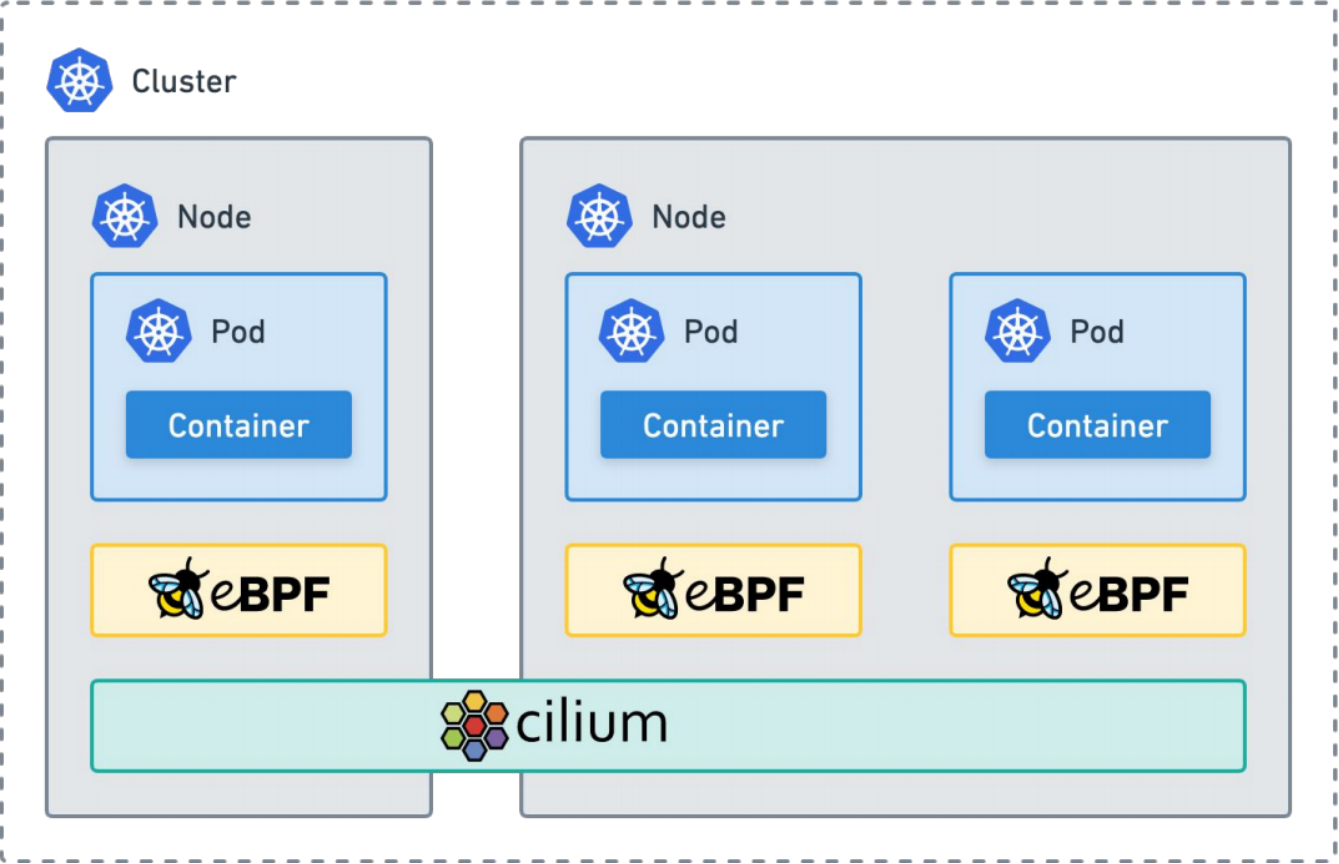
cilium 高性能云原生网络 (CNI)
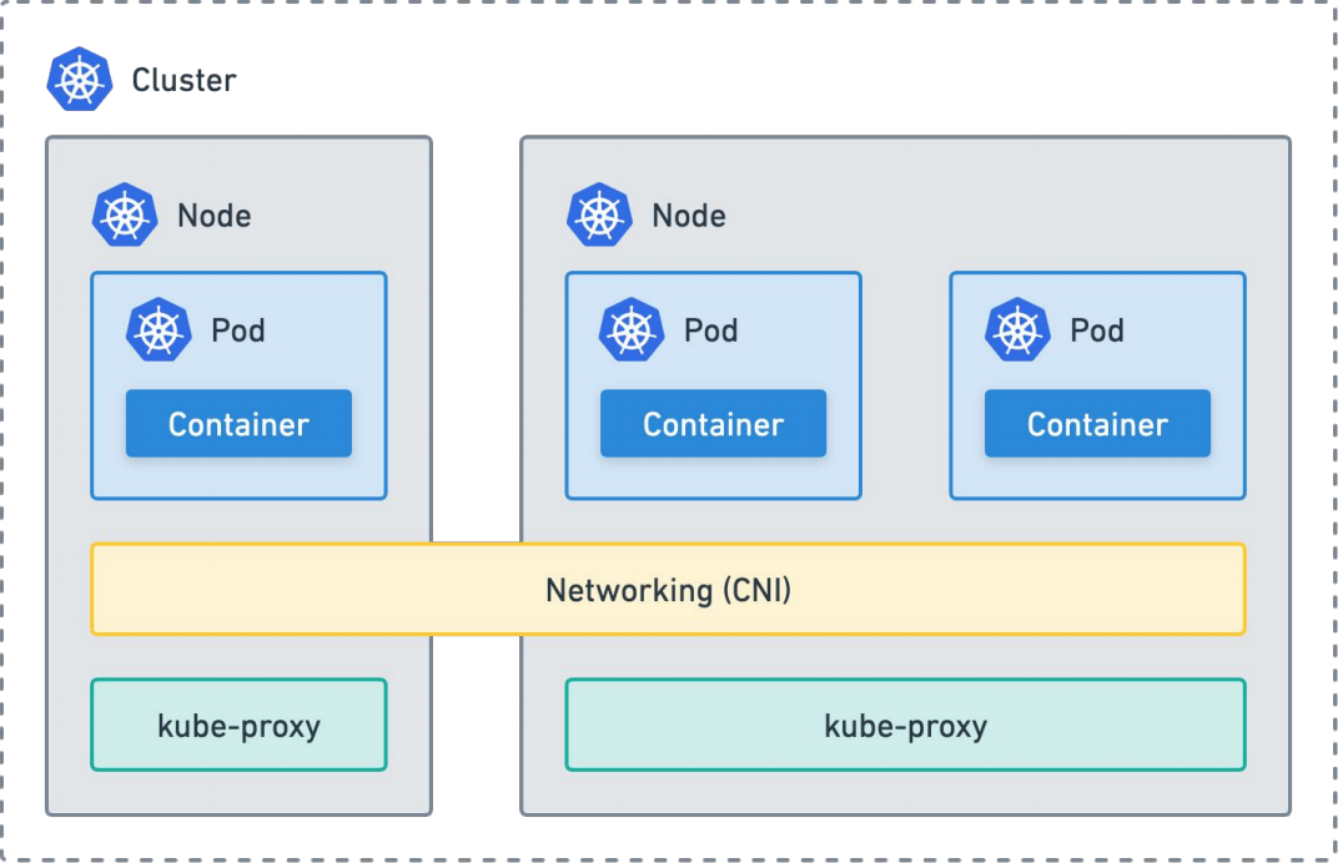
Kubernetes Networking
kube proxy
Networking plugin:
网络设备
IPAM(IP Address Management)
同一节点上的pod间通信
跨节点的pod间通信
kube proxy:
Services
iptables or ipvs
Service discovery
cilium
cilium:
节点级Agent
支持隧道和直接路由
eBPF原生数据平面
可替换kube-proxy
Kubernetes Services
东西向流量
East-west connectivity
Durable abstraction
Connect applications
Ephemeral addresses
High churn
Iptables or ipvs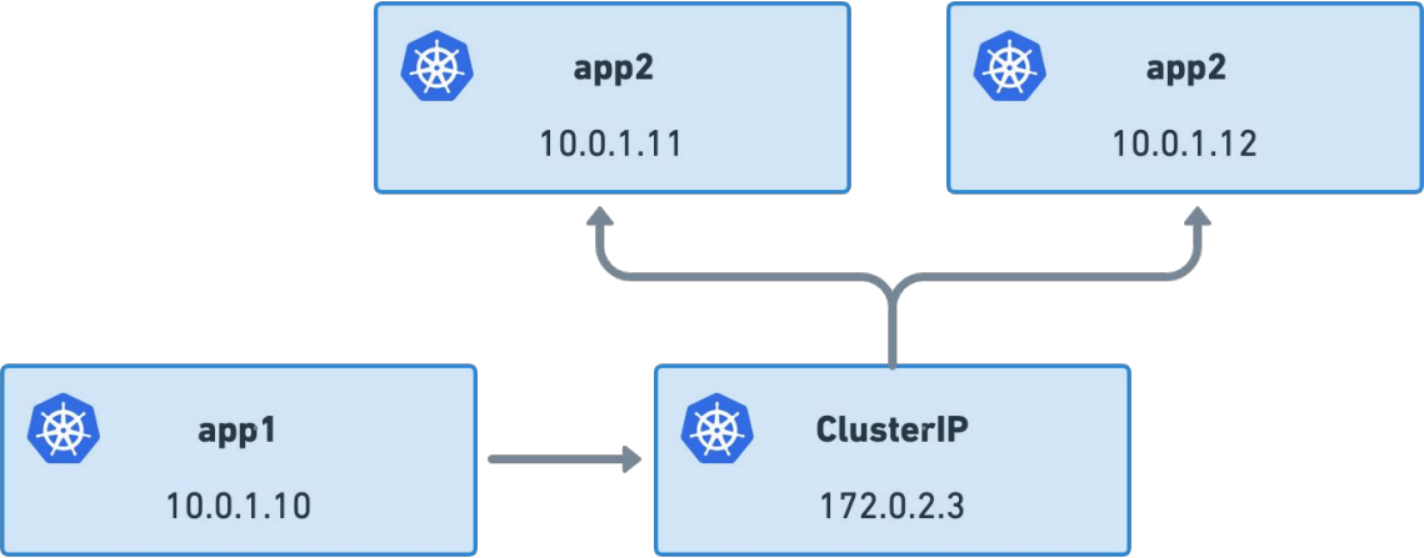
kube-proxy / iptables
Linear list / sieve
All rules have to be replaced as a whole
eBPF based
Per-CPU hash table ⇒ more performant
Native metadata = Cloud Native routing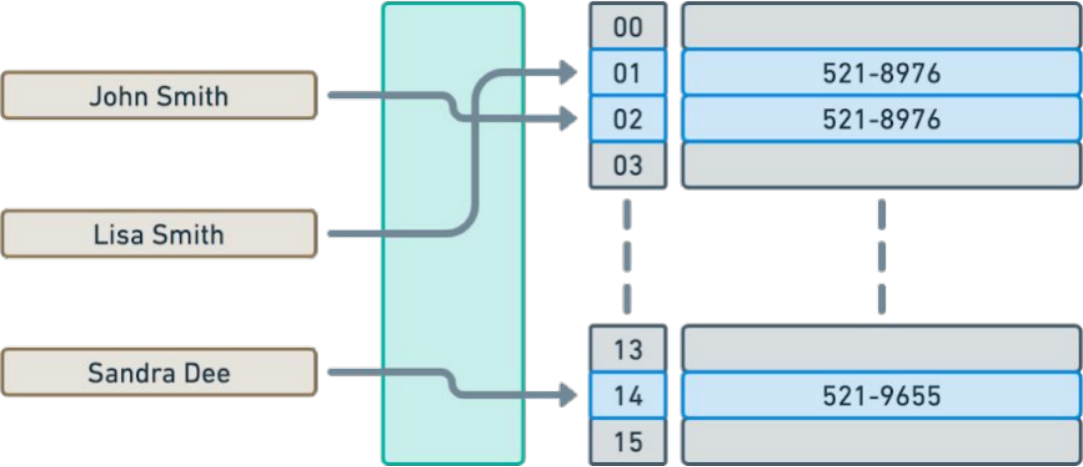
Kubernetes Without kube-proxy
增强 Kubernetes 集群的网络速度和效率将 Kubernetes 从 kube-proxy 和 IPtables 中解放出来。
IPtables 和 Netfilter 是 kube-proxy 实现 Service 抽象的两项基础技术。它们继承了 20 多年开发积累的遗产,这些遗产植根于更传统的网络环境,这些环境通常比普通 Kubernetes 集群静态得多。在云原生时代,它们不再是完成工作的最佳工具,特别是在性能、可靠性、可扩展性和操作方面。Cilium 的 kube-proxy 替换依赖于 socket-LB 功能,这需要 v4.19.57、v5.1.16、v5.2.0 或更高版本的 Linux 内核。 Linux 内核 v5.3 和 v5.8 添加了其他功能,Cilium 可以使用这些功能来进一步优化 kube-proxy 替换实现。保留客户端源 IP
Cilium 的 eBPF kube-proxy replacement 实现了各种选项,以避免对 NodePort 请求执行 SNAT,否则客户端源 IP 地址将在通往服务端点的路径上丢失。externalTrafficPolicy=Local: 对于externalTrafficPolicy=Local策略,通常通过eBPF实现来支持。对于设置了externalTrafficPolicy=Local的服务,可以在集群内实现连接,并且即使从没有本地后端的节点上也可以访问这些服务,这意味着在不需要执行SNAT的情况下,所有服务端点都可以从集群内部进行负载均衡。通过这种方式,可以确保对具有externalTrafficPolicy=Local策略的服务的有效加载均衡,同时在集群内部实现连接。
externalTrafficPolicy=Cluster: 对于默认的Cluster策略,在服务创建时存在多种选项来实现外部流量的客户端源IP保留,即如果后者只有基于TCP的服务向外界公开,则可以在DSR或Hybrid模式下运行kube-proxy替代功能。通过这种方式,可以有效地在集群中保留外部流量的客户端源IP,特别是在面向外部的基于TCP的服务中实现这一点。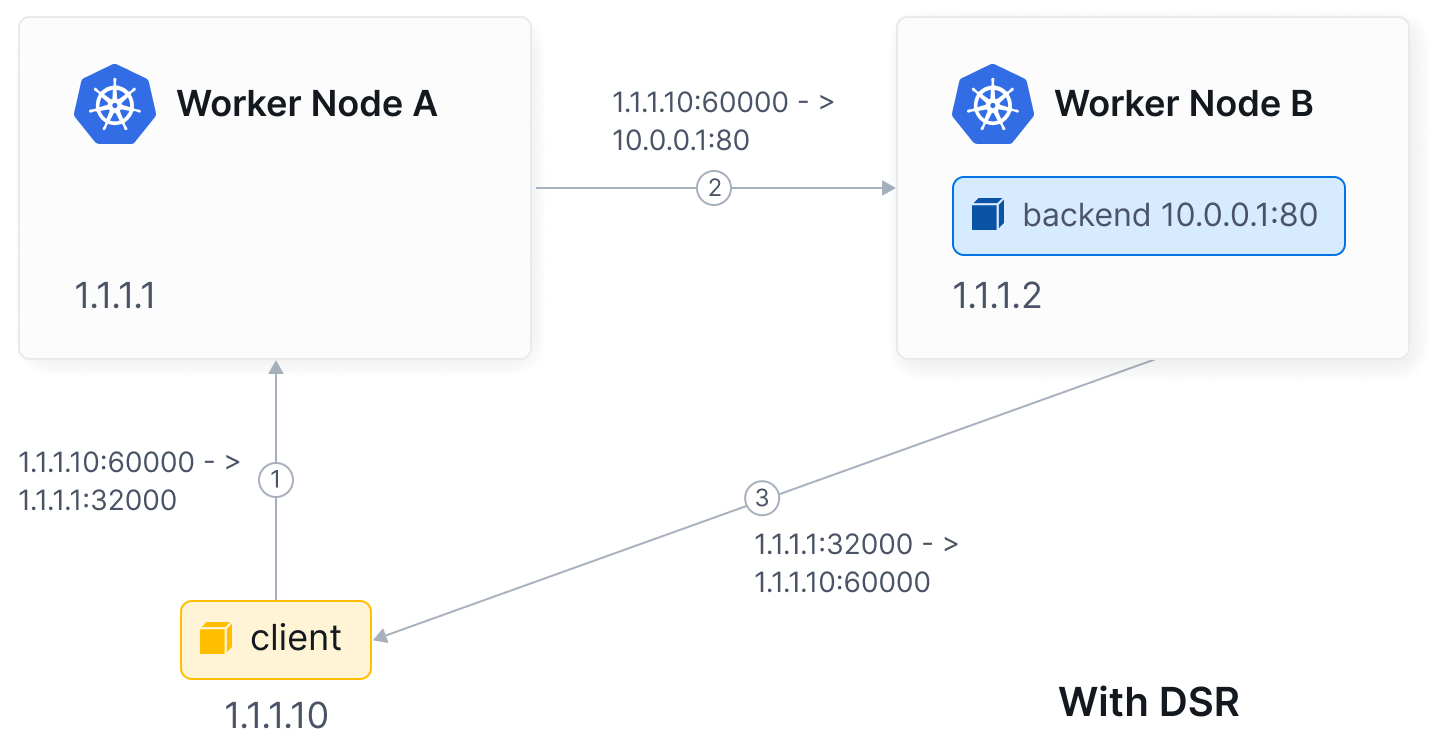
内部流量策略
对于internalTrafficPolicy=Local 的服务,源自当前集群中 Pod 的流量仅路由到流量源自同一节点内的端点。
internalTrafficPolicy=Cluster是默认设置,它不限制可以处理内部(集群内部)流量的端点。这意味着所有的端点都可以处理集群内部的流量,而不对内部流量的处理进行限制。|
Traffic policy |
Service backends used |
||
|---|---|---|---|
|
Internal |
External |
南北向流量 |
东西向流量 |
|
Cluster |
Cluster |
All (default) |
All (default) |
|
Cluster |
Local |
Node-local only |
All (default) |
|
Local |
Cluster |
All (default) |
Node-local only |
|
Local |
Local |
Node-local only |
Node-local only |
Maglev 一致性哈希
Cilium的eBPF kube-proxy replacement功能通过在其负载均衡器中实现The Maglev哈希的变体,从而支持一致性哈希。这提高了在发生故障时的可靠性。此外,它还提供了更好的负载平衡属性,因为添加到集群的节点将为给定的 5-tuple 在整个集群中做出一致的后端选择,而无需与其他节点同步状态。类似地,在删除后端后,后端查找表将被重新编程,对给定服务的不相关后端的干扰最小(重新分配中最多有 1% 的差异)。可以通过设置 --set loadBalancer.algorithm=maglev 来启用用于服务负载平衡的 Maglev 哈希。请注意,Maglev 哈希仅适用于外部 (N-S) 流量。对于集群内服务连接(E-W),套接字直接分配给服务后端,例如在 TCP 连接时,没有任何中间跃点,因此不受 Maglev 的影响。 Cilium 的 XDP 加速也支持 Maglev 哈希。
还有两个特定于 Maglev 的配置设置:maglev.tableSize 和 maglev.hashSeed。maglev.tableSize 指定每个服务的 Maglev 查找表的大小。Maglev 建议表大小 (M) 明显大于最大预期后端数量 (N)。实际上,这意味着M应该大于100 * N,以保证后端更改时重新分配最多有1%差异的特性。 M 必须是质数。 Cilium 对 M 使用默认大小 16381。maglev.tableSize 可选值: 251 509 1021 2039 4093 8191 16381 32749 65521 131071例如,maglev.tableSize 为 16381 适合每个服务最多约 160 个后端。如果在此设置下配置更多数量的后端,则后端更改的重新分配差异将会增加。
建议设置 maglev.hashSeed 选项,以便 Cilium 不依赖于固定的内置种子。种子是一个base64编码的12字节随机数,可以通过head -c12 /dev/urandom | 一次生成。例如,base64 -w0。集群中的每个 Cilium 代理必须使用相同的哈希种子才能使 Maglev 工作。SEED=$(head -c12 /dev/urandom | base64 -w0)
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=true \
--set loadBalancer.algorithm=maglev \
--set maglev.tableSize=65521 \
--set maglev.hashSeed=$SEED \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}请注意,与默认的 loadBalancer.algorithm=random 相比,启用 Maglev 将在每个 Cilium 管理的节点上产生更高的内存消耗,因为 random 不需要额外的查找表。然而,random 不会有一致的后端选择。DSR (Direct Server Return)
默认情况下,Cilium 的 eBPF NodePort 实现在 SNAT 模式下运行。换句话说,当节点外部流量到达并且节点确定LoadBalancer、NodePort或带有externalIPs的服务的后端位于远程节点时,节点将代表它执行SNAT将请求重定向到远程后端。这不需要进行任何额外的MTU更改。这种方式的代价是,后端的回复需要经过额外的跳转返回到该节点,进行逆向SNAT转换,然后直接将数据包返回给外部客户端。
通过使用loadBalancer.mode Helm选项将设置更改为dsr,可以让Cilium的eBPF NodePort实现在DSR模式下运行。在这种模式下,后端直接以服务IP/port作为源回复给外部客户端,而不需要经过额外的跳转。这意味着后端通过使用服务IP/port可以直接回复给外部客户端。
在DSR模式中的另一个优点是保留了客户端的源IP,因此策略可以在后端节点上匹配它。在SNAT模式下这是不可能的。考虑到特定后端可以被多个服务使用,后端需要知道它们需要回复的服务IP/port。Cilium通过将这些信息编码到数据包中(使用下文描述的其中一种分发机制)来实现这一点,但这会导致宣传更低的MTU。对于TCP服务,Cilium仅对SYN数据包编码服务IP/port,而不包括后续数据包。这种优化还允许在后文详细描述的混合模式下运行Cilium,其中TCP使用DSR,UDP使用SNAT,从而避免了否则需要降低MTU的情况。
在某些实施 源/目标 IP 地址检查的公共云提供商环境(例如 AWS)中,必须禁用检查才能使 DSR 模式正常工作。-set loadBalancer.mode=dsr带有 IPv4 选项/IPv6 扩展标头的 DSR
在这种DSR调度模式中,服务IP/port信息通过Cilium特定的IPv4选项或IPv6目标选项扩展头传送到后端。这要求Cilium在 Native-Routing 模式下部署,即在 Encapsulation 模式下无法工作。这种方式确保了服务IP/port信息能够传递到后端,从而实现了一致性处理机制。
在某些公共云提供商环境中,由于底层网络架构可能会丢弃特定于Cilium的IP选项,因此这种DSR模式可能无法正常工作。如果遇到连接到远程节点上的后端的服务的连接问题,首先检查NodePort请求是否实际上到达包含后端的节点。如果不是这种情况,请考虑切换到使用Geneve的DSR模式(如下所述),或者切换回默认的SNAT模式。这种方式可以帮助解决云环境下的连接问题,确保服务正常运行。
在启用了 DSR-only 模式的无 kube-proxy 环境中,上述 Helm 示例配置如下所示:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=native \
--set kubeProxyReplacement=true \
--set loadBalancer.mode=dsr \
--set loadBalancer.dsrDispatch=opt \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}Geneve 的 DSR 模式
在默认情况下,Cilium在DSR模式下会将服务IP/port编码到特定于Cilium的IPv4选项或IPv6目标选项扩展中,以便后端了解需要使用的服务IP/port来进行回复。然而,一些数据中心路由器会将具有未知IP选项的数据包传递给称为“第2层慢路径”的软件处理。如果具有IP选项的数据包数量超过给定阈值,这些路由器会丢弃这些数据包,这可能会显著影响网络性能。
为了避免这个问题,Cilium提供了另一种调度模式,即带有Geneve的DSR模式。在使用Geneve的DSR模式中,Cilium通过Geneve头部将数据包封装到Loadbalancer中,并在Geneve选项中包含服务IP/port信息,然后将数据包重定向到后端。
在kube-proxy-free环境中启用DSR和Geneve调度的Helm示例配置如下:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=native \
--set tunnelProtocol=geneve \
--set kubeProxyReplacement=true \
--set loadBalancer.mode=dsr \
--set loadBalancer.dsrDispatch=geneve \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}DSR with Geneve与Geneve封装模式(Encapsulation)兼容,可以与直接路由模式或Geneve隧道模式一起使用。不幸的是,它与vxlan封装模式不兼容。
以下是在DSR与Geneve调度和隧道模式下的示例配置:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=tunnel \
--set tunnelProtocol=geneve \
--set kubeProxyReplacement=true \
--set loadBalancer.mode=dsr \
--set loadBalancer.dsrDispatch=geneve \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}Hybrid DSR 和 SNAT 模式
Cilium还支持 hybrid DSR和SNAT模式,即对于TCP连接执行DSR,对于UDP连接执行SNAT。这消除了在网络中手动更改MTU的需要,同时仍然受益于通过去除回复的额外跳数带来的延迟改进,特别是当TCP是工作负载的主要传输协议时。
通过设置loadBalancer.mode选项为dsr、snat或hybrid,可以控制行为。默认情况下,代理使用snat模式。
在启用了DSR hybrid 模式的kube-proxy-free环境中,使用Helm的示例配置如下所示:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=native \
--set kubeProxyReplacement=true \
--set loadBalancer.mode=hybrid \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}Socket LoadBalancer Bypass in Pod Namespace
Cilium的套接字级负载均衡器对低层数据路径操作是透明的,即在连接(TCP,已连接的UDP)、sendmsg(UDP)或recvmsg(UDP)系统调用时,会根据目标IP选择现有服务IP之一,并选择一个服务后端作为目标。这意味着尽管应用程序认为自己连接到服务地址,但内核套接字实际上连接到后端地址,因此无需额外的下层NAT。
Cilium内置了绕过套接字级负载均衡器并在veth接口上返回到tc(流量控制)负载均衡器的支持,当自定义重定向或操作依赖于 pod 命名空间内的原始ClusterIP(例如,Istio sidecar)或者由于 Pod 的特性套接字级负载均衡器无效时(例如,KubeVirt,Kata Containers,gVisor)。
通过设置socketLB.hostNamespaceOnly=true来启用此绕过模式。启用后,这将绕过连接(connect())和发送消息(sendmsg())系统调用的BPF挂钩中的套接字重写,允许原始数据包继续到下一个操作阶段(例如,以每个端点路由模式在堆栈中)并重新启用tc BPF程序中的服务查找。
以下是在kube-proxy-free环境中具有套接字负载均衡器绕过的Helm示例配置:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=native \
--set kubeProxyReplacement=true \
--set socketLB.hostNamespaceOnly=true负载均衡器和 NodePort XDP 加速
Cilium内置支持加速NodePort、LoadBalancer服务和具有externalIPs的服务,以便在到达请求需要转发且后端位于远程节点的情况下进行加速。此功能在Cilium 1.8版本引入,位于XDP(eXpress Data Path)层,在该层中,eBPF直接在网络驱动程序中运行,而不是在更高层运行。
将loadBalancer.acceleration设置为选项native可启用此加速功能。选项disabled是默认值,会禁用加速。大多数支持10G或更高速率的驱动程序也支持最新内核上的本地XDP。对于基于云的部署,大多数这些驱动程序都有支持本地XDP的SR-IOV变体。对于本地部署,Cilium XDP加速可以与诸如MetalLB之类的Kubernetes LoadBalancer服务实现组合使用。加速仅能在用于直接路由的单个设备上启用。
对于高规模环境,还可以考虑调整默认映射大小到更大的条目数,例如通过设置较高的config.bpfMapDynamicSizeRatio。
loadBalancer.acceleration设置支持DSR、SNAT和混合模式,并可如下示例中的loadBalancer.mode=hybrid,如下所示:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set routingMode=native \
--set kubeProxyReplacement=true \
--set loadBalancer.acceleration=native \
--set loadBalancer.mode=hybrid \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}在多设备环境中,当Cilium的设备自动检测选择多个设备来公开NodePort或用户指定多个设备时,将在所有设备上启用XDP加速。这意味着每个底层设备的驱动程序在所有Cilium托管节点上必须具有本机XDP支持。如果您的环境中一些设备支持XDP而其他设备不支持,您可以通过将loadBalancer.acceleration设置为best-effort,在支持的设备上启用XDP。此外,出于性能原因,我们建议在多设备XDP加速时使用内核版本 >= 5.5。NodePort Devices, Port and Bind 设置
在运行Cilium的eBPF kube-proxy替代品时,默认情况下,通过具有主机上默认路由或Kubernetes InternalIP或ExternalIP分配的本机设备的IP地址,可以访问NodePort或LoadBalancer服务,或具有externalIPs的服务。如果存在两者,则优先选择InternalIP而不是ExternalIP。要更改设备,请在devices Helm选项中设置它们的名称,例如,devices='{eth0,eth1,eth2}'。列出的每个设备在所有由Cilium管理的节点上必须命名相同。或者,如果设备在不同节点上不匹配,可以使用通配符选项,例如,devices=eth+,这将匹配以eth为前缀开头的任何设备。如果找不到匹配的设备,则Cilium代理将尝试执行自动检测。
当使用多个设备时,只能使用一个设备进行Cilium节点之间的直接路由。默认情况下,如果检测到单个设备或通过devices指定了一个设备,则Cilium将使用该设备进行直接路由。否则,Cilium将使用具有Kubernetes InternalIP或ExternalIP设置的设备。如果两者都存在,则优先选择InternalIP而不是ExternalIP。要更改直接路由设备,请设置nodePort.directRoutingDevice Helm选项,例如,nodePort.directRoutingDevice=eth1。也可以使用通配符选项以及devices选项,例如,directRoutingDevice=eth+。如果有多个设备匹配通配符选项,Cilium将按字母数字顺序递增排序并选择第一个设备。如果直接路由设备不存在于devices中,Cilium将将该设备添加到后者列表中。直接路由设备也用于NodePort XDP加速(如果已启用)。
此外,由于socket-LB功能,NodePort服务可以通过其公共地址、集群内的主机或pod通过任何本地地址(除了以docker*前缀命名的名称)或回环地址默认访问,例如,127.0.0.1:NODE_PORT。
如果kube-apiserver配置为使用非默认NodePort端口范围,则必须通过nodePort.range选项将相同的范围传递给Cilium,例如,将nodePort.range设置为"10000\,32767",表示范围为10000-32767。默认的Kubernetes NodePort范围是30000-32767。
如果NodePort端口范围与临时端口范围(net.ipv4.ip_local_port_range)重叠,Cilium将在保留端口范围(net.ipv4.ip_local_reserved_ports)后附加NodePort范围。这是为了防止NodePort服务夺取与服务端口匹配的主机本地应用程序的流量。要禁用保留端口的修改,将nodePort.autoProtectPortRanges设置为false。
默认情况下,NodePort实现会阻止应用程序对NodePort服务端口进行bind(2)请求。在这种情况下,应用程序通常会看到一个bind: Operation not permitted错误。对于较旧的内核,这会全局发生,或者从v5.7内核开始,只针对默认情况下的主机命名空间,因此不再影响任何应用程序pod的bind(2)请求。要从一般情况中退出此行为,专业用户可以通过将nodePort.bindProtection切换为false来更改此设置。配置 BPF Map 大小
对于大型环境,Cilium的BPF映射可以配置为具有更高的条目限制。可以使用覆盖Helm选项来调整这些限制。
要增加Cilium的BPF LB服务、后端和关联映射中的条目数,请考虑覆盖bpf.lbMapMax Helm选项。该LB映射大小的默认值为65536。
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=true \
--set bpf.lbMapMax=131072容器 HostPort 支持
虽然不是kube-proxy的一部分,Cilium的eBPF kube-proxy replacement方案也原生支持hostPort服务映射,无需使用Helm CNI链接选项cni.chainingMode=portmap。
通过指定kubeProxyReplacement=true,原生hostPort支持会自动启用,因此不需要进一步操作。否则,可以使用hostPort.enabled=true来启用该设置。
如果在不指定额外hostIP的情况下指定了hostPort,那么Pod将以与用于暴露NodePort服务的节点相同的本地地址暴露到外部,例如检测并用于暴露NodePort服务时的Kubernetes InternalIP或ExternalIP(如果设置)。此外,Pod还可以通过节点上的环回地址访问,例如127.0.0.1:hostPort。如果除了hostPort外还为Pod指定了hostIP,那么Pod将仅在给定的hostIP上暴露。hostIP为0.0.0.0时将具有与未指定hostIP时相同的行为。为了避免冲突,hostPort不能位于配置的NodePort端口范围内。
在一个无kube-proxy的环境中,部署示例:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=true \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}优雅终止
Cilium 的 eBPF kube-proxy 替代品支持服务端点 pod 的优雅终止。该功能至少需要 Kubernetes 1.20 版本,并且需要启用功能门 EndpointSliceTerminateCondition。默认情况下,Cilium 代理会检测此类终止 Pod 事件,并增加指标 k8s_termination_endpoints_events_total。如果需要,可以使用配置选项enable-k8s-termination-endpoint 禁用该功能。$ kubectl -n kube-system exec ds/cilium -- cilium-dbg status --verbose
[...]
KubeProxyReplacement Details:
[...]
Graceful Termination: Enabled
[...]会话亲和性
Cilium的eBPF kube-proxy replacement 方案支持Kubernetes服务会话亲和性。来自同一Pod或主机到配置了sessionAffinity: ClientIP的服务的每个连接将始终选择相同的服务端点。亲和性的默认超时时间为三小时(每个请求到服务时更新),但如果需要,可以通过Kubernetes的sessionAffinityConfig进行配置。
亲和性的源取决于请求的发起源。如果从集群外部发送请求到服务,则使用请求的源IP地址来确定端点亲和性。如果从集群内部发送请求,则源取决于是否使用socket-LB功能来负载平衡ClusterIP服务。如果是,则使用客户端的网络命名空间cookie作为源。后者是在5.7版Linux内核中引入的,用于在socket-LB操作的套接字层实现亲和性(在那里并没有可用的源IP,因为端点选择发生在内核构建网络数据包之前)。如果不使用socket-LB(即在每个数据包接口上对Pod网络接口进行负载平衡),则使用请求的源IP地址作为源。
对于Cilium的kube-proxy replacement 方案,默认情况下启用了会话亲和性支持。对于不支持网络命名空间cookie的旧内核的用户,实施了一种基于固定cookie值的集群内部模式作为权衡方案。这使得主机上的所有应用程序对于配置了会话亲和性的给定服务都会选择同一个服务端点。要禁用该功能,请设置config.sessionAffinity=false。
当不使用固定的cookie值时,具有多个端口的服务的会话亲和性是按照服务IP和端口进行的。这意味着从相同源发送到相同服务端口的给定服务的所有请求将被路由到相同的服务端点;但同一服务的两个请求,从相同源发出但发送到不同服务端口,可能会被路由到不同的服务端点。
对于仍在使用kube-proxy的用户(即已禁用Cilium的kube-proxy replacement 方案的用户),当从运行在非主机网络命名空间中的Pod发送请求时,ClusterIP服务的负载平衡仍然在Pod网络接口上执行(直到GH#16197被修复)。对于这种情况,默认情况下会禁用会话亲和性支持。要启用此功能,请设置config.sessionAffinity=true。kube-proxy 替换健康检查服务器
要为kube-proxy replacement 方案启用健康检查服务器,必须设置kubeProxyReplacementHealthzBindAddr选项(默认情况下禁用)。该选项接受 IP 地址和端口,用于健康检查服务器提供服务。例如,要为 IPv4 接口启用,设置 kubeProxyReplacementHealthzBindAddr='0.0.0.0:10256',对于 IPv6,设置 kubeProxyReplacementHealthzBindAddr='[::]:10256'。健康检查服务器可通过HTTP /healthz端点访问。LoadBalancer 源范围检查
当使用`spec.loadBalancerSourceRanges`配置LoadBalancer服务时,Cilium的eBPF kube-proxy替代方案会将外部世界流量(例如外部流量)访问服务限制在字段中指定的白名单CIDR范围内。如果该字段为空,则不会对访问施加任何限制。
当从集群内部访问服务时,kube-proxy replacement 方案将忽略该字段是否设置。这意味着集群中的任何Pod或主机进程都可以在内部访问LoadBalancer服务。
负载均衡器源范围检查功能默认启用,可以通过设置`config.svcSourceRangeCheck=false`来禁用该功能。在某些云服务提供商上运行时,禁用检查是有意义的。例如,Amazon NLB本身实现了该检查,因此可以禁用kube-proxy replacement 方案的功能。同时,GKE内部TCP/UDP负载均衡器则没有这种实现,因此必须保持该功能启用,以限制访问。服务代理名称配置
与kube-proxy类似,Cilium也遵循service.kubernetes.io/service-proxy-name服务注解,并且只管理包含匹配的service-proxy-name标签的服务。这个名称可以通过设置k8s.serviceProxyName选项进行配置,其行为与kube-proxy相同。服务代理名称默认为空字符串,这指示Cilium只管理没有service.kubernetes.io/service-proxy-name标签的服务。拓扑感知提示
kube-proxy replacement 实现了 K8s 服务拓扑感知提示。这允许 Cilium 节点优先选择驻留在同一区域的服务端点。要启用该功能,请设置 loadBalancer.serviceTopology=true。Neighbor Discovery
当启用kube-proxy replacement 方案时,Cilium会对集群中的节点进行L2邻居发现。这对于服务负载平衡是必要的,以便为后端填充L2地址,因为在快速路径上无法动态解析邻居。
在Cilium 1.10或更早版本中,代理本身包含一个ARP解析库,它触发了对加入集群的新节点的发现和定期刷新。已解析的邻居条目被推送到内核并作为永久条目进行刷新。在一些罕见情况下,Cilium 1.10或更早版本可能会在邻居表中留下过时的条目,导致某些节点之间的数据包被丢弃。要跳过邻居发现,而是依赖Linux内核来发现邻居,您可以向`cilium-agent`传递`--enable-l2-neigh-discovery=false`标志。但是,请注意,依赖Linux内核可能也会导致某些数据包被丢弃。例如,NodePort请求可能会在中间节点上被丢弃(即接收到服务数据包并将其转发到运行所选服务端点的目标节点的节点)。这可能会发生,如果内核中没有L2邻居条目(由于条目被垃圾收集或由于内核没有进行邻居解析)。
从Cilium 1.11开始,邻居发现已完全重做,Cilium内部的ARP解析库已从代理中移除。代理现在完全依赖Linux内核来发现在同一L2网络中的网关或主机。Cilium代理支持IPv4和IPv6邻居发现。根据我们最近在Plumbers上展示的内核工作,“managed”邻居条目已被上游并将在Linux内核v5.16或更高版本中可用,Cilium代理将检测并透明地使用这些条目。在这种情况下,代理将新加入集群的节点的L3地址作为外部学习的“managed”邻居条目推送下去。对于内省,iproute2将它们显示为“managed extern_learn”。“extern_learn”属性阻止了内核邻居子系统对条目的垃圾收集。这样的“managed”邻居条目由Linux内核自身动态解析并定期刷新,以防止一段时间内没有活动流量。换句话说,内核试图始终将它们保持在可达状态。对于较早的Linux内核版本v5.15或更早版本,在其中“managed”邻居条目不存在的情况下,Cilium代理类似地将新节点的L3地址推送到内核进行动态解析,但通过代理触发的定期刷新。在这种情况下,iproute2仅将它们显示为“extern_learn”。如果一段时间内没有活动流量,则Cilium代理控制器会触发基于Linux内核的重新解析,以试图保持它们处于可达状态。如果需要,刷新间隔可以通过传递`--arping-refresh-period=30s`标志给`cilium-agent`来进行更改。默认周期为30秒,对应于内核的基本可达时间。
neighbor discovery支持多设备环境,其中每个节点具有多个设备和到另一个节点的多个下一跳。Cilium代理为所有目标设备(包括直接路由设备)推送邻居条目。目前,它支持每个设备一个下一跳。以下示例说明了邻居发现在多设备环境中的工作方式。每个节点有两个连接到不同L3网络(10.69.0.64/26和10.69.0.128/26)的设备以及每个设备一个全局范围地址(分别为10.69.0.1/26和10.69.0.2/26)。从节点1到节点2的下一跳可以是10.69.0.66 dev eno1或者10.69.0.130 dev eno2。在这种情况下,Cilium代理为10.69.0.66 dev eno1和10.69.0.130 dev eno2都推送邻居条目。
+---------------+ +---------------+
| node1 | | node2 |
| 10.69.0.1/26 | | 10.69.0.2/26 |
| eno1+-----+eno1 |
| | | | | |
| 10.69.0.65/26 | |10.69.0.66/26 |
| | | |
| eno2+-----+eno2 |
| | | | | |
| 10.69.0.129/26| | 10.69.0.130/26|
+---------------+ +---------------+
$ ip route show
10.69.0.2
nexthop via 10.69.0.66 dev eno1 weight 1
nexthop via 10.69.0.130 dev eno2 weight 1
$ ip neigh show
10.69.0.66 dev eno1 lladdr 96:eb:75:fd:89:fd extern_learn REACHABLE
10.69.0.130 dev eno2 lladdr 52:54:00:a6:62:56 extern_learn REACHABLE对 ClusterIP 服务的外部访问
根据 k8s 服务,Cilium 的 eBPF kube-proxy replacement 默认情况下不允许从集群外部访问 ClusterIP 服务。这可以通过设置 bpf.lbExternalClusterIP=true 来允许。kube-proxy replacement 局限性
Cilium的eBPF kube-proxy replacement 当前无法与IPsec透明加密一起使用。
Cilium的eBPF kube-proxy replacement 依赖于socket-LB功能,该功能使用eBPF cgroup钩子来实现服务转换。目前,将其与libceph部署一起使用需要支持getpeername(2)钩子地址转换的eBPF,这只适用于v5.8及更高版本的内核。
为了支持内核中带有socket-LB功能的nfs,请确保您的底层内核包括内核提交0bdf399342c5("net: 避免在kernel_connect中地址覆盖")。Linux内核v6.6及更高版本支持它。较旧的稳定内核仍待确定。
Cilium的DSR NodePort模式目前在启用TCP快速开放(TFO)的环境中运行不佳。在这种情况下,建议切换到snat模式。
Cilium的eBPF kube-proxy replacement 不支持SCTP传输协议。目前,只支持TCP和UDP作为服务的传输协议。
Cilium的eBPF kube-proxy replacement 不允许Pods的hostPort端口配置与配置的NodePort范围重叠。在这种情况下,将忽略hostPort设置,并向Cilium代理日志发出警告。同样,当前不支持在宿主命名空间中将hostIP显式绑定到回环地址,这将在Cilium代理日志中记录警告。
当Cilium的kube-proxy replacement 与支持EndpointSlices的Kubernetes版本(< 1.19)一起使用时,没有选择器和支持Endpoints的服务将不起作用。原因是Cilium只在支持的情况下监视对EndpointSlices对象的更改,并在这些情况下忽略Endpoints。Kubernetes 1.19版本引入了EndpointSliceMirroring控制器,它将自定义Endpoints资源镜像到相应的EndpointSlices中,从而允许支持Endpoints的工作。
在部署在老于5.7的内核上时,由于缺乏对网络命名空间cookie的内核支持,Cilium无法区分宿主和Pod命名空间。结果是,Kubernetes服务可以通过回环地址从所有Pods访问。
在多设备环境中,neighbor discovery 无法与运行时设备检测一起工作,这意味着 neighbor discovery 的目标设备不会跟随设备更改。
当启用socket-LB功能时,向服务发送(已连接的)UDP流量的Pods即使在其后端被删除后也可以继续向服务发送流量。Cilium代理通过强制终止连接到已删除后端的宿主网络命名空间中的Pod套接字来处理此类场景,以便Pods可以被负载平衡到活动后端。此功能要求启用这些内核配置:CONFIG_INET_DIAG、CONFIG_INET_UDP_DIAG和CONFIG_INET_DIAG_DESTROY。如果您有应用Pods(未部署在宿主网络命名空间中)使用(已连接的)UDP进行长期连接,您可以启用bpf-lb-sock-hostns-only以便仅在宿主网络命名空间中启用socket-LB功能。kube-proxy Hybrid 模式
Cilium 的 eBPF kube-proxy replacement可以配置为多种模式,即它可以完全替换 kube-proxy,或者如果底层 Linux 内核要求不支持完整的 kube-proxy 替换,它可以与系统上的 kube-proxy 共存。
在系统上与 kube-proxy 共存的情况下部署 eBPF kube-proxy replacement 时,请注意这两种机制彼此独立运行。这意味着,如果在已运行的集群上添加或删除 eBPF kube-proxy replacement ,以便分别将操作委托回 kube-proxy,则必须预期现有连接将中断,因为例如,两个 NAT 表都在彼此不认识。如果在新生成的节点/集群上共存部署且尚未服务用户流量,那么这不是问题。kubeProxyReplacement=true:使用此选项时,强烈建议运行无 kube-proxy 的 Kubernetes 设置,其中 Cilium 预计将完全取代所有 kube-proxy 功能。但是,如果由于特定原因(例如 Kubernetes 分发限制)而无法删除 kube-proxy,也可以将其部署在后台。只需注意共存运行 kube-proxy 时对现有节点的潜在副作用,如上所述。一旦 Cilium 代理启动并运行,它就会负责处理 ClusterIP、NodePort、LoadBalancer 类型的 Kubernetes 服务、具有外部 IP 的服务以及 HostPort。如果不满足底层内核版本要求,那么 Cilium 代理将在启动时退出并显示错误消息。
kubeProxyReplacement=false:这个选项用于禁用任何由kube-proxy完全处理的Kubernetes服务,而是完全依赖kube-proxy,除了从Pod访问的ClusterIP服务(预v1.6行为),或者用于混合设置。也就是说,在Cilium部分替换和优化kube-proxy功能的Kubernetes集群中运行kube-proxy。将该选项设为false需要用户手动指定应该使用eBPF kube-proxy替代方案的组件。与true模式类似,如果在手动启用组件时不满足底层内核要求,Cilium代理将在启动时退出,并显示错误消息。为了进行细粒度配置,可以将socketLB.enabled、nodePort.enabled、externalIPs.enabled和hostPort.enabled设置为true。默认情况下,这四个选项都设置为false。如果将nodePort.enabled设置为true,请确保还将nodePort.enableHealthCheck设置为false,以便Cilium代理不启动NodePort健康检查服务器(kube-proxy也会尝试启动该服务器,在Cilium尝试将其服务器绑定到相同端口时会有冲突)。以下提供了几个对于false选项的示例配置。在true和false模式之间切换,或反之,可能会中断集群中对服务的现有连接。启用或禁用socketLB也是如此。建议在执行此类配置更改之前将所有工作负载排空。
以下Helm设置等效于kubeProxyReplacement=true在无kube-proxy环境中:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=false \
--set socketLB.enabled=true \
--set nodePort.enabled=true \
--set externalIPs.enabled=true \
--set hostPort.enabled=true \
--set k8sServiceHost=${API_SERVER_IP} \
--set k8sServicePort=${API_SERVER_PORT}
下面的 Helm 设置相当于 kube-proxy 环境中 v1.6 或更早版本中的默认 Cilium 服务处理,即为 pod 提供 ClusterIP:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=false
下面的 Helm 设置将优化 Cilium 的 NodePort、LoadBalancer 和服务,并通过外部 IP 处理进入 kube-proxy 环境中 Cilium 托管节点的外部流量:
helm install cilium cilium/cilium --version 1.15.4 \
--namespace kube-system \
--set kubeProxyReplacement=false \
--set nodePort.enabled=true \
--set externalIPs.enabled=true参考文档
https://docs.cilium.io/en/stable/network/kubernetes/intro/#/introduction

 浙公网安备 33010602011771号
浙公网安备 33010602011771号