Envoy 上游集群负载均衡
负载均衡概述
什么是负载均衡
- 负载均衡是一种在单个上游集群内的多个主机之间分配流量的方法,以便有效地利用可用资源。有很多不同的方法可以实现这一点,因此 Envoy 提供了几种不同的负载平衡策略。在高层次上,我们可以将这些策略分为两类:全局负载均衡和分布式负载均衡。
分布式负载均衡
- Envoy自身基于上游主机(区域感知)的位置及健康状态等来确定如何分配负载至相关端点
- 主动健康检查:通过健康检查上游主机,Envoy 可以调整优先级和位置的权重以考虑不可用的主机。
-
区域感知路由:这可用于使 Envoy 更喜欢更近的端点,而无需在控制平面中显式配置优先级。
-
负载平衡算法:Envoy 可以使用几种不同的算法来使用提供的权重来确定选择哪个主机。
全局负载均衡
- 全局负载平衡是指拥有一个单一的全局权限来决定如何在主机之间分配负载。对于 Envoy,这将由控制平面完成,它能够通过指定各种参数(例如优先级、位置权重、端点权重和端点健康)来调整施加到各个端点的负载。
-
优先级
-
位置权重
-
端点权重
-
端点健康状态
-
- 一个简单的例子是让控制平面根据网络拓扑为主机分配不同 的优先级,以确保首选需要较少网络跃点的主机。这类似于区域感知路由,但由控制平面而不是 Envoy 处理。在控制平面中这样做的一个好处是它绕过了区域感知路由的一些 限制。
- 更复杂的设置可能会将资源使用情况报告给控制平面,允许它调整端点或位置的权重以 考虑当前资源使用情况,尝试将新请求路由到空闲主机而不是繁忙主机。
分布式和全局
- 最复杂的部署将利用这两个类别的功能。例如,全局负载平衡可用于定义高级路由优先级和权重,而分布式负载平衡可用于对系统中的变化做出反应(例如使用主动健康检查)。通过将这些结合起来,您可以获得两全其美:一个具有全局意识的权威机构,可以在宏观层面控制流量,同时仍然让各个代理能够对微观层面的变化做出反应。
负载均衡算法
当过滤器需要获取到上游集群中主机的连接时,集群管理器使用负载平衡策略来确定选择哪个主机。负载平衡策略是可插入的,并在配置中针对每个上游集群指定。请注意,如果没有为集群配置活动的健康检查策略,则所有上游集群成员都被认为是健康的,除非通过 health_status另有指定。
加权轮询(weighted round robin)
加权轮询概述
- 这是一个简单的策略,其中每个可用的上游主机都是按循环顺序选择的。如果将权重分配给某个地方的端点,则使用加权循环调度,其中较高权重的端点将更频繁地出现在轮换中以实现有效加权。
-
算法名称为ROUND_ROBIN
加权轮询配置参数
round_robin_lb_config:
slow_start_config: {...} # 慢启动模式的配置。如果未设置此配置,则不会启用慢启动。加权轮询配置示例
查看代码
admin:
profile_path: /tmp/envoy.prof
access_log_path: /tmp/admin_access.log
address:
socket_address: { address: 0.0.0.0, port_value: 9901 }
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 0.0.0.0, port_value: 80 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: webservice
domains: ["*"]
routes:
- match: { prefix: "/" }
route: { cluster: web_cluster_01 }
http_filters:
- name: envoy.filters.http.router
clusters:
- name: web_cluster_01
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: web_cluster_01
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: red
port_value: 80
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: blue
port_value: 80
load_balancing_weight: 3
- endpoint:
address:
socket_address:
address: green
port_value: 80
load_balancing_weight: 5加权最少请求(weighted least request)
加权最少请求概述
最小请求负载均衡器根据主机是否具有相同或不同的权重使用不同的算法。
-
算法名称为LEAST_REQUEST
-
all weights equal :一种 O(1) 算法,它选择配置中指定的 N 个随机可用主机 (默认为 2 个)并选择具有最少活动请求的主机(Mitzenmacher 等人已经证明这种方法几乎一样好作为 O(N) 全扫描)。这也称为 P2C(两种选择的力量)。P2C 负载均衡器具有集群中活动请求数量最多的主机永远不会收到新请求的属性。它将被允许耗尽,直到它小于或等于所有其他主机。
-
all weights not equal:如果集群中的两台或多台主机具有不同的负载均衡权重,负载均衡器将切换到使用加权轮询调度的模式,在这种模式下,权重会根据主机的请求负载动态调整选择。
-
在这种情况下,权重是在选择主机时使用以下公式计算的-
weight = load_balancing_weight / (active_requests + 1)^active_request_bias.
-
- active_request_bias 可以通过运行时配置,默认为 1.0。它必须大于或等于 0.0。
- 主动请求偏差越大,越积极主动的请求会降低有效权重。
- 如果
active_request_bias设置为 0.0,则最小请求负载均衡器的行为类似于循环负载均衡器,并在挑选时忽略活动请求计数。 - 例如,如果 active_request_bias 为 1.0,则权重为 2 且活动请求计数为 4 的主机的有效权重为 2 / (4 + 1)^1 = 0.4。该算法在稳定状态下提供了良好的平衡,但可能无法快速适应负载不平衡。此外,与 P2C 不同,主机永远不会真正耗尽,尽管随着时间的推移它会收到更少的请求。
-
加权最少请求配置参数
least_request_lb_config:
choice_count: "{...}" # 从健康主机中随机挑选出多少个做为样本进行最少连接数比较;默认为 2,因此如果未设置该字段,我们将执行二选一。
active_request_bias: {...} # weight = load_balancing_weight / (active_requests + 1)^active_request_bias
slow_start_config: {...} # 慢启动模式的配置。如果未设置此配置,则不会启用慢启动。加权最少请求配置示例
查看代码
admin:
profile_path: /tmp/envoy.prof
access_log_path: /tmp/admin_access.log
address:
socket_address: { address: 0.0.0.0, port_value: 9901 }
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 0.0.0.0, port_value: 80 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: webservice
domains: ["*"]
routes:
- match: { prefix: "/" }
route: { cluster: web_cluster_01 }
http_filters:
- name: envoy.filters.http.router
clusters:
- name: web_cluster_01
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: LEAST_REQUEST
load_assignment:
cluster_name: web_cluster_01
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: red
port_value: 80
load_balancing_weight: 1
- endpoint:
address:
socket_address:
address: blue
port_value: 80
load_balancing_weight: 3
- endpoint:
address:
socket_address:
address: green
port_value: 80
load_balancing_weight: 5环哈希(ring hash)
环哈希概述
- Envoy使用ring/modulo算法对同一集群中的上游主机实行一致性哈希算法,但它需要依赖于在路由中定义了相应的哈希策略时方才有效;
-
通过散列其地址的方式将每个主机映射到一个环上;
-
然后,通过散列请求的某些属性后将其映射在环上,并以顺时针方式找到最接近的对应主机从而完成路由;
-
该技术通常也称为“ Ketama” 散列,并且像所有基于散列的负载平衡器一样,仅在使用协议路由指定要散列的值时才有效;
-
-
为了避免环偏斜,每个主机都经过哈希处理,并按其权重成比例地放置在环上;
- 最佳做法是显式设置minimum_ring_size和maximum_ring_size参数,并监视min_hashes_per_host和max_hashes_per_host指标以确保请求的能得到良好的均衡;
环哈希配置参数
ring_hash_lb_config:
"minimum_ring_size": "{...}", # 哈希环的最小值,环越大调度结果越接近权重酷比,默认为1024,最在值为8M;
"hash_function": "...", # 哈希算法,支持XX_HASH和MURMUR_HASH_2两种,默认为前一种;
"maximum_ring_size": "{...}" # 哈希环的最大值,默认为8M;不过,值越大越消耗计算资源;环哈希配置示例
查看代码
admin:
profile_path: /tmp/envoy.prof
access_log_path: /tmp/admin_access.log
address:
socket_address: { address: 0.0.0.0, port_value: 9901 }
static_resources:
listeners:
- name: listener_0
address:
socket_address: { address: 0.0.0.0, port_value: 80 }
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: webservice
domains: ["*"]
routes:
- match: { prefix: "/" }
route:
cluster: web_cluster_01
hash_policy:
# - connection_properties:
# source_ip: true
- header:
header_name: User-Agent
http_filters:
- name: envoy.filters.http.router
clusters:
- name: web_cluster_01
connect_timeout: 0.5s
type: STRICT_DNS
lb_policy: RING_HASH
ring_hash_lb_config:
maximum_ring_size: 1048576
minimum_ring_size: 512
load_assignment:
cluster_name: web_cluster_01
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: myservice
port_value: 80
health_checks:
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 2
http_health_check:
path: /livez
expected_statuses:
start: 200
end: 399路由哈希策略
route.RouteAction.HashPolicy
- 用于一致性哈希算法的散列策略列表,即指定将请求报文的哪部分属性进行哈希运算并映射至主机的哈希环上以完成路由;
-
列表中每个哈希策略都将单独评估,合并后的结果用于路由请求;
-
组合的方法是确定性的,以便相同的哈希策略列表将产生相同的哈希
-
-
哈希策略检查的请求的特定部分不存时将会导致无法生成哈希结果
- 如果(且仅当)所有已配置的哈希策略均无法生成哈希,则不会为该路由生成哈希,在这种情况下,其行为与未指定任何哈希策略的行为相同(即,环形哈希负载均衡器将选择一个随机后端);
- 若哈希策略将“terminal”属性设置为true,并且已经生成了哈希,则哈希算法将立即返回,而忽略哈希策略列表的其余部分;
路由哈希策略配置
路由哈希策略定义在路由配置中。
查看代码
route_config:
...
virutal_host:s:
- ...
routes:
- match:
...
route:
...
hash_policy: [] # 指定哈希策略列表,每个列表项仅可设置如下header、cookie或connection_properties三者之一;
header: {...}
header_name: ... # 要哈希的首部名称
cookie: {...}
name: ... # cookie的名称,其值将用于哈希计算,必选项;
ttl: ... # 持续时长,不存在带有ttl的cookie将自动生成该cookie;如果TTL存在且为零,则生成的cookie将是会话cookie
path: ... # cookie的路径;
connection_properties: {...}
source_ip: ... # 布尔型值,是否哈希源IP地址;
terminal: ... # 是否启用哈希算法的短路标志,即一旦当前策略生成哈希值,将不再考虑列表中后续的其它哈希策略;路由哈希配置示例
下面的示例将哈希请求报文的源IP地址和User-Agent首部;
查看代码
static_resources:
listeners:
- address:
...
filter_chains:
- filters:
- name: envoy.http_connection_manager
...
route:
cluster: webcluster1
hash_policy:
- connection_properties:
source_ip: true
- header:
header_name: User-Agent
http_filters:
- name: envoy.filters.http.router
clusters:
- name: webcluster1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: RING_HASH
ring_hash_lb_config:
maximum_ring_size: 1048576
minimum_ring_size: 512
load_assignment:
...磁悬浮(maglev)
磁悬浮概述
-
Maglev是环哈希算法的一种特殊形式,它使用固定为65537的环大小;
- 环构建算法将每个主机按其权重成比例地放置在环上,直到环完全填满为止;例如,如果主机A的权重为1,主机B的权重为2,则主机A将具有21,846项,而主机B将具有43,691项(总计65,537项)
- 该算法尝试将每个主机至少放置一次在表中,而不管配置的主机和位置权重如何,因此在某些极端情况下,实际比例可能与配置的权重不同;
- 最佳做法是监视min_entries_per_host和max_entries_per_host指标以确保没有主机出现异常配置;
- 在需要一致哈希的任何地方,Maglev都可以取代环哈希;同时,与环形哈希算法一样,Magelev仅在使用协议路由指定要哈希的值时才有效;
-
通常,与环哈希ketama算法相比,Maglev具有显着更快的表查找建立时间以及主机选择时间;
-
稳定性略逊于环哈希;
-
磁悬浮配置参数
maglev_lb_config:
table_size: {...} # Maglev 散列的表大小。Maglev 的目标是“最小的干扰”,而不是绝对的保证。最小的中断意味着当上游主机的集合发生变化时,一个连接可能会被发送到与以前相同的上游。增加表大小可以减少中断量。表大小必须是质数,限制为 5000011。如果不指定,则默认为 65537。随机(random)
- 随机负载均衡器选择一个随机可用的主机。如果没有配置健康检查策略,随机负载均衡器的性能通常比轮询更好。随机选择避免了对失败主机之后的集合中的主机的偏见。
负载均衡策略
节点优先级
节点优先级概述
- EDS配置中,属于某个特定位置的一组端点称为LocalityLbEndpoints,它们具有相同的位置(locality)、权重(load_balancing_weight)和优先级(priority);
-
locality:从大到小可由region(地域)、zone(区域)和sub_zone(子区域)进行逐级标识;
- load_balancing_weight:可选参数,用于为每个priority/region/zone/sub_zone配置权重,取值范围[1,n);通常,一个locality权重除以具有相同优先级的所有locality的权重之和即为当前locality的流量比例;
-
此配置仅启用了位置加权负载均衡机制时才会生效;
-
-
priority:此LocalityLbEndpoints组的优先级,默认为最高优先级0;
-
- 通常,Envoy调度时仅挑选最高优先级的一组端点,且仅此优先级的所有端点均不可用时才进行故障转移至下一个优先级的相关端点;
- 注意,也可在同一位置配置多个LbEndpoints,但这通常仅在不同组需要具有不同的负载均衡权重或不同的优先级时才需要;
节点优先级配置格式
# endpoint.LocalityLbEndpoints
{
"locality": "{...}",
"lb_endpoints": [],
"load_balancing_weight": "{...}",
“priority”: “...“ # 0为最高优先级,可用范围为[0,N],但配置时必须按顺序使用各优先级数字,而不能跳过;默认为0;
}优先级调度
-
调度时,Envoy仅将流量调度至最高优先级的一组端点(LocalityLbEnpoints)
- 在最高优先级的端点变得不健康时,流量才会按比例转移至次一个优先级的端点;例如一个优先级中20%的端点不健康时,也将有20%的流量转移至次一个优先级端点;
-
超配因子:也可为一组端点设定超配因子,实现部分端点故障时仍将更大比例的流量导向至本组端点;
- 计算公式:转移的流量=100%-健康的端点比例*超配因子;于是,对于1.4的因子来说,20%的故障比例时,所有流量仍将保留在当前组;当健康的端点比例低于72%时,才会有部分流量转移至次优先级端点;
-
一个优先级别当前处理流量的能力也称为健康评分(健康主机比例*超配因子,上限为100%);
- 若各个优先级的健康评分总和(也称为标准化的总健康状态)小于100,则Envoy会认为没有足够的健康端点来分配所有待处理的流量,此时,各级别会根据其健康分值的比例重新分配100%的流量;例如,对于具有{20,30}健康评分的两个组(标准化的总健康状况为50)将被标准化,并导致负载比例为40%和60%;
- 另外,优先级调度还支持同一优先级内部的端点降级(DEGRADED)机制,其工作方式类同于在两个不同优先级之间的端点分配流量的机制;
-
非降级端点健康比例*超配因子大于等于100%时,降级端点不承接流量;
-
非降级端点的健康比例*超配因子小于100%时,降级端点承接与100%差额部分的流量;
-
优先级调度示例
下面的示例基于不同的locality分别定义了两组不同优先级的端点组;
查看代码
admin:
access_log_path: "/dev/null"
address:
socket_address:
address: 0.0.0.0
port_value: 9901
static_resources:
listeners:
- address:
socket_address:
address: 0.0.0.0
port_value: 80
name: listener_http
filter_chains:
- filters:
- name: envoy.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.config.filter.network.http_connection_manager.v2.HttpConnectionManager
codec_type: auto
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: backend
domains:
- "*"
routes:
- match:
prefix: "/"
route:
cluster: webcluster1
http_filters:
- name: envoy.router
clusters:
- name: webcluster1
connect_timeout: 0.5s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
load_assignment:
cluster_name: webcluster1
policy:
overprovisioning_factor: 140
endpoints:
- locality:
region: cn-north-1
priority: 0
lb_endpoints:
- endpoint:
address:
socket_address:
address: webservice1
port_value: 80
- locality:
region: cn-north-2
priority: 1
lb_endpoints:
- endpoint:
address:
socket_address:
address: webservice2
port_value: 80
health_checks:
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 1
http_health_check:
path: /livez流量调度样例
当健康的端点比例低于72%时,才会有部分流量转移至次优先级端点;
例如,当 50% 的 P=0 端点健康时,它们将接收 50 * 1.4 = 70% 的流量。每个优先级接收的流量的整数百分比统称为系统的“优先级负载”。(具有 2 个优先级,P=1 100% 健康):
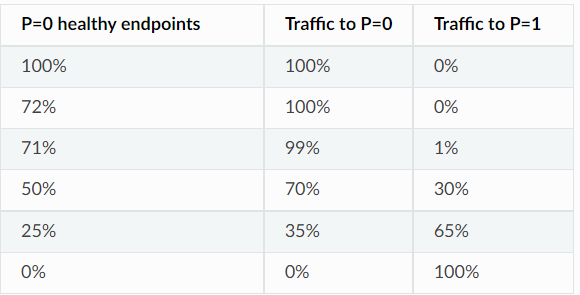
例如,对于具有{20,30}健康评分的两个组(标准化的总健康状况为50)将被标准化,并导致负载比例为40%和60%;

随着更多优先级的增加,每个级别消耗的负载等于其标准化的有效生命值,除非其上方级别的生命值总和为 100%,在这种情况下,它不会接收任何负载。
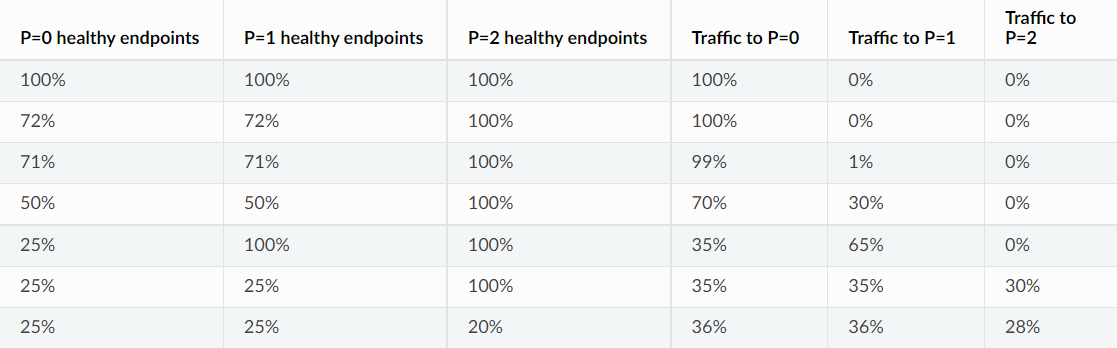
Panic阈值
恐慌阈值
- 调度期间,Envoy仅考虑上游主机列表中的可用(健康或降级)端点,但可用端点的百分比过低时,Envoy将忽略所有端点的健康状态并将流量调度给所有端点;此百分比即为Panic阈值,也称为恐慌阈值;
-
默认的Panic阈值为50%;
-
Panic阈值用于避免在流量增长时导致主机故障进入级联状态;
-
-
恐慌阈值可与优先级一同使用;
-
给定优先级中的可用端点数量下降时,Envoy会将一些流量转移至较低优先级的端点;
-
若在低优先级中找到的承载所有流量的端点,则忽略恐慌阈值;
- 否则,Envoy会在所有优先级之间分配流量,并在给定的优先级的可用性低于恐慌阈值时将该优先的流量分配至该优先级的所有主机;
-
-
恐慌阈值配置格式
# Cluster.CommonLbConfig
{
"healthy_panic_threshold": "{...}", # 百分比数值,定义恐慌阈值,默认为50%;
"zone_aware_lb_config": "{...}",
"locality_weighted_lb_config": "{...}",
"update_merge_window": "{...}",
"ignore_new_hosts_until_first_hc": "..."
}位置加权负载均衡
位置加权负载均衡概述
- 位置加权负载均衡(Locality weighted load balancing)即为特定的Locality及相关的LbEndpoints组显式赋予权重,并根据此权重比在各Locality之间分配流量;
-
所有Locality的所有Endpoint均可用时,则根据位置权重在各Locality之间进行加权轮询;
- 例如,cn-north-1和cn-north-2两个region的权重分别为1和2时,且各region内的端点均处理于健康状态,则流量分配比例为“1:2”,即一个33%,一个是67%;
- 注意:位置加权负载均衡同区域感知负载均衡互斥,因此,用户仅可在Cluster级别设置locality_weighted_lb_config或zone_aware_lb_config其中之一,以明确指定启用的负载均衡策略;
-
-
当某Locality的某些Endpoint不可用时,Envoy则按比例动态调整该Locality的权重;
-
位置加权负载均衡方式也支持为LbEndpoint配置超配因子,默认为1.4;
-
于是,一个Locality(假设为X)的有效权重计算方式如下:
- availability(L_X) = 140 * available_X_upstreams / total_X_upstreams
effective_weight(L_X) = locality_weight_X * min(100, availability(L_X))
load to L_X = effective_weight(L_X) / Σ_c(effective_weight(L_c))
- availability(L_X) = 140 * available_X_upstreams / total_X_upstreams
- 例如,假设位置X和Y分别拥有1和2的权重,则Y的健康端点比例只有50%时,其权重调整为“2×(1.4×0.5)=1.4”,于是流量分配比例变为“1:1.4”;
-
-
若同时配置了优先级和权重,负载均衡器将会以如下步骤进行调度
-
选择priority;
-
从选出的priority中选择locality;
-
从选出的locality中选择Endpoint;
-
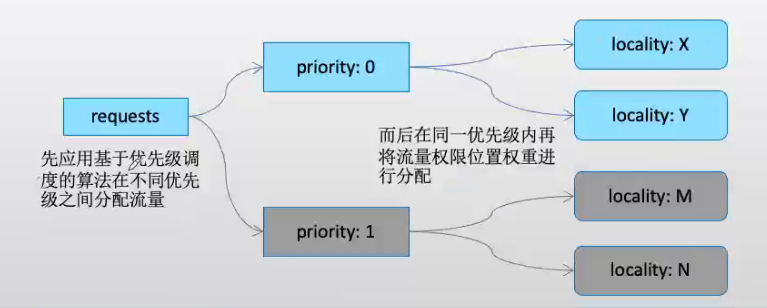
位置加权负载均衡配置格式
cluster:
- name: ...
...
common_lb_config:
locality_weighted_lb_config: {} # 启用位置加权负载均衡机制,它没有可用的子参数;
...
load_assignment:
endpoints:
locality: "{...}"
lb_endpoints": []
load_balancing_weight: "{}" # 整数值,定义当前位置或优先级的权重,最小值为1;
priority: "..."位置加权负载均衡配置示例
查看代码
admin:
access_log_path: "/dev/null"
address:
socket_address: { address: 0.0.0.0, port_value: 9901 }
static_resources:
listeners:
- address:
socket_address: { address: 0.0.0.0, port_value: 80 }
name: listener_http
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
codec_type: auto
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: backend
domains:
- "*"
routes:
- match:
prefix: "/"
route:
cluster: webcluster1
http_filters:
- name: envoy.filters.http.router
clusters:
- name: webcluster1
connect_timeout: 0.25s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
http2_protocol_options: {}
common_lb_config:
locality_weighted_lb_config: {}
load_assignment:
cluster_name: webcluster1
policy:
overprovisioning_factor: 140
endpoints:
- locality:
region: cn-north-1
priority: 0
load_balancing_weight: 10
lb_endpoints:
- endpoint:
address:
socket_address: { address: webservice1, port_value: 80 }
- locality:
region: cn-north-2
priority: 0
load_balancing_weight: 20
lb_endpoints:
- endpoint:
address:
socket_address: { address: webservice2, port_value: 80 }
health_checks:
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 1
http_health_check:
path: /livez
expected_statuses:
start: 200
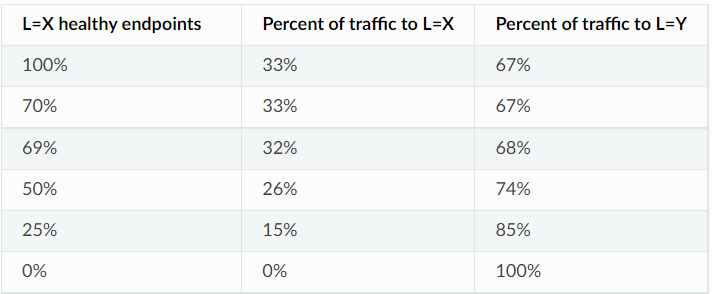
end: 399位置加权负载均衡图例
假设具有 2 个位置 X 和 Y 的简单设置,其中 X 的位置权重为 1,Y 的位置权重为 2,L=Y 100% 可用,默认过度配置因子为 1.4。
负载均衡器子集
负载均衡器子集概述
-
Envoy还支持在一个集群中基于子集实现更细粒度的流量分发
- 首先,在集群的上游主机上添加元数据(键值标签),并使用子集选择器(分类元数据)将上游主机划分为子集;
- 而后,在路由配置中指定负载均衡器可以选择的且必须具有匹配的元数据的上游主机,从而实现向特定子集的路由;
-
各子集内的主机间的负载均衡采用集群定义的策略(lb_policy);
- 配置了子集,但路由并未指定元数据或不存在与指定元数据匹配的子集时,则子集均衡均衡器为其应用“回退策略”
-
NO_FALLBACK:请求失败,类似集群中不存在任何主机;此为默认策略;
-
ANY_ENDPOINT:在所有主机间进行调度,不再考虑主机元数据;
-
DEFAULT_SUBSET:调度至默认的子集,该子集需要事先定义;
-
配置负载均衡器子集
-
子集必须预定义方可由子集负载均衡器在调度时使用
-
定义主机元数据:键值数据
-
主机的子集元数据必须要定义在“envoy.lb”过滤器下;
-
仅当使用ClusterLoadAssignments定义主机时才支持主机元数据
-
通过EDS发现的端点
-
通过load_assignment字段定义的端点
-
-
-
定义子集:基于子集选择器,目标仅支持键值列表
- 对于每个选择器,Envoy会遍历主机并检查其“envoy.lb”过滤器元数据,并为每个惟一的键值组合创建一个子集;
- 若某主机元数据可以匹配该选择器中指定每个键,则会将该主机添加至此选择器中;这同时意味着,一个主机可能同时满足多个子集选择器的适配条件,此时,该主机将同时隶属于多个子集;
-
若所有主机均未定义元数据,则不会生成任何子集;
-
-
路由元数据匹配(metadata_match)
- 使用负载均衡器子集还要求在路由条目上配置元数据匹配(metadata_match)条件,它用于在路由期间查找特定子集;
-
仅在上游集群中与metadata_match中设置的元数据匹配的子集时才能完成流量路由;
-
使用了weighted_clusters定义路由目标时,其内部的各目标集群也可定义专用的metadata_match;
-
-
不存在与路由元数据匹配的子集时,将启用后退策略;
- 使用负载均衡器子集还要求在路由条目上配置元数据匹配(metadata_match)条件,它用于在路由期间查找特定子集;
配置负载均衡器子集格式
定义主机元数据
查看代码
load_assignment:
cluster_name: webcluster1
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
protocol: TCP
address: ep1
port_value: 80
metadata:
filter_metadata:
envoy.lb:
version: '1.0'
stage: 'prod'定义子集
clusters:
- name: ...
...
lb_subset_config:
fallback_policy: "..." # 回退策略,默认为NO_FALLBACK
default_subset: "{...}" # 回退策略DEFAULT_SUBSET使用的默认子集;
subset_selectors: [] # 子集选择器
- keys: [] # 定义一个选择器,指定用于归类主机元数据的键列表;
fallback_policy: ... # 当前选择器专用的回退策略;
locality_weight_aware: "..." # 是否在将请求路由到子集时考虑端点的位置和位置权重;存在一些潜在的缺陷;
scale_locality_weight: "..." # 是否将子集与主机中的主机比率来缩放每个位置的权重;
panic_mode_any: "..." # 是否在配置回退策略且其相应的子集无法找到主机时尝试从整个集群中选择主机;
list_as_any": ..."路由元数据匹配
routes:
- name: ...
match: {...}
route: {...} # 路由目标,cluster和weighted_clusters只能使用其一;
cluster:
metadata_match: {...} # 子集负载均衡器使用的端点元数据匹配条件;若使用了weighted_clusters且内部定义了metadat_match,则元数据将被合并,且weighted_cluster中定义的值优先;过滤器名称应指定为envoy.lb;
filter_metadata: {...} # 元数据过滤器
envoy.lb: {...}
key1: value1
key2: value2
...
weighted_clusters: {...}
clusters: []
- name: ...
weight: ...
metadata_match: {...}子集选择器配置示例一
启用子集负载平衡

查看代码
---
name: cluster-name
type: EDS
eds_cluster_config:
eds_config:
path: '.../eds.conf'
connect_timeout:
seconds: 10
lb_policy: LEAST_REQUEST
lb_subset_config:
fallback_policy: DEFAULT_SUBSET
default_subset:
stage: prod
subset_selectors:
- keys:
- v
- stage
- keys:
- stage
fallback_policy: NO_FALLBACK路由配置示例
路由配置说明
- 路由时,路由上配置的元数据用于匹配和过滤出目标子集;路由匹配条件也需要使用“envoy.lb”过滤器
-
存在匹配的子集时,其将用于负载均衡的调度目标范围;
-
否则,应用回退策略;
-
路由配置示例
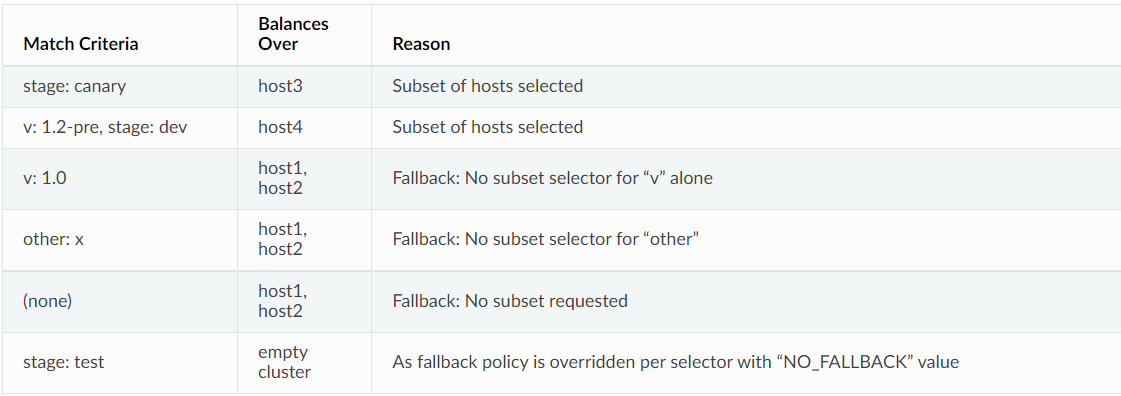
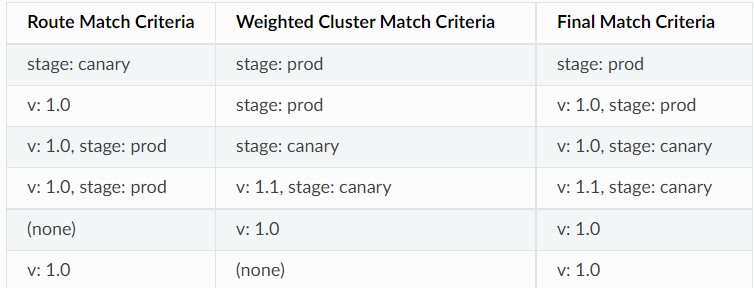
LbEndpoint带有主机元数据的 EDS :
---
endpoint:
address:
socket_address:
protocol: TCP
address: 127.0.0.1
port_value: 8888
metadata:
filter_metadata:
envoy.lb:
version: '1.0'
stage: 'prod'Route具有元数据匹配条件的 RDS :
---
match:
prefix: /
route:
cluster: cluster-name
metadata_match:
filter_metadata:
envoy.lb:
version: '1.0'
stage: 'prod'子集选择器配置示例二
元数据
clusters:
- name: webclusters
lb_policy: ROUND_ROBIN
lb_subset_config:
fallback_policy: DEFAULT_SUBSET
default_subset:
stage: prod
version: '1.0'
type: std
subset_selectors:
- keys: [stage, type]
- keys: [stage, version]
- keys: [version]
- keys: [xlarge, version]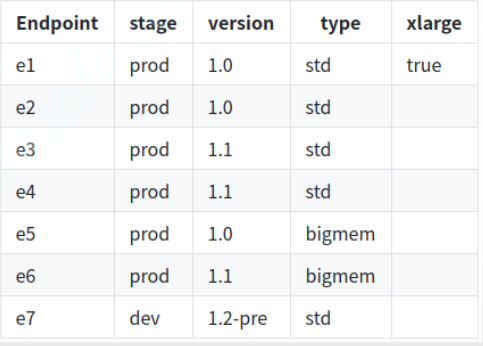
映射的子集
-
映射出十个子集
-
stage=prod, type=std (e1, e2, e3, e4)
-
stage=prod, type=bigmem (e5, e6)
-
stage=dev, type=std (e7)
-
stage=prod, version=1.0 (e1, e2, e5)
-
stage=prod, version=1.1 (e3, e4, e6)
-
stage=dev, version=1.2-pre (e7)
-
version=1.0 (e1, e2, e5)
-
version=1.1 (e3, e4, e6)
-
version=1.2-pre (e7)
-
version=1.0, xlarge=true (e1)
-
-
额外还有一个默认的子集
- stage=prod, type=std, version=1.0 (e1, e2)
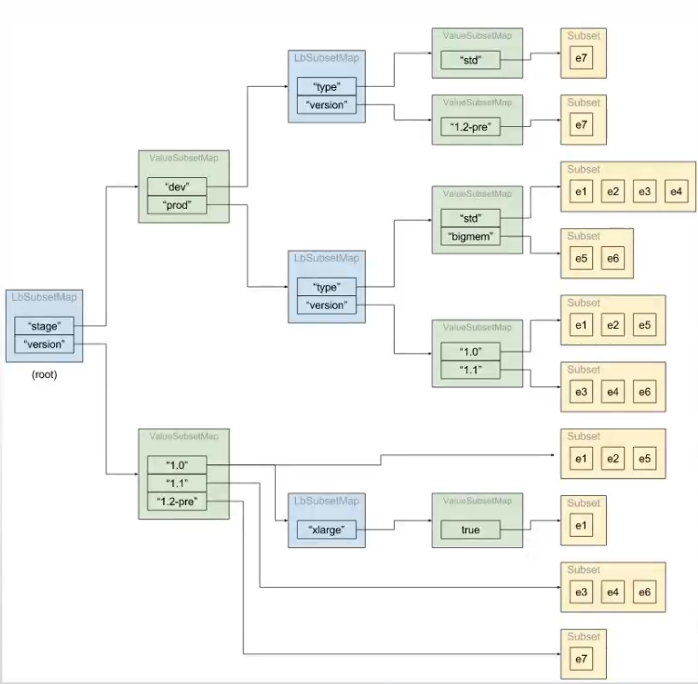
配置示例
查看代码
admin:
access_log_path: "/dev/null"
address:
socket_address: { address: 0.0.0.0, port_value: 9901 }
static_resources:
listeners:
- address:
socket_address: { address: 0.0.0.0, port_value: 80 }
name: listener_http
filter_chains:
- filters:
- name: envoy.filters.network.http_connection_manager
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.network.http_connection_manager.v3.HttpConnectionManager
codec_type: auto
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: backend
domains:
- "*"
routes:
- match:
prefix: "/"
headers:
- name: x-custom-version
exact_match: pre-release
route:
cluster: webcluster1
metadata_match:
filter_metadata:
envoy.lb:
version: "1.2-pre"
stage: "dev"
- match:
prefix: "/"
headers:
- name: x-hardware-test
exact_match: memory
route:
cluster: webcluster1
metadata_match:
filter_metadata:
envoy.lb:
type: "bigmem"
stage: "prod"
- match:
prefix: "/"
route:
weighted_clusters:
clusters:
- name: webcluster1
weight: 90
metadata_match:
filter_metadata:
envoy.lb:
version: "1.0"
- name: webcluster1
weight: 10
metadata_match:
filter_metadata:
envoy.lb:
version: "1.1"
metadata_match:
filter_metadata:
envoy.lb:
stage: "prod"
http_filters:
- name: envoy.filters.http.router
clusters:
- name: webcluster1
connect_timeout: 0.5s
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: webcluster1
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: e1
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.0"
type: "std"
xlarge: true
- endpoint:
address:
socket_address:
address: e2
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.0"
type: "std"
- endpoint:
address:
socket_address:
address: e3
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.1"
type: "std"
- endpoint:
address:
socket_address:
address: e4
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.1"
type: "std"
- endpoint:
address:
socket_address:
address: e5
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.0"
type: "bigmem"
- endpoint:
address:
socket_address:
address: e6
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "prod"
version: "1.1"
type: "bigmem"
- endpoint:
address:
socket_address:
address: e7
port_value: 80
metadata:
filter_metadata:
envoy.lb:
stage: "dev"
version: "1.2-pre"
type: "std"
lb_subset_config:
fallback_policy: DEFAULT_SUBSET
default_subset:
stage: "prod"
version: "1.0"
type: "std"
subset_selectors:
- keys: ["stage", "type"]
- keys: ["stage", "version"]
- keys: ["version"]
- keys: ["xlarge", "version"]
health_checks:
- timeout: 5s
interval: 10s
unhealthy_threshold: 2
healthy_threshold: 1
http_health_check:
path: /livez
expected_statuses:
start: 200
end: 399区域感知路由
区域感知路由术语
-
起源/上游集群:Envoy 将请求从起源集群路由到上游集群。
-
本地区域:包含原始集群和上游集群中的主机子集的同一区域。
-
区域感知路由:将请求路由到本地区域中的上游集群主机。
区域感知路由先决条件
- 在原始集群和上游集群中的主机属于不同区域的部署中,Envoy 执行区域感知路由。
- 区域感知路由(zone aware routing)用于尽可能地向上游集群中的本地区域发送流量,并大致确保将流量均衡分配至上游相关的所有端点;它依赖于以下几个先决条件;
-
始发集群(客户端)和上游集群(服务端)都未处于恐慌模式;
-
启用了区域感知路由;
-
始发集群与上游集群具有相同数量的区域;
-
上游集群具有能承载所有请求流量的主机;
-
本地区域和上游集群的关系
- 区域感知路由的目的是向上游集群中的本地区域发送尽可能多的流量,同时在所有上游主机上大致保持每秒相同数量的请求(取决于负载平衡策略)。
- 只要上游集群中每个主机的请求数量大致相同,Envoy 就会尝试将尽可能多的流量推送到本地上游区域。Envoy 是路由到本地区域还是执行跨区域路由的决定取决于本地区域中原始集群和上游集群中健康主机的百分比。关于本地区域中原始集群和上游集群之间的百分比关系,有两种情况:
-
原始集群本地区域百分比大于上游集群中的百分比。在这种情况下,我们无法将所有请求从原始集群的本地区域路由到上游集群的本地区域,因为这将导致所有上游主机之间的请求不平衡。相反,Envoy 计算可以直接路由到上游集群本地区域的请求的百分比。其余请求是跨区域路由的。根据区域的剩余容量选择特定区域(该区域将获得一些本地区域流量,并且可能具有 Envoy 可用于跨区域流量的额外容量)。
-
原始集群本地区域百分比小于上游集群中的百分比。在这种情况下,上游集群的本地区域可以从原始集群的本地区域获取所有请求,并且还有一些空间来允许来自原始集群中其他区域的流量(如果需要)。
-
- 目前,区域感知路由仅支持0优先级;
区域感知路由配置格式
common_lb_config:
zone_aware_lb_config:
"routing_enabled": "{...}", # 值类型为百分比,用于配置在多大比例的请求流量上启用区域感知路由机制,默认为100%,;
"min_cluster_size": "{...}" # 配置区域感知路由所需的最小上游集群大小,上游集群大小小于指定的值时即使配置了区域感知路由也不会执行 区域感知路由;默认值为6,可用值为64位整数;原始目标负载均衡
原始目的地
- 调度时,可用的目标上游主机范围将根据下游发出的请求连接上的元数据进行选定,并将请求调度至此范围内的某主机;
- 连接请求会被指向到将其重定向至Envoy之前的原始目标地址;换句话说,是直接转发连接到客户端连接的目标地址,即没有做负载均衡;
- 原始连接请求发往Envoy之前会被iptables的REDIRECT或TPROXY重定向,其目标地址也就会发生变动;
- 这是专用于原始目标集群(Original destination,即type参数为ORIGINAL_DST的集群)的负载均衡器;
- 请求中的新目标由负载均衡器添按需添加到集群中,而集群也会周期性地清理不再被使用的目标主机;
- 连接请求会被指向到将其重定向至Envoy之前的原始目标地址;换句话说,是直接转发连接到客户端连接的目标地址,即没有做负载均衡;
原始目标主机请求标头
- Envoy也能够基于HTTP标头x-envoy-original-dst-host获取原始目标;
-
需要注意的是,原始目标集群不与其它负载均衡策略相兼容;
原始目标过滤器状态
- 自定义扩展可以使用过滤状态对象覆盖目标地址
envoy.network.transport_socket.original_dst_address。此行为可用于隧道到中间代理而不是直接原始目标。
负载均衡配置参数
查看代码
clusters:
- name: ...
...
load_assignment: {...}
cluster_name: ...
endpoints: [] # LocalityLbEndpoints列表,每个列表项主要由位置、端点列表、权重和优先级四项组成;
- locality: {...} # 位置定义
region: ...
zone: ...
sub_zone: ...
lb_endpoints: [] # 端点列表
- endpoint: {...} # 端点定义
address: {...} # 端点地址
health_check_config: {...} # 当前端点与健康状态检查相关的配置;
load_balancing_weight: ... # 当前端点的负载均衡权重,可选;
metadata: {...} # 基于匹配的侦听器、过滤器链、路由和端点等为过滤器提供额外信息的元数据,常用用于提供服务配置或辅助负载均衡;
health_status: ... # 端点是经EDS发现时,此配置项用于管理式设定端点的健康状态,可用值有UNKOWN、HEALTHY、UNHEALTHY、DRAINING、TIMEOUT和DEGRADED;
load_balancing_weight: {...} # 权重
priority: ... # 优先级
policy: {...} # 负载均衡策略设定
drop_overloads: [] # 过载保护机制,丢弃过载流量的机制;
overprovisioning_factor: ... # 整数值,定义超配因子(百分比),默认值为140,即1.4;
endpoint_stale_after: ... # 过期时长,过期之前未收到任何新流量分配的端点将被视为过时,并标记为不健康;默认值0表示永不过时;
lb_subset_config: {...}
ring_hash_lb_config: {...}
original_dst_lb_config: {...}
least_request_lb_config: {...}
round_robin_lb_config: {...}
common_lb_config: {...}
health_panic_threshold: ... # Panic阈值,默认为50%;
zone_aware_lb_config: {...} # 区域感知路由的相关配置;
locality_weighted_lb_config: {...} # 局部权重负载均衡相关的配置;
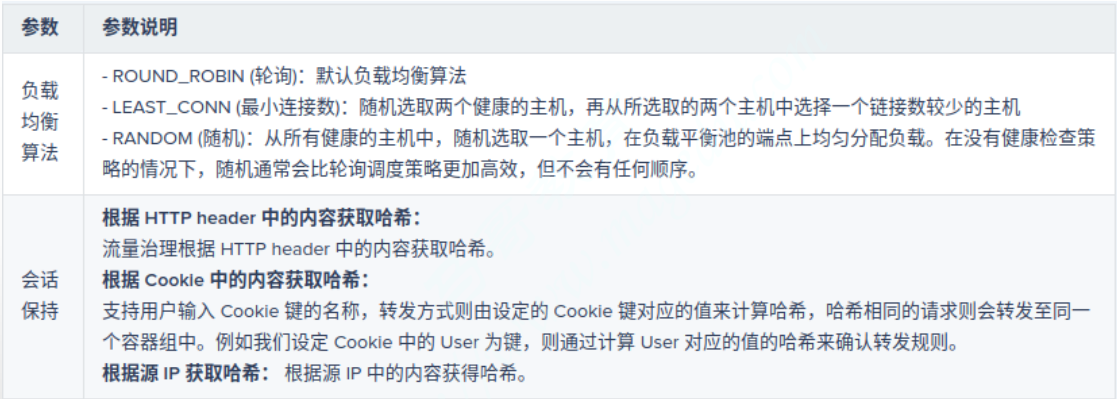
ignore_new_hosts_until_first_hc: ... # 是否在新加入的主机经历第一次健康状态检查之前不予考虑进负载均衡;负载均衡算法比较
参考文档
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/load_balancing/load_balancing
https://www.envoyproxy.io/docs/envoy/latest/api-v3/config/route/v3/route_components.proto#envoy-v3-api-msg-config-route-v3-routeaction-hashpolicy
https://www.envoyproxy.io/docs/envoy/latest/api-v3/config/cluster/v3/cluster.proto#config-cluster-v3-cluster

 浙公网安备 33010602011771号
浙公网安备 33010602011771号