaN NaN NaN
d NaN NaN NaN
e NaN NaN NaN
f NaN NaN NaN
#DataFrame直接索引 只支持先列后行,不支持先行后列的 索引方式
#但是支持对行的切片
data
>>>
year month salary
0 2020 1 4k
1 2020 5 5k
2 2019 6 4k
3 2020 9 5k
data[:3]
>>>
year month salary
0 2020 1 4k
1 2020 5 5k
2 2019 6 4k
data[1] #直接对行进行索引会报错
Traceback (most recent call last):
File "pandas\_libs\hashtable_class_helper.pxi", line 1619, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas\_libs\hashtable_class_helper.pxi", line 1627, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 1
4.算术运算与数据对齐
a = pd.Series(data=range(3)) #Series一维数组
b = pd.Series(data=range(6))
a
>>>
0 0
1 1
2 2
dtype: int64
b
>>>
0 0
1 1
2 2
3 3
4 4
5 5
dtype: int64
a+b
>>>
0 0.0
1 2.0
2 4.0
3 NaN
4 NaN
5 NaN
dtype: float64
a.add(b,fill_value=0) #对a里面没有的数组进行填充fill_value=0
>>>
0 0.0
1 2.0
2 4.0
3 3.0
4 4.0
5 5.0
dtype: float64
作者:王韩六六
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

