


目标检测 1 : 目标检测中的Anchor详解
咸鱼了半年,年底了,把这半年做的关于目标的检测的内容总结下。
本文主要有两部分:
- 目标检测中的边框表示
- Anchor相关的问题,R-CNN,SSD,YOLO 中的anchor
目标检测中的边框表示
目标检测中,使用一个矩形的边框来表示。在图像中,可以基于图像坐标系使用多种方式来表示矩形框。
- 最直接的方式,使用矩形框的左上角和右下角在图像坐标系中的坐标来表示。

使用绝对坐标的\((x_{min},y_{min},x_{max},y_{max})\)。 但是这种绝对坐标的表示方式,是以原始图像的像素值为基础的,这就需要知道图像的实际尺度,如果图像进行缩放,这种表示就无法准确的进行定位了。
- 对图像的尺寸进行归一化,使用归一化后的坐标矩形框

坐标进行归一化,这样只要知道图像的scale就能够很容易在当前尺度下使用矩形框定位。
- 中心坐标的表示方式
使用中心坐标和矩形框的宽和高的形式表示矩形框。

\((c_x,c_y,w,h)\)这种方式很明确的指出来矩形框的大小。
在目标检测中,训练数据的额标签通常是基于绝对坐标的表示方式的,而在训练的过程中通常会有尺度的变换这就需要将边框坐标转换为归一化后的形式。
在计算损失值时,为了平衡尺寸大的目标和尺寸小的目标对损失值的影响,就需要将矩形框表示为中心坐标的方式,以方便对矩形框的宽和高添加权重。
最后,要将归一化后的中心坐标形式转换为检测图像的原始尺度上。
Anchor Box
预定义边框就是一组预设的边框,在训练时,以真实的边框位置相对于预设边框的偏移来构建
训练样本。 这就相当于,预设边框先大致在可能的位置“框“出来目标,然后再在这些预设边框的基础上进行调整。
为了尽可能的框出目标可能出现的位置,预定义边框通常由上千个甚至更多,在深度学习之前,通常使用各种形状的“滑动窗口”,在原图像滑动,来产不同位置不同形状的预设边框。
到了深度学习时期,由于对图像特征提取技术的进步,可以使用Anchor Box在图像的不同位置生成边框,并且能够方便的提取边框对应区域的特征,用于边框位置的回归。
一个Anchor Box可以由:边框的纵横比和边框的面积(尺度)来定义,相当于一系列预设边框的生成规则,根据Anchor Box,可以在图像的任意位置,生成一系列的边框。
由于Anchor box 通常是以CNN提取到的Feature Map 的点为中心位置,生成边框,所以一个Anchor box不需要指定中心位置。
总结来说就是:在一幅图像中,要检测的目标可能出现在图像的任意位置,并且目标可能是任意的大小和任意形状。
- 使用CNN提取的Feature Map的点,来定位目标的位置。
- 使用Anchor box的Scale来表示目标的大小
- 使用Anchor box的Aspect Ratio来表示目标的形状
常用的Anchor Box定义
- Faster R-CNN 定义三组纵横比
ratio = [0.5,1,2]和三种尺度scale = [8,16,32],可以组合处9种不同的形状和大小的边框。 - YOLO V2 V3 则不是使用预设的纵横比和尺度的组合,而是使用
k-means聚类的方法,从训练集中学习得到不同的Anchor - SSD 固定设置了5种不同的纵横比
ratio=[1,2,3,1/2,1/3],由于使用了多尺度的特征,对于每种尺度只有一个固定的scale
Anchor 的意义
Anchor Box的生成是以CNN网络最后生成的Feature Map上的点为中心的(映射回原图的坐标),以Faster R-CNN为例,使用VGG网络对对输入的图像下采样了16倍,也就是Feature Map上的一个点对应于输入图像上的一个\(16 \times 16\)的正方形区域(感受野)。根据预定义的Anchor,Feature Map上的一点为中心 就可以在原图上生成9种不同形状不同大小的边框,如下图:
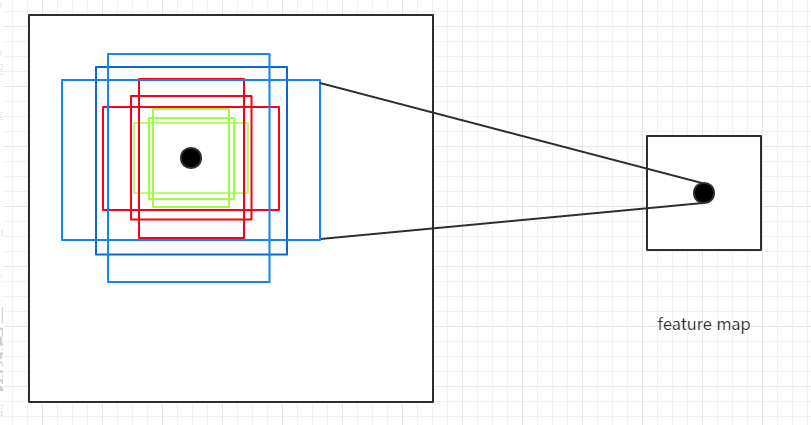
从上图也可以看出为什么需要Anchor。根据CNN的感受野,一个Feature Map上的点对应于原图的\(16 \times 16\)的正方形区域,仅仅利用该区域的边框进行目标定位,其精度无疑会很差,甚至根本“框”不到目标。 而加入了Anchor后,一个Feature Map上的点可以生成9中不同形状不同大小的框,这样“框”住目标的概率就会很大,就大大的提高了检查的召回率;再通过后续的网络对这些边框进行调整,其精度也能大大的提高。
Faster R-CNN的Anchor Box
Faster R-CNN中的Anchor有3种不同的尺度\({128\times 128,256 \times 256,512 \times 512}\),3种形状也就是不同的长宽比\(W:H = {1:1,1:2,2:1}\),这样Feature Map中的点就可以组合出来9个不同形状不同尺度的Anchor Box。
Faster R-CNN进行Anchor Box生成的Feature Map是原图下采样16倍得到的,这样不同的长宽比实际上是将面积为\(16 \times 16\)的区域,拉伸为不同的形状,如下图:
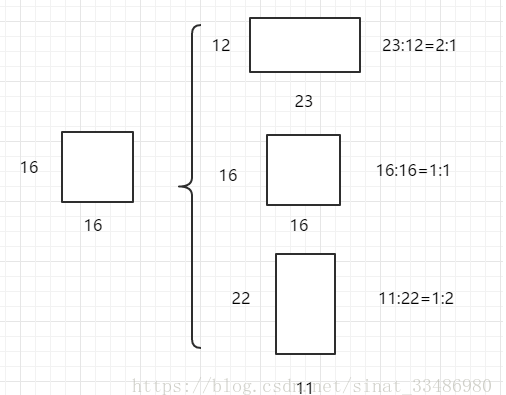
不同的ratio生成的边框的面积是相同的,具有相同的大小。三种不同的面积(尺度),实际上是将上述面积为\(16 \times 16\)的区域进行放大或者缩小。
\(128 \times 128\)是\(16 \times 16\)放大8倍;\(256 \times 256\)是放大16倍;\(512 \times 512\)则是放大32倍。如下图:
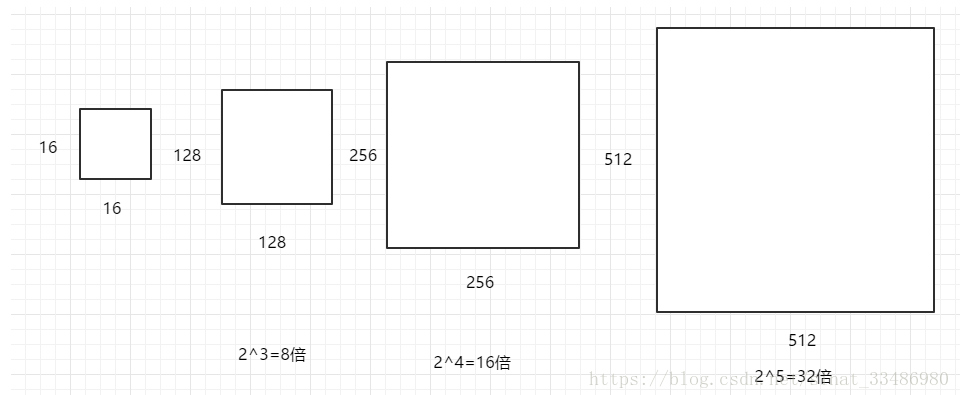
上图引用自: https://blog.csdn.net/sinat_33486980/article/details/81099093
Anchor 计算
这里先计算每个Anchor的长和宽,至于其中心位置是Feature Map的每个点在原图上的映射,是固定,可以先不考虑。
从上面可以知道,任意的形状和大小的Anchor的宽和高都可以从最基础的宽和高\(16 \times 16\)变换而来。首先看三种ratio的变换。
设矩形框的面积\(s = 16 \times 16\),矩形框的宽\(w\),高为\(h\),则有:
所以最终得到
不同尺度的是在基础的尺度上的缩放,设尺度为\(scale\),则缩放后的面积为\(scale \cdot s\)。当然也可以从宽高的缩放比例来看,基础的面积为\(16 \times 16\),则尺度为$128 \times 128 \(则是相当于长宽高各放大了3倍。只是要注意数值的变换,从面积的角度看缩放因子为\)scale_{area} = (128 \times 128) / (16 \times 16)$,从宽高看的话,缩放因子为宽高的比值。
通过上面的计算,实际只是得到了9种不同的可以放在任意位置矩形框(因为矩形框的中心位置还没有确定)。 边框的中心位置,是将Feature map上的点映射回原图得到的,Feature map任一点对应的是原图的一块正方形区域,其中心位置就落在改区域的中心位置。以
以Feature map上\((0,0)\)点为例,其对应于原图的\((0,0,15,15)\)(左上角坐标,右下角坐标),则在改点生成Anchor box的中心点就是原图的\((7.5,7.5)\),Feature Map上其余位置在原图对应的中心点在此基础上进行平移即可得到。例如Feature Map上(0,0)的点在原图上对应区域的的中心点为(7.5,7.5),则(0,1)对应的中心点为(7.5,7.5 + 16),依次类推(x,y)对应的中心点为(x * 16 + 7.5 ,y * 16 + 7.5)。
如果是以(左上角坐标,右下角坐标)表示的矩形框,则将(左上角坐标,右下角坐标)平移相应的距离即可。
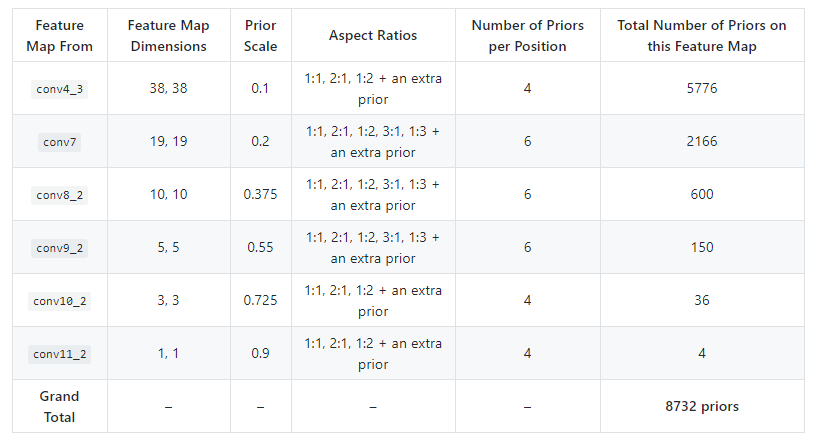
SSD的 default Prior box
SSD的Prior Box的三要素:
-
Feature Map
为了能够更好的检测小目标,SSD使用不同层的Feature Map(不同尺度)。具体就是:\(38 \times 38,19 \ times 19,10 \times 10 ,5 \times 5,3 \times 3,1\times 1\) -
Scale
- 假设一个prior box的scale为\(s\),这就表示该prior box的面积是以\(s\)为边长的正方形的面积。
- scale的值是以相对于原始图像的边长比例来设定的。 例如$ s= 0.1\(,则表示实际\)s = 0.1 \cdot W_src$。
- SSD中使用了多个不同尺度的Feature Map。针对不同的Feature Map,设定不同的尺度。除了第一个Feature Map(\(38 \times 38\))的\(scale = 0.1\),剩余各层的按照Feature Map的尺度从大大小排列,其scale按照下面的公式增大
\[scale = s_{min} + \frac{s_{max} - s_{min}}{ m - 1} \cdot (k - 1), \]其中,\(m = 5 ,k = 1,2,3,4,5,s_{min} = 0.2,s_{max} = 0.9\)
可以看到,尺度大的Feature Map其scale较小,利于小目标的检测。 -
Aspect Ratio
每个尺度的Feature Map的prior box都有\((1:1,2:1,1:2)\)这三种aspect ratio。其中,\(19 \times 19,10 \times 10,5 \times 5\)这三个Feature Map则有额外的两个aspect ratio \((1:3,3:1)\)。 -
附加的prior box
针对所有的Feature Map 都有一个附加的 prior box,其aspect ratio为\(1:1\),其尺度为当前Feature Map 和下一个Feature Map的几何平均值,也就是\(\sqrt(scale_k \cdot scale_{k+1})\)
SSD的Prior box的总结如下:
YOLO 的Anchor Box
YOLO v2,v3的Anchor Box 的大小和形状是通过对训练数据的聚类得到的。 作者发现如果采用标准的k-means(即用欧式距离来衡量差异),在box的尺寸比较大的时候其误差也更大,而我们希望的是误差和box的尺寸没有太大关系。这里的意思是不能直接使用\(x,y,w,h\)这样的四维数据来聚类,因为框的大小不一样,这样大的定位框的误差可能更大,小的定位框误差会小,这样不均衡,很难判断聚类效果的好坏。
所以通过IOU定义了如下的距离函数,使得误差和box的大小无关:
官方的 V2,V3的Anchor
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828 // yolo v2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 // yolo v3
需要注意的是 anchor计算的尺度问题。 yolo v2的是相对最后一个Feature Map \((13 \times 13)\)来的,yolo v3则是相对于原输入图像的\(416 \times 416\)的。 这也是在计算目标检测中,边框计算中需要注意的问题,就是计算的边框究竟在相对于那个尺度得出的。
So YOLOv2 I made some design choice errors, I made the anchor box size be relative to the feature size in the last layer. Since the network was downsampling by 32 this means it was relative to 32 pixels so an anchor of 9x9 was actually 288px x 288px.
In YOLOv3 anchor sizes are actual pixel values. this simplifies a lot of stuff and was only a little bit harder to implement
总结
Anchor box 实际上就是用来生成一系列先验框的规则,其生成的先验框有以下三部分构成:
- CNN提取的Feature Map的点,来定位边框的位置。
- Anchor box的Scale来表示边框的大小
- Anchor box的Aspect Ratio来表示边框的形状
在one stage中的目标检测,是直接在最后提取的Feature map上使用预定义的Anchor生成一系列的边框,最后再对这些边框进行回归。
而 two stage中的,提取的Feature map上使用预定义的Anchor生成一系列的边框,这些边框经过RPN网络,生成一些的ROI区域。将提取到的ROI输入到后续网络中进行边框回归,这就比one stage的方法多了一步,所以精度和耗时上都有所增加。
最后,在使用Anchor生成边框的时候,要注意其定义在那种尺度上,最好将生成的边框使用归一化的坐标表示,在使用的时候,乘以原图像的尺度就行了。

