

权值初始化 - Xavier和MSRA方法
设计好神经网络结构以及loss function 后,训练神经网络的步骤如下:
- 初始化权值参数
- 选择一个合适的梯度下降算法(例如:Adam,RMSprop等)
- 重复下面的迭代过程:
- 输入的正向传播
- 计算loss function 的值
- 反向传播,计算loss function 相对于权值参数的梯度值
- 根据选择的梯度下降算法,使用梯度值更新每个权值参数
初始化
神经网络的训练过程是一个迭代的过程,俗话说:好的开始就是成功的一半,所以的权值参数的初始化的值对网络最终的训练结果有很大的影响。 过大或者过小的初始值,对网络收敛的结果都会有不好的结果。
所有的参数初始化为0或者相同的常数
最简单的初始化方法就是将权值参数全部初始化为0或者一个常数,但是使用这种方法会导致网络中所有的神经元学习到的是相同的特征。
假设神经网络中只有一个有2个神经元的隐藏层,现在将偏置参数初始化为:\(bias = 0\),权值矩阵初始化为一个常数\(\alpha\)。 网络的输入为\((x_1,x_2)\),隐藏层使用的激活函数为\(ReLU\),则隐藏层的每个神经元的输出都是\(relu(\alpha x_1 + \alpha x_2)\)。 这就导致,对于loss function的值来说,两个神经元的影响是一样的,在反向传播的过程中对应参数的梯度值也是一样,也就说在训练的过程中,两个神经元的参数一直保持一致,其学习到的特征也就一样,相当于整个网络只有一个神经元。
过大或者过小的初始化
如果权值的初始值过大,则会导致梯度爆炸,使得网络不收敛;过小的权值初始值,则会导致梯度消失,会导致网络收敛缓慢或者收敛到局部极小值。
如果权值的初始值过大,则loss function相对于权值参数的梯度值很大,每次利用梯度下降更新参数的时,参数更新的幅度也会很大,这就导致loss function的值在其最小值附近震荡。
而过小的初值值则相反,loss关于权值参数的梯度很小,每次更新参数时,更新的幅度也很小,着就会导致loss的收敛很缓慢,或者在收敛到最小值前在某个局部的极小值收敛了。
Xavier初始化
Xavier初始化,由Xavier Glorot 在2010年的论文 Understanding the difficulty of training deep feedforward neural networks 提出。
为了避免梯度爆炸或者梯度消失,有两个经验性的准则:
- 每一层神经元激活值的均值要保持为0
- 每一层激活的方差应该保持不变。
在正向传播时,每层的激活值的方差保持不变;在反向传播时,每层的梯度值的方差保持不变。
基于上述的准则,初始的权值参数\(W^l\)(\(l\)为网络的第\(l\)层)要符合以下公式
其中\(n^{n-1}\)是第\(l-1\)层的神经元的个数。 也就是说,初始的权值\(w\)可以从均值\(\mu = 0\),方差为\(\sigma^{2}=\frac{1}{n ^{l-1}}\)的正态分布中随机选取。
正向传播的推导过程:
推导过程中的三个假设:
- 权值矩阵\(w\)是独立同分布的,且其均值为0
- 每一层的输入\(a\)是独立同分布的,且均值也为0
- \(w\)和\(a\)是相互独立的
设\(L\)层的权值矩阵为\(W\),偏置为\(b\),其输入为\(a\)
则
有统计概率的知识可得到:(第一个假设\(W\),\(x\)相互独立)
由第一第二个假设可知:\(l\)层输入的均值为0,权值参数\(W\)的均值也为0,即:\(E(x_i) = 0,E(w_i) = 0\)则有:\(Var(w_ix_i) = Var(w_i)Var(x_i)\),即
设权值矩阵\(W\)独立同分布的则有\(Var(w^l) = Var(w_{11}^l) = \cdots = Var(W_{ij}^l)\),输入\(a^{l-1}\)也是独立同分布的有:\(Var(a^{l-1}) = Var(a_1^{l-1}) = \cdots = Var(a_i^{l-1})\)
则有
这里得出了第\(l\)层输入到激活函数中的值\(z^l\)与其输入\(a^{l-1}\)(也就是上一层输出的激活值)的方差之间的关系。但我们假设的是每一层输出的激活值的方差保持不变,也就是说要得到\(Var(a^l)\)和\(Var(a^{l-1})\)之间的关系。
设\(f\)为激活函数,则有
Xavier假设的激活函数为\(tanh\),其函数曲线为
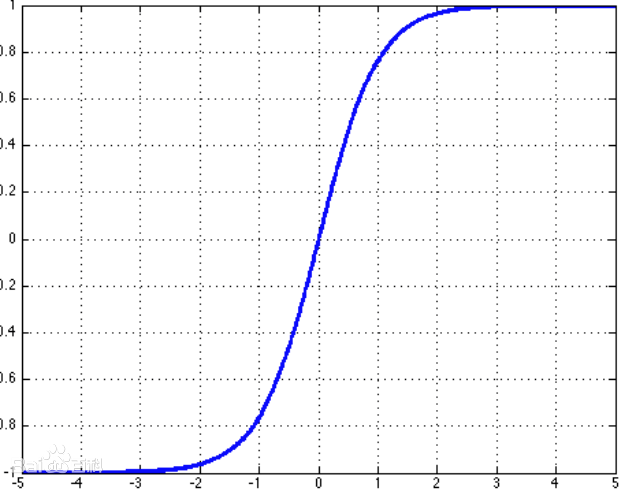
其中间的部分可以近似线性(linear regime),而在训练的过程就要保证激活值是落在这个线性状体的区间内的,不然就会出现梯度饱和的情况。所以,这里可以近似的有
也就是说:
要让每一层的激活值的方差保持不变,则有\(Var(a^l) = Var(a^{l-1})\),既有
通常输入神经元和输出神经元的个数不一定总是相同的,这里取两者的均值
限制
对于权值的初始化,Glorot提出两个准则:
- 各个层激活值的方差保持不变(正向传播)
- 各个层的梯度值的方差保持不变(反向传播)
在Xavier的推导的过程中,做了以下假设:
- 权值矩阵\(w\)是独立同分布的,且其均值为0
- 每一层的输入\(a\)是独立同分布的,且均值也为0
- \(w\)和\(a\)是相互独立的
但是,对Xavier限制最大的则是,其是基于tanh作为激活函数的。
上述公式的详细推导过程可参见 http://www.deeplearning.ai/ai-notes/initialization/ 。
Xavier的初始化有个假设条件,激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign。
均匀分布
通过上面的推导,得出权值矩阵的均值为:0,方差为
$[a,b] \(间的均匀分布的方差为\) var = \frac{(b-a)^2}{12}\(,设\)F_{in}\(为输入的神经元个数,\)F_{out}$为输出的神经元个数
则权值参数从分布
正态分布
基于正态分布的Xavier初始化从均值为0,方差为\(\sqrt{\frac{2}{F_{in} + F_{out}}}\)的正态分布中随机选取。
He初始化(MSRA)
由 Kaiming 在论文Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification提出,由于Xavier的假设条件是激活函数是关于0对称的,而常用的ReLU激活函数并不能满足该条件。
只考虑输入的个数,MSRA的初始化是一个均值为0,方差为\(\sqrt{\frac{2}{F_{in}}}\)的高斯分布
正向传播的推导过程:
其前半部分的推导和Xavider类似
对于第\(l\)层,有如下公式 :
其中,\(x_l\)为当前层的输入,也是上一层的激活后的输出值。\(y_l\)为当前层输入到激活函数的值,\(w_l\)和\(b_l\)为权值和偏置。其中\(x_l\)以及\(w_l\)都是独立同分布的,(和Xavier相同的假设条件),则有:
设\(w_l\)的均值为0,即\(E(w_l) = 0\),则有:
这里有和Xavier一个很大的不同是,这里没有假设输入的值的均值为0。这是由于,使用ReLU的激活函数,\(x_l = max(0,y_{l-1})\),每层输出的值不可能均值为0。
上面最终得到
初始化时通常设,\(w\)的均值为0,偏置\(b = 0\),以及\(w\)和\(x\)是相互独立的,则有
也就是说,\(y_l\)的均值为0。
再假设\(w\)是关于0对称分布的(均匀分布,高斯分布都符合),则可以得到\(y_l\)在0附近也是对称分布的。
这样,使用ReLU作为激活函数,则有
由于只有当\(y_{l-1} > 0\)的部分,\(x_l\)才有值,且\(y_l\)在0附近也是对称分布的,则可以得到
将得到的\(\operatorname{E}(x_l^2) = \frac{1}{2}\operatorname{Var}(y_{l-1})\),带入到 $\operatorname{Var}(y_l) = n_{l} \operatorname{Var}(w_l) \cdot E(x_l^2) $ 则可以得到
将所有层的方差累加到一起有:
为了是每一层的方差保持不变,则有:
也即得到 权值矩阵的方差应该是
和Xavier的方法,也可以使用正态分布或者均匀分布来取得初始的权值矩阵的值。
正态分布
均匀分布
总结及使用的概率公式
正确的初始化方法应该避免指数级地减小或放大输入值的大小,防止梯度“饱和”。 Glorot提出两个准则:
- 各个层激活值的方差保持不变(正向传播)
- 各个层的梯度值的方差保持不变(反向传播)
通常初始的权值矩阵的均值为0.
这这些条件的基础上,Glorot 使用\(tanh\)作为激活函数,并假设输入值的均值为0,提出了Xavier初始化的方法。
而Kaiming使用ReLU作为激活函数,就无法满足数值的均值为0的条件,因此使用Xavier来初始化ReLU作为激活函数的网络,效果也就不是那么理想。其提出了MSRA的初始化方法,来解决该问题。
附
推导时使用的概率公式:
如果\(E(y) = 0\),则有:
如果\(x,y\)是相互独立的,则有
本文只推导了正向传播的过程,对于反向传播的推导可参考原始论文

