Istio可观测性
可观测性应用
- 日志、指标和跟踪是应用程序可观测性的三大支柱,前二者更多的是属于传统的“以主机为中心”的模型,而跟踪则“以流程为中心”
- 日志:日志是随时间发生的离散事件的不可变时间戳记录,对单体应用很有效,但分布式系统的故障通常会由多个不同组件之间的互连事件触发
-
ElasticStack、Splunk、Fluentd...
-
- 指标:由监控系统时序性收集和记录的固定类型的可聚合数据,同样对单体应用较有效,但它们无法提供足够的信息来理解分布式系统中调用(RPC)的生命周期
-
Statsd、Prometheus...
-
-
跟踪:跟踪是跟随一个事务或一个请求从开始到结束的整体生命周期的过程,包括其所流经的组件
-
分布式跟踪是跟踪和分析分布式系统中所有服务中的请求或事务发生的情况的过程
-
“跟踪”意味着获取在每个服务中生成原始数据
-
“分析”意味着使用各种搜索、聚合、可视化和其它分析工具,帮助用户挖掘原始跟踪数据的价值
-
-
- 日志:日志是随时间发生的离散事件的不可变时间戳记录,对单体应用很有效,但分布式系统的故障通常会由多个不同组件之间的互连事件触发
-
Istio的可观测性
-
Istio为网格内所有的服务间通信生成详细的可观测数据,以便于运维人员进行排障、维护和优化;
-
它生成的遥测类型数据包括如下几种
-
Metrics:服务指标(基于四个黄金信号:延迟、流量、错误和饱和度)和控制平面的详细指标;
-
Distributed Traces:支持为每个服务生成span,以记录服务依赖和调用关系;
-
Access Log:可于workload级别为每个服务请求生成完整的记录,包括源和目标的元数据;
-
-
Istio的可观测性
Metrics
Metrics:Istio会为所有服务的流量和自身控制平面的各组件生成详细的指标;但究竟要收集哪些指标则由运维人员通过配置来确定;
-
Proxy-level metrics:代理级指标,数据平面指标
-
Envoy Proxy会为出入的所有流量生成丰富的一组指标
-
Envoy Proxy还会生成自身管理功能的详细统计信息,包括配置和运行状态等
-
-
Service-level metrics:服务指标,用于监控服务通信,数据平面指标
-
面向服务的指标主要包括服务监视的四个基本需求:延迟、流量、错误和饱和度;
-
-
Control plane metrics,控制平面指标
-
istiod还提供了一组自我监控的指标,这些指标允许监控Istio自身的行为;
-
Distributed Traces
-
Istio支持通过代理程序Envoy进行分布式跟踪
-
这意味着被代理的应用程序只需要转发适当的context即可,实现了“近零侵入”
-
支持Zipkin、Jaeger、LightStep和Datadog等后端系统
-
支持运维人员自定义采样频率
Access Log
-
访问日志提供了从单个workload级别监视和了解服务行为的方法
-
日志格式可由运维人员按需进行定义,且可把日志导出到自定义的后端,例如Fluentd等;
Istio的可观测性功能
-
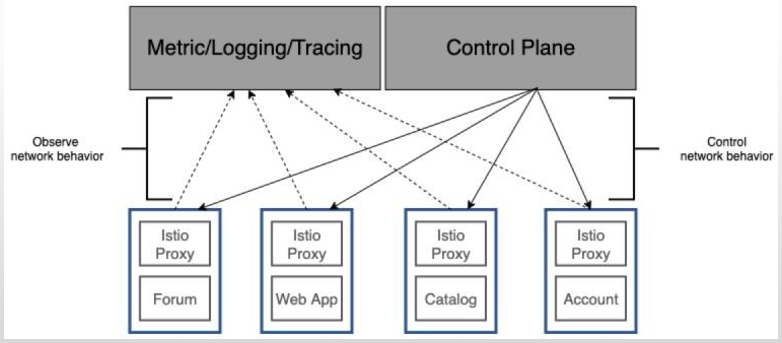
Istio的可观测性功能主要发生网格中的数据平面上
-
因为数据平面代理istio-proxy(Envoy)位于服务间的请求路径上
-
Istio需要通过Envoy捕获与请求处理和服务交互相关的重要指标
-
Istio还附带了一些OOTB工具,例如Prometheus、Grafana和Kiali等
-
Istio的可观测机制
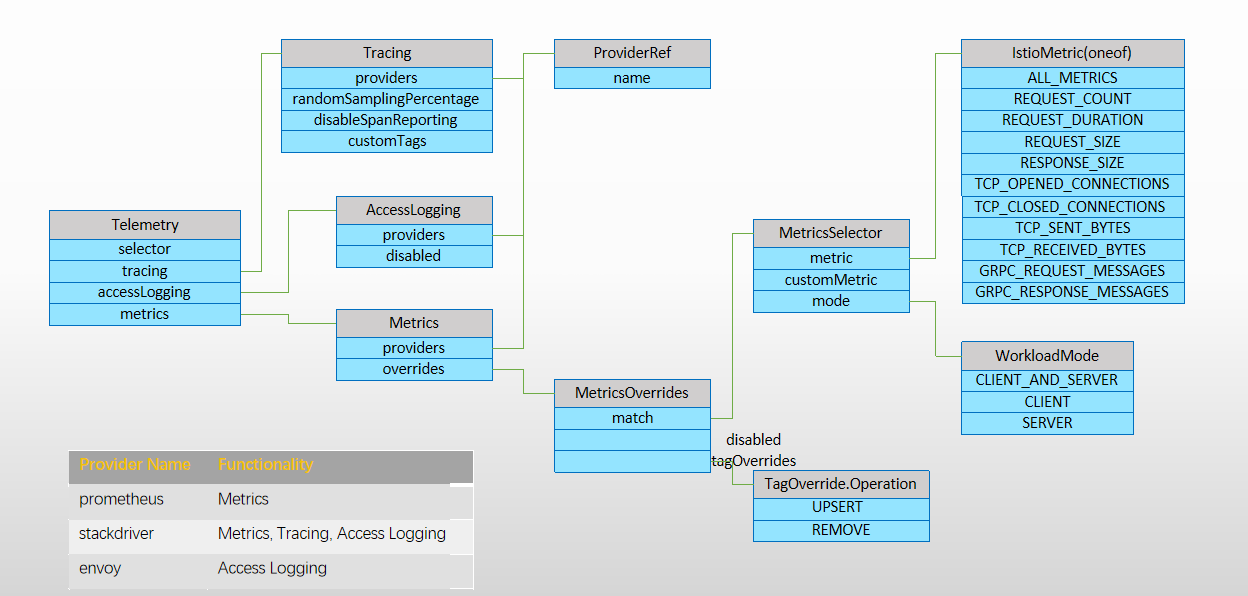
Istio在网格代理上启用的可观测机制,可以在部署Istio时进行配置,也可随后通过MeshConfig或者Telemetry CR定义
启用网格的可观测性
- 部署网格时,通过IstioOperator配置中的MeshConfig段进行全局配置
-
部署网格后,通过IstioOperator配置中的MeshConfig段进行全局配置
-
通过Telemetry API(Telemetry CR资源)定义
-
在root namespace(例如istio-system)中配置
-
为特定的namespace进行配置
-
为namespace中的特定workload进行配
-
- 在工作负载的podTemplate资源上,通过“proxy.istio.io/config”注解进行配置
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
spec:
meshConfig:
enableTracing: true # 启用追踪功能
accessLogFile: /dev/stdout # 启用日志,并指定文件
defaultConfig: # 代理相关的配置
tracing: {} # 代理上的追踪机制
proxyStatsMatcher: {} # Stats插件提供的服务指标apiVersion: apps/v1
kind: Deployment
metadata:
name: ...
spec:
...
template:
metadata:
...
annotations: # 访问日志不支持该中配置方式
proxy.istio.io/config: |
tracing: {}
proxyStatsMatcher: {}
spec:
...Telemetry CR 资源规范
Metrics
-
Istio会为所有服务的进出流量及控制平面自身分别生成详细的指标;
-
服务指标:用于监控服务的访问行为
-
控制平面指标:用于监控控制平面自身
-
-
Istio提供的指标类别
-
代理级(Proxy Level)指标
-
流经每个Proxy的入站和出站流量相关的丰富指标
-
Envoy代理程序本身的统计信息
-
相关指标由各Envoy实例自行提供,Prometheus抓取指标相关的端口为15020/tcp;
-
-
服务级(Service Level)指标
-
用于监控服务通信的专用指标
-
涵盖了服务监控的四个基本需求:延迟、流量、错误和饱和度
-
相关指标由各Envoy实例上的WASM插件(stats或stackdriver)提供
-
-
控制平面指标
-
控制平面提供的自我监控的指标,这些指标允许监控Istio自身的行为
-
Prometheus抓取指标的相关端口为15014/tcp;
-
-
Envoy状态统计
-
Envoy运行过程中会生成大量的统计数据,这些统计数据大体可以分为三类
- DownStream:与传入当前Envoy实例相关的连接相关的统计信息,主要由侦听器、HTTP连接管理器和TCP代理过滤器等生成
- UpStream:与离开当前Envoy实例相关的连接相关的统计信息,主要由集群管理器、配置的每个集群、健康状态检测、异常值探测、断路器、TLS等等生成
-
Envoy Server:记录了Envoy服务器实例的工作细节,例如服务器正常运行时间或分配的内存量等
-
Envoy统计的数据类型主要有三类,数据类型均为无符号整数
-
Counter:累加型的计数器数据,单调递增,例如total requests等
-
Gauge:常规的指标数据,可增可降,例如current active requests等
- Histogram:柱状图数据, 主要用于统计一些数据的分布情况,用于计算在一定范围内的分布情况,同时还提供了度量指标值的总和,例如upstream request time
-
参考文档
https://istio.io/latest/zh/docs/tasks/observability/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号