SSD网络模型之DetectionOutput算子
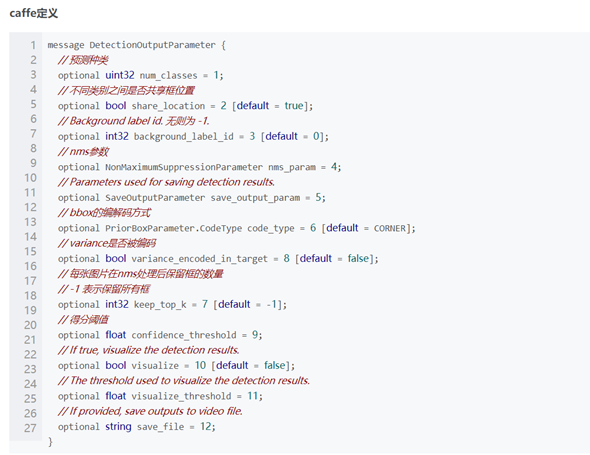
DetectionOutput算子
本文基本结构:首先介绍detection output 这一层的基本理解,之后给出ssd所有代码的详细注释,最后给出caffe中该层各个参数的定义和默认值。
detection out layer是ssd网络最后一层,用于选框整合预、预选框偏移以及得分三项结果,最终输出满足条件的目标检测框、目标的label和得分。
输入方面,mbox_priorbox是网络各个priorbox层输出concat后的结果(priorbox解析点这里),相当于把所有预选框放到一起;mbox_loc是在预选框的基础上的偏移量;mbox_conf_flatten就是每个类别在各个框上的得分。
输出大小为[1, 1, x, 7],其中x是最后保留的框的个数,最后一维存放的数据为: [image_id, label, confidence, xmin, ymin, xmax, ymax]
计算思路:
1)对bottom层的location、confidence和priorbox进行解析,放到vector中
2)对每个priorbox进行解码。所谓解码其实就是整合输入层。前面说到过了,输出需要给出每个目标的检测框,但是输入是预选框和偏移量,这里要做的就是计算出最终的检测框。解码需要考虑priorbox编码方式,共三种情况。
假设检测框用b表示(存储内容:b_xmin, b_ymin, b_xmax, b_ymax),预选框用p表示(存储内容:p_xmin, p_ymin, p_xmax, p_ymax),偏移量用t表示(存储内容:t_x, t_y, t_height, t_width)。
b和p的宽高分别用x和y的最大最小值减一下得到,中心点的值用最大最小值相加除以2得到。
那么在每种类型中,编码公式分别为:

解码时求取b的各个值就可以。如果需要添加variance的值,将t与variance相乘即可。
以center_size解码方式为例:

据此分别计算出b_xmin, b_ymin, b_xmax, b_ymax即可。详细可参见代码
3) Non-Maximum Suppression非极大值抑制
检测算法给出的box往往有很多,如下图所示,多个检测框其实框出的是一个目标,nms就是一个目标保留一个最优框。抑制的过程是一个迭代-遍历-消除的过程。
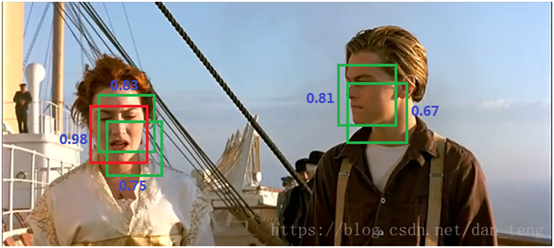
给定处理前的集合:预选结合,处理后的集合keep集合
首先,将预选集合所有框按照得分高低进行排序,选中得分最高的框,从预选集合移出放到keep集合中;
接下来进行迭代:
*从当前预选集合移出得分最高的框,用它与keep集合每个框计算交并比:
*超过阈值说明二者重复很多,框住的应该是同一个东西,不放到keep集合中;
*如果与keep集合中每个框交并比都小于阈值,说明当前框框住的是一个新目标,应该放到keep中。
迭代下去,直到预选集合为空,那么keep集合中留下的就是检出的所有目标的检测框。
jaccard overlap
这里补充介绍一下ssd网络中的jaccard overlap。
jaccard overlap其实就是交并比,简单说起来就是两个检测框重合的面积(相交的部分)除以两个检测框并在一起的面积(面积之和减去重合部分),用公式表示为
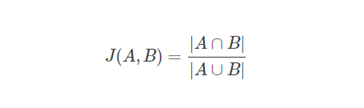
J为0说明两个框一点没有重合,为1说明完全重合
4)按照输出大小要求输出结果