性能测试工具---loadrunner
1.什么是参数化
参数化:把固定的一个值,变成动态、可变的数组,把数组的值进行值传递。数组大小可控制。
2.为什么要使用参数化,2个原因。
1、数据库校验字段值的唯一性。(数据库修改字段的唯一性,可避免参数化)
2、应用程序不允许用一个值反复操作。(开发调整不允许一个值反复操作,可避免参数化)
3、避免数据库的查询缓存,保证测试结果的真实性。(数据库在执行一条SQL查询操作时,先进行语法检查、语义分析(写法是否正确、表是否存在、是否有权限),生成执行计划,按执行计划做查询操作,如果查询的数据在数据库内存,返回数据;如果不在内存,需要从硬盘里把数据放到硬盘,返回数据,同时会缓存这条SQL的执行计划和结果。如果同样的查询操作,就直接在查询缓存里返回)(数据库关掉缓存,可避免参数化)
3.参数化有九种取值策略:
顺序+迭代,顺序+每次遇到,顺序+once
随机+迭代,随机+每次出现,随机+once
唯一+迭代,唯一+每次出现,唯一+once
随机和顺序他们取值是总的参数化内的值,但是在唯一的时候每个用户的值都是不一样的,没有交集,是总的参数化内的子集。
4.关联定义:无需要不关联,所以肯定需要用到 用到就要关联
关联:将服务器返回的、动态的、变化的值,把它保存为一个参数,以便后面需要使用这个参数的地方进行使用。(批量替换使用)
5.什么值需要进行关联:
a.服务器校验该值的合法性;
例子:session、cookie、token、时间戳(formhash等)、验证码(图片验证码、短信验证码、邮箱验证码等)等等。
验证码(①.自己写JS,解析图片,获取验证码;②.改成万能验证码)
请求成功不代表业务测试成功,要注意看回放页面是否有报错。
b.数据库,后续需要对该值进行增删改查操作。(一定是int类型的数字)
例子:insert操作 插入的值需要与其他表的数据建立关联关系/对应关系,需要进行关联。
delete操作 看请求里非手动输入的ID有多少个即可确认是否需要做关联。
update操作 where条件
select操作 where条件
6.关联函数放在什么位置?
服务器返回需要关联的参数值请求之前。
①.查看源文件;②.F12捕获(抓包);③.Tree视图的Response Body里找(/WebTours/nav.pl?in=home);④.在日志里打印服务器返回的数据(Run-time Settings→Log→Extcndcd log→Data returned by server)。
所有reg开头的函数都是预注册函数。
为什么关联函数要放在server返回值之前呢?脚本是按顺序执行的话,按理说不是返回后才能知道动态值吗?
关联函数是预注册函数;预注册:先声明后使用。
7.关联函数怎么写?
日志(Replay Log)里的内容:绿色是请求、蓝色是参数或者关联函数请求的值、红色是错误信息;
在Tree里找不到,就到扩展日志里找。(扩展日志里的内容捕获得比Tree里的内容更多)。
①.最快速的关联:右键关联。找到需要关联的值,右键把它保存为一个参数。(用左右边界出现概率较多的值)
Create Praamter---创建参数不替换 Create Correlation---创建关联函数并替换
②.在Insert→new step(Alt+Insert/右键)里输入关联函数,根据Tree视图的Response Body获取到的左右边界,设定好左右边界值。
③.用日志里打印服务器返回的数据(Run-time Settings→Log→Extcndcd log→Data returned by server),获取到的左右边界,在Insert→new step(Alt+Insert/右键)创建关联函数。
④.用IE→F12,获取到的左右边界,在Insert→new step(Alt+Insert/右键)创建关联函数。
⑤.用IE→查看源文件,获取到的左右边界,在Insert→new step(Alt+Insert/右键)创建关联函数。
web_reg_save_pram_ex数组 正则表达式的时候需要用这个函数)用Ordinal选定第一个值,如果不选定则用web_reg_save_pram默认第一个。
Ordinal:如果填写数字,那么说明从迒回的记录中取出对应顸序的值,如果填写All的话将会返回所有内容。
8.接口
我理解的:是开发人员封装好的,只需要往这个方法里传递需要的东西,比如,这个接口说,你给我传一个id,我才能给你返回你要查询的值,这时候,你就在接口后面加一个id,就OK了
App本身相当于web前端,http
开发和开发之间一定有一个接口说明文档,通过接口说明文档进行对接
http接口一般用postman测试
lr写接口时,按照条件将参数输入到地址后面,然后去网页地址栏试一下,看能不能返回信息,如果可以,再去lr里写脚本。回放的时候,把日志第二项勾选,看有没有打印结果,有就行,即使是乱码也没有关系。
Webservices
你工作时测接口吗?测什么类型的接口:http、
soapui,专业版既能做功能又能做性能,开源版本功能小一些,不能做性能测试,不能做值得传递
有一种方法是用关联函数获取这个状态码,如果是200,就代表请求正确,事物成功了,我们现在测接口,一般都这么判断。一般开发会在接口文档里写。
纯接口的话按照接口说明文档写,接口的url给你、拼参数(lr是web_submit_data,jm是http协议),https对jm是最好做的,把协议改成https,走443端口就可以了;
9.为什么参数化、关联、检查点、集合点、思考时间、事务、TPS(单位时间内,每秒通过的事务数,通过的总事务数/总耗时)、响应时间RT(事务的响应时间,end-start的时间)。
事务:事务是Loadrunner性能测试结果的基础,没有事务就没有响应时间。事务是自己定义的,一般只放一个请求,录完也可以加事务。开始事务和结束事务的事务名要一致。事物是自己定义的,想放几个放几个。事物是成对出现的,start,end。事物就是计时用的。一般一个事物里面有一个请求,可以有多个。
响应时间running time:就是end减去start的时间,即使系统对请求做出的响应时间
吞吐量:系统在单位时间内处理的请求数量
Tps:每秒通过的事物数。以后订目标,建议用tps
并发:每秒钟有多少个用户在跑,并发时间不包含加载时间。
Lr并发的实质就是多线程
思考时间lr_think_time(7): 等待时间。减少单位时间内向服务器发出的请求数,缓解服务器的压力(lr_think_time(2);等两秒之后再进行下一步。)
(从性能测试实质来说,一般不加think_time;并发量达不到测试要求,为了出测试报告,加think_time。加了think_time,会影响TPS值,前提是TPS值没有到极限。加在一个事务的外面。)
服务器处理能力是恒定的,有极限的一个值。不会因为增加了思考时间,缓解了服务器的压力,就会增加服务器的处理能力。CPU使用率高,任务多,进程多,切片更繁忙。处理的事更多。
thinktime和pacing的区别:两个都是一个等待时间,think time 可以加在任何请求前,Pacing只能加在迭代之间。think time 需要自己加,Pacing之间设置即可。
检查点web_reg_find(放在请求前)或者web_find(放在请求后):(尽量设置数字或者英文)设置检查点,检测脚本是否成功。写的操作不用加(可以通过LR中的contorl中的passed transaction和数据库中做比对),查的操作要加。reg的都是预注册函数,是放在请求前面;没有reg的放在请求的后面。
集合点:lr_rendezvous();
为了更加真实的模拟用户的瞬时并发,等待所有的并发一起执行接下来的操作。
设置集合点策略;集合点设置为100%,则需要所有用户都到集合点时再并发。加了集合点也不能保证后面的请求同时执行,可以提高顺势请求的数量。
抢购、秒杀类似的请求前,加上集合点。
10.做JDBC脚本
推荐用Jemter做JDBC的脚本,测试数据库
Loadrunner连JDBC的方式:1、装驱动;2、录制MySQL脚本;3、加载文件;4、Java Vuser
11.范围:场景(单场景、混合场景、稳定性场景)、接口、功能
一个脚本、接口 单场景(一般10~15分钟) 测试是否达到测试目标
多个脚本、接口 混合场景(一般10~15分钟) 不同的请求,测试线程死锁,数据库死锁
长时间 稳定性场景(至少12个小时) 测试是否有内存泄漏
混合场景和稳定性场景 测试可能出现的问题
性能测试必须三个场景都要测试。
单场景的测试结果更准确。单场景的TPS比混合场景的TPS大。
混合场景放集合点,也是单场景的测试结果更准确。
数据量、磁盘满了等环境因素和数据因素都会影响测试结果。
12.如何测试
1)测试响应时间----------测试多少个并发情况下XXX功能/接口的响应时间。(前提条件是多少个并发)
直接加载多少个并发用户去测试XXX功能/接口,并发运行时间10~15分钟,得出平均响应时间即可。
2)测试最大TPS----------测试XXX功能/接口的最大TPS。(TPS每秒通过的事务数,隐含条件是1s)
直接从1个用户开始测试,通过不断加压(加用户)去测试最大TPS,最大TPS的标志是随着用户的增加,TPS不再增加或者TPS反而减小,那么那个不再增加的TPS或者出现拐点的TPS就是最大的TPS。
3)测试最大并发用户数:测试XXX功能/接口,响应时间在多少秒以内。
用户直接从1开始测试,逐渐加大并发用户数,观察响应时间,直到响应时间达到多少秒,然后继续观察是否稳定,如果稳定了,那么这个并发数就是最大并发数;如果不稳定,那么需要增加或者减少用户。
13.TPS怎么评估?
1)由产品经理或者开发制定;
2)测试要有预估值
a.最精确的来源于线上的日志分析;
b.其次可以用28原则预估(80%的用户会在20%的时间段做同一件事情);例子:100个并发用户,并发运行时间10分钟,预估TPS=80/(2min*60)s
14.std标准方差
把所有曲线时间和平均值做一个比对,曲线波动越大,标准方差就越大,和90%用户响应时间结合用,意思是90%的用户小于这个值的,90%不是平均值。如果标准方差在5以内,那么取平均值,如果标准方差的值比较大,建议用90%的响应时间。
15.同样的请求响应时间不同,原因可能是:
1)缓存 不需要从应用服务器返回;
2)前两个请求都失败了。
16.加压后tps为什么会减少
随着并发的增加,导致负载过大,加到某一个用户数后,tps不再增加或者下降,就是tps的最大值。
随着用户数增加,服务器的负载高了,进程之间切换越来越大,那么cup切换换来越快,可能导致系统处理能力下降。理论来说tps是恒定的,但是也有上述说的可能。
tps处理到极限的时候,如果发送的请求大于处理请求,出现排队情况,响应时间就会越来越长
17.Loadrunner和JMeter区别
Loadrunner的响应时间会比JMeter响应时间短;
JMeter回收垃圾内存,GC会占用Java应用程序的线程(即JMeter的线程);
小规模并发,JMeter响应时间比Loadrunner短;大规模并发,Loadrunner响应时间比JMeter短;
测试时候要加检查点,注意请求是否成功。
Loadrunner的结果比较准确。
18.开发和测试,测试结果不一致。
软件硬件、环境、测试工具是否一致。
19.开发和测试的软硬件、环境以及测试工具等都一致,测试结果有差异。
属于正常现象,因为硬件与并发情况、网络原因会有少许差异,出现差异,取平均值。
20.工具的响应时间是2.9s,服务器日志的响应时间是1.8s。
判断开发那边打断点有没有打错(打计时有没有打错),同事务数同请求下。
21.响应时间图:响应时间是过程①到过程⒓相加。这只是一个最简单的系统架构webserver+db
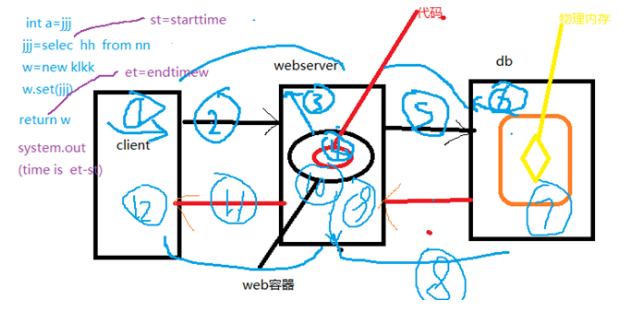
1和12是负载均衡服务器问题;2和11是负载机到webserver的网络问题;3和9是中间件问题(排队);
4和10是代码问题;5和8是WebServer到数据库的网络问题;6和7是数据库执行问题。
看WebServer、DB的硬件问题,硬件没有问题再看中间件、SQL执行过程,最后看代码。
java程序要加JVM监控。
1)client端开始发送请求,
2)网络传输
3)线程池拿到这个数据之后,用空闲线程来拿这个请求
4)线程拿到之后开始执行这个代码(在5到8执行的时间,4处于空闲状态,挂起,然后9状态给唤醒)
5)通过网络发到数据库
6)数据库连接池拿到这个数据之后开始解析,语法检查、语义分析、open这张表,然后再开始生成执行计划,然后再让这条执行计划去内存里面取数据(黄色是内存)。如果数据在内存里面,直接把数据结果取到返回,如果不在物理内存里,需要从磁盘把数据拿到内存里面,然后再返回。
7)整个dmr处理时间,也就是整条sql语句处理时间
8)WebServer到数据库的网络问题
9)线程的唤醒操作
10)代码继续往下执行,也就是 w=new klkk w.set(jjj)这一步,执行完之后有一个return w,然后给client端
11)网络传输时间
12)一对一的接收的时间。全部接收时间完成client端就响应到了一个正确的结果
开发的响应时间是从st=starttime开始计时,et=endtime结束。
system.out(time is st-et)响应时间是从4开始到10结束。可能4和10也不全,因为4开始还需要执行int a=jjj,可能还有很多
现在我的响应时间是2.9s,开发响应时间是1.8秒,那么慢在哪儿了,1、2、3、11、12,所以可能是client端有问题,可能是网络有问题,可能线程池会有问题(比如拿不到请求)。
如果我测试2.9s,开发服务器日志里是2.8s,这样的响应时间是比较慢的,但是应该没有问题,慢的原因就是服务器处理慢。就是请求处理的慢,问题可能出现在4和10或者6和7这里。
一般来说,工具上的时间和开发的响应时间应该差不多,这样说明负载机、网络、中间件这里是没有问题的。如果相差太多,需要在负载机、网络、中间件这里去排查。
开发日志里时间显示短些,工具里显示大些原因?client端问题,网络问题,webserver问题
环境、数据、工具、脚本、场景都需要一模一样。