
elasticsearch
elasticsearch 依赖jdk 环境,如果无法判断使用哪个版本jdk 可以下载带有jdk版本的elasticsearch。官方下载地址或华为镜像源下载地址。启动后监听本机的9200端口为客户端提供数据访问,监听9300端口用于集群内部集群选举和数据同步。
单机部署
-
max_map_count
内存映射(Memory Mapping)是一种在应用程序地址空间和物理存储器之间建立映射关系的技术
max_map_count参数是用于限制每个进程能够使用的最大内存映射区域数量。如果不修改,启动时提示错误: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
sysctl -w vm.max_map_count=262144 echo 'vm.max_map_count=262144' >>/etc/sysctl.conf -
添加服务用户
注意事项: elasticsearch 不能以root用户启动
useradd --system esticsearch -
下载安装包
version=7.2.0 wget https://repo.huaweicloud.com/elasticsearch/${version}/elasticsearch-${version}-linux-x86_64.tar.gz tar xf elasticsearch-${version}-linux-x86_64.tar.gz -C /opt chown -R esticsearch:esticsearch /opt/elasticsearch-7.2.0/ -
修改配置文件
tee /opt/elasticsearch-7.2.0/config/elasticsearch.yml <<EOF cluster.name: my-application node.name: node-1 path.data: ./data path.logs: ./logs # 是否在程序启动时立即分配指定大小内存给elasticsearch进程 bootstrap.memory_lock: false network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"] EOF -
创建systemd启动文件
#su - esticsearch -c /opt/elasticsearch-7.2.0/bin/elasticsearchtee /etc/systemd/system/elasticsearch.service <<EOF [Unit] Description= elasticsearch serveice After=network.target [Service] WorkingDirectory=/opt/elasticsearch-7.2.0/ ExecStart=/opt/elasticsearch-7.2.0/bin/elasticsearch User=esticsearch LimitNOFILE=65535 [Install] WantedBy=multi-user.target EOFsystemctl daemon-reload systemctl start elasticsearch systemctl status elasticsearch -
验证服务
查看当前集群存在的节点
curl http://127.0.0.1:9200/_cat/nodes?v查看当前集群状态
curl -s http://127.0.0.1:9200/_cluster/health?pretty=true |jq ".status"
当我开启内存锁定后,以下参数必须设定
报错信息: memory locking requested for elasticsearch process but memory is not locked
echo "DefaultLimitMEMLOCK=infinity" >>/etc/systemd/system.conf
# 该命令会重启systemd 进程
systemctl daemon-reexec
以下内容建议执行,不执行并不会导致报错
cat >>/etc/security/limits.conf<<EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
EOF
cat >> /etc/systemd/system.conf<<EOF
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
EOF
集群部署
集群模式只是配置文件不同,其他配置参考单机部署
节点一
tee /opt/elasticsearch-7.2.0/config/elasticsearch.yml <<EOF
# 所有节点集群名称必须相同
cluster.name: my-application
# 节点名称集群内不许唯一
node.name: node-1
path.data: ./data
path.logs: ./logs
# 是否在程序启动时立即分配指定大小内存给elasticsearch进程
bootstrap.memory_lock: false
network.host: 0.0.0.0
http.port: 9200
#初始化时哪些节点可以被选举为master ,集群内的主机可以都填写上,也可以填写部分主机。支持使用 `node.name` 或者 `ip地址`
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# 启动时向哪些主机进行宣告,进行集群选举,集群内的主机都要填写上。包括自己
discovery.seed_hosts: ["10.4.7.250","10.4.7.251","10.4.7.252"]
# 当集群进行数据恢复时必须大于指定数量的节点在线,才可以进行数据恢复。通常设置为 (集群节点数量/2+1)
gateway.recover_after_nodes: 1
# 当删除索引时是否支持索引名称的模糊匹配,当`true` 时表示不支持模糊。
action.destructive_requires_name: true
EOF
节点二
tee /opt/elasticsearch-7.2.0/config/elasticsearch.yml <<EOF
# 所有节点集群名称必须相同
cluster.name: my-application
# 节点名称集群内不许唯一
node.name: node-2
path.data: ./data
path.logs: ./logs
# 是否在程序启动时立即分配指定大小内存给elasticsearch进程
bootstrap.memory_lock: false
network.host: 10.4.7.251
http.port: 9200
#初始化时哪些节点可以被选举为master ,集群内的主机可以都填写上,也可以填写部分主机。支持使用 `node.name` 或者 `ip地址`
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# 启动时向哪些主机进行宣告,进行集群选举,集群内的主机都要填写上。包括自己
discovery.seed_hosts: ["10.4.7.250","10.4.7.251","10.4.7.252"]
# 当集群进行数据恢复时必须大于指定数量的节点在线,才可以进行数据恢复。通常设置为 (集群节点数量/2+1)
gateway.recover_after_nodes: 1
# 当删除索引时是否支持索引名称的模糊匹配,当`true` 时表示不支持模糊。
action.destructive_requires_name: true
EOF
节点三
tee /opt/elasticsearch-7.2.0/config/elasticsearch.yml <<EOF
# 所有节点集群名称必须相同
cluster.name: my-application
# 节点名称集群内不许唯一
node.name: node-3
path.data: ./data
path.logs: ./logs
# 是否在程序启动时立即分配指定大小内存给elasticsearch进程
bootstrap.memory_lock: false
network.host: 10.4.7.252
http.port: 9200
#初始化时哪些节点可以被选举为master ,集群内的主机可以都填写上,也可以填写部分主机。支持使用 `node.name` 或者 `ip地址`
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# 启动时向哪些主机进行宣告,进行集群选举,集群内的主机都要填写上。包括自己
discovery.seed_hosts: ["10.4.7.250","10.4.7.251","10.4.7.252"]
# 当集群进行数据恢复时必须大于指定数量的节点在线,才可以进行数据恢复。通常设置为 (集群节点数量/2+1)
gateway.recover_after_nodes: 1
# 当删除索引时是否支持索引名称的模糊匹配,当`true` 时表示不支持模糊。
action.destructive_requires_name: true
EOF
查询集群状态
一般情况下我们使用 elasticsearch-head 插件来监听elasticsearch。也可以使用api接口来查询
方式一:
http://10.4.7.250:9200/_cluster/health?pretty
http://10.4.7.250:9200/_cat/health?v
http://10.4.7.250:9200/_cat/nodes?v
# 创建索引
http://10.4.7.50:9200/_cat/indices?v
方式二:
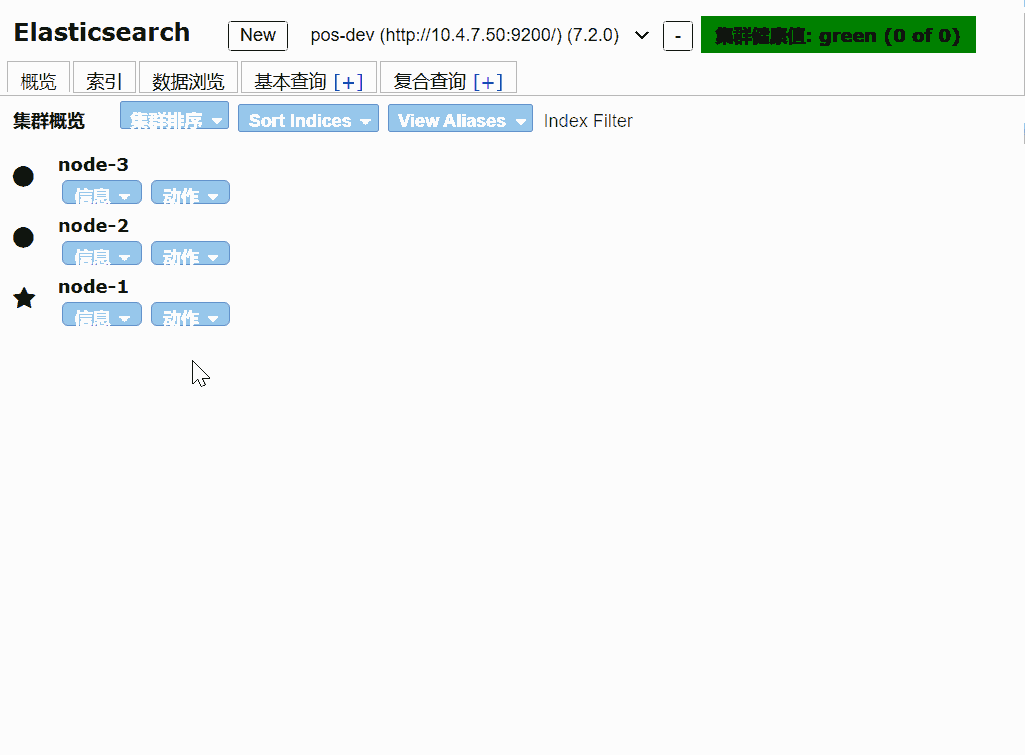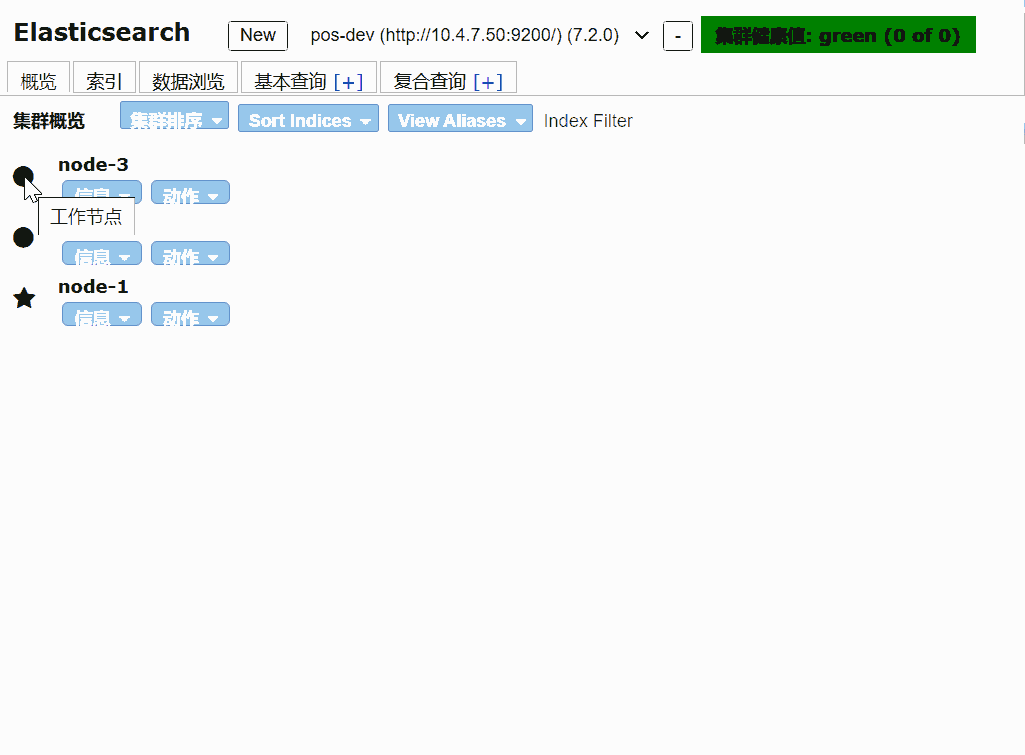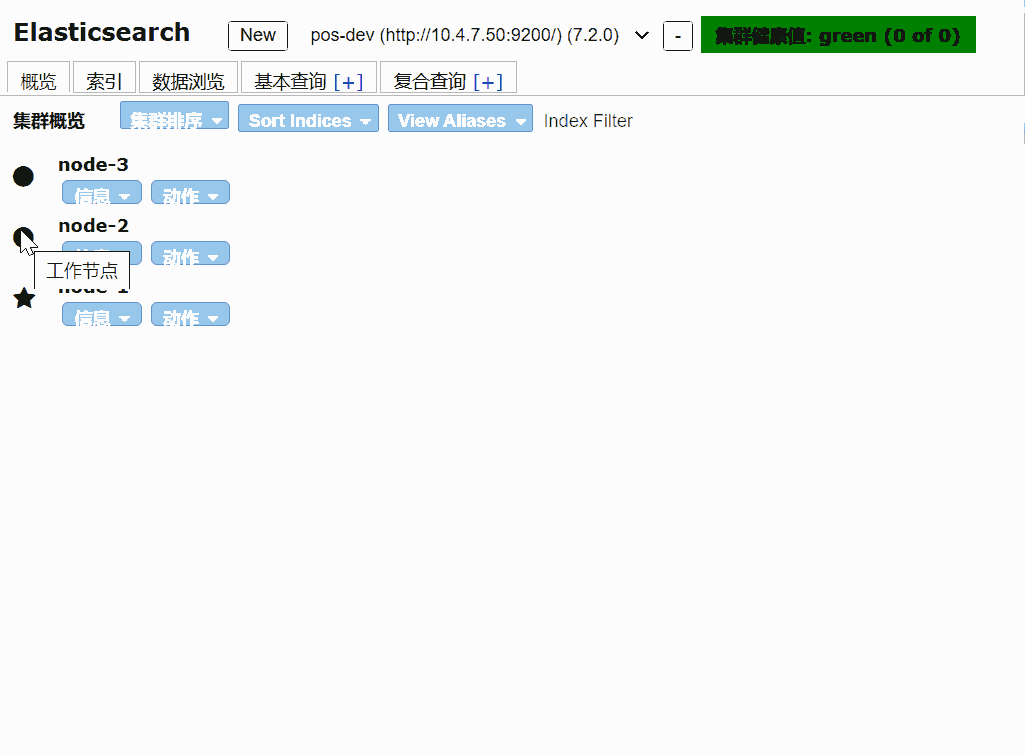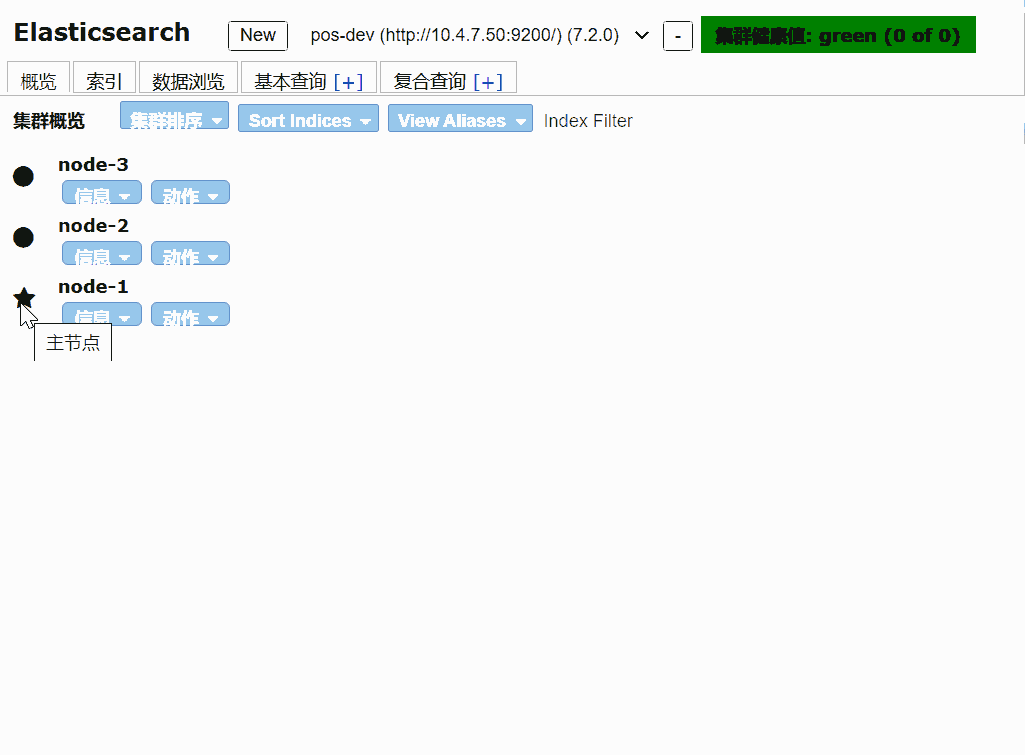
创建一个索引
http://10.4.7.50:9200/_cat/indices?v
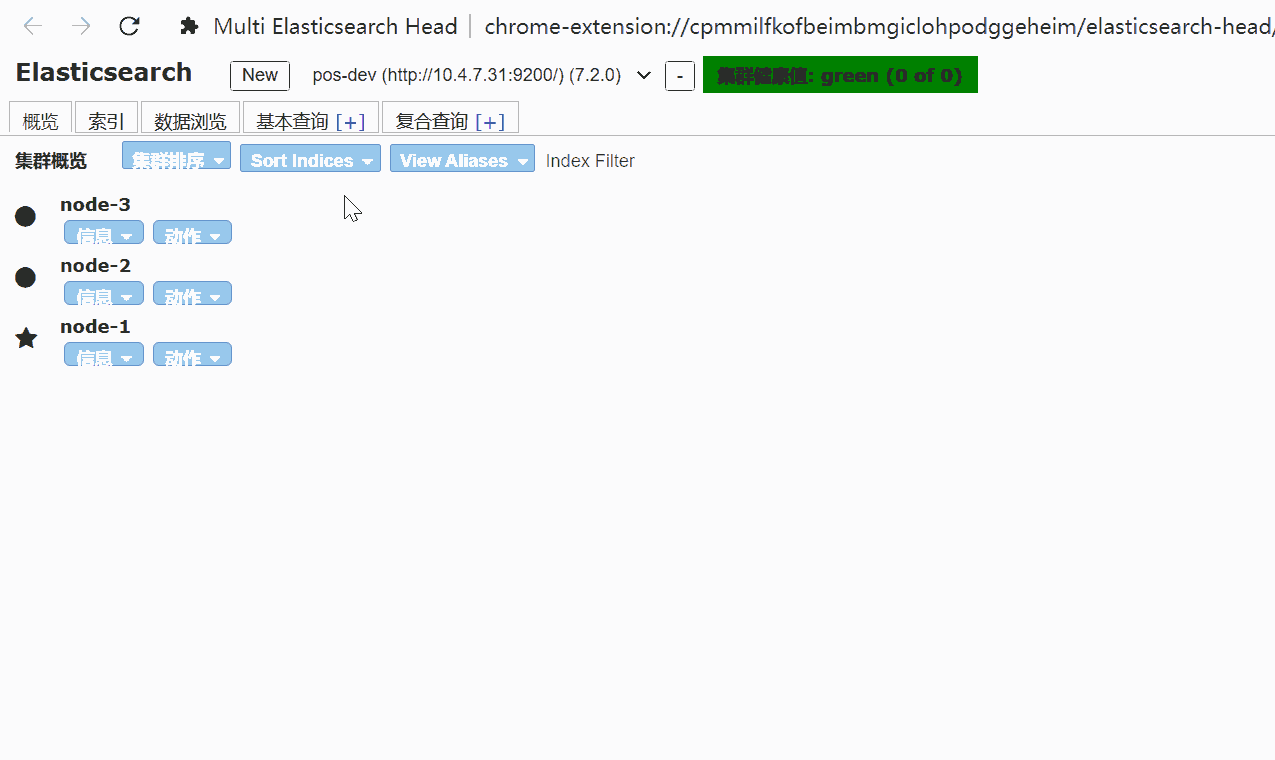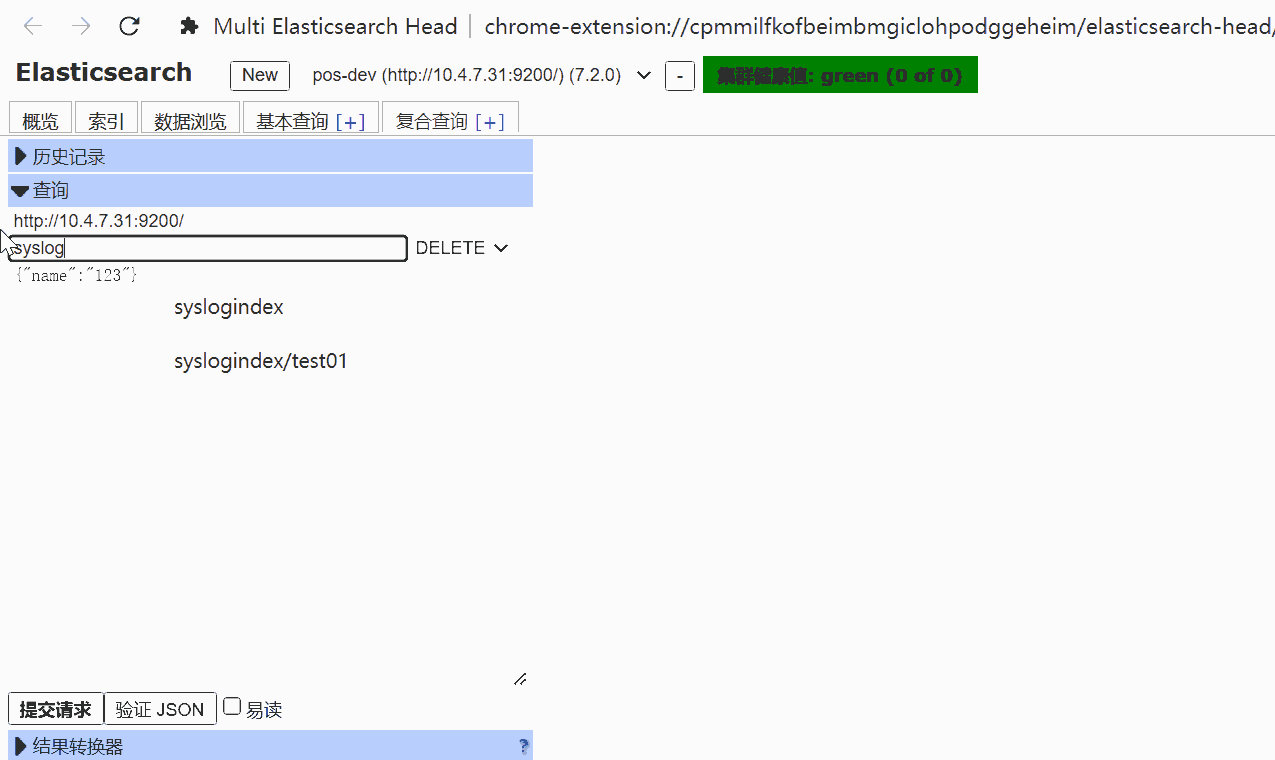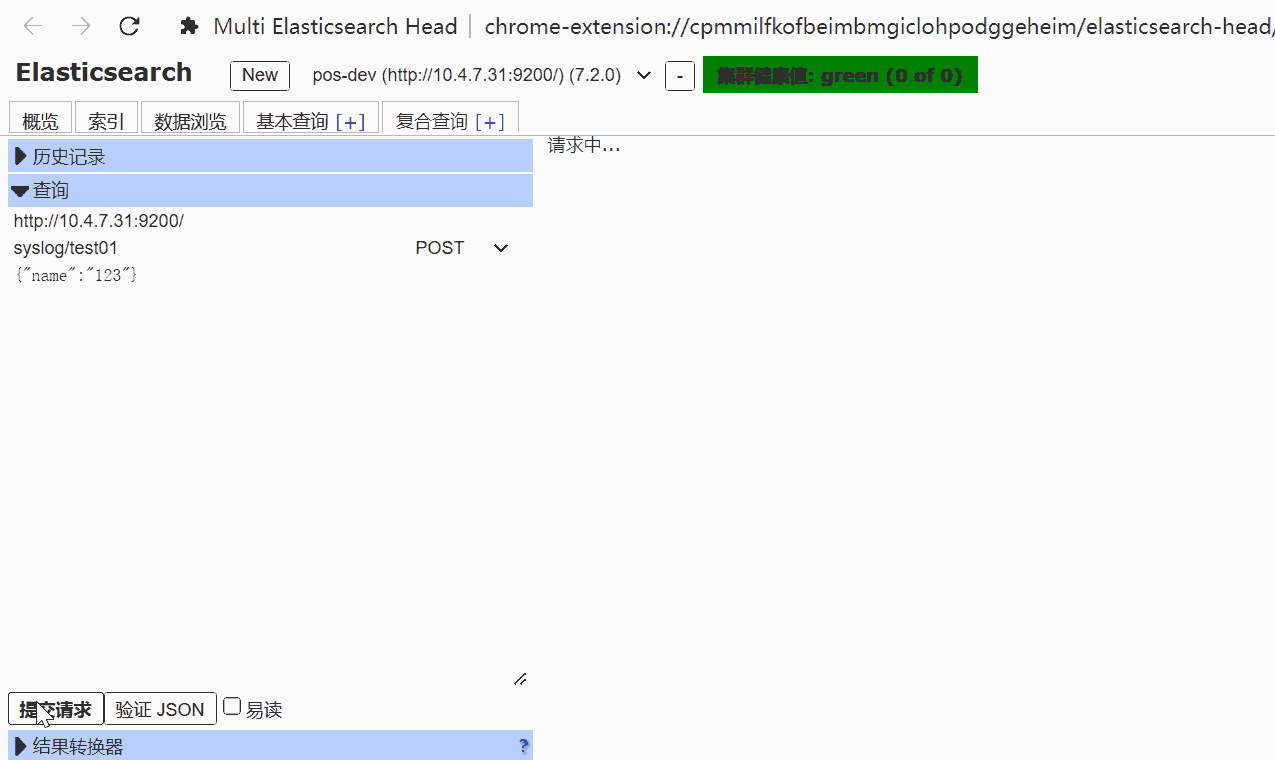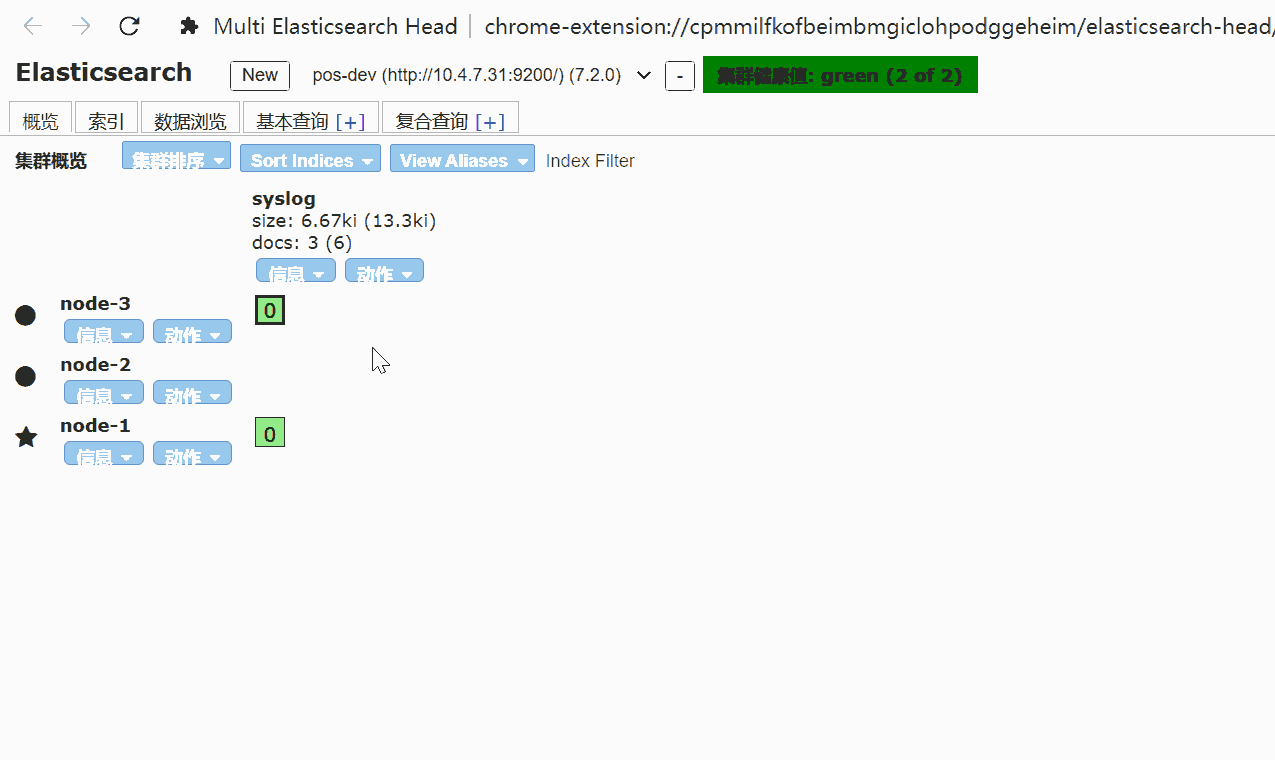
elasticsearch-head 是对elasticsearch API 封装,可以使用chrome插件查看,也可以通过启动服务的方式查看
http.cors.enabled: true
http.cors.allow-origin: "*"
docker run --rm -it -p9100:9100 mobz/elasticsearch-head:5-alpine

 浙公网安备 33010602011771号
浙公网安备 33010602011771号