keepalived负载高可用原理
VRRP协议
虚拟路由冗余协议(virtual router redundancy protocol,简称VRRP),是由IETF提出的解决局域网中配置静态网关出现单点失效现象的路由协议,1998年已推出正式的RFC2338协议标准,VRRP广泛应用在边缘网络中,它的设计目标是支持特定情况下IP数据流量失败转移不会引起混乱,允许主机使用单路由器,以及及时在实际第一跳路由器使用失败的情形下仍能够维护路由器间的连通性。
VRRP术语
- 虚拟路由器:Virtual Router
- 虚拟路由器标识:VRID唯一标识虚拟路由器
- VIP:Virtual IP
- master:主设备
- backup:备用设备
- priority:优先级
Keepalived是什么?
keepalived软件起初是专门为LVS负载均衡软件而设计,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能,因此,keepalived除了能够管理LVS软件ipvsadm外,还可以作为其它服务(例如:Nginx、HAProxy、MySQL等)的高可用解决方案软件
keepalived软件主要使用过VRRP协议实心高可用功能;VRRP是Virtual Route Redundancy Protocol(虚拟路由冗余协议)的缩写,VRRP出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行
所以,Keepalived一方面具有配置管理LVS的功能,同时还具有LVS下面节点进行健康检查的功能,另一方面也可以实现系统网络服务的高可用功能
Keepalived官网 http://www.keepalived.org
Keepalived服务的三个重要功能
1)管理LVS负载均衡软件ipvsadm
2)实现LVS集群节点的健康检查
3)作为系统网络服务的高可用性
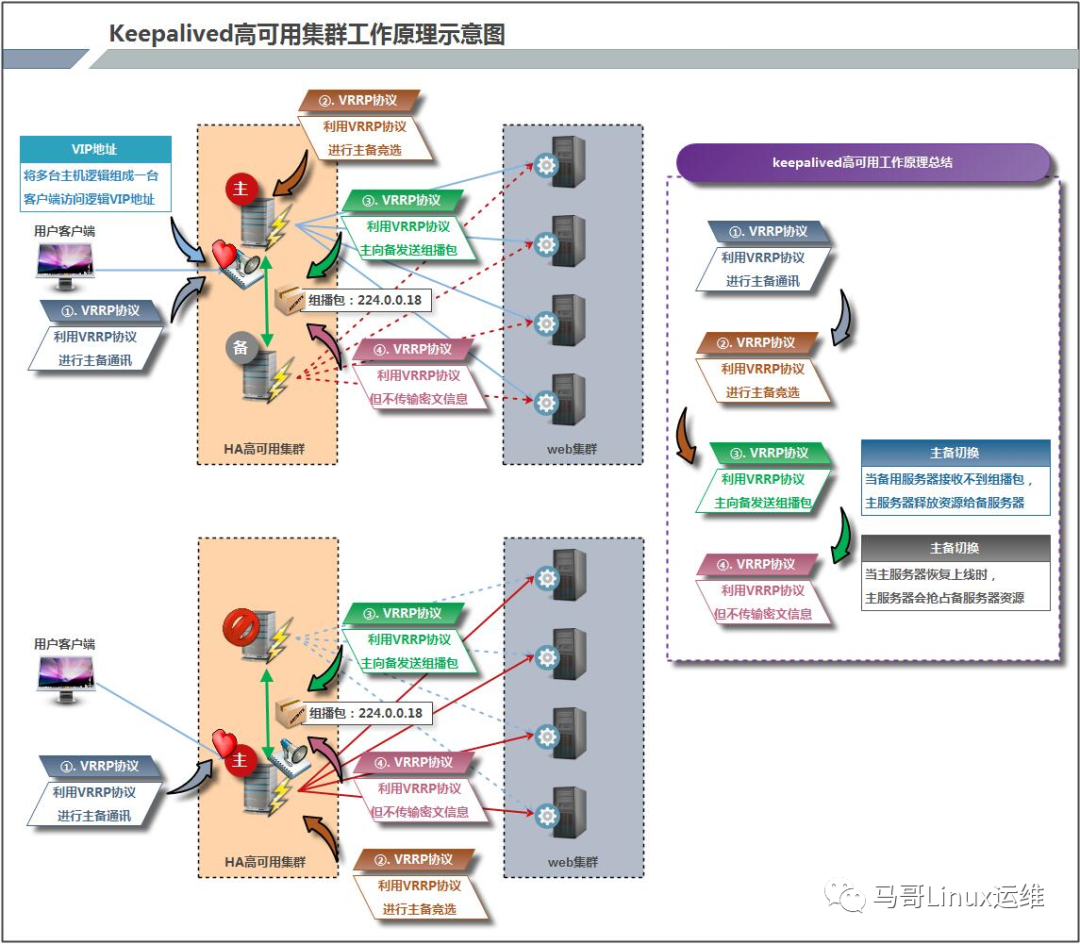
Keepalived工作原理
Keepalived运行机制示意图
工作机制
Keepalived通过VRRP协议来竞争实现虚拟路由的功能,所有的协议报文都是通过IP多播(multicast)包发送(多播地址224.0.0.18)每个发送的多播数据包都是从多播地址发送;虚拟路由器由VRID(范围0-255)和一组IP地址组成,对外表现为一个周知的MAC地址:00-00-5E-00-01-{VRID}.所以在一个虚拟路由器中,不管谁是MASTER,对外都是相同的MAC和IP(称之为VIP)。客户端主机并不需要因为MASTER的改变而修改自己的路由配置,对他们来说,这一切都是透明的。
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP多播包,这里说的MASTER发送多播包就是指的是上面所说的由VRRP协议224.0.0.18地址所发出的多播包,发多播包是为了告诉Backup节点自己还活着,BACKUP就不会抢占MASTER,除非它的优先级(priority更高)。
工作原理:
Keepalived高可用对之间是通过VRRP通信的,因此,我们从 VRRP开始了解起:
1) VRRP,全称 Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议,VRRP的出现是为了解决静态路由的单点故障。
2) VRRP是通过一种竟选协议机制来将路由任务交给某台 VRRP路由器的。
3) VRRP用 IP多播的方式(默认多播地址(224.0_0.18))实现高可用对之间通信。
4) 工作时主节点发包,备节点接包,当备节点接收不到主节点发的数据包的时候,就启动接管程序接管主节点的开源。备节点可以有多个,通过优先级竞选,但一般 Keepalived系统运维工作中都是一对。
5) VRRP使用了加密协议加密数据,但Keepalived官方目前还是推荐用明文的方式配置认证类型和密码。
介绍完 VRRP,接下来我再介绍一下 Keepalived服务的工作原理:
Keepalived高可用对之间是通过 VRRP进行通信的, VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主挂了的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务。
在 Keepalived服务对之间,只有作为主的服务器会一直发送 VRRP广播包,告诉备它还活着,此时备不会枪占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性.接管速度最快可以小于1秒。
Keepalived高可用故障切换转移原理
Keepalived高可用服务之间的故障切换转移,还是通过VRRP(Vritual Route Redundancy Protocol,虚拟路由冗余协议)来实现的
在Keepalived服务正常工作时,主Master节点会不断向备节点发送心跳消息(多播的方式),用来告诉备用节点自己还活着,当主Master节点发送故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主Master的心跳消息了,于是调用自身的接管程序,接管主Master节点的IP资源及服务。而当主Master恢复时,备Backup节点默认又会主动释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
Keepalived双主模式
Keepalived不抢占机制(nopreempt)
当Master出现问题后,Backup会竞选为新的Master,那么之前的Master如果故障恢复后,是继续成为Master还是变成Backup呢?默认情况下,如果没设置不抢占,那么之前的Master起来后还是会继续抢占成为Master,也就是说,整个过程需要发生两次切换;主机诶单出故障会发送Master —> Backup,主节点恢复会发送 Backup —>Master;这样对业务频繁的切换是不能容忍的,因此我们希望Master起来后成为Backup,所以要设置不抢占,Keepalived里面提供了 nopreempt 这个配置只能用在状态为Backup的机器上,但是我们明明希望的是Master不进行抢占,那没办法,Master的状态也得设置为Backup,也就是说两台负载均衡器都要讲state状态设置为Backup;那么谁是Master?就要通过优先级priority的高低来决定了,优先级搞得成为Master,反之.
Keepalived脑裂
在高可用HA系统中,当联系2个节点的“心跳线”断开时,本来为一整体,一个VRRP协议组,动作协调的HA系统,就分裂为两个独立的个体。由于相互失去了联系,都以为对方出了故障;两个节点的HA软件像“连体人”一样,有共同的身体却拥有两个脑袋,争抢“共享资源”身体,争抢服务器里的应用服务,就会发送严重后果,或者共享资源被瓜分,两边服务都起不来或者都起来都为Master,假如两端服务器发生了脑裂现象就会成为各自的Master,会同时读写“共享存储”,导致数据损坏(常见的如数据库轮询着的联机日志出错)
对付HA系统“裂脑”的对策,目前达成共识的的大概有以下几条:
1)添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率;
2)启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
3)设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
脑裂产生的原因
一般来说,裂脑的发生,有以下几种原因:
1) 高可用服务器对之间心跳线链路发生故障,导致无法正常通信
2)因心跳线坏了(包括断了,老化)
3)因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
4)因心跳线间连接的设备故障(网卡及交换机)
5)因仲裁的机器出问题(采用仲裁的方案)
6)高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输
7)高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
8)其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等
提示: Keepalived配置里同一 VRRP实例如果 virtual_router_id两端参数配置不一致也会导致裂脑问题发生
脑裂常见的解决方案
在实际生产环境中,我们可以从以下几个方面来防止裂脑问题的发生:
1) 同时使用串行电缆和以太网电缆连接,同时用两条心跳线路,这样一条线路坏了,另一个还是好的,依然能传送心跳消息。
2)当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源。
3) 做好对裂脑的监控报警(如邮件及手机短信等或值班).在问题发生时人为第一时间介入仲裁,降低损失。例如,百度的监控报警短倍就有上行和下行的区别。报警消息发送到管理员手机上,管理员可以通过手机回复对应数字或简单的字符串操作返回给服务器.让服务器根据指令自动处理相应故障,这样解决故障的时间更短.
当然,在实施高可用方案时,要根据业务实际需求确定是否能容忍这样的损失。对于一般的网站常规业务.这个损失是可容忍的。
转载地址:http://www.yunweipai.com/36333.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号