xv6 thread
thread
之前未解决的问题
tp是什么?
the thread pointer, which xv6 uses to hold this core's hartid (core number), the index into cpus[],实际上是存放着hartid的寄存器
hartid是什么?
运行当前代码硬件线程(hart)的ID。对软件层面来说,就是一个独立的处理器。
上下文切换
用户进程上下文切换的机制
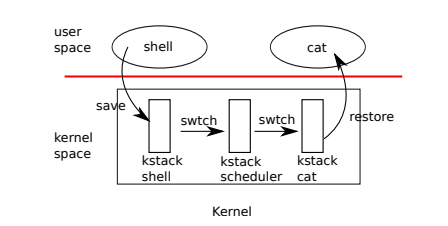
- 用户通过系统调用或者终端进入内核
- 内核通过swtch进入调度程序
- 调度程序通过swtch进入新进程
- 新进程返回到用户空间
进程切换需要保存sp(栈指针)和ra(返回地址,而不是pc)以及一系列callee-saved registers(注意C是在caller里保存caller-saved registers),其实也就意味着改变执行的代码以及栈,并切换寄存器的值,使用contex来管理这些内容。
cpu也管理了一个contex,记录的是调度程序的上下文,每次使用swtch其实就是从进程到调度器的切换,而调度器再使用swtch切换到要运行的进程。
对于时钟中断,uertrap会调用yield,进而调用swtch来进入调度器。
调度代码
对于想要让出CPU的进程,它必须获取进程锁并释放其他锁,并且更新进程状态,然后进入sched,在yield、sleep和exit中都有相关代码。进入调度器后,从swtch之后执行,释放进程锁,然后继续循环找到可以运行的进程。进程sched之前必须获得锁,可以防止CPU还未实际让出之前,另一个CPU选择调度该进程,导致的冲突。
和通常见到的acquire和release成对出现不同,xv6总是在一个进程里获取锁,并在另一个进程释放,比如在yield里获取,在scheduler里释放,使用锁来保证一些状态等常量被修改而且swtch完全运行完后,其他CPU才能运行进程,通俗来说就是保证进程切换的原子性。
对于内核线程,sched是让出CPU的唯一方式,并且调度后CPU从其他进程调用sched之后的位置执行,因此可以把sched和scheduler看做协程,但也有例外:
新进程的返回地址ra是forkre,因此第一个swtch返回到forkret,释放由scheduler获得的进程锁,并且由于之前调用了fork,需要使用usertrapret返回到用户空间。
cpu和proc
cpu记录了目前正在运行的proc,scheduler上下文等信息。
mycpu返回指向当前cpu的指针,实际是将tp作为cpus数组的索引获得的。为了保证获取正在运行的cpu的hartid,任何调用mycpu必须完成关中断和开中断。
编译器保证不能使用tp寄存器,而只有机器模式才能随时获取hartid。xv6保证内核中tp寄存器存储的就是hartid,而用户进程可能修改,因此需要在trapframe里记录。
myproc调用mycpu获得当前运行进程的指针。
sleep和wakeup
sleep和wakeup接口过于底层,此处以信号量的设计为例,学习其工作原理。
使用锁和计数来实现信号量。
- 自旋忙等待,占用cpu, pass
- P的锁只保护计数时,如果检测了计数但还没sleep时,V调用wakeup并未发现休眠进程,可能导致P等待一个已经发生的V操作,永远不能被唤醒。
- P的锁也包围检测计数和sleep,会导致进程带锁休眠,而V获取不了锁,发生死锁。
因此,正确的方法是在sleep函数内,原子地完成进程休眠和释放锁,保证了V中的wakeup一定可以发现P中sleep产生的休眠进程。
sleep和wakeup代码
sleep会先获取进程锁(这样就可以保证wakeup不能提前,因为wakeup在改变进程状态前需要获取进程锁)然后就可以释放条件锁lk,记录chan(waitchannel,可以看作进程休眠的标志,后续wakeup使用同样的chan来唤醒进程)并且改变进程状态state为SLEEPING,调用sched。
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
wakeup会遍历所有进程,找到在chan上休眠的进程,修改状态为为RUNNABLE。
要注意的是调用wakeup前要获取条件锁。
struct proc *p;
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
acquire(&p->lock);
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
release(&p->lock);
}
}
sleep进程至少获取进程锁和条件锁中的一个,而wakeup必须两个都获取,因此唤醒者在消费者检查条件之前,设置条件;在sleep进程标记为睡眠后,wakeup将看到睡眠进程并唤醒它。
多个进程在同一channel上睡眠,比如读取同一个管道,一个wakeup可以唤醒所有的休眠进程,但如果最早醒来的进程读取完了数据,其他进程就出现了假唤醒,需要重新睡眠,因此sleep需要处于循环中,不断检测条件。
pipe
生产者在每次写之后都要唤醒消费者,如果在写的过程中缓冲区满了,需要提前唤醒消费者并且自己进入睡眠状态。
消费者在每次读之后都要唤醒生产者,如果读的过程中缓冲区为空,需要提前唤醒生产者。
为什么不是对称的?缓冲区为空生产者为什么不睡眠?
因为读并不需要严格读取需要的n字节,只需要返回实际读取到的就行,没有必要睡眠。
int
pipewrite(struct pipe *pi, uint64 addr, int n)
{
int i = 0;
struct proc *pr = myproc();
acquire(&pi->lock);
while(i < n){
if(pi->readopen == 0 || killed(pr)){
release(&pi->lock);
return -1;
}
if(pi->nwrite == pi->nread + PIPESIZE){ //DOC: pipewrite-full
wakeup(&pi->nread);
sleep(&pi->nwrite, &pi->lock);
} else {
char ch;
if(copyin(pr->pagetable, &ch, addr + i, 1) == -1)
break;
pi->data[pi->nwrite++ % PIPESIZE] = ch;
i++;
}
}
wakeup(&pi->nread);
release(&pi->lock);
return i;
}
int
piperead(struct pipe *pi, uint64 addr, int n)
{
int i;
struct proc *pr = myproc();
char ch;
acquire(&pi->lock);
while(pi->nread == pi->nwrite && pi->writeopen){ //DOC: pipe-empty
if(killed(pr)){
release(&pi->lock);
return -1;
}
sleep(&pi->nread, &pi->lock); //DOC: piperead-sleep
}
for(i = 0; i < n; i++){ //DOC: piperead-copy
if(pi->nread == pi->nwrite)
break;
ch = pi->data[pi->nread++ % PIPESIZE];
if(copyout(pr->pagetable, addr + i, &ch, 1) == -1)
break;
}
wakeup(&pi->nwrite); //DOC: piperead-wakeup
release(&pi->lock);
return i;
}
进程相关系统调用
子进程通过exit终止时,父进程可能在wait中sleep或者在做其他事,无论如何后续调用wait时,必须观察到子进程终止。
wait
获取wait_lock(条件锁),遍历进程,找到自己的子进程,对状态为ZOMBIE的记录pid和exit status(作为wait返回值),调用freeproc释放子进程资源。
exit
记录退出状态,释放一些资源(打开文件,cwd),调用reparent将其子进程交给init进程,在父进程处于等待状态时唤醒父进程,将调用者标记为僵尸,并永久地放弃CPU。
kill
设置p->killed,如果进程正在睡眠,则唤醒它。最终,进程将进入或离开内核,此时usertrap中的代码将调用exit。如果进程在用户空间中运行,它将通过发出系统调用或计时器(或其他设备)中断而很快进入内核。
一些对sleep的调用也在循环中测试p->killed,如果为真可能直接退出,比如piperead;也有一些不检查,因为代码处于一个应该是原子的多步骤系统调用的中间,比如virtio驱动程序。
进程锁
一种简单方法是,在读取或写入以下任何结构过程字段时必须持有锁:p->state、p->chan、p->killed、p->xstate和p->pid。这些字段可以被其他进程或其他内核上的调度器线程使用,加锁是很自然的。
p->lock的大多数用途是保护xv6进程数据结构和算法的高级方面,理解起来有些困难
- Along with p->state, it prevents races in allocating proc[] slots for new processes.
- It conceals a process from view while it is being created or destroyed.
- It prevents a parent’s wait from collecting a process that has set its state to ZOMBIE but has not yet yielded the CPU.
- It prevents another core’s scheduler from deciding to run a yielding process after it sets its state to RUNNABLE but before it finishes swtch.
- It ensures that only one core’s scheduler decides to run a RUNNABLE processes.
- It prevents a timer interrupt from causing a process to yield while it is in swtch.
- Along with the condition lock, it helps prevent wakeup from overlooking a process that is calling sleep but has not finished yielding the CPU.
- It prevents the victim process of kill from exiting and perhaps being re-allocated between kill’s check of p->pid and setting p->killed.
- It makes kill’s check and write of p->state atomic.
有几条其实真的不太好理解qaq
p->parent由全局锁wait_lock保护,而不是由p->lock保护。
虽然p->parent由进程本身和搜索其子进程的其他进程读取,但只有进程的父进程才能修改p->parent。wait_lock的目的是在wait休眠等待任何子进程退出时充当条件锁。退出的子进程持有wait_lock或p->lock,直到它将自己的状态设置为ZOMBIE,唤醒父进程,并释放CPU。
条件锁和进程锁配合使用,可以防止the lost wake-up problem。
对于可能休眠的进程,步骤为获取条件锁,检查条件,进入sleep获取进程锁,释放条件锁,修改进程状态,调用sched,返回后释放进程锁,重新获得条件锁,在while循环中重新从检查条件开始执行。
对于想要唤醒的进程,步骤为获取条件锁,检查或修改条件,进入wakeup获取进程锁,修改进程状态,释放进程锁,释放条件锁。
可以参考sleep(p, &wait_lock)以及pipe中的sleep。
============================手动分割
看书时在一系列acquire(&p->lock)的操作纠结了好久,后来才明白,在此也记录一下自己愚蠢的想法吧。刚开始想法是:
yield和sleep等调用sched来使用内核scheduler进行进程切换的函数,在切换前要获取进程锁;
而scheduler调度程序、wakeup更改进程状态也要获取进程锁,那被切换的进程还怎么唤醒和被重新调度?这不是矛盾了吗?
尝试问了GPT,它胡说一气。后来认真想想又看了书上的细节:
swtch returns on the scheduler’s stack as though scheduler’s swtch had returned (kernel/proc.c:463). The scheduler continues its for loop, finds a process to run, switches to it, and the cycle repeats.
才恍然大悟,自已理解错了调度器的使用,实际上使用swtch进入调度器程序后,交换上下文并ret,从scheduler的swtch之后执行,相当于scheduler的swtch返回了,其实之前已经获得了锁。
从正向看就是
Each CPU calls scheduler() after setting itself up.
There is one case when the scheduler’s call to swtch does not end up in sched. allocproc
sets the context ra register of a new process to forkret (kernel/proc.c:515), so that its first swtch “returns” to the start of that function. forkret exists to release the p->lock; otherwise, since the new process needs to return to user space as if returning from fork, it could instead start at usertrapret.
最初scheduler获取进程锁后调度由allocproc创建的进程,此时进程上下文的ra为forkret,因此进入forkret函数,会释放进程锁,也就不会导致我最开始疑问的死锁问题。
而这些其实文章中都有,第一次看的时候可能没太注意。而且确实模糊理解上没问题,文档中大部分也和操作系统学的差不多,本来改变进程的状态肯定就要持有锁,但深究发现自己实际上对进程调度具体机制没有很清楚,还是有点tricky的。
但是读完其实还有些疑问:
对于书中给出的PV操作的例子,为什么选择使用lock来保护计数,而不是采用原子加减法?
而且明明xv6中acquire(&lock)本来就是通过test_and_set原子操作构建自旋锁,为什么还要费这么大劲去实现sleep和wakeup优化的PV操作?
当然,如果对用户来说要用更高层次的函数来实现信号量,那确实可以用锁和条件变量来实现信号量,而且sleep(void *chan, struct spinlock *lk)和cond_wait(cond_t *cv, lock_t *lock)的实现也具有相似之处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号