分布式存储Ceph(二) Ceph基础
Ceph 简介
- ceph 是一个开源的分布式存储系统, 同时支持文件存储(cephfs)、块存储(rbd)和对象存储(rgw)的分布式存储系统,具有高扩展性、高性能、高可靠性等优点。
- ceph 是一个对象(object)式存储系统, 它把每一个待管理的数据流(文件等数据)切分为一到多个固定大小(默认 4 兆)的对象数据, 并以其为原子单元(原子是构成元素的最小单元)完成数据的读写。
Ceph特点
- 高性能
- 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
- 考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架等。
- 能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用性
- 副本数可以灵活控制。
- 支持故障域分割,数据强一致性。
- 多重故障场景自动进行修复自愈。
- 没有单点故障,自动管理。
- 高可扩展性
- 去中心化。
- 扩展灵活。
- 随着节点增加而线性增长。
- 特性丰富
- 支持三种存储接口:块存储、文件存储、对象存储。
- 支持自定义接口,支持多种语言驱动。
Ceph存储架构
- Ceph支持三种接口:
-
- Object:有原生的API,而且也兼容Swift和S3的API,适合单客户端使用。
- Block:支持精简配置、快照、克隆,适合多客户端有目录结构。
- File:Posix接口,支持快照。
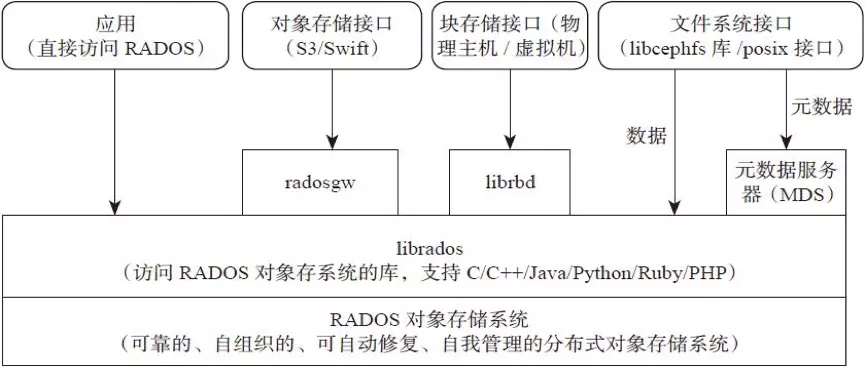
Ceph逻辑组织架构
- Pool:存储池、分区,存储池的大小取决于底层的存储空间。
- PG(placement group):一个pool内部可以有多个PG存在,pool和PG都是抽象的逻辑概念,一个pool中有多少个PG可以通过公式计算。
- OSD(Object Storage Daemon):每一块磁盘都是一个osd,一个主机由一个或多个osd组成。
ceph集群部署好之后,要先创建存储池才能向ceph写入数据,文件在想ceph保存之前要先进行一致性hash计算,计算后会把文件保存在某个对象的PG,此文件一定属于某个pool的一个PG,在通过PG保存在OSD上。
数据对象在写到主OSD之后在同步从OSD以实现数据的高可用。
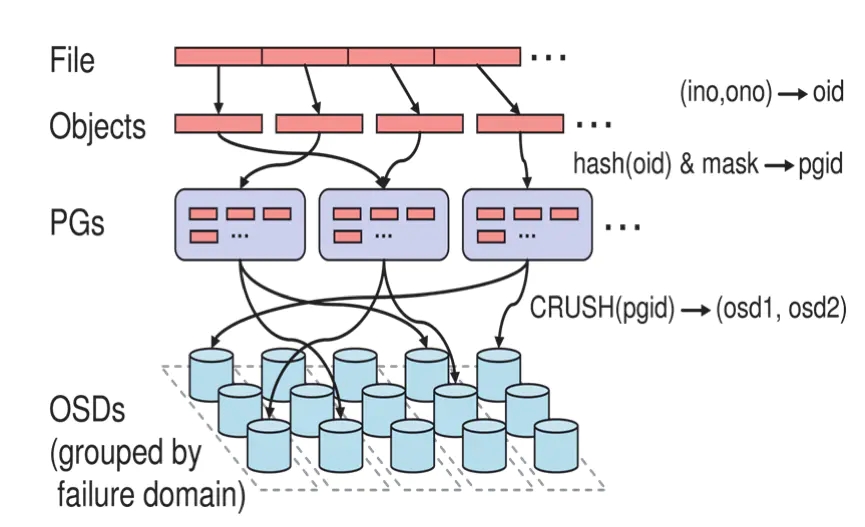
Ceph文件存储过程
-
一个文件将会切割为多个object(如1G文件每个object为4M将切割为256个),每个object会由一个由innode(ino)和object编号(ono)组成oid,即object id,oid是真个集群唯一,唯一标识object对象;
-
针对object id做hash并做取模运算,从而获取到pgid,即place group id,通过hash+mask获取到PGs ID,PG是存储object的容器;
-
Ceph通过CRUSH算法,将pgid进行运算,找到当前集群最适合存储PG的OSD节点,如osd1和osd2(假设为2个副本);
-
PG的数据最终写入到OSD节点,完成数据的写入过程,当然这里会涉及到多副本,一份数据写多副本;
- 主OSD将数据同步给备份OSD,并等待备份OSD返回确认;
- 主OSD将写入完成返回给客户端。
Ceph存储类型-块存储(RBD)
- https://docs.ceph.com/en/pacific/rbd/
块存储介绍
- 一个块是一个字节序列(通常为 512)。基于块的存储接口是将数据存储在包括 HDD、SSD、CD、软盘甚至磁带在内的介质上的一种成熟且常见的方式。无处不在的块设备接口非常适合与包括 Ceph 在内的海量数据存储进行交互。
- 块存储(RBD)需要格式化,将文件直接保存到磁盘上。
块存储结构图
- Ceph 块设备是精简配置的、可调整大小的,并存储在多个 OSD 上条带化的数据。Ceph 块设备利用 RADOS功能,包括快照、复制和强一致性。Ceph 块存储客户端通过内核模块或
librbd库与 Ceph 集群通信。
块存储特性
- Thin-provisioned 瘦分配,即先分配特定存储大小,随着使用实际使用空间的增长而占用存储空间,避免空间占用;
- Images up to 16 exabytes 耽搁景象最大能支持16EB;
- Configurable striping 可配置的切片,默认是4M;
- In-memory caching 内存缓存;
- Snapshots 支持快照,将当时某个状态记录下载;
- Copy-on-write cloning Copy-on-write克隆复制功能,即制作某个镜像实现快速克隆,子镜像依赖于母镜像;
- Kernel driver support 内核驱动支持,即rbd内核模块;
- KVM/libvirt support 支持KVM/libvirt,实现与云平台如openstack,cloudstack集成的基础;
- Back-end for cloud solutions 云计算多后端解决方案,即为openstack,kubernetes提供后端存储;
- Incremental backup 增量备份;
- Disaster recovery (multisite asynchronous replication) 灾难恢复,通过多站点异步复制,实现数据镜像拷贝。
块存储优点
- 通过RAID与LVM等手段,对数据提供保护。
- 多块廉价的硬盘组合起来,提供容量。
- 多块磁盘组合出来的逻辑盘,提高读写效率。
块存储缺点
- 采用SAN架构组网时,光纤交换机,造价成本高。
- 主机之间无法共享数据。
块存储使用场景
- docker容器、虚拟机磁盘。
- 日志存储。
- 文件存储。
Ceph存储类型-CephFS
- https://docs.ceph.com/en/pacific/cephfs/
CephFS介绍
- Ceph 文件系统或CephFS是一个符合 POSIX 的文件系统,它构建在 Ceph 的分布式对象存储RADOS之上。CephFS 致力于为各种应用程序提供最先进的、多用途、高可用性和高性能的文件存储,包括共享主目录、HPC 暂存空间和分布式工作流共享存储等传统用例。
- CephFS 通过使用一些新颖的架构选择来实现这些目标。值得注意的是,文件元数据与文件数据存储在一个单独的 RADOS 池中,并通过可调整大小的元数据服务器集群或MDS 提供服务,该集群可以扩展以支持更高吞吐量的元数据工作负载。文件系统的客户端可以直接访问 RADOS 来读取和写入文件数据块。出于这个原因,工作负载可能会随着底层 RADOS 对象存储的大小线性扩展;也就是说,没有网关或代理为客户端调解数据 I/O。
- CephFS提供数据存储的接口,是由操作系统针对块存储的应用,即由操作系统提供存储接口,应用程序通过调用操作系统将文件保存到块存储进行持久化。
- 要使用CephFS,需要部署cephfs服务。
- 从 Pacific 版本开始,支持多文件系统稳定且可以使用。此功能允许在单独的池上配置具有完全数据分离的单独文件系统。
CephFS架构图
- 对数据的访问通过 MDS 集群进行协调,MDS 集群作为客户端和 MDS 共同维护的分布式元数据缓存状态的权限。元数据的变异被每个 MDS 聚合成一系列有效的写入到 RADOS 上的日志;MDS 不会在本地存储元数据状态。此模型允许在 POSIX 文件系统上下文中的客户端之间进行连贯且快速的协作。

CephFS特性
- POSIX-compliant semantics POSIX风格接口;
- Separates metadata from data 元数据metadata和数据data分开存储;
- Dynamic rebalancing 动态数据均衡;
- Subdirectory snapshots 子目录快照;
- Configurable striping 可配置切割大小;
- Kernel driver support 内核驱动支持,即CephFS;
- FUSE support 支持FUSE风格;
- NFS/CIFS deployable 支持NFS/CIFS形式部署;
- Use with Hadoop (replace HDFS) 可支持与Hadoop继承,替换HDFS存储。
CephFS优点
- 造价低,随便一台机器就可以。
- 方便文件共享。
CephFS缺点
- 读写效率低。
- 传输速率慢。
CephFS使用场景
- 日志存储。
- FTP、NFS。
- 有目录结构的文件存储。
Ceph存储类型-对象存储(Object)
- https://docs.ceph.com/en/pacific/radosgw/
对象存储介绍
- 对象存储(Object)也称为基于对象的存储,其中的文件被拆分成多个部分并散布在多个存储服务器,在对象存储中,数据会被分解称为“对象”的离散单元,并保存在单个存储库中,而不是作为文件夹中的文件或服务器上的块来保存,对象存储需要一个简单的HTTP应用编程接口(API),以供大多数客户端使用。
- Ceph 对象存储支持两个接口。
-
-
S3 兼容:通过与 Amazon S3 RESTful API 的大部分子集兼容的接口提供对象存储功能。
-
Swift 兼容:通过与 OpenStack Swift API 的大部分子集兼容的接口提供对象存储功能。
-
对象存储架构图
- Ceph 对象存储使用 Ceph 对象网关守护进程 (
radosgw),它是一个 HTTP 服务器,用于与 Ceph 存储集群交互。由于它提供了与 OpenStack Swift 和 Amazon S3 兼容的接口,因此 Ceph 对象网关有自己的用户管理。Ceph 对象网关可以将数据存储在用于存储来自 Ceph 文件系统客户端或 Ceph 块设备客户端的数据的同一个 Ceph 存储集群中。S3 和 Swift API 共享一个公共命名空间,因此您可以使用一个 API 编写数据并使用另一个 API 检索数据。
对象存储特性
- RESTful Interface RESTful风格接口;
- S3- and Swift-compliant APIs 提供兼容于S3和Swfit风格API;
- S3-style subdomains S3风格的目录风格;
- Unified S3/Swift namespace 统一扁平的S3/Swift命名空间,即所有的对象存放在同一个平面上;
- User management 提供用户管理认证接入;
- Usage tracking 使用情况追踪;
- Striped objects 对象切割,将一个大文件切割为多个小文件(objects);
- Cloud solution integration 云计算解决方案即成,可以与Swfit对象存储即成;
- Multi-site deployment 多站点部署,保障可靠性;
- Multi-site replication 多站点复制,提供容灾方案。
对象存储 优点
- 具备块存储的读写高速。
- 具备文件存储的共享等特性。
对象存储使用场景
- 图片存储。
- 视频存储。
Ceph 概念介绍
RADOS
-
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
Librados
-
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。
Crush
-
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
Pool
-
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code)。
PG
-
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
Object
-
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
Ceph核心组件
Monitor (ceph-mon)
-
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责监视整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证(认证使用cephx协议)与授权。通常至少需要三个监视器才能实现冗余和高可用性。
Managers(ceph-mgr)
- 在一个主机上运行的一个守护进程。ceph manager守护程序负责跟踪运行时指标和ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。ceph manager 守护程序还托管基于python的模块来管理和公开ceph集群信息,包括基于web的ceph仪表盘和REST API 为外界提供统一的入口。高可用性通常至少需要两个管理器。
OSD(对象存储守护程序ceph-osd)
- OSD是负责物理存储的进程,操作系统上的一个磁盘就是一个OSD守护程序,OSD用于处理ceph集群数据复制,恢复,重新平衡,并通过检查其他ceph OSD守护程序的心跳来向ceph监视器和管理器提供一些监视信息。通常至少需要3个ceph OSD才能实现冗余和高可用性。
-
Pool、PG和OSD的关系:
-
- 一个Pool里有很多PG;
- 一个PG里包含一堆对象,一个对象只能属于一个PG;
- PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型);
MDS(ceph元数据服务器 ceph-mds)
-
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务。
RBD
- RBD全称RADOS block device,是Ceph对外提供的块设备服务。
RGW
- RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
CephFS
- CephFS全称Ceph File System,是Ceph对外提供的文件系统服务。
Ceph元数据保存方式
- 对象数据的元数据以key-value的形式存在,在RADOS中有两种实现:xattrs和omap。
- ceph可选后端支持多种存储引擎,比如filestore,bluestore,kvstore,memstore,ceph使用bluestore存储对象数据的元数据信息。
xattrs(扩展属性)
- 是将元数据保存在对象对应文件的扩展属性中并保存到系统磁盘上,这要求支持对象存储的本地文系统(一般是XFS)支持扩展属性。
omap(object map对象映射)
- omap:是object map的简称,是将元数据保存在本地文件系统只外的独立key-value存储系统中,在使用filestore时是leveldb,在使用bluestore时是rocksdb,由于filestore存在功能问题(需要将磁盘格式化为XFS格式)及元数据高可用问题等,因此ceph(Luminous 12.2.z 版本开始)主要使用bluestore。
filestore与leveldb
- ceph(Luminous 12.2.z 版本之前)早期基于filestore使用google的levelDB保存对象的元数据,LevelDb是一个持久化存储的kv系统,和Redis这种内存型的kv系统不同,leveldb不会像Redis一样将数据放在内存从而占用大量的内存空间,而是将大部分数据存储到磁盘上,但是需要把磁盘上的leveldb空间格式化为文件系统(XFS)。
- Filestore将数据保存到与Posix兼容的文件系统(Btrfs,XFS,ext4)。在ceph后端使用传统的linux文件系统尽管提供了一些好处,但也有代价,如性能、对象属性与磁盘本地文件系统属性匹配存在限制等。
bluestore与rocksdb
- 由于leveldb依然需要磁盘文件系统支持,后去facebok对levelDB进行改进为RocksDB, RocksDB将对象数据的元数据保存在RocksDB,ceph对象数据放在了每个OSD中,那么就在当前OSD中划分出一部分空间,格式化为BlueFS文件系统用于保存RocksDB中的元数据信息(成为Bluestore),并实现元数据的高可用,BlueStore最大的特点是构建在裸磁盘设备之上,并且对诸如SSD等新的存储设备做了很多优化工作。
- 对全SSD及全NVMe SSD闪存适配。
- 绕过本地文件系统层,直接管理裸设备,缩短IO路径。
- 严格分离元数据和数据,提高索引效率。
- 使用kv索引,解决文件系统目录结构遍历效率低的问题。
- 支持多种设备类型。
- 解决日志“双写”问题。
- 期望带来至少2倍的写性能提升和同等读性能。
- 增加数据校验及数据压缩等功能。
- RocksDB通过中间层BlueRocksDB访问文件系统的接口。这个文件系统与传统的linux文件系统(ext4和XFS)是不同的,它不是在VFS下面的通用文件系统,而是一个用户态的逻辑。BlueFS通过函数接口(API,非POSIX)的方式为BlueRocksDB提供类似文件系统的能力。
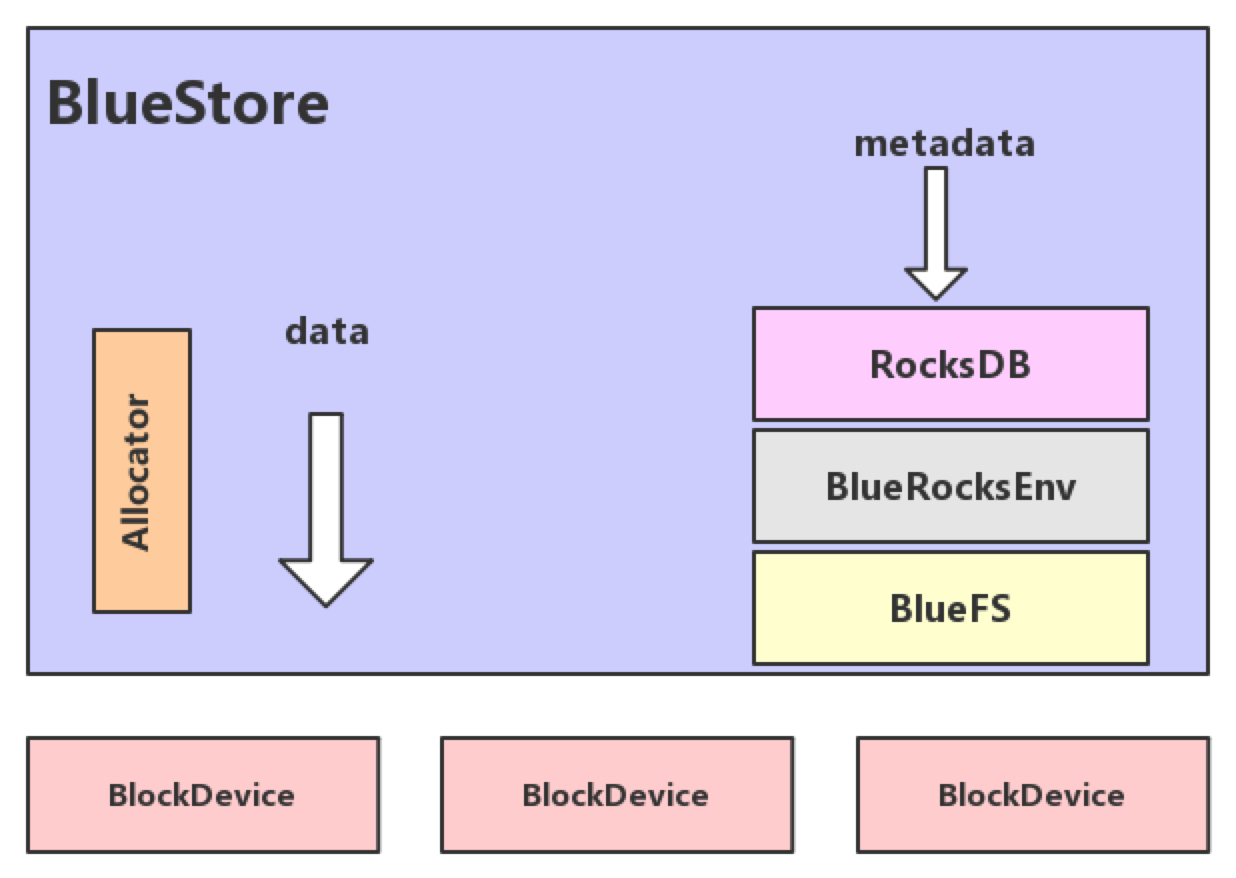
-
- Allocator:负责裸设备的空间管理分配。
- RocksDB:rocksdb是facebook基于leveldb开发的一款kv数据库,BlueStore将元数据全部存放至RocksDB中,这些元数据包括存储预写式日志、数据对象元数据、ceph的omap数据信息以及分配器的元数据。
- BlueRocksEnv:这是RocksDB与BlueFS交互的接口,RocksDB提供了文件操作的接口EnvWrapper(Env封装器)可以通过继承实现该接口来自定义底层的读写操作,BlueRocksEnv就是继承自EnvWrapper实现对BlueFS的读写。
- BlueFS:BlueFS是BlueStore针对RocksDB开发的轻量级文件系统,用于存放RocksDB产生的.sst和.log等文件。
- BlockDevice:BlueStore抛弃了传统的ext4、xfs文件系统,使用直接管理裸磁盘的方式;BlueStore支持同时使用多种不同类型的设备,在逻辑上BlueStore将存储空间划分为三层:慢速(Slow)空间、告诉(DB)空间、超高速(WAL)空间,不同的空间可以指定使用不同的设备类型,当然也可以使用同一块设备。
- BlueStore的设计考虑了FileStore中存在的一些硬伤,抛弃了传统的文件系统直接管理裸设备,缩短了IO路径,同时采用了ROW的方式,避免了日志双写的问题,在写入性能有了极大的提高。
Ceph CRUSH算法
- Controllers replication under scalable hashing #可控的、可复制的、可伸缩的一致性hash算法。
- ceph使用CRUSH算法来存放和管理数据,它是ceph的智能数据分发机制。ceph使用CRUSH算法来准确计算数据应该被保存到哪里,以及应该从哪里读取数据和保存元数据,不用的是CRUSH是按需计算出元数据,因此它就消除了对中心式的服务器/网关的需求,它使得ceph客户端能够计算出元数据,改过程也称为CRUSH查找,然后和OSD直接通信。
- 如果把对象直接映射到OSD之上会导致对象与OSD的对应关系过于紧密和耦合,当OSD由于故障发生变更时将会对整个ceph集群产生影响。
- 于是ceph将一个对象映射到RADOS集群的时候分为两步走。
- 首先使用一致性hash算法将对象名称映射到PG 2.7。
- 然后在PG ID基于CRUSH算法映射到OSD即可查找对象。
- 以上两个过程都是以实时计算的方式完成,而没有使用传统的查询数据与块设备的对应表的方式,这样有效避免了组件的中心化问题,也解决了查询性能和冗余问题。使得ceph集群扩展不在收查询的性能限制。
- 这个实时计算操作使用的就是CRUSH算法。
- Controllers replication under scalable hashing #可控的、可复制的、可伸缩的一致性hash算法。
- CRUSH是一种分布式算法,类似于一致性hash算法,用于为RADOS存储集群控制数据分配。
Ceph的管理节点
- ceph常用管理接口是一组命令行工具程序,例如rados、ceph、rbd等命令,ceph管理员可以从摸个特定的ceph-mon节点执行管理操作。
- 推荐使用部署专用的管理节点对ceph进行配置管理、升级与后期维护,方便后期权限管理,管理节点的权限支队管理人员开放,可以避免一些不必要的误操作发生。
Ceph集群部署方法
官方文档
- https://github.com/ceph/ceph #github仓库
- http://docs.ceph.org.cn/install/manual-deployment/ #简要部署过程
- https://docs.ceph.com/en/latest/releases/index.html #版本历史
- https://docs.ceph.com/en/latest/releases/pacific/#v16-2-0-pacific #ceph 16 即 Pacific 版本支持的系统
- CentOS 8
- Ubuntu 20.04 (Focal)
- Ubuntu 18.04 (Bionic)
- Debian Buster
- Container image (based on CentOS 8)
官方推荐
- Cephadm
- 使用容器和 systemd 安装和管理 Ceph 集群,并与 CLI 和仪表板 GUI 紧密集成。
- cephadm 仅支持 Octopus 和更新版本。
- cephadm 与新的编排 API 完全集成,并完全支持新的 CLI 和仪表板功能来管理集群部署。
- cephadm 需要容器支持(podman 或 docker)和 Python 3。
- Rook
- 部署和管理在 Kubernetes 中运行的 Ceph 集群,同时还支持通过 Kubernetes API 管理存储资源和配置。我们推荐 Rook 作为在 Kubernetes 中运行 Ceph 或将现有 Ceph 存储集群连接到 Kubernetes 的方式。
- Rook 仅支持 Nautilus 和更新版本的 Ceph。
- Rook 是在 Kubernetes 上运行 Ceph 或将 Kubernetes 集群连接到现有(外部)Ceph 集群的首选方法。
- Rook 支持新的 Orchestrator API。完全支持 CLI 和仪表板中的新管理功能。
其它方法
- ceph-ansible: https://github.com/ceph/ceph-ansible #python
- ceph-salt: https://github.com/ceph/ceph-salt #python
- ceph-container: https://github.com/ceph/ceph-container #shell
- ceph-chef: https://github.com/ceph/ceph-chef #Ruby
- ceph-deploy: https://github.com/ceph/ceph-deploy #python
- Ceph-deploy是一个ceph官方维护的基于ceph-deploy命令行部署ceph集群的工具,基于ssh执行可以sudo权限的shell命令以及一些python脚本实现ceph集群的部署和管理维护。
- Ceph-deploy 只用于部署和管理ceph集群,客户端需要访问ceph,需要部署客户端工具。
- Ceph-deploy v2.0.1版本不兼容python 3.7+
Ceph 的版本历史
- x.0.z - 开发版(给早期测试者和勇士们) 9.0.0->9.0.1->9.0.2 等。
- x.1.z - 候选版(用于测试集群、 高手们)9.1.0->9.1.1->9.1.2 等。
- x.2.z - 稳定、 修正版(给用户们) 9.2.0->9.2.1->9.2.2 等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号