memory-cnblog
linux虚拟内存系统
进程的虚拟内存
用户区分段:代码段、数据段、堆、共享库、栈
内核区:存放进程信息,PID\程序计数器、打开文件列表、task和mm(描述虚拟内存)结构等
Linux加载进程时(exec系列系统调用)会为该地址空间每个段分配VMA,VMA数据结构(vm_area_struct)会描述该段的虚拟空间的开始地址,结束地址,同时会描述该VMA背后映射的文件名、映射空间所在文件的偏移量和大小(file指针指向它的backend硬盘文件)。但是Linux内核不给该空间分配物理内存,所以此时的页表项是空的。进程分配的虚拟内存只有在实际写入数据时,才会变为物理内存,否则不占用空间,因此虽然进程地址空间位4G,但内存可以同时容纳多个进程。在内存不够时,会发生内存交换,将不常用的进程的内存交换到快速磁盘上,从而腾出空间给其他进程使用。
在翻译虚拟内存时,如果发生缺页,则系统要判断:
- 地址是否合法?处理程序会将地址和mm_struct的mmap成员指针指向的每个区域vm_area_struct的start和end对比,从而判断是否合法,不合法就会报错segment fault
- 内存访问是否合法?读写或者执行权限判断
共享对象不要求虚拟地址相同,但物理地址相同,这是任何进程的读写对其他进程都是可见的,也会反映到磁盘上。
私有对象采用写时复制
从内存角度看系统调用
- fork,创建子进程,包括mm_struct(描述虚拟内存当前状态)、区域结构和页表,分配pid,并把两个进程的页面都标记为只读,每个段标记为写时复制。
- execve,删除用户区,映射私有区域(代码,数据,堆栈),映射共享区域(如标准c库),设置pc。
显式分配器
- malloc,分配至少为参数大小的内存块(包含边界对齐),返回指向该块的指针。malloc可以使用mmap和sbrk(使用内核的brk指针扩展或者收缩堆)等函数来分配内存
- free,释放malloc分配的内存块,参数是malloc返回的指针
内存分配器实现(来自csapp)
-
隐式空闲链表:见csapp 9.9.12,即使用头部和脚部(边界标记)来记录块大小和是否空闲(脚部方便合并),中间用来存储有效载荷,但这样空间浪费,且分配时间是块总数的线性时间。有一种边界标记的优化方法,把上一个块的已分配位存放在当前块中多出来的低位(以书中为例,有3位用于标记,但实际只用了1位),这样上一个块的脚部就可以存放数据。但是空闲块仍然需要脚部,因为合并时要知道上一个块的大小。
-
显式空闲链表:将空闲块组织为显式数据结构--链表,由于空闲块不需要存数据,所以指针可以放在空闲块主体里
-
分离空闲链表:维护多个空闲链表,其中每个链表中的块有大致相等的大小。分配器维护着一个空闲链表数组,每个大小类一个空闲链表,按照大小的升序排列。当分配器需要一个块时,它就搜索相应的空闲链表。如果不能找到合适的块与之匹配,它就搜索下一个链表,以此类推。
- 简单分离存储:每个大小类的空闲链表包含大小相等的块,为了分配一个给定大小的块,我们检査相应的空闲链表。如果链表非空,我们简单地分配其中第一块的全部。空闲块是不会分割以满足分配请求的。如果链表为空,分配器就向操作系统请求一个固定大小的额外内存片(通常是页大小的整数倍), 将这个片分成大小相等的块,并将这些块链接起来形成新的空闲链表。要释放一个块,分配器只要简单将这个块插人到相应的空闲链表的前部。缺点是会带来内部碎片,即分配的块比请求的块大,但是分配器不会将它们分割以满足其他请求。
- 分离适配:每个链表包含潜在的大小不同的块,为了分配一个块,必须确定请求的大小类,并且对适当的空闲链表做首次适配,査找一个合适的块。如果找到了一个,那么就(可选地)分割它,并将剩余的部分插入到适当的空闲链表中。如果找不到合适的块,那么就搜索下一个更大的大小类的空闲链表。如此重复,直到找到一个合适的块。如果空闲链表中没有合适的块,那么就向操作系统请求额外的堆内存,从这个新的堆内存中分配出一个块,将剩余部分放置在适当的大小类中。要释放一个块,执行合并,并将结果放置到相应的空闲链表中。既减少了搜索时间,也提高了内存效率。书上说GNU malloc采用这种方法?
- 伙伴系统:是分离适配的一种特例,其中每个大小类都是2的幂,请求块大小向上舍人到最接近的2的幂。初始时只有一个大块,分配时找到第一个大小足够的块,如果正好相等,就分配;否则递归二分这个块,直到大小相等,而其余半块(伙伴)加入到相应的空闲链表。释放块时,与空闲的伙伴合并,直到遇到已分配的伙伴。优点是合并和分配快,缺点是可能导致内部碎片,但对于特定的分配需求,比如分配空间大小为2的幂,是很好的选择。
-
glibc实现为代表的ptmalloc,隐藏头风格,
下面详细介绍malloc方法
ptmalloc
分配器处在用户程序和内核之间,它响应用户的分配请求,向操作系统申请内存,然后将其返回给用户程序,为了保持高效的分配,分配器一般都会预先分配一块大于用户请求的内存,并通过某种算法管理这块内存,来满足用户的内存分配要求,用户释放掉的内存也并不是立即就返回给操作系统,相反,分配器会管理这些被释放掉的空闲空间,以应对用户以后的内存分配要求。因此,分配器不但要管理已分配的内存块,还需要管理空闲的内存块,分配器会首先在空闲空间中寻找一块合适的内存给用户,在空闲空间中找不到的情况下才分配一块新的内存。
ptmalloc 中使用一个 chunk 来表示内存块,无论是分配的还是空闲的。
chunk 的结构如下:
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
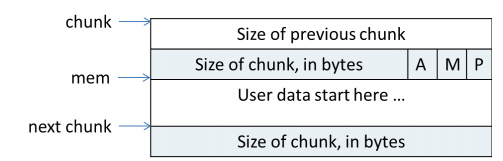
size除了包括大小外,还包括了chuck是否使用等位信息。
- P: PREV_INUSE. P=0则前一个chunk空闲,P=1则前一个chunk被分配。
- M: IS_MMAPPED. M=1为mmap映射区域分配,M=0为heap区域分配
- A: NON_MAIN_ARENA. A=0为主分配区分配,A=1为非主分配区分配。
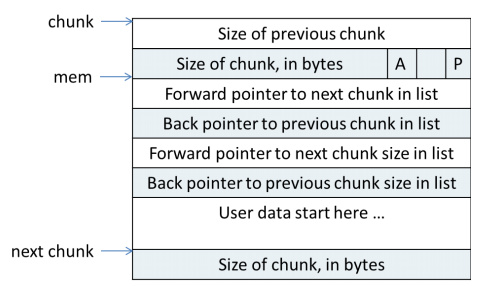
links只有在空闲时有用,被分配时也就不需要了,可以用于存放数据。
fd_nextsize 指向下一个比当前 chunk 大小大的第一个空闲 chunk , bk_nextszie 指向前一个比当前 chunk 大小小的第一个空闲 chunk。被分配时存放数据。加快在large bin中查找最近匹配的空闲chunk
-
使用中的chunk
-
空闲chunk
将相似大小的chunk用双向链表链接起来,这样一个链表被称为一个bin,基于chunk的大小,有下列几种可用bins:
- fast
- unsorted
- small
- large
使用bins数组保存large bin之外的所有bins,共有128个。使用fastbinsY数组保存fast bins,共有10个。
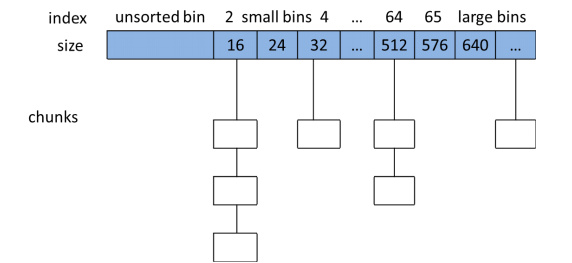
fast bins
对应的bins记录在数组fastbinsY中,共有10个大小不同的bins,每个chunk的大小为 16-64B。最后释放的 chunk 被链接到链表的头部,而申请 chunk 是从链表头部开始查找。fast bins 中的 chunk 不会被合并,当用户释放一块不大于max_fast(默认值64B)的chunk的时候,会默认会被放到fast bins上。,当需要给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会到fast bins上寻找是否有合适的chunk。
unsorted bin
是第1个bin,大小无严格限制。当用户释放的内存大于max_fast或者fast bins合并后的chunk都会首先进入unsorted bin上。在进行 malloc 操作的时候,如果在 fast bins 中没有找到合适的 chunk,则 ptmalloc 会先在 unsorted bin 中查找合适的空闲 chunk,如果没有合适的bin,ptmalloc会将unsorted bin上的chunk放入bins上,然后才查找 bins。
具体遍历过程如下:
如果只有一个chunk并且大于待分配的chunk,则进行切割,并且剩余的chunk继续放入 unsorted bins
如果有大小和待分配chunk相等的,则返回,并从unsorted bins删除;
如果某一chunk大小 属于small bins的范围,则放入small bins的头部;
如果某一chunk大小 属于large bins的范围,则找到合适的位置放入。
small bins
small bin是第2-64个bin,大小为16-512B同一个small bin中的chunk具有相同的大小。两个相邻的small bin中的chunk大小相差8bytes。small bins 中的 chunk 按照最近使用顺序进行排列(FIFO),最后释放的 chunk 被链接到链表的头部,而申请 chunk 是从链表尾部开始查找。可以通过 chunk 的大小计算出它所在的 small bin 的索引,即最优适配,这样就可以快速定位到 small bin。
当空闲的 chunk 被链接到 bin 中的时候,ptmalloc 会把表示该 chunk 是否处于使用中的标志 P 设为 0(这个标志实际上处在下一个 chunk 中),同时 ptmalloc 还会检查它前后的 chunk 是否也是空闲的,如果是的话,ptmalloc 会首先把它们合并为一个大的 chunk,然后将合并后的 chunk 放到 unstored bin 中。
large bins
大小大于等于512字节的chunk被称为large chunk,保存在bins的第65-128个bin中,large bins中的每一个bin分别包含了一个给定范围内的chunk(大小类),其中的chunk按大小递减排序,大小相同则按照最近使用时间排列。使用最优适配,多余部分分割后加入到unsorted bin中。合并方法和small bins相同。
特殊情况
- top chunk。top chunk相当于分配区的顶部空闲内存,当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
- 当top chunk大小比用户所请求大小还大的时候,top chunk会分为两个部分:User chunk(用户请求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成为新的top chunk。
- 当top chunk大小小于用户所请求的大小时,top chunk就通过sbrk(main arena)或mmap(thread arena)系统调用来扩容。
- mmaped chunk。当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。
- last remainder chunk。当需要分配一个small chunk,但在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号