
图像检索(3):BoW实现
在上一篇文章中图像检索(2):均值聚类-构建BoF中,简略的介绍了基于sift特征点的BoW模型的构建,以及基于轻量级开源库vlfeat的一个简单实现。
本文重新梳理了一下BoW模型,并给出不同的实现。
- 基于OpenCV的BoW实现
- BoWTrainer的使用
- 词袋模型开源库DBoW3
BoW
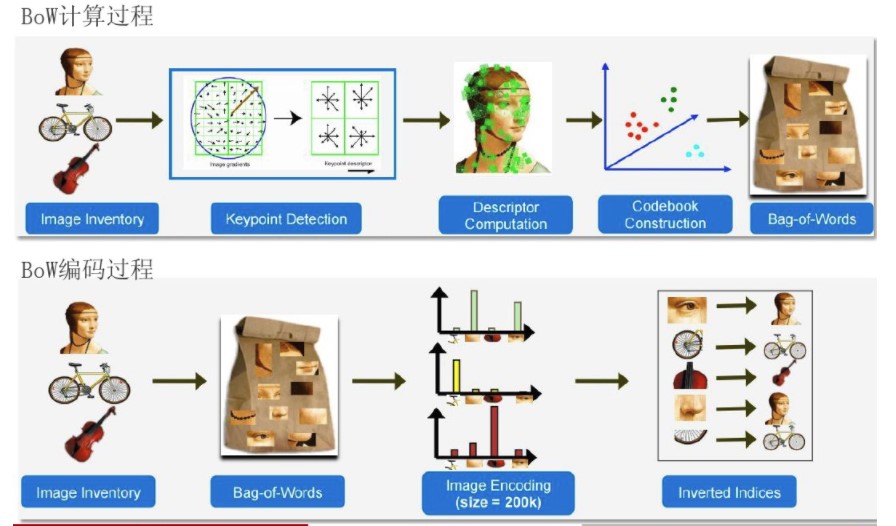
BoW模型最初是为解决文档建模问题而提出的,因为文本本身就是由单词组成的。它忽略文本的词序,语法,句法,仅仅将文本当作一个个词的集合,并且假设每个词彼此都是独立的。这样就可以使用文本中词出现的频率来对文档进行描述,将一个文档表示成一个一维的向量。
将BoW引入到计算机视觉中,就是将一幅图像看着文本对象,图像中的不同特征可以看着构成图像的不同词汇。和文本的BoW类似,这样就可以使用图像特征在图像中出现的频率,使用一个一维的向量来描述图像。
要将图像表示为BoW的向量,首先就是要得到图像的“词汇”。通常需要在整个图像库中提取图像的局部特征(例如,sift,orb等),然后使用聚类的方法,合并相近的特征,聚类的中心可以看着一个个的视觉词汇(visual word),视觉词汇的集合构成视觉词典(visual vocabulary) 。 得到视觉词汇集合后,统计图像中各个视觉词汇出现的频率,就得到了图像的BoW表示。
总结起来就是:
- 提取图像库中所有图像的局部特征,例如sift,得到特征集合\(F\)
- 对特征集合\(F\)进行聚类,得到\(k\)个聚类中心\(\{C_i|i = 1,\dots,k\}\),每一个聚类中心\(C_i\)代表着一个视觉词汇。聚类中心的集合就是视觉词典\(vocabulary = \{C_i|i = 1,\dots,k\}\)
- 一幅图像的BoW表示
- 提取图像的局部特征,得到特征集合\(f = \{f_i |i = 1,\dots,n\}\)
- 计算特征\(f_i\)属于那个词汇\(C_i\)(到该中心的距离最近)
- 统计每个词汇\(C_i\)在图像中出现的频数,得到一个一维的向量,该向量就是图像的BoW表示。
综合起来,取得一幅图像的BoW向量的步骤:
- 构建图像库的视觉词典
Vocabulary- 提取图像库中所有图像的局部特征,如SIFT.
- 对提取到的图像特征进行聚类,如k-means,得到聚类中心就是图像库的视觉词汇词典
Vocabulary
- 计算一幅图像的BoW向量
- 提取图像的局部特征
- 统计
Vocabulay中的每个视觉词汇visual word ,在图像中出现的频率。
基于OpenCV的实现
基于OpenCV的原生实现
- 第一步提取图像的sift特征。对sift特征的详细讲解,可以参考其余两篇文章:再论SIFT-基于vlfeat实现 和SIFT特征详解。 这里不再赘述,提取特征的代码如下:
void siftDetecotor::extractFeatures(const std::vector<std::string> &imageFileList,std::vector<cv::Mat> &features)
{
int index = 1;
int count = 0;
features.reserve(imageFileList.size());
auto size = imageFileList.size();
//size = 20;
//#pragma omp parallel for
for(size_t i = 0; i < size; i ++){
auto str = imageFileList[i];
Mat des;
siftDetecotor::extractFeatures(str,des);
features.emplace_back(des);
count += des.rows;
index ++ ;
}
cout << "Extract #" << index << "# images features done!" << "Count of features:#" << count << endl;
}
传入imageFileList是图像的路径列表,vector<Mat> featurues返回提取得到的所有图像的特征。
- 聚类,得到
Vocabulary
OpenCV中k-means聚类的接口如下:
double cv::kmeans ( InputArray data,
int K,
InputOutputArray bestLabels,
TermCriteria criteria,
int attempts,
int flags,
OutputArray centers = noArray()
)
data输入数据,每一行是一条数据。k聚类的个数,这是就是Vocabulary的大小(词汇的个数u)。bestLabels每一个输入的数据所属的聚类中心的indexcriteriakmenas算法是迭代进行,这里表示迭代的终止条件。 可以是迭代的次数,或者是结果达到的精度,也可以是两者的结合,达到任一条件就结束。attmepts算法的次数,使用不同的初始化方法flags算法的初始化方法,可以选择随机初始化KMEANS_RANDOM_CENTERS,或者kmeans++的方法KMEANS_PP_CENTERScenters聚类的中心组成的矩阵。
得到图像库中图像的所有特征后,可以将这些特征组成一个大的矩阵输入到kmeans算法中,得到聚类中心,也就是Vocabulary
Mat f;
vconcat(features,f);
vector<int> labes;
kmeans(f,k,labes,TermCriteria(TermCriteria::COUNT + TermCriteria::EPS,100,0.01),3,cv::KMEANS_PP_CENTERS,m_voc);
首先,使用vconcat将提取的特征点沿Y方向叠放在一起。k-means算法的终止条件是ermCriteria::COUNT + TermCriteria::EPS,100,0.01,算法迭代100次或者精度达到0.01就结束。
- 图像的BoW编码
得到Vocabulary后,统计视觉词汇在每个图像出现的概率就很容易得到图像的BoW编码
void Vocabulary::transform_bow(const cv::Mat &img,std::vector<int> bow)
{
auto fdetector = xfeatures2d:: SIFT ::create(0,3,0.2,10);
vector<KeyPoint> kpts;
Mat des;
fdetector->detectAndCompute(img,noArray(),kpts,des);
Mat f;
rootSift(des,f);
// Find the nearest center
Ptr<FlannBasedMatcher> matcher = FlannBasedMatcher::create();
vector<DMatch> matches;
matcher->match(f,m_voc,matches);
bow = vector<int>(m_k,0);
// Frequency
/*for( size_t i = 0; i < matches.size(); i++ ){
int queryIdx = matches[i].queryIdx;
int trainIdx = matches[i].trainIdx; // cluster index
CV_Assert( queryIdx == (int)i );
bow[trainIdx] ++; // Compute word frequency
}*/
// trainIdx => center index
for_each(matches.begin(),matches.end(),[&bow](const DMatch &match){
bow[match.trainIdx] ++; // Compute word frequency
});
}
在查找图像的某个特征属于的聚类中心时,本质上就是查找最近的向量,可以使用flann建立索引树来查找;也可以使用一些特征匹配的方法,这里使用flannMatcher。统计每个词汇在图像中出现的频率,即可得到图像的BoW向量。
BoWTrainer
在OpenCV中封装了3个关于BoW的类。
抽象基类BOWTrainer,从图像库中的特征集中构建视觉词汇表Vobulary
class CV_EXPORTS_W BOWTrainer
{
public:
BOWTrainer();
virtual ~BOWTrainer();
CV_WRAP void add( const Mat& descriptors );
CV_WRAP const std::vector<Mat>& getDescriptors() const;
CV_WRAP int descriptorsCount() const;
CV_WRAP virtual void clear();
CV_WRAP virtual Mat cluster() const = 0;
CV_WRAP virtual Mat cluster( const Mat& descriptors ) const = 0;
protected:
std::vector<Mat> descriptors;
int size;
};
类BOWKMeansTrainer基于k-means聚类,实现了BOWTrainer的方法。使用kmeans方法,从特征集中聚类得到视觉词汇表Vocabulary。其声明如下:
class CV_EXPORTS_W BOWKMeansTrainer : public BOWTrainer
{
public:
CV_WRAP BOWKMeansTrainer( int clusterCount, const TermCriteria& termcrit=TermCriteria(),
int attempts=3, int flags=KMEANS_PP_CENTERS );
virtual ~BOWKMeansTrainer();
CV_WRAP virtual Mat cluster() const;
CV_WRAP virtual Mat cluster( const Mat& descriptors ) const;
protected:
int clusterCount;
TermCriteria termcrit;
int attempts;
int flags;
};
该类的使用也是很简单的,首先构建一个BOWKMeansTrainer的实例,其第一个参数clusterCount是聚类中心的个数,也就是Vocabulary的大小,余下的几个参数就是使用kmeans函数的参数,具体可参考上面的介绍。
然后,调用add方法,添加提取到的特征集。 添加特征集的时候,有两种方法:
for(int i=0; i<numOfPictures; i++)
bowTraining.add( descriptors( i ) );
也可以提取好所有图像的特征,然后将特征合并为一个矩阵添加
Mat feature_list;
vconcat(features,feature_list);
BOWKMeansTrainer bow_trainer(k);
bow_trainer.add(feature_list);
添加图像特征后,调用
vocabulary = bow_trainer.cluster();
对特征集进行聚类,得到的聚类中心就是所要求的视觉词汇表Vocabulary。
在得到Vocabulary后,就可以对一副图像进行编码,使用BoW向量来表示该图像,这时候就要使用BOWImgDescriptorExtractor。其声明如下:
class BOWImgDescriptorExtractor{
public:
BOWImgDescriptorExtractor( const Ptr<DescriptorExtractor> &dextractor, const Ptr<DescriptorMatcher> & dmatcher );
virtual ~BOWImgDescriptorExtractor(){}
void setVocabulary( const Mat& vocabulary );
const Mat& getVocabulary() const;
void compute( const Mat& image, vector<KeyPoint> & keypoints,
Mat& imgDescriptor,
vector<vector<int> >* pointIdxOfClusters = 0,
Mat* descriptors = 0 );
int descriptorSize() const;
int descriptorType() const;
protected:
Mat vocabulary;
Ptr<DescriptorExtractor> dextractor;
Ptr<DescriptorMatcher> dmatcher;
该类实现了一下三个功能:
- 根据相应的
Extractor提取图像的特征 - 找到距离每个特征最近的visual word
- 计算图像的BoW表示,并且将其进归一化。
要实例化一个BOWImgDescriptorExtractor,需要提供三个参数
- 视觉词汇表
Vocabulalry - 图像特征提取器
DescriptorExtractor - 特征匹配的方法
descriptorMatcher,用来查找和某个特征最近的visual word。
其使用也很便利,使用Extractor和Matcher实例化一个BOWImgDescriptorExtractor,然后设置Vocabulary,
BOWImgDescriptorExtractor bowDE(extractor, matcher);
bowDE.setVocabulary(dictionary); //dictionary是通过前面聚类得到的词典;
要求某图像的BoW,可以调用compute方法
bowDE.compute(img, keypoints, bow);
Summary
BOWKMeansTrainer 对提取到的图像特征集进行聚类,得到视觉词汇表Vocabulary
BOWImgDescriptorExtractor 在得到视觉词汇表后,使用该类,可以很方便的对图像进行BoW编码。
DBoW3
DBoW3是一个开源的C++词袋模型库,可以很方便将图像转化成视觉词袋表示。它采用层级树状结构将相近的图像特征在物理存储上聚集在一起,创建一个视觉词典。DBoW3还生成一个图像数据库,带有顺序索引和逆序索引,可以使图像特征的检索和对比非常快。
DBoW3是DBoW2的增强版,仅依赖OpenCV,能够很方便的使用。开源的SLAM项目ORB_SLAM2就是使用DBoW2进行回环检测的,关于DBoW3详细介绍,可以参考浅谈回环检测中的词袋模型(bag of words).
本文仅介绍下DBoW3的使用,DBoW3的源代码在github上https://github.com/rmsalinas/DBow3, 是基于CMake的,配置好OpenCV库后,直接cmake编译即可。
DBoW3两个比较重要的类是Vocabulary和Database,Vocabulary表示图像库的视觉词汇表,并可以将任一的图像转换为BoW表示,Database是一个图像数据库,能够方便的对图像进行检索。
构建Vocabulary的代码如下:
void vocabulary(const vector<Mat> &features,const string &file_path,int k = 9,int l = 3){
//Branching factor and depth levels
const DBoW3::WeightingType weight = DBoW3::TF_IDF;
const DBoW3::ScoringType score = DBoW3::L2_NORM;
DBoW3::Vocabulary voc(k,l,weight,score);
cout << "Creating a small " << k << "^" << l << " vocabulary..." << endl;
voc.create(features);
cout << "...done!" << endl;
//cout << "Vocabulary infomation: " << endl << voc << endl << endl;
// save the vocabulary to disk
cout << endl << "Saving vocabulary..." << endl;
stringstream ss;
ss << file_path << "/small_voc.yml.gz";
voc.save(ss.str());
cout << "Done" << endl;
}
传入图像的特征集,配置聚类树的分支树(k),以及深度(l),调用create进行聚类即得到Vocabulary。 可以将得到的Vocabulary保存成文件,以便后面使用。
有了Vocabulary后,就可以构建一个Database方便图像的查找
void database(const vector<Mat> &features,const string &file_path){
// load the vocabulary from disk
stringstream ss ;
ss << file_path <<"/small_voc.yml.gz";
DBoW3::Vocabulary voc(ss.str());
DBoW3::Database db(voc, false, 0); // false = do not use direct index
// add images to the database
for(size_t i = 0; i < features.size(); i++)
db.add(features[i]);
cout << "... done!" << endl;
cout << "Database information: " << endl << db << endl;
// we can save the database. The created file includes the vocabulary
// and the entries added
cout << "Saving database..." << endl;
db.save("small_db.yml.gz");
cout << "... done!" << endl;
}
需要前面得到Vocabulary和图像的特征集来创建Database,创建完成后,也可以将其保存为本地文件,方便后面的使用。
有了Database后,可以其调用query方法,来查找数据库中是否有相类似的图片。
//auto fdetector=cv::xfeatures2d::SURF::create(400, 4, 2);
auto fdetector = xfeatures2d::SIFT::create(0,3,0.2,10);
vector<KeyPoint> kpts;
Mat des;
fdetector->detectAndCompute(img,noArray(),kpts,des);
db.query(des,ql,max_resuts);
提取图像的特征,调用query该方法使用QueryResults返回查询的结构。
Summary
本文重新梳理了下BoW模型,并且介绍了三种的实现方法:
- 基于OpenCV的原生实现,调用OpenCV的特征提取,聚类,匹配方法,获取图像的BoW向量。
- 使用OpenCV封装的
BowTrainer和BOWImgDescriptorExtractor类,更简单的实现BoW模型。 - 使用开源库DBoW3,该方法不断能够很简单的创建
Vocabulary,而且创建了一个图像的Database,比较方法的利用BoW向量在图像库中查找类似图片。
做了几个月的图像检索,陆续把这段时间的收获整理下。 本文主要介绍了BoW的实现,下一篇争取实现一个完整的图像检索的流程,预计有以下几个方面:
- TF-IDF
- root-sift
- vlad
本系列图像检索的代码会push到github上,初期一直在写各种sample,代码有点乱,欢迎fork/start。
地址: https://github.com/brookicv/imageRetrieval

 浙公网安备 33010602011771号
浙公网安备 33010602011771号