集合
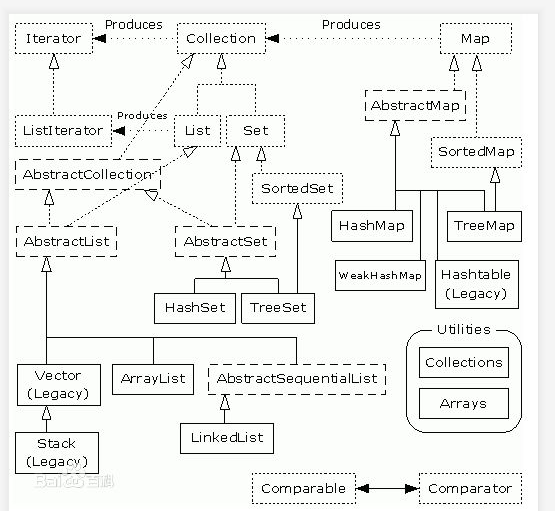
集合
集合一般常用的集合为:
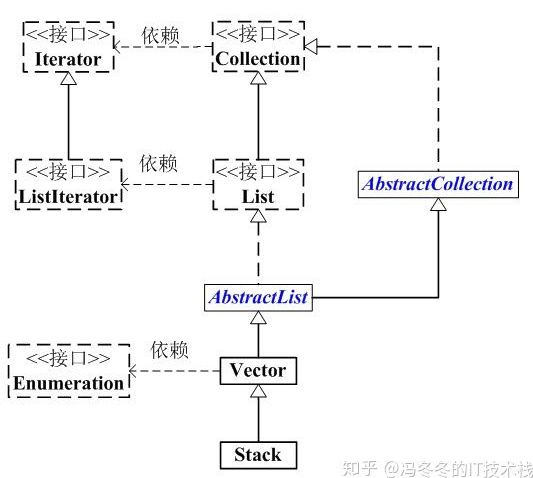
List是接口,ArrayList与LinkedList都是一个实现了该接口的类,可以被实例化
List (中文:列表),这种集合底层是数组;类似于乾坤袋,故而他应该有下标,并且元素在集合中的排列是有序的,就像数组一样,第一个位置放置的元素,第二个位置放置的元素,第三个位置放置的元素.........,一般初始数组容量为10,每次容量使用完以后,会new一个新数组,再将原数组copy到新数组,新数组的容量是原数组的1.5倍+1;
1、产生对象:
List list=new ArrarList();
List是ArrayList和LinkList的
List<String> list=new ArrarList<>();
<T> 是泛型,是指在这个集合中只能用这个类型,这个类型只能为引用类型,而且只能放这种类型及他的子类,两个<>中的类型一定要一致,因为集合中放的是对象所以基本类型要转换为包装类;
2、增:list.add(object o);
list.add(index,element);------指定下标进行添加,集合中的元素依次后退
例如:
list.add("hahah");
list.add("hahah");
list.add("java");
list.add("java");
3、删:lidt.remove(int index);//删除指定下标的元素
list.remove(object);//删除指定元素
这里如果删除的是需要int数据类型需要转换为Integer包装类否则会被当做下标处理
4、改:list.set(index,object);
5、查:(获取指定元素)list.get(index);也可以根据元素来查找对应的下标,但如果有相同的下标只能找一个的位置比如:第一个或者最后一个。比如:
list.indexOf(a);
在没有用泛型进行限制的情况下,应该用object来接受元素,再用instance来进行判断再来强转,但是最好用泛型
6、获取size:list.siz
7、遍历
这里因为集合集合中什么都可以放,所以是集合里面的元素类型为Object
1、普通for循环
2、用Iterator(迭代器),遍历集合中元素,但不能控制它的下标(步长(i++))
Iterator it=list.iterator;//先获得该容器的迭代器,
while(it.hasNext()){
object tmp=it.next();//next方法取出下一个元素
system.out.prinln(tmp);
}
3、for-each循环:支持操作集合与数组
for(object tmp:list){
system.out.prinln(tmp);
}
}
ArrayList与LinkedList的区别
1、ArrayList的底层是使用数组实现的,所以需要连续的内存;而LinkedList底层是使用双向链表的方式实现的,他并不需要连续的内存,它本身除了数据之外还需要存地址,查询是需要从头开始,效率低
2、ArrayList适用于做大量的访问元素或修改元素,不同步,线程不安全;LinkedList适用于做大量往中间增加或者删除元素
还有Vector与stack,其中ArrayList与Vector方法与实现基本都一样,底层也都是数组的实现。但Vector是线程安全的,效率低下,而ArrayList没有考虑线程安全;
stack是继承自Vector,底层使用数组存储、用来模拟栈的一个java集合。同时也是线程安全的
Set(中文:集)
特点:这个集合存入进去是无序的,不能放重复的数据,最大的特征是没有下标。TreeSet、HashSet是Set接口类的实现。
判断重复的数据要先判断哈希值在用equals来判断内容是否一致,只有两个判断值为true时才是相同,所以要重写equals和hashcode;这有些像判断两个引用类型是否相等,要先判断引用指向相同(位置相同)还要判断内容相同
1、产生对象:
Set<String> set=new HashSet<>();
2、增:set.add(String str);
3、删 set.remove(object);//删除指定元素,Set没有下标所以不能按下标去取
4、改:不能修改----由于没有下标就没有修改相关的方法
5、查:(获取指定元素)不能获取
6、获取size:list.siz
7、遍历
1、用Iterator(迭代器),遍历集合中元素,但不能控制它的下标(步长(i++))
Iterator it=set.iterator;//先获得该容器的迭代器,
while(it.hasNext()){
object tmp=it.next();//next方法取出下一个元素
system.out.prinln(tmp);
}
2、for-each循环:支持操作集合与数组
for(object tmp:set){
system.out.prinln(tmp);
}
}
treeSet是有序,不可重复;.
collection与collections的区别
collection是接口,是所有容器的跟接口,其下有 set 及 list;
collections是工具类,工具类提供的方法都是静态方法,所以没有产生对象的必要,直接用类名进行调用。其中排序,只能对list排序
comparable与Comparator 的区别
comparable是java.lang 包,Comparator是java.until包
调用的方法不同,comparable的方法是compareTo,Comparator的方法是compare
comparable是在内部实现比较,Comparator在外部实现比较
集合Map(中文映射)
特点:集合中的元素是以键值对(键与对应值)的形式存在
键值对(K(key)-V(value))
每一个元素放到容器中还要自己定一个不重复的键值,这相当于自定义一个下标
[添加链接描述](https://blog.csdn.net/winson_jason/article/details/16331097)
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对
HashMap由数组+链表组成的,数组是HashMap的主体;
HashMap的实现原理:
1利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
2存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同,则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
3获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
4理解了以上就不难明白HashMap是如何解决hash冲突的问题,核心就是使用了数组存储方式,然后将冲突的key的对象放入链表中,一旦发现冲突就在链表中做进一步的 对比。
HashMap的整体结构如下
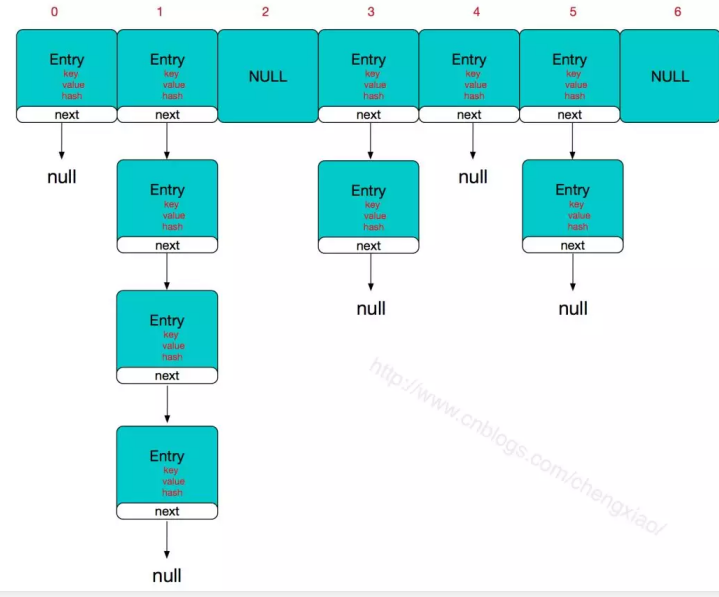
常用类 HashMap
1、产生对象
HashMap<K,v.>stuMap=new HashMap<>();
2、增:stuMap.put(k,v);//注意这里用的是put不是add
3、删 stuMap.remove(k,v);//删除指定元素,不存在不会报错
4、改: stuMap.put(k,v);//该仍然用put
5、查:(获取指定元素)
通过k取值,如果k不存在保护会报错会返回null;
例如:studentBean stu=stuMap.get(k);
6、获取size: stuMap.siz
7、遍历--------Map不能成对比遍历只能k与v分开遍历
Set<String>Keyset= stuMap.Keyset();//得到所有的k,再用foreach进行打印
collection<v>values= stuMap.values();//得到所有的值,再用foreach进行打印
//遍历一个map,从中取得key
Map m = new HashMap();
for (Object o : map.keySet()) {
map.get(o);
}
//.遍历一个map,从中取得value
Map map = new HashMap() ;
Iterator it = map.entrySet().iterator() ;
//Entry 中保存了键值对
while (it.hasNext())
{
Map.Entry entry = (Map.Entry) it.next() ;
Object key = entry.getKey() ;
Object value = entry.getValue() ;
}
TreeMap集合默认会对键进行排序,所以键必须实现自然排序和定制排序中的一种
properties是Map集合中的一个实现类
特点:1、按键值对的形势将元素放入容器但键与值都要是字符串;
2、他是一种数化得持久手段,可以将自己存放的内容放置到文件或从文件中读取内容放置到容器中
遍历
Set<String>Keyset= stuMap.Keyset();//set不能加泛型
collection<>values= stuMap.values();
内部内在外部也能调用,前提是类中是public,
