Prometheus之Alertmanager邮件报警配置
一 Alertmanager配置
1.1 编辑Alertmanager配置文件
点击查看代码
root@node-02:~# cat /usr/local/alertmanager/alertmanager.yml
global:
smtp_from: '1304995320@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1304995320@qq.com'
smtp_auth_password: 'xxxxxxxxx'
smtp_hello: '@qq.com'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5s
repeat_interval: 1m
receiver: 'web.hook'
receivers:
- name: 'web.hook'
email_configs:
- to: '1304995320@qq.com'
inhibit_rules:
- source_match:
alertname: InstanceDown
severity: 'critical'
target_match:
alertname: InstanceDown
severity: 'critical'
equal: ['alertname', 'dev', 'instance']1.2 重启Alertmanager服务
root@node-02:~# systemctl restart alertmanager
二 Prometheus报警设置
2.1 修改Prometheus配置文件
root@prometheus-01:~# cat /usr/local/prometheus/prometheus.yml
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.174.104:9093
rule_files:
- "rules/*.yaml"
"alert_rules/*.yaml"
2.2 创建告警规则文件
root@prometheus-01:~# cat /usr/local/prometheus/alert_rules/instance_down.yaml
groups:
- name: ALLInstances
rules:
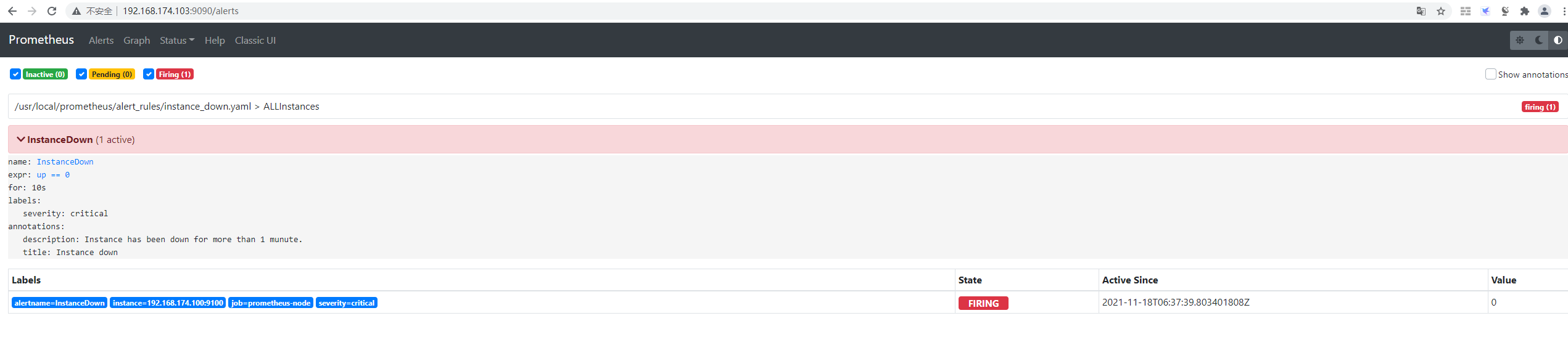
- alert: InstanceDown
expr: up == 0
for: 1m
annotations:
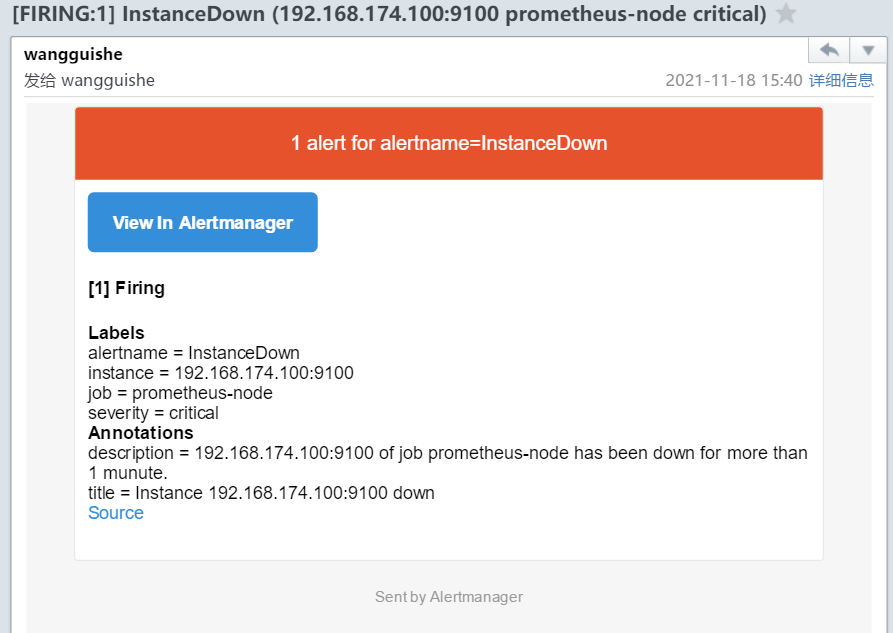
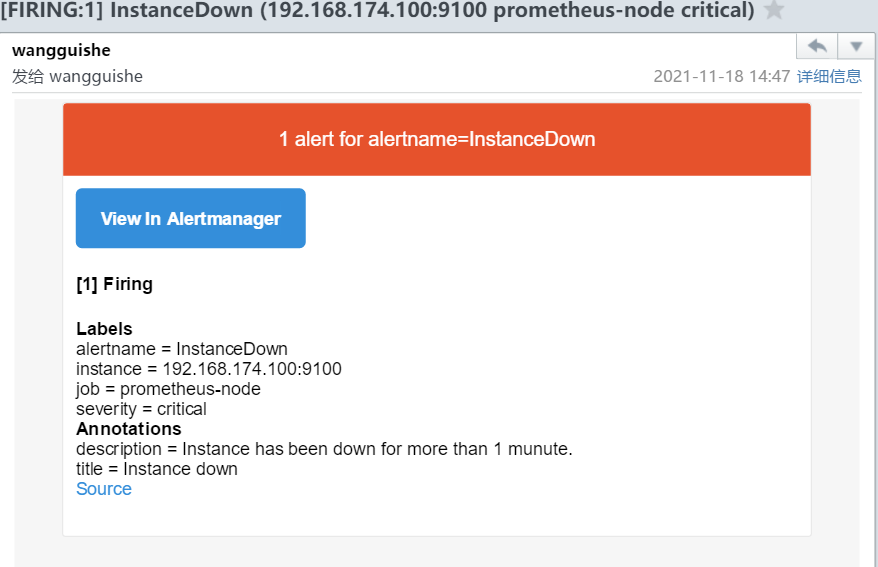
title: 'Instance down'
description: 'Instance has been down for more than 1 munute.'
labels:
severity: 'critical'
2.3 验证规则
root@prometheus-01:~# /usr/local/prometheus/promtool check rules /usr/local/prometheus/alert_rules/instance_down.yaml Checking /usr/local/prometheus/alert_rules/instance_down.yaml SUCCESS: 1 rules found
2.4 重启Prometheus服务
root@prometheus-01:~# systemctl restart prometheus.service
2.5 停止node_exporter服务
root@k8s-master-01:~# systemctl stop node-exporter
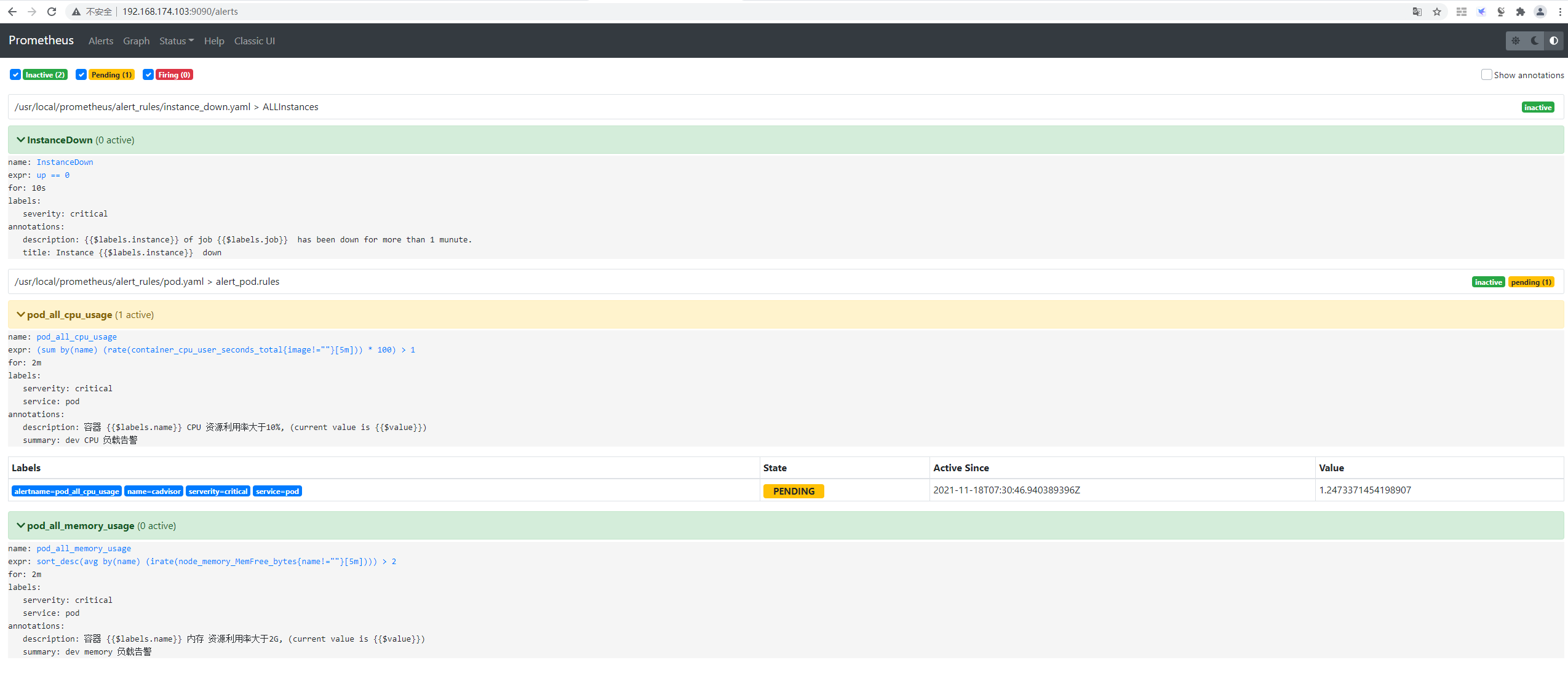
2.6 Prometheus web界面
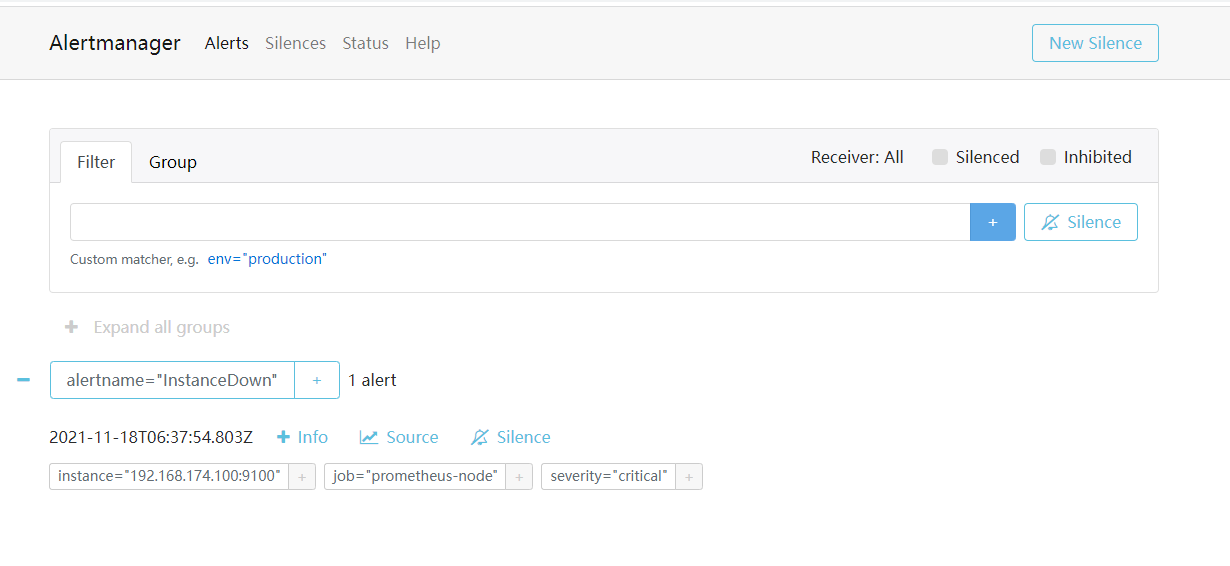
2.7 验证Alertmanager界面
2.8 验证邮件告警信息
三 告警模板
3.1 修改Prometheus规则文件
root@prometheus-01:~# cat /usr/local/prometheus/alert_rules/pod.yaml groups: - name: alert_pod.rules rules: - alert: pod_all_cpu_usage expr: (sum by(name)(rate(container_cpu_user_seconds_total{image!=""}[5m]))* 100) > 1 for: 2m labels: serverity: critical service: pod annotations: description: 容器 {{$labels.name}} CPU 资源利用率大于10%, (current value is {{$value}}) summary: dev CPU 负载告警- alert: pod_all_memory_usage expr: sort_desc(avg by(name)(irate(node_memory_MemFree_bytes{name!=""}[5m]))) > 2 #内存大于2G for: 2m labels: serverity: critical service: pod annotations: description: 容器 {{$labels.name}} 内存 资源利用率大于2G, (current value is {{$value}}) summary: dev memory 负载告警
3.2 重启Prometheus服务
root@prometheus-01:~# systemctl restart prometheus.service
3.3 Prometheus web界面验证
3.4 查看邮件告警信息