kubernetes容器与pod
pod介绍
kubernetes是分布式运行于多个主机之上、负责运行及管理应用程序的云操作系统或云原生应用操作系统,它将pod作为运行应用的最小化组件和基础调度单元。pod是kubernetes资源对象模型中可由用户创建或部署的最小化应用组件,而大多数其它API资源基本上都是负载支撑和扩展pod功能的组件。
pod资源基础
现代应用容器技术用来运行单个进程,它在容器中PID名称空间中的进程号为1,可直接接收并处理信号,因而该进程终止也将导致容器终止并退出。这种设计是的容器与内部进程具有共同的生命周期,更容器发现和判定故障,也更利于对单个应用程序按需求进行扩容和缩容。但进程容器可将应用日志直接送往标准输出(STDOUT)和标准错误(STDERR),有利于让容器引擎及容器编排工具获取、存储和管理。因此一个容器中仅应运行一个进程是应用容器立身之本,这也是docker及kubernetes使用容器的标准方式。
单进程模型的应用容器显然不利于有IPC通信等需求的多个具有强耦合关系的进程间的协同,除非在组织这类容器时人为地让它们运行于同一内核之上共享IPC名称空间。于是,跨多个主机运行的容器编排系统需要能够描述这种容器间的强耦合关系,并确保它们始终能够被调度至集群中的同一节点之上,kubernetes为应对这种需求发明了Pod这一抽象概念,并将其设计为顶级API对象,是集群的一等公民。
事实上,任何人都能够配置容器运行时工具来控制各容器内各容器之间的共享级别:首先创建一个基础容器作为父容器,而后使用必要的命令选项来创建与父容器共享指定环境的新容器,并管理好这些容器的生命周期即可。kubernetes使用名为pause的容器作为pod中所有容器的父容器来支撑这种构想,因而也被称为pod的基础架构容器。
pod除了是一组共享特定名称空间的容器集合之外,其设计还隐藏了容器运行时复杂的命令行选项以及管理容器实例、存储卷及其它资源的复杂性,也隐藏了不同容器运行时彼此间的差异。从而让最终用户只需要掌握pod资源配置格式便能够创建并允许容器,且无需关心具体的运行时就能够平滑的在不同的OCI容器运行时之间迁移容器。
同一pod中,这些共享PID、IPC、Network和UTS名称空间的容器彼此间可通过IPC通信,共享使用主机名和网络接口、IP地址、端口和路由等各种网络资源,因而各容器进程能够通过lo网络接口通信且不能使用相同的网络套接字地址。尽管可以把pod类比为物理机或虚拟机,但一个pod内通常仅应该运行具有强耦合关系的容器,否则出了pause以外,只应该存在单个容器,或者只存在单个主容器和一个以上的辅助类容器,这也符合单进程应用容器设计初衷。
pod生命周期
pod相位介绍
pod对象从创建开始至终止退出之间的时间称为其生命周期,这段时间里的某个时间点,pod会处于某个特定的运行阶段或相位,以概况描述其在生命周期中所处的位置。kubernetes为pod资源严格定义了5种相位,并将特定pod对象的当前相位存储在某内部的子对象PodStatus的phase字段上,因而它总是应该处于其生命进程中以下几个相位之一。
- Pending:API Server创建pod资源对象并以存入etcd中,但它尚未被调度完成或仍处于从仓库中下载容器镜像的过程中。
- Running:pod已经被调度至某节点所有容器都已经被kubelet创建完成,且至少有一个容器处于启动、重启或运行过程中。
- Succeeded:pod中的所有容器都已经成功终止且不会在重启。
- Failed:所有容器都已经终止,但至少一个容器终止失败,即容器以非0状态码退出或已经被系统终止。
- Unknown:API Server无法正常获取到pod对象的状态信息,通常是由于其无法与所在的工作节点的kubelet通信所致。
需要注意的是,阶段仅是对pod对象生命周期运行阶段的概括性描述,而非pod或内部容器状态的总和汇总,因此pod对象的status字段的状态未必一定是可用的相位,它也有可能是pod某个错误状态,例如CrashLoopBackOff或Error等。
pod生命周期
pod资源的核心职责是运行和维护称为主容器的应用程序,在其整个生命周期之中的多种可选行为也是围绕更好地实现该功能而进行。初始化容器(init container)是常用的pod环境初始化方式,健康状态检测(starupProbe、livenessProbe和readinessProbe)为编排工具提供了检测容器运行状态的编程接口,而时间钩子(preStop和postStart)则赋予了应用容器读取来自编排工具上自定义事件的机制。尽管健康状态检测也可归为较为重要的操作环节,但这其中仅创建和运行主容器是必要任务,其它都可根据需要在创建pod对象时按需定义。
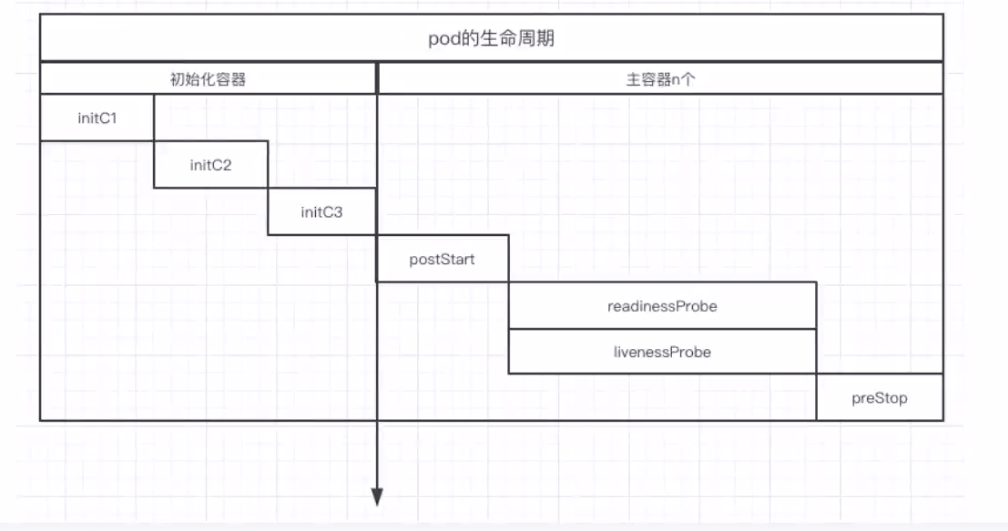
一个pod对象生命周期的运行步骤如下:
- 在启动包括初始化容器在内的任何容器之前先创建pause基础容器,它初始化pod环境并为后续加入的容器提供共享的名称空间。
- 按顺序以串行方式运行用户定义的各个初始化容器进行pod环境初始化;任何一个初始化容器运行失败都将导致pod创建失败,并按其restartPolicy的策略进行处理,默认为重启。
- 待所有初始化容器成功完成后,启动应用程序容器,多容器pod环境中,此步骤会并行启动所有应用容器,例如主容器和Sidecar容器,它们各自按其定义展开其生命周期;容器启动的那一刻会同时运行主容器上定义的PostStart钩子事件,该步骤失败将导致相关容器被重启。
- 运行容器启动健康状态监测(startupProbe),判定容器是否启动成功,该步骤失败,同样参照restartPolicy定义的策略进行处理;未定义时,默认状态为Success。
- 容器启动成功后,定期进行存活状态检测(liveness)和就绪状态检测(readiness);存活状态检测失败将导致容器重启,而就绪状态检测失败会使得该容器从其所属的Service对象的可以端点列表中删除。
- 终止pod对象时,会先运行preStop钩子事件,并在宽限期结束后终止主容器,宽限期默认为30秒。
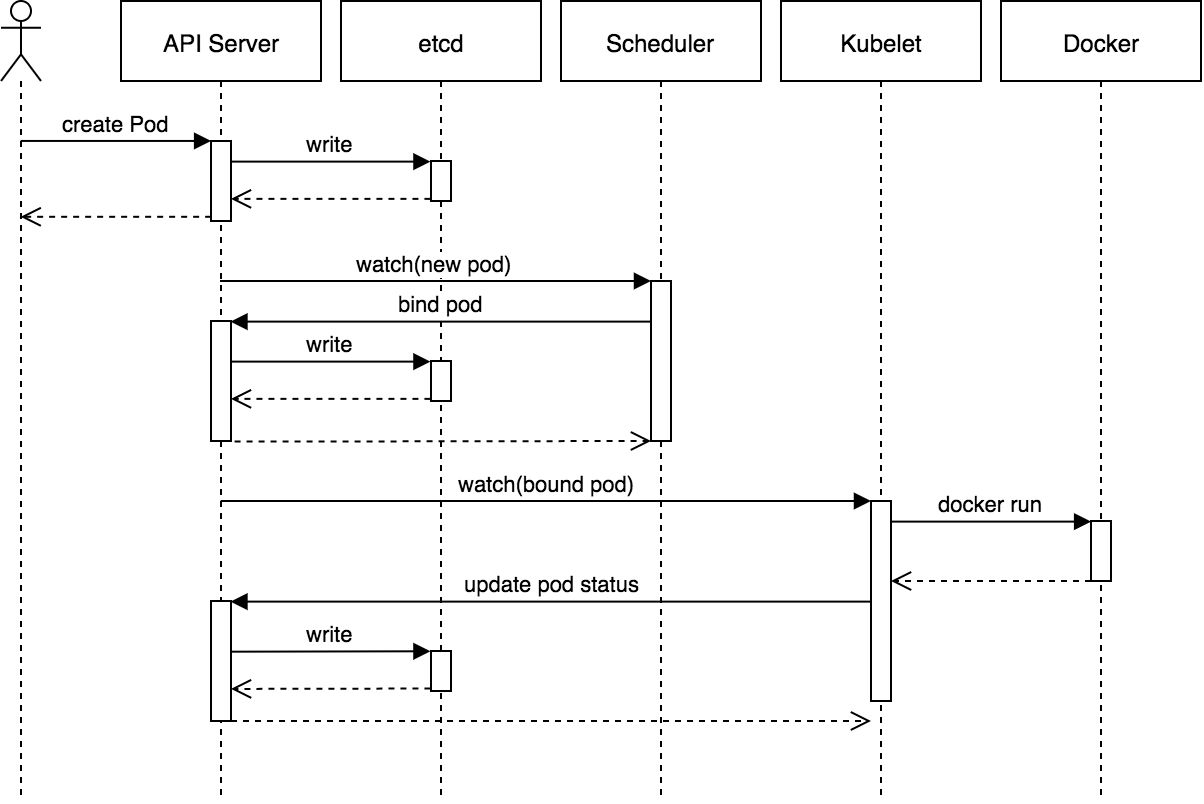
pod创建过程
- 用户通过kubectl或其它API客户端提交pod spec给API Server。
- API Server尝试着将pod对象的相关信息存入etcd中,带写入操作执行完成后,API Server会立即返回确认信息至客户端。
- Scheduler通过其watcher检测到API Server创建了新的pod对象,于是为该pod对象挑选一个工作节点并将结果信息更新至API Server。
- 调度结果信息有API Server更新至etcd存储系统,并同步给Scheduler。
- 相应节点的kubelet检测到由调度器绑定于本节点的pod后会读取其配置信息,并由本地容器运行时创建相应的容器启动pod对象后将结果回存至API Server。
- API Server将kubelet发来的pod状态信息存入etcd系统,并将确认信息发送至相应的kubelet。
- Kubelet 根据 Pod 的配置信息,使用本地的容器运行时(如 Docker、containerd 等)拉取image并创建相应的容器。Kubelet 将 Pod 的状态信息发送回 API Server。
- API Server 接收到 Kubelet 发来的 Pod 状态信息后,将其存入 etcd 系统。API Server 将确认信息发送至相应的 Kubelet,告知其状态已更新。
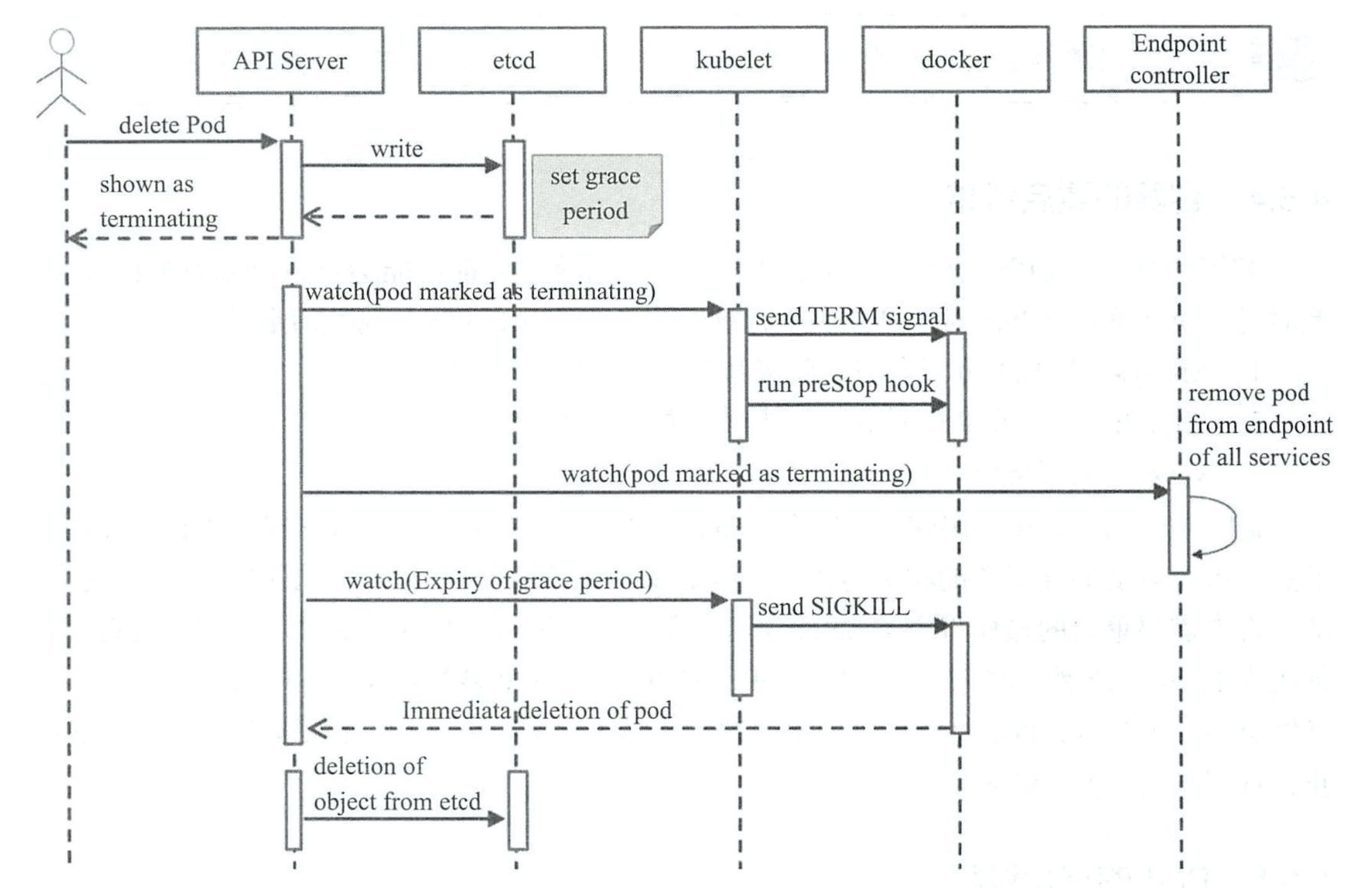
pod删除过程
kubernetes可删除宽限期确保终止操作能够以平滑方式优雅完成,从而用户也可以在正常提交删除操作后获知何时开始终止并最终完成。删除时,用户提交请求后系统即会进行强制删除操作的宽限期倒计时,并将TERM信号发送给pod对象中每个容器的主进程。宽限期倒计时结束后,这些进程将收到强制终止的KILL信号,pod对象也随机由API Server删除。如果在等待进程终止的过程中kubelet或容器管理器发生了重启,则终止操作会重新获的一个满额的删除宽限期并重新执行删除操作。
- 用户发送删除Pod对象命令。
- API服务器中pod对象会随着时间的推移而更新,在宽限期内(默认为30s),pod被视为dead。
- 将pod标记为Terminating状态。
- kubelet在监控到pod对象转为Terminating状态的同时启动pod关闭过程。
- 端点控制器监控到pod对象的关闭行为时将从所有匹配到此端点的service资源的端点列表中移除。
- 如果当前pod对象定义了preStop钩子句柄,在其标记为Terminating后即会以同步方式启动执行;如果宽限期结束后,preStop仍未执行完,则重新执行第二步并额外获取一个时长为2秒的小宽限期。
- pod对象中的容器进程收到TERM信号。
- 宽限期结束后,若存在任何一个仍在运行的进程,pod对象即会收到SIGKILL信号。
- kubelet请求API Server将此pod资源的宽限期设置为0从而完成删除操作,它变得对用户不可见。
默认情况下,所有删除操作的宽限期都是30秒,不过kubectl delete命令可以使用--grace-period=<seconds>选项自定义其时长,使用0值则表示直接强制删除指定的资源,不过此时需要同时为命令使用--force选项。
pod应用
pod配置格式
apiVersion: v1
kind: Pod
metadata:
name: ... #pod标识名称,在名称空间中必须唯一
namespace: ... #该pod所属的名称空间,省略时使用默认名称空间。例如default
spec:
containers: #定义容器,它是一个列表对象,可包括多个容器的定义,至少得有一个
- name: ... #容器名称,必须字段,在当前pod中必须唯一
image: ... #创建容器时使用的镜像
imagePullPolicy: ... #容器镜像下载策略
env: #设置环境变量
- name: HOST #变量名称
value: "127.0.0.1" #变量值
- name: PORT
value: "8080"kubernetes系统支持用户自定义容器镜像文件的获取策略,例如在网络资源较为紧张时可以禁止从仓库获取镜像文件,或者不允许使用工作节点本地镜像。容器的imagePullPolicy字段用于为其指定镜像获取策略,,它的可用值包括如以下几个。
- Always:每次启动pod时都要从指定的仓库下载镜像。
- IfNotPresent:仅本地镜像缺失时方才从目标仓库下载镜像。
- Never:禁止从仓库下载镜像,仅使用本地镜像
对于标签为latest的镜像文件,其默认的镜像获取策略为Always,其他标签的镜像默认策略为IfNotPresent。需要注意的是,从私有仓库中下载镜像时通常需要事先到Registry服务器认证后才能进行,认证过程要么需要在相关节点上交互式执行docker login命令,要么将认证信息定义为专有的Secret资源,并配置Pod通过imagePullSecretes字段调用此认证信息完成。
删除pod对象则使用kubectl delete命令
- 命令式命令:kubectl delete pods/name
- 命令式对象配置:kubectl delete -f filename
若删除后pod一直处于Terminating状态,则可在一次执行删除命令,并同时使用--force 和--grace-period=0选项进行强制删除。
获取pod状态
- kubectl describe:显示资源的详细,包括运行状态、事件等信息,但不同的资源类型输出内容不尽相同。
- kubectl logs:查看pod对象中容器输出到控制台的日志信息。当pod中运行多个容器时,需要使用选项-c指定容器名称。
- kubectl exec:在pod对象某容器内运行指定的程序其功能类似于docker exec命令,可用于了解容器个方面的相关信息或执行必要的设定操作等。
打印pod状态
# kubectl get pods/kubernetes-dashboard-688994654d-9cwwz -n kubernetes-dashboard -o yamlapiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2021-11-18T12:34:47Z"
generateName: kubernetes-dashboard-688994654d-
labels:
k8s-app: kubernetes-dashboard
pod-template-hash: 688994654d
name: kubernetes-dashboard-688994654d-9cwwz
namespace: kubernetes-dashboard
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: kubernetes-dashboard-688994654d
uid: aec5177d-b702-4773-826c-0675a5f93095
resourceVersion: "1459990"
uid: de166f1c-4034-4877-9598-05ee67b095f2
spec:
containers:
- args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
image: 192.168.174.120/baseimages/dashboard:v2.4.0
imagePullPolicy: Always
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 8443
scheme: HTTPS
initialDelaySeconds: 30
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
name: kubernetes-dashboard
ports:
- containerPort: 8443
protocol: TCP
resources: {}
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsGroup: 2001
runAsUser: 1001
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /certs
name: kubernetes-dashboard-certs
- mountPath: /tmp
name: tmp-volume
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-79sqk
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: 192.168.174.106
nodeSelector:
kubernetes.io/os: linux
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kubernetes-dashboard
serviceAccountName: kubernetes-dashboard
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: kubernetes-dashboard-certs
secret:
defaultMode: 420
secretName: kubernetes-dashboard-certs
- emptyDir: {}
name: tmp-volume
- name: kube-api-access-79sqk
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2021-11-18T12:34:47Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2022-05-16T02:56:00Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2022-05-16T02:56:00Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2021-11-18T12:34:47Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: docker://3d9793c5f29e9c17a16b8544cc9c6b71b67bf089b949b9396cf2cad33cabaa03
image: 192.168.174.120/baseimages/dashboard:v2.4.0
imageID: docker-pullable://192.168.174.120/baseimages/dashboard@sha256:2d2ac5c357a97715ee42b2186fda39527b826fdd7df9f7ade56b9328efc92041
lastState:
terminated:
containerID: docker://2fe046033be96b71205fb31f892761ecb2e7419bbd6863153fd6c248d07d474e
exitCode: 2
finishedAt: "2022-05-16T02:55:51Z"
reason: Error
startedAt: "2022-05-16T01:45:07Z"
name: kubernetes-dashboard
ready: true #是否已经就绪
restartCount: 207 #重启次数
started: true
state: #当前状态
running:
startedAt: "2022-05-16T02:56:00Z" #启动时间
hostIP: 192.168.174.106 #节点IP
phase: Running #pod当前相位
podIP: 10.200.154.253 #pod的主IP地址
podIPs: #pod上的所有IP地址
- ip: 10.200.154.253
qosClass: BestEffort #Qos类别
startTime: "2021-11-18T12:34:47Z"conditions字段是一个称为PodConditions的数组,它记录了pod所处的境况或者条件,其中的每个数组元素都可能由以下6个字段组成
- lastProbeTime:上次进行pod探测时的时间
- lastTransitionTime:pod上次发生状态转换的时间戳
- message:上次状态转换相关的易读格式信息
- reason:上次状态转换原因,用驼峰格式的单个单词表达
- status:是否为状态信息,可取值为True、False和Unknown
- type:境况的类型或名称,有4个固定值:PodScheduled表示已经与节点绑定;Ready表示已经就绪,可服务客户端请求;Initialized表示所有的初始化容器都已经成功启动;ContainersReady则表示所有容器均以就绪
containerStatuses字段描述了pod中个容器的相关状态信息,包括容器ID、镜像和镜像ID、上一次的状态、名称、启动与否、就绪与否、重启次数和状态等。随着系统运行该pod对象的状态可能会因各种原因发生变动,例如程序自身的bug导致的故障、工作节点资源耗尽引起的驱逐等,用户可根据需要随时请求查看这些信息,甚至将其纳入监控系统中进行实时监控和告警。
查看容器日志
# kubectl logs kubernetes-dashboard-688994654d-9cwwz -n kubernetes-dashboard 2022/05/16 02:56:01 Using namespace: kubernetes-dashboard
2022/05/16 02:56:01 Using in-cluster config to connect to apiserver
2022/05/16 02:56:01 Starting overwatch
2022/05/16 02:56:01 Using secret token for csrf signing
2022/05/16 02:56:01 Initializing csrf token from kubernetes-dashboard-csrf secret
2022/05/16 02:56:01 Successful initial request to the apiserver, version: v1.21.6
2022/05/16 02:56:01 Generating JWE encryption key
2022/05/16 02:56:01 New synchronizer has been registered: kubernetes-dashboard-key-holder-kubernetes-dashboard. Starting
2022/05/16 02:56:01 Starting secret synchronizer for kubernetes-dashboard-key-holder in namespace kubernetes-dashboard
2022/05/16 02:56:01 Initializing JWE encryption key from synchronized object
2022/05/16 02:56:01 Creating in-cluster Sidecar client
2022/05/16 02:56:01 Successful request to sidecar
2022/05/16 02:56:02 Auto-generating certificates
2022/05/16 02:56:02 Successfully created certificates
2022/05/16 02:56:02 Serving securely on HTTPS port: 8443
2022/05/16 03:27:43 Metric client health check failed: an error on the server ("unknown") has prevented the request from succeeding (get services dashboard-metrics-scraper). Retrying in 30 seconds.
2022/05/16 03:28:13 Successful request to sidecar
2022/05/16 05:49:28 Metric client health check failed: the server is currently unable to handle the request (get services dashboard-metrics-scraper). Retrying in 30 seconds.
2022/05/16 05:49:58 Successful request to sidecar进入pod
~# kubectl -it exec wgs-tomcat-app1-deployment-7df6b45b59-hj4fw -n wgs -- /bin/sh
/usr/local/apache-tomcat-8.5.73 # 在pod执行命令
~# kubectl -it exec wgs-tomcat-app1-deployment-7df6b45b59-hj4fw -n wgs -- ps aux
PID USER TIME COMMAND
1 root 0:04 /usr/local/jdk/jre/bin/java -Djava.util.logging.config.fil
73 root 0:00 ps aux暴露容器服务
端口映射
- containerPort:必选字段,指定在pod对象的IP地址上暴露的容器端口,有效范围(0,65536);使用时,需要指定为容器应用程序监听的端口。
- name:当前端口的名称标识,必须符合IANA_SVC_NAME规范且在当前pod内要具有唯一性,此端口可以被Server资源按名调用。
- protocol:端口相关的协议,其值仅支持TCP、SCTP或UDP三者之一,默认为TCP。
- hostPort:主机端口,它将接收到的请求通过NAT机制转发至由container-port字段指定的容器端口。
- hostIP:主机端口要绑定的主机IP,默认为主机之上所有可用的IP地址;该字段通常使用默认值。
主机端口配置
apiVersion: v1
kind: Pod
metadata:
name: pod-using-hostport
namespace: default
spec:
containers:
- name: demo
image: 192.168.174.120/baseimages/tomcat-app1:v1.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
hostPort: 10080节点网络配置
apiVersion: v1
kind: Pod
metadata:
name: pod-using-hostnetwork
namespace: default
spec:
containers:
- name: demo
image: 192.168.174.120/baseimages/tomcat-app1:v1.0
imagePullPolicy: IfNotPresent
hostNetwork: true容器设计模式
单容器模式
单容器模式是指将应用程序封装为应用容器运行。该模式需要遵循简单和单一原则,每个容器仅承载一种工作负载。
单节点多容器模式
单节点多容器模式是指扩容器的设计模式,其目的是在单个主机之上同时运行多个共生关系的容器,因而容器管理系统需要将它们作为一个原子单位进行同一调度。kubernetes编排系统设计的pod概念就是这个设计模式的实现之一。
若多个容器间存在强耦合关系,它们具有完全相同的生命周期,或者必须运行于同一节点之上时,通常应该将它们置于同一个pod中,较常见的情况是为主容器并行运行一个助理管理进程。单节点多容器模式的常见实现有Sidercar(边车)、适配器(Adapter)、大使(Ambassador)、初始化(Initializer)容器模式等。
Sidecar模式
Sidecar模式是多容器系统设计的最常用模式,它由一个主应用程序以及一个辅助容器(Sidecar)组成,该辅助容器用于为主容器提供辅助服务以增强主容器功能,是主应用程序必不可少的一部分,但却不一定非得存在于应用程序本身内部。
最常见的sidecar容器时日志记录服务、数据同步服务、配置服务和代理服务等。对于主容器应用的每个实例,Sidecar的实例都被部署并托管在它旁边,主容器与sidecar容器具有相同的生命周期,毕竟主容器运行时,运行sidecar容器并无实际意义,尽管完全可以将sidecar容器集成到主容器内部,但是使用不同的容器来运行处理不同功能还是存在较多优势;
- 辅助应用的运行时环境和编译语言与主应用程序无关,因而无需为每种为每种编程语言分别开发一个辅助工具;
- 二者可基于IPC、lo接口或共享存储进行数据交换,不存在明显的通信延迟;
- 容器镜像时发布的基本单位,将主应用与辅助应用划分为两个容器使得可由不同团队开发和维护,从而变得方便及高效,单独测试及集成测试也变得可能;
- 容器限制了故障边界,使得系统整体可以优雅降级,例如sidecar容器异常时主容器仍可提供服务;
- 容器时部署的基本单元,每个功能模块均可独立部署及回滚。
大使模式
云原生应用程序需要诸如断路、路由、计量和监视等功能,以及具有进行网络相关的配置更新的功能,但更新旧有的应用程序或现有代码库以添加这些功能可能很困难,甚至于难于实现,进程外代理便成了一种有效地解决方案。大使模式本质上就是这么一类代理程序,它代表主容器发送网络请求至外部环境中,因此可以将其视作与客户端位于同一位置的外交官。
大使模式的最佳用例之一是提供对数据库的访问。实践中,开发环境、测试环境和生成环境中的主应用程序可能需要分别连接到不同的数据库服务。尽管使用环境变量可配置主容器应用完成此类功能,但更好的方案是让应用程序始终通过localhost连接至大使容器,而如何正确连接到目标数据库的责任由大使容器完成。另外,需要以智能客户端连接至外部的分布式数据库时,也可以使用大使来扮演此类的客户端程序。
代理会增加网络开销并导致一定的延迟,因而对延迟敏感的应用该仔细权衡模式的得失。
适配器模式
适配器模式用于为主应用提供一致的接口,实现了模块重用,支持标准化和规范化主容器应用程序的输出以便于外部服务进行聚合。相比较来说,大使模式为内部容器提供了简化统一的外部服务视图,适配器模式则刚好反过来,它通过标准化容器的输出和接口,为外界展示了一个简化的应用视图。
一个实际的例子就是借助于适配器容器确保系统内的所有容器提供统一的监控接口。如今应用通过各种各样的方式暴露不尽相同的指标格式,而通过一个固定的监控接口暴露指标将有助于分布式应用的监控工具收集、聚合及可视化等功能。尽管目前一些监控解决方案支持与多种类型的后端通信,但这种在监控系统内部置入与特定应用程序相关的代码却有违代码解耦及整洁性。
初始化容器
初始化容器模式负载以不同于主容器的生命周期来完成那些必要的初始化任务,包括在文件系统上设置必要的特权权限、数据库模式设置或为主应用程序提供初始数据等。但这些初始化逻辑无法包含在应用程序的镜像文件中,或者处于安全原因,应用程序镜像没有执行初始化活动的权限,在或者用户期望能延迟应用程序启动,知道外部环境满足其启动条件为止。
初始化容器将pod内部的容器分成了两组:初始化容器和应用程序容器,初始容器可以不止一个,但它们需要以特定的顺序串行运行,并需要在启动应用程序容器之前成功终止。不过,多个应用程序容器一般需要并行启动和运行。
多节点模式
多节点模式就是将分布式应用的每个任务实例分布于多个节点,分别以单节点模式运行,并以更高级的形式进行彼此通信和协同的更高级模式。典型的分布式应用程序具有许多以协调方式执行任务,这些任务可能依赖于外部的协调机制来确保各任务实例互不冲突,以避免导致争抢共享资源或者意外干扰其它实例正在执行的工作。
领导者选举模式
领导者选举的思想是,若一个分布式应用同时运行某一任务的多个无差别、完全对等实例以提高服务可用性级别,但这种实例存在可写入的共享资源,或者支持将复杂计算分割为多个并行执行的任务实例并需要对结果进行聚合时,就需要选举一个实例来充当领导者以对其它下属任务实例的操作进行协调。运行相同的代码的每个每个实例都可能被选举为领导者,因而必须确保选举流程正确进行,以防止两个或更多实例同时接管领导者角色。一个系统也可能并行运行多个选举流程,例如每个数据分片子集需要分别选择各自的领导者等。
工作队列模式
分布式应用程序的各组件存在大量的事件传递需求,当某应用组件需要将信息广播至大量订阅者时,可能需要与多个独立开发的,可能使用了不同平台、编程语言和通信协议的应用程序或服务通信,并且无须订阅者实时响应地通信,此时工作队列模式将是较为适用的解决方案。它具有解耦子系统、提高伸缩能力和可靠性、支持延迟事件处理、简化异构组件间的集成等优势。
类型领导者选举模式,工作队列模式也受益于容器技术。工作队列已被深入研究并且有许多框架进行了实现,但这些框架同样受限于编程语言或存在实现不完整的问题。容器实现的接口支持开发人员便捷地创建出一个通用队列的容器,而后创建另一个支持接收输入数据并将其转换为目标数据格式的容器作为可重用框架容器,以便能够让应用程序轻松使用工作队列。
分散/聚集
分散/聚集模式与工作队列模式非常相似,它同样将大型任务拆分为较小的任务,区别是容器会立即将响应返回给用户,一个很好的例子是MapReduce算法。该模式需要两类组件:一个称为根节点或父节点的组件,将来自客户端的请求切分成多个小任务并分散到多个节点并行计算;另一类称为计算节点或叶子节点,每个节点负责运行一部分任务分片并返回结果数据,根节点收集这些结果数据并聚合为有意义的数据返回给客户端。开发这类分布式系统需要请求扇出、结果聚合以及客户端交互等大量的模板代码,但大部分都比较通用。因而要实现该模式,我们需要分别将两类组件各自构建为容器即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号