
图像检索(1): 再论SIFT-基于vlfeat实现
概述
基于内容的图像检索技术是采用某种算法来提取图像中的特征,并将特征存储起来,组成图像特征数据库。当需要检索图像时,采用相同的特征提取技术提取出待检索图像的特征,并根据某种相似性准则计算得到特征数据库中图像与待检索图像的相关度,最后通过由大到小排序,得到与待检索图像最相关的图像,实现图像检索。图像检索的结果优劣取决于图像特征提取的好坏,在面对海量数据检索环境中,我们还需要考虑到图像比对(图像相似性考量)的过程,采用高效的算法快速找到相似图像也至关重要。
在构建图像特征库的时候,通常不会使用原始的图像特征,这是由于Raw Feature有很多冗余信息,而且维度过高在构建特征数据库和匹配的时候效率较低。所以,通常要对提取到的原始特征进行重新编码。比较常用的三种编码方式:
- BoF , Bog of Feature 源于文本处理的词袋模型(Bog,Bag of Words)
- VLAD , Vector of Aggragate Locally Descriptor
- FV , fisher vector
构建图像特征数据库,通常有以下几个步骤:
- 图像预处理流程(增强,旋转,滤波,缩放等)
- 特征提取(全局特征,局部特征:SIFT,SURF,CNN等)
- 对每张图片提取的原始特征重新编码(BoF,VLAD,FV)形成图像的特征库
图像的特征库构建完成后,在检索阶段,主要涉及到特征的相似性度量准则,排序,搜索
- 提取图像的特征,
- 特征编码
- 在图像特征库中进行检索
- 返回相似性较高的结果
SIFT特征
SIFT特征的讲解已经很多了,之前的博客也有过介绍。本文就借助vlfeat对SIFT特征的提取过程做一个总结。
一个SIFT特征有两部分组成:关键点(keypoint)和对应特征描述子(Descriptor)。使用SIFT detector 进行SIFT关键点的提取,然后使用SIFT descriptor计算关键点的描述子。也可以独立的使用SIFT detector进行SIFT 关键点的提取,或者使用SIFT descriptor进行别的关键点描述子的计算。
一个SIFT keypoint是一块圆形区域并且带有方向,使用4个参数描述该区域的几何结构:
- keypoint的中心位置的坐标\((x,y)\)
- keypoint的scale(圆形区域的半径\(r\))
- keypoint的方向(使用弧度表示的角度\(\theta\))

一个SIFT关键点由4个参数确定:
SIFT在多尺度空间检测关键点,确定关键点的位置和尺度,保证了关键点的尺度不变性;利用关键点邻域像素的梯度分布来确定关键点的方向,保证关键点的旋转(方向)不变性。
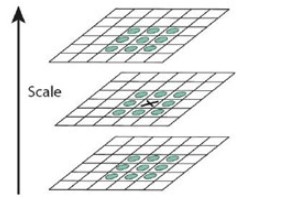
高斯尺度空间
SIFT在高斯尺度空间进行特征点检测,一个高斯尺度空间有图像和不同的高斯卷积核卷积得到:
\(L(x,y,\sigma)\)表示图像的高斯尺度空间,\(\sigma\)称为尺度空间因子,它是高斯函数标准差,反映了图像的模糊程度,其值越大图像越模糊,对应的尺度也就越大。
而对图像关键点的检测比较好的算子是\(\Delta^2G\),高斯拉普拉斯(LoG)。但是该算子的运算量较大,所以通常使用\(DoG\)(Difference of Gaussian)来近似计算LoG。
\(DoG\)的定义为:
\(L(x,y,\sigma)\)表示高斯尺度空间,则相邻两个高斯尺度空间相减就得到来的\(DoG\)的响应图像。
所以为了的得到\(DoG\)的响应图像,就需要先构建高斯尺度空间。高斯尺度空间是由图像金字塔降采样结合高斯滤波得到的。高斯尺度空间分为多个组\(Octave\)(每组图像的分辨率一样),每组有多层\(Level\)(使用不同的\(\sigma\)进行高斯模糊得到)。以一个\(512 \times 512\)的图像\(I\),其构建高斯尺度空间的步骤:(倒立的金字塔)
- 高斯尺度的组数$ o = log_2 min(m,n) - 3 = log_2(512) - 3 = 6$
- 构建第0组,将原图像进行上采样,宽和高增加一倍得到图像\(I_0\)。
- 第0层\(I_0 * G(x,y,\sigma_0)\)
- 第1层\(I_0 * G(x,y,k\sigma_0)\)
- 第2层\(I_0 * G(x,y,k^2\sigma_0)\)
- 构建第1组,将\(I_0\)进行降采样,得到图像\(I_1\)
- 第0层\(I_1 * G(x,y,2\sigma_0)\)
- 第1层\(I_1 * G(x,y,2k\sigma_0)\)
- 第2层\(I_1 * G(x,y,2k^2\sigma_0)\)
- ...
- 构建第\(o\)组,第\(s\)层 \(I_o * G(x,y,2^ok^s\sigma)\)
在Lowe的算法实现中\(\sigma_0 = 1.6,o_min = -1\)。\(o_min = -1\)表示金字塔的第0组是原图像上采样得到的,宽和高加一倍。
DoG 极值点检测
高斯图像金字塔构建完成后,将同一组的相邻两层相减就得到了\(DoG\)金字塔。
每组的层数\(S = 3\),也就是说每组可以得到两层的\(DoG\)图像,以第一组为例:其尺度为\(\sigma,k\sigma\),只有两项是无法求取极值的,需要左右两边都有尺度。由于无法比较取得极值,那么我们就需要继续对每组的图像进行高斯模糊,使得尺度形成\(\sigma,k\sigma,k^2\sigma,k^3\sigma,k^4\sigma\)这样就可以选择中间的三项\(k\sigma,k^2\sigma,k^3\sigma\)
检测关键点,就是在\(DoG\)的图像空间中寻找极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,改点就是极值点。如图所示,中间的检测点要和其所在图像的\(3 \times 3\)邻域8个像素点,以及其相邻的上下两层的\(3\times 3\)领域18个像素点,共26个像素点进行比较。
删除不好的极值点
删除两类极值点
- 在对比度比较低低的区域检测到的极值点
- 在图像的边缘部分检测到的极值点
确定关键点的方向
统计关键点邻域像素的梯度方向分布来确定关键点的方向。具体步骤如下:
- 计算以特征点为中心,以\(3 \times1.5 \sigma\)为半径的区域图像的幅角和幅值,每个像点\(L(x,y)\)的梯度的模\(m(x,y)\)以及方向\(\theta(x,y)\)可通过下面公式求得
- 统计像素点的幅角和幅值的直方图,梯度方向的直方图的横轴是梯度方向的角度(梯度方向的范围是0到360度,直方图每36度一个柱共10个柱,或者没45度一个柱共8个柱),纵轴是梯度方向对应梯度幅值的累加,在直方图的峰值就是特征点的主方向。在梯度直方图中,当存在一个相当于主峰值80%能量的柱值时,则可以将这个方向认为是该特征点辅助方向。所以,一个特征点可能检测到多个方向(也可以理解为,一个特征点可能产生多个坐标、尺度相同,但是方向不同的特征点)。
得到特征点的主方向后,对于每个特征点可以得到三个信息\(k(x,y,r,\theta)\),即位置、尺度和方向。由此可以确定一个SIFT特征区域,一个SIFT特征区域由三个值表示,中心表示特征点位置,半径表示关键点的尺度,箭头表示主方向。
具有多个方向的关键点可以被复制成多份,然后将方向值分别赋给复制后的特征点,一个特征点就产生了多个坐标、尺度相等,但是方向不同的特征点。
计算关键点描述子
在检测部分已经得到了SIFT关键点的位置,尺度和方向信息,生成关键点的描述子,就是使用一个向量来描述关键点及其邻域像素的信息。
由以下步骤生成描述子:
-
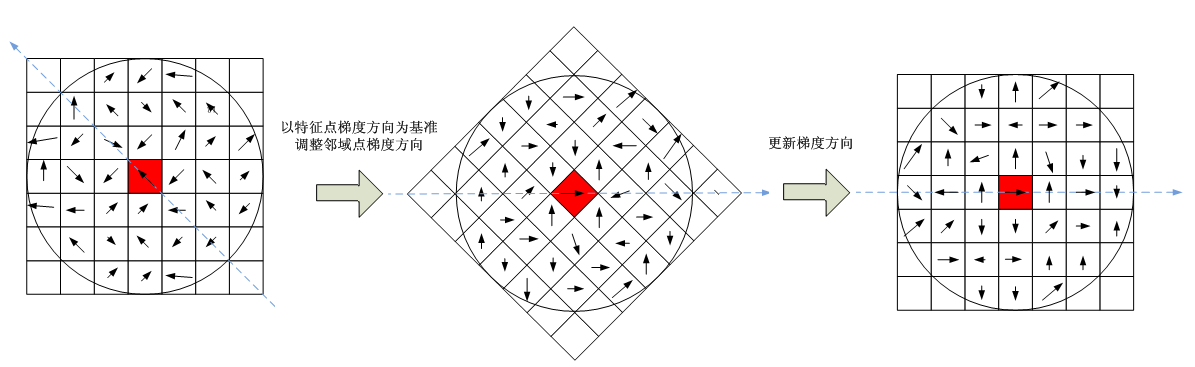
为了保证旋转不变性,将关键点为中心的邻域像素的坐标轴进行旋转,将\(x\)轴旋转至关键点主方向,如下图:
-
分块计算邻域内像素的梯度方向直方图,以关键点为中心的\(16\times16\)的区域内,划分\(4\times4\)个块,分别计算每个块的梯度直方图,如下图:

每个块的梯度直方方向直方图的计算方式,和求关键点主方向时类似:此时每个区域的梯度直方图在0-360之间划分为8个方向区间,每个区间为45度,即每个种子点有8个方向的梯度强度信息,最后将得到的\(4\times4\times8=128\)维的特征向量。
- 为了去除光照变化的影响,需对上述生成的特征向量进行归一化处理。在归一化处理后,在128维的单位向量中,对大于0.2的要进行截断处理,即大于0.2的值只取0.2,然后重新进行一次归一化处理,其目的是为了提高鉴别性。0.2 是实验得出的经验值。
vlfeat实现的sift特征提取
vlfeat是一个开源的轻量级的计算机视觉库,主要实现图像局部特征的提取和匹配以及一些常用的聚类算法。其对sift特征提取的各个步骤进行了封装,使用的方法如下:
- 调用
vl_sift_new初始化VlSiftFilt,设置sift提取时参数信息,如:图像的大小,Octave的个数,每个Octave的中的层数,起始的Octave的index. 各个参数的具体含义可以参考上面sift特征提取的方法。 - 设置剔除不稳定关键点的阈值。在上面提到,sift在进行极值检查后,要剔除两类不稳定的极值点:1.对比度较低区域的极值点;2.边缘部分的极值点。 可以调用
vl_sift_set_peak_thresh设置接受极值点是一个关键点的最小对比度。 该值越小,提取到的关键点就越多。y vl_sift_set_edge_thresh()设置一个极值点是在边缘上的阈值。 该值越小,提取到的关键点就越多。
这两个参数对最终提取到的特征点个数有很大的影响。
- 初始化工作完成后,可以循环的对尺度空间的每个Octave进行处理了
- 调用
vl_sift_process_first_octave()和vl_sift_process_next_octave()来计算下一个DoG尺度空间。 - 调用
vl_sift_detect进行关键点提取 - 对每一个提取到的关键点
vl_sift_calc_keypoint_orientations计算关键点的方向,可能多于一个l_sift_calc_keypoint_descriptor计算每个方向的特征描述子。
- 调用
vl_sift_delete释放资源。
具体代码如下:
// 初始化
const string file = "../0.jpg";
Mat img = imread(file,IMREAD_GRAYSCALE);
Mat color_img = imread(file);
Mat float_img;
img.convertTo(float_img,CV_32F);
int rows = img.rows;
int cols = img.cols;
VlSiftFilt* vl_sift = vl_sift_new(cols,rows,4,3,0);
vl_sift_set_peak_thresh(vl_sift,0.04);
vl_sift_set_edge_thresh(vl_sift,10);
vl_sift_pix *data = (vl_sift_pix*)(float_img.data);
vector<VlSiftKeypoint> kpts;
vector<float*> descriptors;
vl_sift_extract(vl_sift,data,kpts,descriptors);
/*
Extract sift using vlfeat
parameters:
vl_sfit, VlSiftFilt*
data , image pixel data ,to be convert to float
kpts, keypoint list
descriptors, descriptor. Need to free the memory after using.
*/
void vl_sift_extract(VlSiftFilt *vl_sift, vl_sift_pix* data,
vector<VlSiftKeypoint> &kpts,vector<float*> &descriptors) {
// Detect keypoint and compute descriptor in each octave
if(vl_sift_process_first_octave(vl_sift,data) != VL_ERR_EOF){
while(true){
vl_sift_detect(vl_sift);
VlSiftKeypoint* pKpts = vl_sift->keys;
for(int i = 0; i < vl_sift->nkeys; i ++) {
double angles[4];
// 计算特征点的方向,包括主方向和辅方向,最多4个
int angleCount = vl_sift_calc_keypoint_orientations(vl_sift,angles,pKpts);
// 对于方向多于一个的特征点,每个方向分别计算特征描述符
// 并且将特征点复制多个
for(int i = 0 ; i < angleCount; i ++){
float *des = new float[128];
vl_sift_calc_keypoint_descriptor(vl_sift,des,pKpts,angles[0]);
descriptors.push_back(des);
kpts.push_back(*pKpts);
}
pKpts ++;
}
// Process next octave
if(vl_sift_process_next_octave(vl_sift) == VL_ERR_EOF) {
break ;
}
}
}
}
vlfeat中sift提取接受的是float类型的数据,所以要先将读到的数据图像转换为float。
和OpenCV中的sift提取的对比结果如下:

- vlfeat提取的特征点是用绿色画出来的,共有1961个特征点。
- OpenCV的是蓝色,有4617个特征点。
Summary
几年前写过一篇关于SIFT的文章,SIFT特征详解 当时多是从理论上。现在在做图像检索的时候,发现还是有很多东西理解的不是很清晰,比如:关键点的多个方向,不稳定极值点的剔除以及梯度方向直方图计算等等。
正在做一个图像检索的项目,陆续将项目的中学到一些知识总结下来,下一篇是关于均值聚类的,对提取到的图像特征进行聚类生成视觉特征(Visul Feature)表。本系列的代码会陆续更新到Github上,欢迎start/fork 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号