


卷积神经网络之VGG
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的).论文下载 Very Deep Convolutional Networks for Large-Scale Image Recognition。论文主要针对卷积神经网络的深度对大规模图像集识别精度的影响,主要贡献是使用很小的卷积核(\(3\times3\))构建各种深度的卷积神经网络结构,并对这些网络结构进行了评估,最终证明16-19层的网络深度,能够取得较好的识别精度。 这也就是常用来提取图像特征的VGG-16和VGG-19。
VGG可以看成是加深版的AlexNet,整个网络由卷积层和全连接层叠加而成,和AlexNet不同的是,VGG中使用的都是小尺寸的卷积核(\(3\times3\))。
VGG的特点
- 结构简洁,如下图VGG-19的网络结构
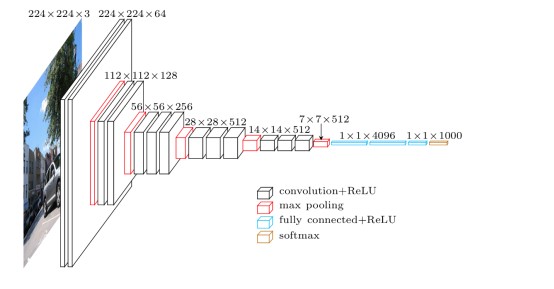
对比,前文介绍的AlexNet的网络结构图,是不是有种赏心悦目的感觉。整个结构只有\(3\times3\)的卷积层,连续的卷积层后使用池化层隔开。虽然层数很多,但是很简洁。
- 小卷积核和连续的卷积层
VGG中使用的都是\(3\times3\)卷积核,并且使用了连续多个卷积层。这样做的好处:- 使用连续的的多个小卷积核(\(3\times3\)),来代替一个大的卷积核(例如(\(5\times5\))。
使用小的卷积核的问题是,其感受野必然变小。所以,VGG中就使用连续的\(3\times3\)卷积核,来增大感受野。VGG认为2个连续的\(3\times3\)卷积核能够替代一个\(5\times5\)卷积核,三个连续的\(3\times3\)能够代替一个\(7\times7\)。
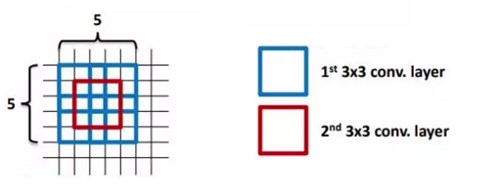
- 小卷积核的参数较少。3个\(3\times3\)的卷积核参数为\(3 \times 3 \times = 27\),而一个\(7\times7\)的卷积核参数为\(7\times7 = 49\)
- 由于每个卷积层都有一个非线性的激活函数,多个卷积层增加了非线性映射。
- 使用连续的的多个小卷积核(\(3\times3\)),来代替一个大的卷积核(例如(\(5\times5\))。
- 小池化核,使用的是\(2\times 2\)
- 通道数更多,特征度更宽
每个通道代表着一个FeatureMap,更多的通道数表示更丰富的图像特征。VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。 - 层数更深
使用连续的小卷积核代替大的卷积核,网络的深度更深,并且对边缘进行填充,卷积的过程并不会降低图像尺寸。仅使用小的池化单元,降低图像的尺寸。 - 全连接转卷积(测试阶段)
这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
如本节第一个图所示,输入图像是224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
全连接转卷积的替换过程如下:
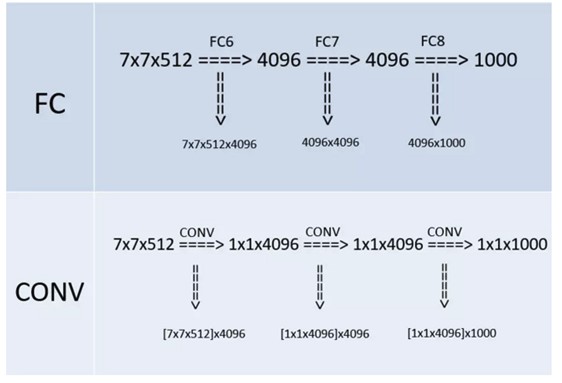
例如\(7 \times 7 \times 512\)的层要跟4096个神经元的层做全连接,则替换为对\(7 \times 7 \times 512\)的层作通道数为4096、卷积核为\(1 \times 1\)卷积。
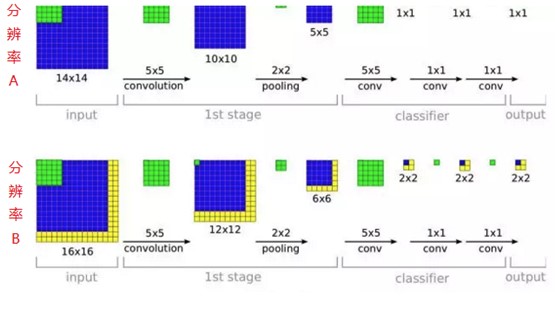
这个“全连接转卷积”的思路是VGG作者参考了OverFeat的工作思路,例如下图是OverFeat将全连接换成卷积后,则可以来处理任意分辨率(在整张图)上计算卷积,这就是无需对原图做重新缩放处理的优势。
VGG网络结构
VGG网络相比AlexNet层数多了不少,但是其结构却简单不少。
- VGG的输入为\(224 \times 224 \times 3\)的图像
- 对图像做均值预处理,每个像素中减去在训练集上计算的RGB均值。
- 网络使用连续的小卷积核(\(3 \times 3\))做连续卷积,卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变。
- 连续的卷积层会接着一个池化层,降低图像的分辨率。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。
- 卷积层后,接着的是3个全连接层,前两个每个都有4096个通道,第三是输出层输出1000个分类。
- 所有的隐藏层的激活函数都使用的是ReLU
- 使用\(1\times1\)的卷积核,为了添加非线性激活函数的个数,而且不影响卷积层的感受野。
- 没有使用局部归一化,作者发现局部归一化并不能提高网络的性能。
VGG论文主要是研究网络的深度对其分类精度的影响,所以按照上面的描述设计规则,作者实验的了不同深度的网络结构
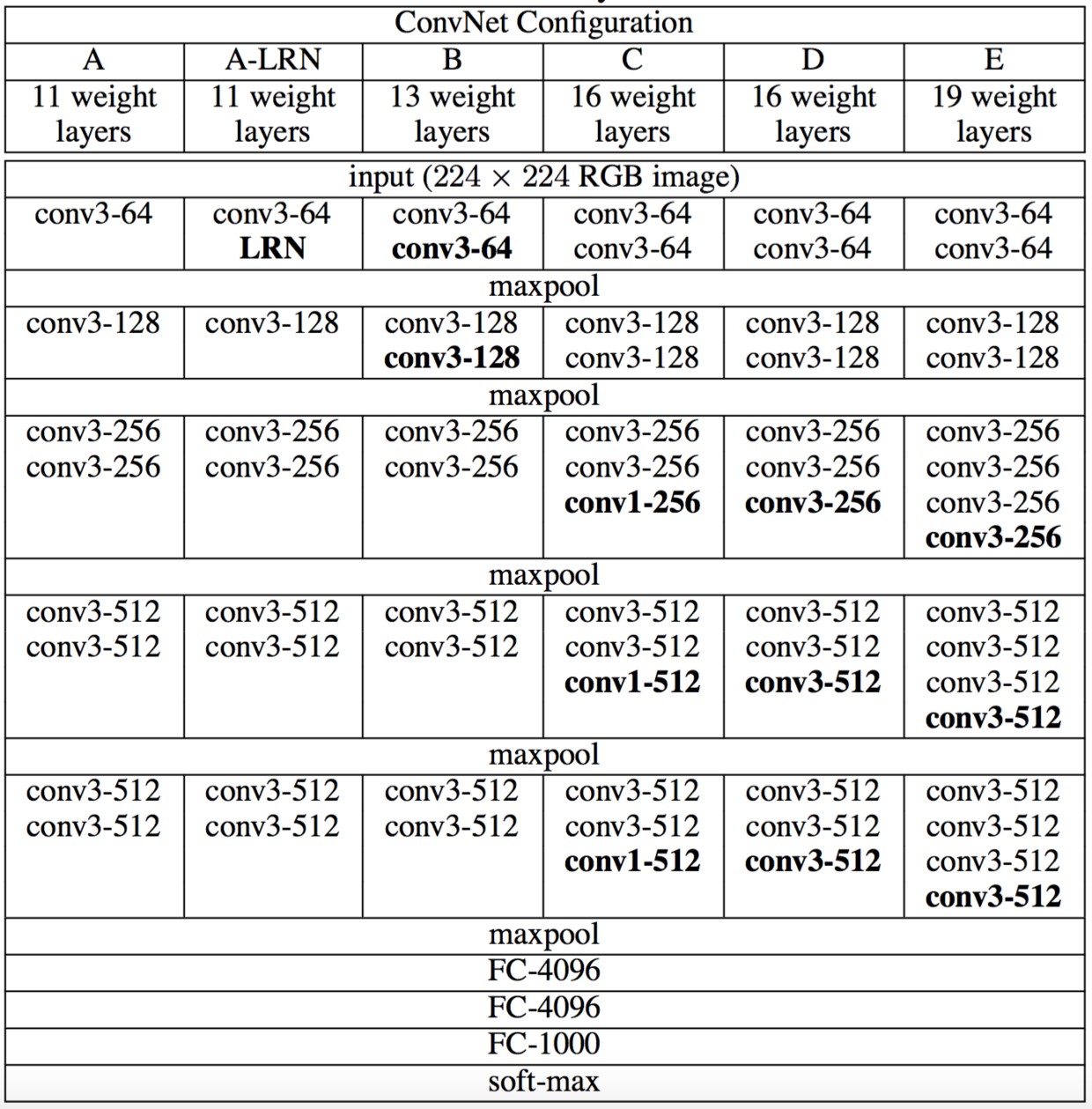
所有网络结构都遵从上面提到的设计规则,并且仅是深度不同,也就是卷积层的个数不同:从网络A中的11个加权层(8个卷积层和3个FC层)到网络E中的19个加权层(16个卷积层和3个FC层)。卷积层的宽度(通道数)相当小,从第一层中的64开始,然后在每个最大池化层之后增加2倍,直到达到512。
上图给出了各个深度的卷积层使用的卷积核大小以及通道的个数。最后的D,E网络就是大名鼎鼎的VGG-16和VGG-19了。
AlexNet仅仅只有8层,其可训练的参数就达到了60M,VGG系列的参数就更恐怖了,如下图(单位是百万)

由于参数大多数集中在后面三个全连接层,所以虽然网络的深度不同,全连接层确实相同的,其参数区别倒不是特别的大。
VGG训练与测试
论文首先将训练图像缩放到最小边长度的方形,设缩放后的训练图像的尺寸为\(S \times S\)。网络训练时对训练图像进行随机裁剪,裁剪尺寸为网络的输入尺寸\(224 \times 224\)。如果\(S =224\),则输入网络的图像就是整个训练图像;如果\(S > 224\),则随机裁剪训练图像包含目标的部分。
对于训练集图像的尺寸设置,论文中使用了两种方法:
- 固定尺寸训练,设置\(S = 256\)和\(S = 384\)
- 多尺度训练,每个训练图像从一定范围内\([S_{min},S_{max}],(S_{min}=256,S_{max}=512)\)进行随机采样。由于图像中的目标可能具有不同的大小,因此在训练期间考虑到这一点是有益的。这也可以看作是通过尺度抖动进行训练集增强,其中单个模型被训练在一定尺度范围内识别对象。
网络性能评估
-
单尺度评估,测试图像固定尺度。结果如下表
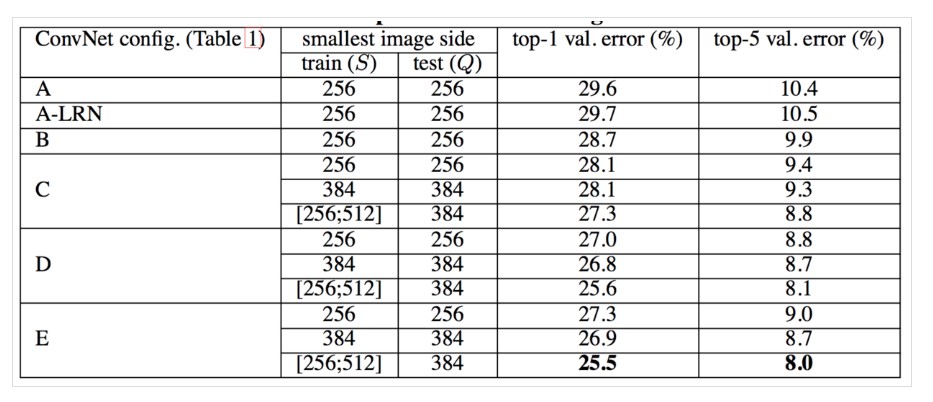
通过评估结果,可以看出:- 局部归一化(A-LRN)网络,对网络A的结果并没有很大的提升。
- 网络的性能随着网络的加深而提高。应该注意到B,C,D这个网络的性能。C网络好于B网络,说明额外添加的非线性激活函数,确实是有好处的;但是,D网络好于C网络,这说明也可以使用非平凡的感受野( non-trivial receptive fields)来捕获更多的信息更有用。
- 当网络层数达到19层时,使用VGG架构的错误率就不再随着层数加深而提高了。更深的网络应该需要更多的数据集。
- 论文还将网络B与具有5×5卷积层的浅层网络进行了比较,浅层网络可以通过用单个5×5卷积层替换B中每对3×3卷积层得到。测量的浅层网络top-1错误率比网络B的top-1错误率(在中心裁剪图像上)高7%,这证实了具有小滤波器的深层网络优于具有较大滤波器的浅层网络。
- 训练时的尺寸抖动(训练图像大小\(S \in [256,512]\))得到的结果好于固定尺寸,这证实了通过尺度抖动进行的训练集增强确实有助于捕获多尺度图像统计。
-
多尺度评估,测试图像的尺度抖动对性能的影响
对同一张测试图像,将其缩放到不同的尺寸进行测试,然后取这几个测试结果的平均值,作为最终的结果(有点像集成学习,所不同的是,这里是测试图像的尺寸不同)。使用了三种尺寸的测试图像:\(Q\)表示测试图像,\(S\)表示训练是图像尺寸:\(Q = S - 32\),\(Q = S + 32\),前面两种是针对训练图像是固定大小的,对于训练时图像尺寸在一定范围内抖动的,则可以使用更大的测试图像尺寸。\(Q = \{S_{min},0.5(S_{min} + S_{max}),S_{max}\}\).
评估结果如下:
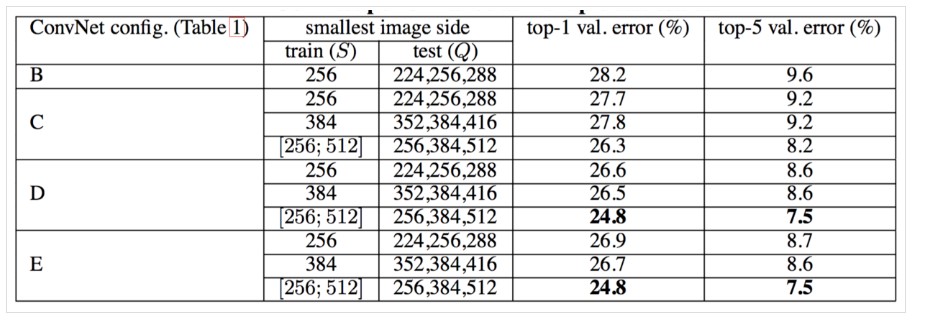
评估结果表明,训练图像尺度抖动优于使用固定最小边S。 -
稠密和多裁剪图像评估
Dense(密集评估),即指全连接层替换为卷积层(第一FC层转换到7×7卷积层,最后两个FC层转换到1×1卷积层),最后得出一个预测的score map,再对结果求平均。
multi-crop,即对图像进行多样本的随机裁剪,将得到多张裁剪得到的图像输入到网络中,最终对所有结果平均
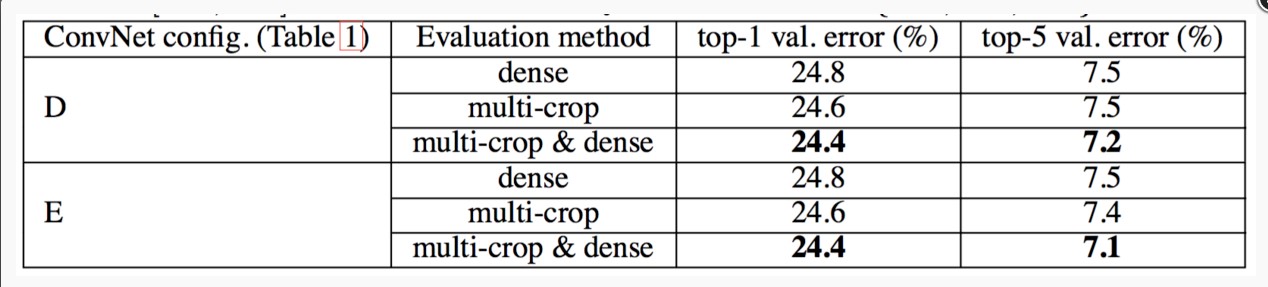
从上图可以看出,多裁剪的结果是好于密集估计的。而且这两种方法确实是互补的,因为它们的组合优于其中的每一种。
由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的图像内容信息。
评估结论
- 在训练时,可以使用多尺度抖动的训练图像,其精度好于固定尺寸的训练集。
- 测试时,使用多裁剪和密集评估(卷积层替换全连接层)像结合的方法
Keras实现
依照VGG的设计原则,只使用小尺寸的\(3\times3\)卷积核以及\(2 \times 2\)的池化单元,实现一个小型的网络模型。
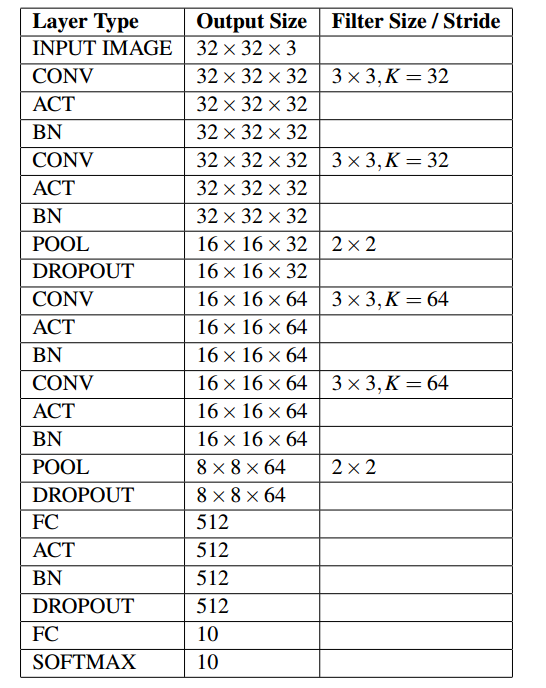
class MiniVGGNet:
@staticmethod
def build(width,height,depth,classes):
model = Sequential()
inputShape = (height,width,depth)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (depth,height,width)
chanDim = 1
model.add(Conv2D(32,(3,3),padding="same",input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(32,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(64,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64,(3,3),padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
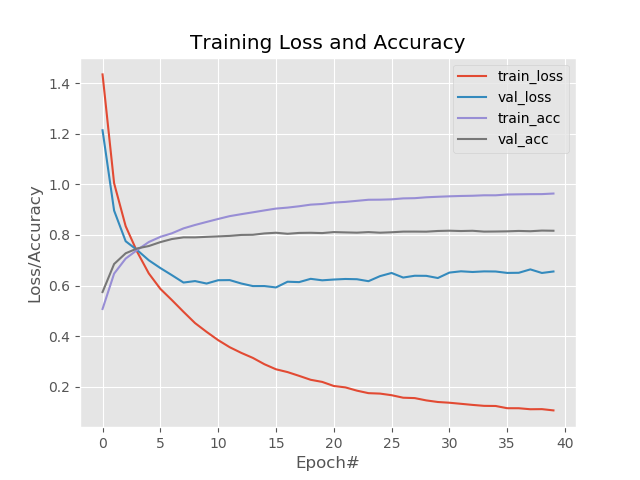
最终输出10分类,应用于CIFAR10,表现如下:
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。


【推荐】中国电信天翼云云端翼购节,2核2G云服务器一口价38元/年
【推荐】博客园携手 AI 驱动开发工具商 Chat2DB 推出联合终身会员
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步